Unix 和 Java IO 模型简析
Unix 和 Java IO 模型简析
从计算机结构的视角来看的话, I/O 描述了计算机系统与外部设备之间通信的过程。
为了保证操作系统的稳定性和安全性,内存的地址空间划分为 用户空间(User space) 和 内核空间(Kernel space ) 。
像我们平常运行的应用程序都是运行在用户空间,只有内核空间才能进行系统态级别的资源有关的操作,比如文件管理、进程通信、内存管理等等。并且,用户空间的程序不能直接访问内核空间。
因此,用户进程想要执行 IO 操作的话,必须通过 系统调用 来间接访问内核空间。我们在平常开发过程中接触最多的就是 磁盘 IO(读写文件) 和 网络 IO(网络请求和响应)。
也就是说,我们的应用程序实际上只是发起了 IO 操作的调用而已,具体 IO 的执行是由操作系统的内核来完成的。
当应用程序发起 I/O 调用后,会经历两个步骤:
- 内核等待 I/O 设备准备好数据
- 内核将数据从内核空间拷贝到用户空间
Unix IO 模型简介
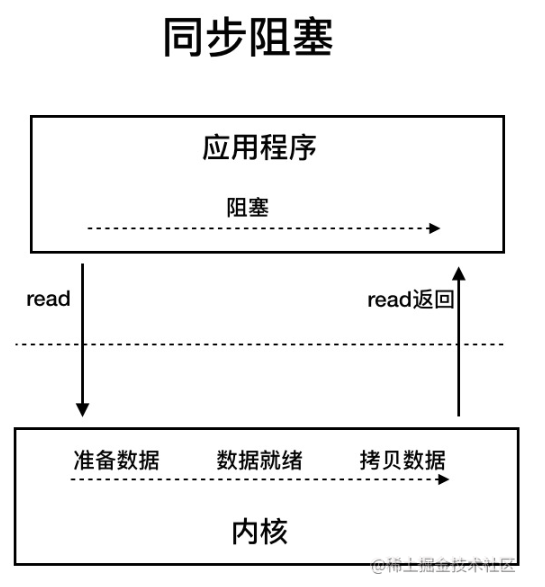
同步阻塞式 I/O
应用进程被阻塞,直到数据复制到应用进程缓冲区中才返回。
应该注意到,在阻塞的过程中,其它程序还可以执行,因此阻塞不意味着整个操作系统都被阻塞。因为其他程序还可以执行,因此不消耗 CPU 时间,这种模型的执行效率会比较高。
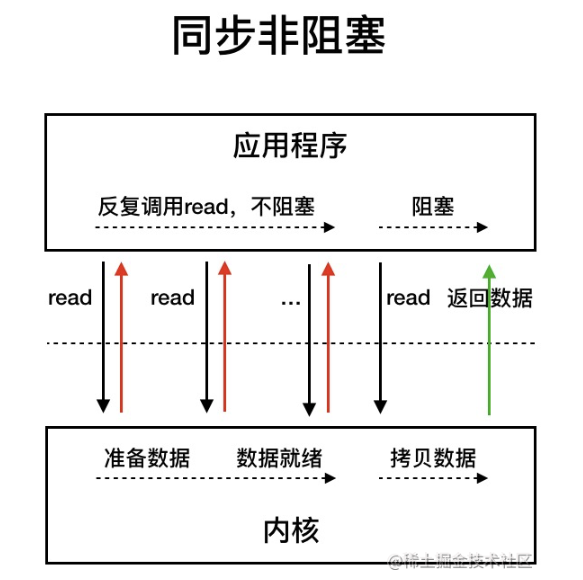
同步非阻塞式 I/O
应用进程执行系统调用之后,内核返回一个错误码。应用进程可以继续执行,但是需要不断的执行系统调用来获知 I/O 是否完成,这种方式称为轮询(polling)。
由于 CPU 要处理更多的系统调用,因此这种模型是比较低效的。几乎跟阻塞用户进程无异。
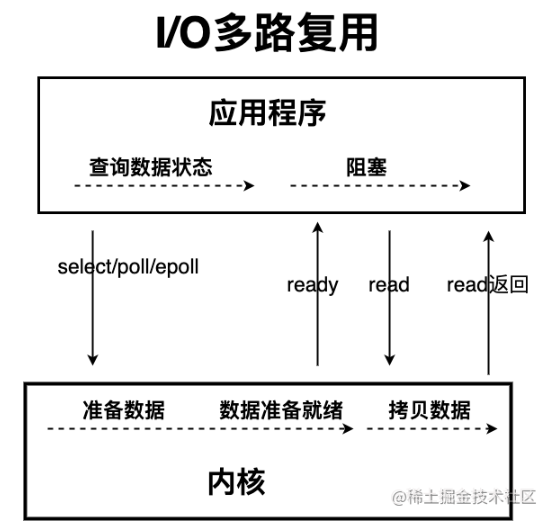
I/O 多路复用
使用 select 或者 poll 等待数据,并且可以等待多个套接字中的任何一个变为可读,这一过程会被阻塞,当某一个套接字可读时返回。之后再使用 recvfrom 把数据从内核复制到进程中。
它可以让单个进程具有处理多个 I/O 事件的能力。又被称为 Event Driven I/O,即事件驱动 I/O。
如果一个 Web 服务器没有 I/O 复用,那么每一个 Socket 连接都需要创建一个线程去处理。如果同时有几万个连接,那么就需要创建相同数量的线程。并且相比于多进程和多线程技术,I/O 复用不需要进程线程创建和切换的开销,系统开销更小。
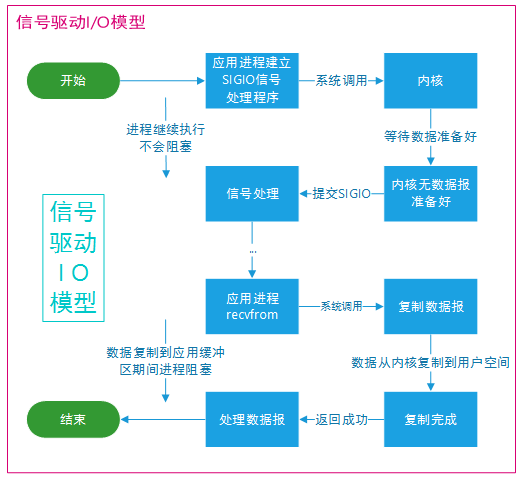
信号驱动 I/O
应用进程使用 sigaction 系统调用,内核立即返回,应用进程可以继续执行,也就是说等待数据阶段应用进程是非阻塞的。内核在数据到达时向应用进程发送 SIGIO 信号,应用进程收到之后在信号处理程序中调用 recvfrom 将数据从内核复制到应用进程中。
相比于非阻塞式 I/O 的轮询方式,信号驱动 I/O 的 CPU 利用率更高。
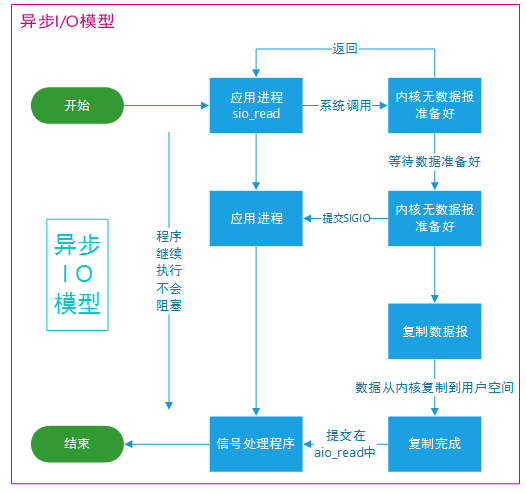
异步 I/O
进行 aio_read 系统调用会立即返回,应用进程继续执行,不会被阻塞,内核会在所有操作完成之后向应用进程发送信号。
异步 I/O 与信号驱动 I/O 的区别在于,异步 I/O 的信号是通知应用进程 I/O 完成,而信号驱动 I/O 的信号是通知应用进程可以开始 I/O。
Java IO 模型
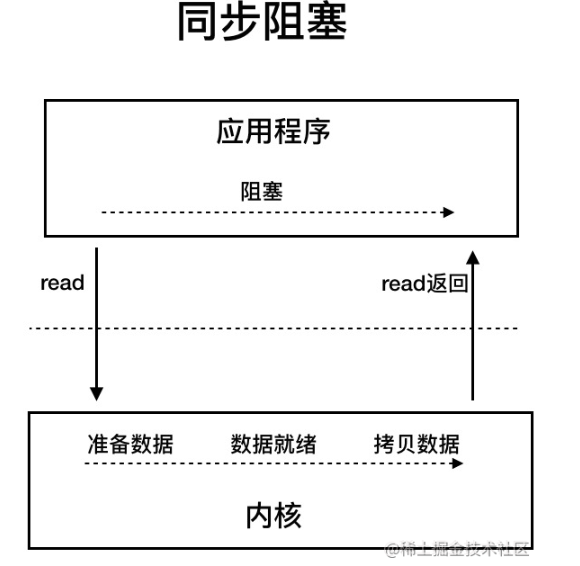
BIO (Blocking I/O)
同步阻塞 IO 模型中,应用程序发起 read 调用后,会一直阻塞,直到内核把数据拷贝到用户空间。
NIO (Non-blocking/New I/O)
Java 中的 NIO 可以看作是 I/O 多路复用模型。
IO 多路复用模型中,线程首先发起 select 调用,询问内核数据是否准备就绪,等内核把数据准备好了,用户线程再发起 read 调用。read 调用的过程(数据从内核空间 -> 用户空间)还是阻塞的。
目前支持 IO 多路复用的系统调用,有 select,epoll 等等。select 系统调用,目前几乎在所有的操作系统上都有支持。
- select 调用 :内核提供的系统调用,它支持一次查询多个系统调用的可用状态。几乎所有的操作系统都支持。
- epoll 调用 :linux 2.6 内核,属于 select 调用的增强版本,优化了 IO 的执行效率。
IO 多路复用模型,通过减少无效的系统调用,减少了对 CPU 资源的消耗。
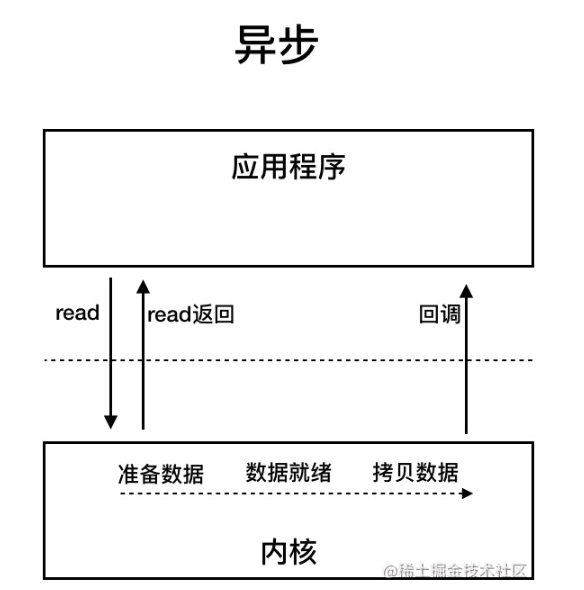
AIO (Asynchronous I/O)
AIO 也就是 NIO 2。Java 7 中引入了 NIO 的改进版 NIO 2,它是异步 IO 模型。
异步 IO 是基于事件和回调机制实现的,也就是应用操作之后会直接返回,不会堵塞在那里,当后台处理完成,操作系统会通知相应的线程进行后续的操作。
目前来说 AIO 的应用还不是很广泛。Netty 之前也尝试使用过 AIO,不过又放弃了。这是因为,Netty 使用了 AIO 之后,在 Linux 系统上的性能并没有多少提升。
IO多路复用模型
Java NIO 就是按照 IO 多路复用模型来实现的。
应用场景
很容易产生一种错觉认为只要用 epoll 就可以了,select 和 poll 都已经过时了,其实它们都有各自的使用场景。
- select
- select 的 timeout 参数精度为 1ns,而 poll 和 epoll 为 1ms,因此 select 更加适用于实时要求更高的场景,比如核反应堆的控制。
- select 可移植性更好,几乎被所有主流平台所支持
- poll
- poll 没有最大描述符数量的限制,如果平台支持并且对实时性要求不高,应该使用 poll 而不是 select。
- 需要同时监控小于 1000 个描述符,就没有必要使用 epoll,因为这个应用场景下并不能体现 epoll 的优势。
- 需要监控的描述符状态变化多,而且都是非常短暂的,也没有必要使用 epoll。因为 epoll 中的所有描述符都存储在内核中,造成每次需要对描述符的状态改变都需要通过
epoll_ctl()进行系统调用,频繁系统调用降低效率。并且 epoll 的描述符存储在内核,不容易调试
- epoll
- 只需要运行在 Linux 平台上,并且有非常大量的描述符需要同时轮询,而且这些连接最好是长连接。
参考资料:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号