Git 学习笔记
Git 学习笔记
起步
安装
# 在 ubuntu 上安装
sudo apt install git-all
git --version
初次运行 Git 前的配置
安装完 git 之后,要做的第一件事就是设置你的用户名和邮件地址,因为每一个 git 提交都会使用这些信息,它们会写入到你的每一次提交中,不可更改:
# 显示当前的 Git 配置
$ git config --list
# 编辑 Git 配置文件
$ git config -e [--global]
# 设置提交代码时的用户信息
git config --global user.name "lockegogo"
git config --global user.email "lockegogo@example.com"
如果使用了
--global选项,那么该命令只需要运行一次,因为之后无论你在该系统上做任何事情, Git 都会使用那些信息。
Git 常用命令
获取 git 仓库
在已存在目录中初始化仓库
# 在当前目录新建一个 Git 代码库
cd /home/user/my_project
git init
上述命令将创建一个名为 .git 的子目录,这个子目录含有你初始化的 git 仓库中所有的必须文件,但是目前我们仅仅是做了一个初始化的操作,项目里的文件还没有被跟踪。
如果在一个已存在文件的文件夹(而非空文件夹)中进行版本控制,你应该开始追踪这些文件并进行初始提交。可以通过 git add 命令来指定所需的文件来进行追踪,然后执行 git commit:
git add *.c
git add LICENSE
git commit -m 'initial project version
克隆现有的仓库
# 远程拉取
git clone <url>
# 自定义本地仓库的名字
git clone <url> <新目录名>
# 举个栗子
git clone https://github.com/libgit2/libgit2 mylibgit
# 从远程仓库拉取最新的 master 分支代码
git pull origin master
记录每次更新到仓库
# 检查当前文件状态
git status
# 跟踪新文件,将文件放入暂存区
git add README
# 注意:如果运行了 git add 之后又对文件做了修订,需要重新运行 git add 把最新版本暂存起来
# 忽略文件
$ cat .gitignore
*.[oa]
*~
# 第一行告诉 Git 忽略所有以 .o 或 .a 结尾的文件。一般这类对象文件和存档文件都是编译过程中出现的。 第二行告诉 Git 忽略所有名字以波浪符(~)结尾的文件
我们再看一个 .gitignore 文件的例子:
# 忽略所有的 .a 文件
*.a
# 但跟踪所有的 lib.a,即便你在前面忽略了 .a 文件
!lib.a
# 只忽略当前目录下的 TODO 文件,而不忽略 subdir/TODO
/TODO
# 忽略任何目录下名为 build 的文件夹
build/
# 忽略 doc/notes.txt,但不忽略 doc/server/arch.txt
doc/*.txt
# 忽略 doc/ 目录及其所有子目录下的 .pdf 文件
doc/**/*.pdf
如果要查看尚未暂存的文件更新了哪些部分,可使用 git diff,但注意其本身只显示尚未暂存的改动,而不是自上次提交以来所作的所有改动。
# 比较工作目录中当前文件和暂存区域快照之间的差异
git diff
# 比对已暂存文件与最后一次提交的文件差异
git diff --staged
git diff --cached
接下来提交更新:
git commit
# 接下来输入提交说明
# -m: 或者将提交信息与命令放在同一行
git commit -m "新增 README"
# -a: 跳过暂存,直接将所有已经跟踪过的文件提交
git commit -a -m "新增 README"
# 使用一次新的commit,替代上一次提交
# 如果代码没有任何新变化,则用来改写上一次 commit 的提交信息
git commit --amend -m [message]
一些小 tips:
# 对文件重命名
git mv file_from file_to
查看提交历史
git log
# 查看每次提交的简略统计信息
git log --stat
回滚
未使用 git add 缓存代码
# 放弃特定文件的修改
git checkout [file-name]
git restore [file-name] # 推荐用 restore
# 放弃所有文件的修改
git checkout .
git restore . # 推荐用 restore
注意,此命令用来放弃所有还没有加入到缓存区的修改:内容修改与整个文件删除,但是此命令不会删除掉刚新建的文件,因为刚新建的文件还没有加入到 git 的管理系统中,对于 git 是未知的,自己手动删除就好了。
已使用 git add 缓存了代码
# 放弃指定文件的缓存
git reset [file-name]
# 放弃所有文件的缓存
git reset .
注意,此命令用来清除 git 对于文件修改的缓存,相当于撤销 git add 命令所做的工作。在使用本命令后,本地的修改并不会消失。
如果希望工作区的修改也消失,需要再使用
git checkout .
已使用 git commit 提交了代码
如果想要回滚到上一次提交的状态,可以使用 git reset 命令。具体步骤如下:
- 确认当前所在分支。使用
git branch命令查看当前所在分支。如果不是您想要从上一次提交恢复的分支,请切换到正确的分支。
git branch
- 使用
git log命令查看您要恢复的提交的哈希值。从提交历史中查找上一次提交的哈希值。
git log
- 使用
git reset命令将 HEAD 指向指定 commit。使用--hard参数可以强制重置暂存区和工作区
git reset --hard [提交的哈希值]
如果不加 –hard 命令,使用
git reset [提交的哈希值],则只会重置暂存区,但是工作区不变。
Git 回滚命令有如下三个使用方式,请因地制宜,切换到指定分支后,根据自己的情况选择合适的那个:
# 回滚到上个版本
git reset --hard HEAD^
# 回退到前 n 次提交之前,若 n=3,则可以回退到 3 此提交之前
git reset --hard HEAD~n
# 回i滚到指定 commit 的 sha 码,推荐使用这种方式
git reset --hard commit_sha
# 示例
git reset --hard 05ac0bfb2929d9cbwiener75e52ecb011950fb
放弃所有本地修改(包括文件)
git reset --hard
git clean -df
Git 分支
# 1. 查看分支
# 1.1 查看所有本地分支
git branch
--merged:过滤已经合并到当前分支的分支
--no-merged: 过滤尚未合并到当前分支的分支
# 1.2 列出所有远程分支
$ git branch -r
# 1.3 列出所有本地分支和远程分支
$ git branch -a
# 2. 创建分支
# 2.1 新建一个分支,但是依然停留在当前分支
git branch [branch-name]
# 2.2 新建一个分支,指向指定 commit,但是依然停留在当前分支
git branch [branch-name] [commit]
# 3. 切换分支
# 3.1 切换到指定分支,并更新工作区
git checkout [branch-name]
# 也可以使用一行命令同时执行创建和切换
git checkout -b [branch-name]
# 3.2 如果使用 2.23.0 及以上版本,推荐使用 switch
# 因为 checkout 命令可以创建分支、切换分支、恢复文件等,使用起来容易混淆
git switch [branch-name]
# 合并指定分支到当前分支
git merge -no-ff [branch-name]
# 删除分支
## 1. 删除本地分支
git branch --delete dev
# 或者使用缩写:git branch -d dev
# 强制删除,不查看是否合并
git branch -D dev
## 2. 删除远程分支
git push origin --delete [branch-name] # 该指令也会删除追踪分支
## 3. 删除追踪分支
git branch –delete –remotes <remote>/<branch>
git branch -dr <remote>/<branch>
接下来,我们模拟一个真实的场景:
- 开发某个网站。
- 为实现某个新的用户需求,创建一个分支。
- 在这个分支上开展工作。
正在此时,你突然接到一个电话说有个很严重的问题需要紧急修补。 你将按照如下方式来处理:
- 切换到你的线上分支(production branch)。
- 为这个紧急任务新建一个分支,并在其中修复它。
- 在测试通过之后,切换回线上分支,然后合并这个修补分支,最后将改动推送到线上分支。
- 切换回你最初工作的分支上,继续工作。
git checkout -b iss53
vim index.html
git commit -a -m 'added a new footer [issue 53]'
git checkout master
git checkout -b hotfix
vim index.html
git commit -a -m 'fixed the broken email address'
# 运行测试,确保修改是正确的,然后将 hotfix 分支合并回你的 master 分支来部署到线上
git checkout master
git merge hotfix
# 解决紧急问题之后,应该先删除 hotfix 分支,然后再回到之前的工作
git branch -d hotfix
git checkout iss53
vim index.html
git commit -a -m 'finished the new footer [issue 53]'
# 最终进行合并
git checkout master
git merge iss53
git branch -d iss53
# 注意如果一个分支还没有合并,使用 -d 是删除不掉的,如果真的不想要了,可以使用 -D 强制删除
如果在两个不同的分支中,对用一个文件的同一个部分进行了不同的修改,在合并时就会遇到冲突,Git 没办法干净的合并它们。
git status
# 使用图形化工具来解决冲突
git mergetool
如果想要强制推送到远程仓库:
git push origin HEAD --force
服务器上的 Git
在服务器上搭建 Git
如何给团队的每个人提供服务器上的 git 的访问权?
我们可以给每个人创建账号并且设置临时密码,但这种方案十分麻烦。
更好的做法是:在主机上建立一个 git 账户,让每个需要写权限的人发送一个 SSH 公钥,然后将其加入 git 账户的 ~/.ssh/authorized_keys 文件。
生成 SSH 公钥
ssh-keygen -o
首先 ssh-keygen 会确认密钥的存储位置(默认是 .ssh/id_rsa),然后它会要求你输入两次密钥口令。 如果你不想在使用密钥时输入口令,将其留空即可。 然而,如果你使用了密码,那么请确保添加了 -o 选项,它会以比默认格式更能抗暴力破解的格式保存私钥。
然后将公钥(.pub 文件内容)添加到 git 账户,公钥看起来是这样的:
$ cat ~/.ssh/id_rsa.pub
ssh-rsa AAAAB3NzaC1yc2EAAAABIwAAAQEAklOUpkDHrfHY17SbrmTIpNLTGK9Tjom/BWDSUGPl+nafzlHDTYW7hdI4yZ5ew18JH4JW9jbhUFrviQzM7xlELEVf4h9lFX5QVkbPppSwg0cda3Pbv7kOdJ/MTyBlWXFCR+HAo3FXRitBqxiX1nKhXpHAZsMciLq8V6RjsNAQwdsdMFvSlVK/7XAt3FaoJoAsncM1Q9x5+3V0Ww68/eIFmb1zuUFljQJKprrX88XypNDvjYNby6vw/Pb0rwert/EnmZ+AW4OZPnTPI89ZPmVMLuayrD2cE86Z/il8b+gw3r3+1nKatmIkjn2so1d01QraTlMqVSsbxNrRFi9wrf+M7Q== schacon@mylaptop.local
Github:在个人账户的 settings 菜单下找到 SSH and GPG keys,将刚刚复制的密钥添加到 key 这一栏中,点击「add SSH key」提交。
配置服务器
在 Github 或 Gitlab 上创建个人仓库,搭建好之后,开发者可以克隆仓库并进行改动:
$ git clone git@gitserver:/srv/git/project.git
$ cd project
$ vim README
$ git commit -am 'fix for the README file'
# 将本地的 master 分支推送到 origin 主机的 master 分支
$ git push origin master
git push 命令用于从将本地的分支版本上传到远程并合并。
git push <远程主机名> <本地分支名>:<远程分支名>
# 如果本地分支名与远程分支名相同,则可以省略冒号:
git push <远程主机名> <本地分支名>
拉取远程仓库时只同步指定目录和文件
使用 sparse-checkout 可以实现 git 仓库的定制化同步,需要什么目录和文件就同步什么目录和文件:
# 1. 从 github 上拉取仓库
git remote add -f origin git@github.com:itwanger/toBeBetterJavaer.git
# 2. 启用 sparse-checkout,并初始化
git config core.sparseCheckout true
git sparse-checkout init
# 3. 使用 sparse-checkout 拉取指定仓库目录
git sparse-checkout set docs # 只拉取 docs 目录
# 如果是第一次使用 sparse-checkout,还需要执行:
git pull origin master
# 4. 如果还想要拉取其他文件或目录,可使用
git sparse-checkout add README.md
GitHub
对 Github 项目做出贡献
如何对 Github 项目做出贡献?下面举个栗子:
# 克隆项目
git clone https://github.com/tonychacon/blink
# 创建出名称有意义的分支
cd blink
git checkout -b slow-blink
# 修改代码
sed -i '' 's/1000/3000/' blink.ino (macOS)
# 检查改动
git diff --word-diff
# 将改动提交到分支中
git commit -a -m 'three seconds is better'
# 将新分支推送到 GitHub 的副本中
git push origin slow-blink
现在到 GitHub 上查看之前的项目副本,可以看到 GitHub 提示我们有新的分支, 并且显示了一个大大的绿色按钮让我们可以检查我们的改动,并给源项目创建拉取请求。
让你的 Github 仓库保持更新
当你派生了一个 GitHub 仓库之后,你的仓库(即你的“派生”)会独立于原仓库而独立。 特别地,当原仓库有新的提交时,GitHub 会通知你,但你的 GitHub 仓库不会被 GitHub 自动更新,这件事必须由你自己来做:
# 切换到 master
git checkout master
# 抓取更改
git pull https://github.com/progit/progit2.git
# 将 master 分支推送到 origin
git push origin master
这虽然可行,但每次都要输入从哪个 URL 抓取有点麻烦。你可以稍微设置一下来自动完成它:
# 添加源仓库并取一个名字,这里叫它 progit
git remote add progit https://github.com/progit/progit2.git
# 将 master 分支设置为从 progit 远端抓取
git branch --set-upstream-to=progit/master master
# 将默认推送仓库设置为 origin
git config --local remote.pushDefault origin
搞定之后,工作流程为更加简单:
git checkout master
git pull
git push
Git 的数据模型
快照
Git 将顶级目录中的文件和文件夹称作集合,并通过一系列快照来管理历史记录。在 Git 的术语中,文件被称为 blob 对象,也就是一组数据。目录则被称为 tree,可以包含文件和子目录。
<root> (tree)
|
+- foo (tree)
| |
| + bar.txt (blob, contents = "hello world")
|
+- baz.txt (blob, contents = "git is wonderful")
历史记录建模:关联快照
版本控制系统是如何和快照进行关联的呢?线性历史记录是一种最简单的模型,它包含了一组按时间顺序线性排列的快照,但是 git 并没有采用这种模型,在 git 中,历史记录是一个由快照组成的有向无环图:
o <-- o <-- o <-- o
^
\
--- o <-- o
o 表示一次 commit,也就是一次快照。箭头指向了当前 commit 的父辈。在第三次 commit 之后,历史记录分叉成了两条独立的分支,分支开发完成后会合并为一个新的 commit:
o <-- o <-- o <-- o <---- o
^ /
\ v
--- o <-- o
引用
所有快照都可以通过它们的哈希值来标记,但 40 位的十六制字符很难记。针对这个问题,git 的解决方法是给这些哈希值赋予一个可读的名字,也就是引用(reference),引用是指向 commit 的指针,与对象不同,它是可变的,可以被更新,指向新的 commit。通常,master 引用通常会指向主分支的最新一次 commit。
这样,git 就可以使用 “master” 这样容易被记住的名称来表示历史记录中特定的 commit,而不需要再使用一长串的十六进制字符了。
在 Git 中,当前的位置有一个特殊的索引,它就是“HEAD”。
Git 的内容实现
Git 只有两种对象抽象:
- 对象数据库:object database
- 当前目录缓存:current directory cache
Git 的本质就是一系列的文件对象集合,代码文件是对象,文件目录树是对象,commit 也是对象。这些文件对象的名称即内容的 SHA1 值,SHA1 哈希算法的值为 40 位。
对象有三种:BLOB、TREE、CHANGESET。
- BLOB:即二进制对象,这就是 Git 存储的文件,Git 不像某些 VCS (如 SVN)那样存储变更 delta 信息,而是存储文件在每一个版本的完全信息。Linus 在设计时,BLOB 中仅记录文件的内容,而不包含文件名、文件属性等元数据信息,这些信息被记录在第二种对象 TREE 里。
- TREE:目录树对象。在 Linus 的设计里,TREE 对象就是一个时间切片中的目录树信息抽象,包含了文件名、文件属性及 BLOB 对象的 SHA1 值信息,但是没有历史信息,这样设计的好处是可以快速比较两个历史记录的 TREE 对象,不能读取内容,而根据 SHA1 值显示一致和差异的文件。
- CHANGESET:即 Commit 对象。一个 CHANGESET 对象中记录了该次提交的 TREE 对象信息(SHA1),以及提交者(committer)、提交备注(commit message)等信息。
理解了 Git 的三种基本对象,那么对于 Linus 对于 Git 初始设计的“对象数据库”和“当前目录缓存”这两层抽象就很好理解了。加上原本的工作目录,Git 有三层抽象,如下图示:一个是当前工作区(Working Directory),也就是我们查看/编写代码的地方,一个是 Git 仓库(Repository),即 Linus 说的对象数据库,我们在 Git 仓看到的 .git 文件夹中存储的内容,Linus 在第一版设计时命名为 .dircache,在这两个存储抽象中还有一层中间的缓存区(Staging Area),即 .git/index 里存储的信息,我们在执行 git add 命令时,便是将当前修改加入到了缓存区。
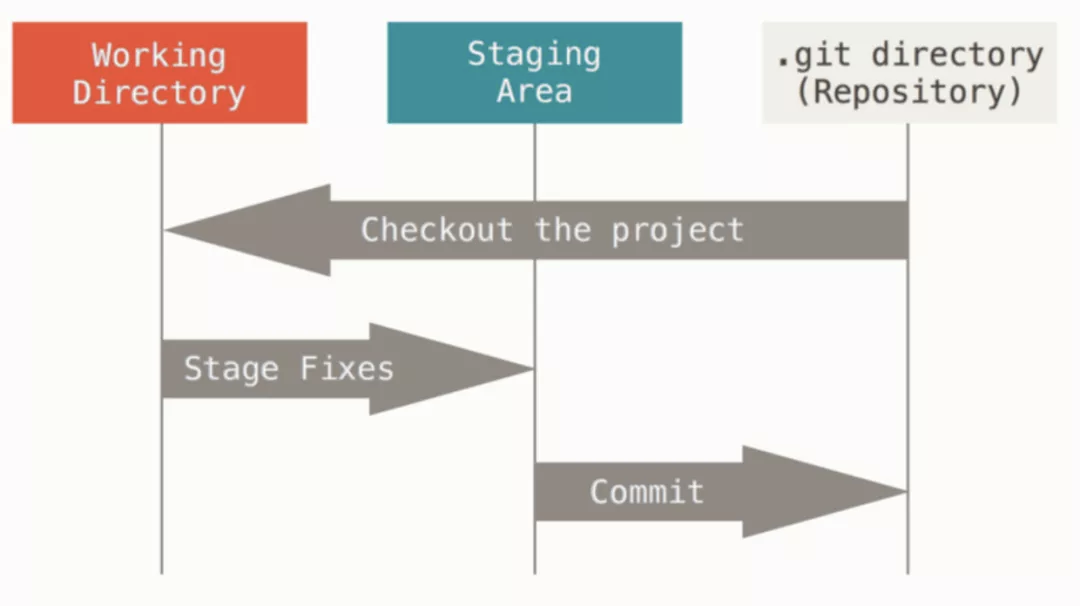
Linus 解释了“当前目录缓存”的设计,该缓存就是一个二进制文件,内容结构很像 TREE 对象,与 TREE 对象不同的是 index 不会再包含嵌套 index 对象,即当前修改目录树内容都在一个 index 文件里。这样设计有两个好处:
- 能够快速的复原缓存的完整内容,即使不小心把当前工作区的文件删除了,也可以从缓存中回复所有文件
- 能够快速找出缓存中和当前工作区内容不一致的文件。
参考资料
- Scott Chacon, Ben Straub:《Pro Git》
- 最简单明了的 Git 教程


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!