FATE 实战
FATE 实战
FATE 实战:纵向联邦学习
数据集预处理
数据集:California 房价预测数据集(内置在 sklearn 库),样本数为 20640,共有 8 个特征
import pandas as pd
from sklearn.datasets import fetch_california_housing
# 数据预处理
california_dataset = fetch_california_housing()
california = pd.DataFrame(california_dataset.data, columns=california_dataset.feature_names)
california = (california-california.mean())/(california.std())
california.head()
col_names = california.columns.values.tolist()
columns = {}
for idx, n in enumerate(col_names):
columns[n] = "x%d"%idx
california = california.rename(columns=columns)
california['y'] = california_dataset.target
california['idx'] = range(california.shape[0])
idx = california['idx']
california.drop(labels=['idx'], axis=1, inplace = True)
california.insert(0, 'idx', idx)
纵向数据切分
切分策略:
- 前 15000 个数据作为训练数据,后 5640 个数据作为测试数据
- 训练数据集切分:随机抽取 12000 条数据和前 4 个特征作为机构 A 的本地数据,随机抽取 13000 条数据和后 4 个特征以及标签作为机构 B 的本地数据
- 测试数据集切分:随机抽取 3600 条数据和前 4 个特征作为机构 A 的本地测试数据,随机抽取 3800 条数据和后 4 个特征以及标签作为机构 B 的本地测试数据
# 切分训练数据
train = california.iloc[:15000]
df1 = train.sample(12000)
df2 = train.sample(13000)
housing_1_train = df1[["idx", "x0", "x1", "x2", "x3"]]
housing_1_train.to_csv('data/house/housing_1_train.csv', index=False, header=True)
housing_2_train = df2[["idx", "y", "x4", "x5", "x6", "x7"]]
housing_2_train.to_csv('data/house/housing_2_train.csv', index=False, header=True)
# 切分测试数据
eval = california.iloc[15000:]
df1 = eval.sample(3600)
df2 = eval.sample(3800)
housing_1_eval = df1[["idx", "x0", "x1", "x2", "x3"]]
housing_1_eval.to_csv('data/house/housing_1_eval.csv', index=True, header=True)
housing_2_eval = df2[["idx", "y", "x4", "x5", "x6", "x7"]]
housing_2_eval.to_csv('data/house/housing_2_eval.csv', index=True, header=True)
通过 dsl 和 conf 运行训练和预测任务
准备工作
- 启动容器,进行目录挂载
docker run -it --name standalone_fate -p 8080:8080 -v ${本机地址}:${Docker内地址} federatedai/standalone_fate:1.8.0
# 例如
docker run -it --name standalone_fate -p 8080:8080 -v D:\Dropbox\学习计划\FATE\data\house:/workspace federatedai/standalone_fate:1.8.0
- 进入容器
docker exec -it standalone_fate /bin/bash
- 在容器内进入挂载地址
cd /workspace
数据上传
我们需要在本机的挂载目录下新建如下四个文件,文件会自动同步到 Docker:
upload_train_host_conf.json:上传训练数据至机构 1
{
"file": "housing_1_train.csv",
"table_name": "homo_housing_1_train",
"namespace": "homo_host_housing_train",
"head": 1,
"partition": 16,
"work_mode": 0,
"backend": 0
}
upload_train_guest_conf.json:上传训练数据至机构 2
{
"file": "housing_2_train.csv",
"table_name": "homo_housing_2_train",
"namespace": "homo_guest_housing_train",
"head": 1,
"partition": 16,
"work_mode": 0,
"backend": 0
}
upload_eval_host_conf.json:上传测试数据至机构 1
{
"file": "housing_1_eval.csv",
"table_name": "homo_housing_1_eval",
"namespace": "homo_host_housing_eval",
"head": 1,
"partition": 16,
"work_mode": 0,
"backend": 0
}
upload_eval_guest_conf.json:上传测试数据至机构 2`
{
"file": "housing_2_eval.csv",
"table_name": "homo_housing_2_eval",
"namespace": "homo_guest_housing_eval",
"head": 1,
"partition": 16,
"work_mode": 0,
"backend": 0
}
- 上传数据:在 bash 界面右键可粘贴命令
flow init --ip 127.0.0.1 --port 9380
flow data upload -c upload_train_host_conf.json
flow data upload -c upload_train_guest_conf.json
flow data upload -c upload_eval_host_conf.json
flow data upload -c upload_eval_guest_conf.json
模型训练
与横向联邦学习相比较,纵向联邦学习需要进行样本对齐,即在不泄露双方数据的前提下,求取出双方用户的交集,从而确定模型训练的训练数据集。
- 在本机的挂载目录下新建
hetero_linr_train_job_dsl.json,内容模板在data/projects/fate/examples/dsl/v2/hetero_linear_regression/test_hetero_linr_train_job_dsl.json,增加evaluation_0组件-
reader_0:数据读取组件,支持图像数据 -
data_transform_0:数据 IO 组件 -
intersection_0:样本对齐组件 -
hetero_linr_0:纵向线性回归模型组件 -
evaluation_0:模型评估组件
-
{
"components": {
"reader_0": {
"module": "Reader",
"output": {
"data": ["data"]
}
},
"data_transform_0": {
"module": "DataTransform",
"input": {
"data": {
"data": ["reader_0.data"]
}
},
"output": {
"data": ["data"],
"model": ["model"]
}
},
"intersection_0": {
"module": "Intersection",
"input": {
"data": {
"data": ["data_transform_0.data"]
}
},
"output": {
"data": ["data"]
}
},
"hetero_linr_0": {
"module": "HeteroLinR",
"input": {
"data": {
"train_data": ["intersection_0.data"]
}
},
"output": {
"data": ["data"],
"model": ["model"]
}
},
"evaluation_0": {
"module": "Evaluation",
"input": {
"data": {
"data": ["hetero_linr_0.data"]
}
},
"output": {
"data": ["data"]
}
}
}
}
- 在本机的挂载目录下新建
hetero_linr_train_job_conf.json,内容模板在data/projects/fate/examples/dsl/v2/hetero_linear_regression/test_hetero_linr_train_job_conf.json,需要修改- 修改 party ID 为对应 ID
- 指定数据对应上传数据时的设置
- 修改 label_name
- 设置模型参数
- 设置 evaluation_0 相关参数
{
"dsl_version": 2,
"initiator": {
"role": "guest",
"party_id": 10000
},
"role": {
"arbiter": [10000],
"host": [10000],
"guest": [10000]
},
"component_parameters": {
"common": {
"hetero_linr_0": {
"penalty": "L2",
"tol": 0.001,
"alpha": 0.01,
"optimizer": "sgd",
"batch_size": -1,
"learning_rate": 0.15,
"init_param": {
"init_method": "zeros"
},
"max_iter": 20,
"early_stop": "weight_diff",
"decay": 0.0,
"decay_sqrt": false,
"floating_point_precision": 23
},
"evaluation_0": {
"eval_type": "regression",
"pos_label": 1
}
},
"role": {
"host": {
"0": {
"reader_0": {
"table": {
"name": "homo_housing_1_train",
"namespace": "homo_host_housing_train"
}
},
"data_transform_0": {
"with_label": false
}
}
},
"guest": {
"0": {
"reader_0": {
"table": {
"name": "homo_housing_2_train",
"namespace": "homo_guest_housing_train"
}
},
"data_transform_0": {
"with_label": true,
"label_name": "y",
"label_type": "float",
"output_format": "dense"
}
}
}
}
}
}
- 提交任务:
flow job submit -c ${conf_path} -d ${dsl_path}
flow job submit -c hetero_linr_train_job_conf.json -d hetero_linr_train_job_dsl.json
- 在
arbiter节点中查看训练过程中 loss 的变化
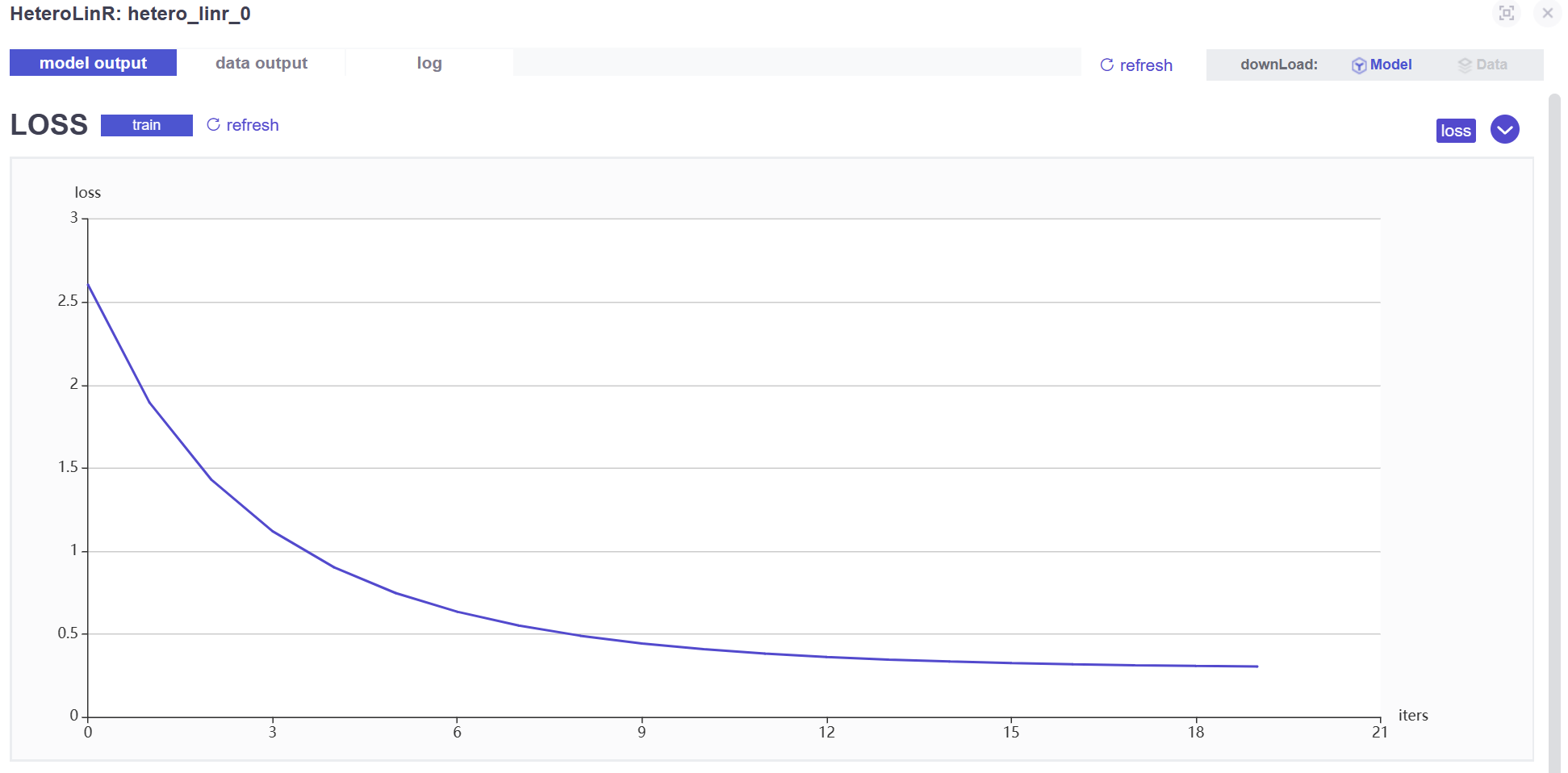
- 在 guest 节点中查看模型在训练数据上的效果

模型评估
在模型评估阶段,官方提供的配置文件示例在
data/projects/fate/examples/dsl/v1/hetero_linear_regression/test_hetero_linr_validate_job_dsl.jsondata/projects/fate/examples/dsl/v1/hetero_linear_regression/test_hetero_linr_validate_job_conf.json
与训练阶段的操作类似,我们需要对配置文件进行修改:
- 在本机的挂载目录下新建
hetero_linr_validate_job_dsl.json,增加evaluation_0组件
"evaluation_0": {
"module": "Evaluation",
"input": {
"data": {
"data": ["hetero_linr_0.data"]
}
}
}
- 在本机的挂载目录下新建
hetero_linr_validate_job_conf.json,内容修改- 修改 party ID
- 修改数据源,修改 label_name
- 设置 evaluation_0 组件的参数
- 设置模型参数
{
"dsl_version": 2,
"initiator": {
"role": "guest",
"party_id": 10000
},
"role": {
"arbiter": [
10000
],
"host": [
10000
],
"guest": [
10000
]
},
"component_parameters": {
"common": {
"hetero_linr_0": {
"penalty": "L2",
"tol": 0.001,
"alpha": 0.01,
"optimizer": "sgd",
"batch_size": -1,
"learning_rate": 0.15,
"init_param": {
"init_method": "zeros"
},
"max_iter": 20,
"early_stop": "weight_diff",
"decay": 0.0,
"decay_sqrt": false,
"callback_param": {
"callbacks": [
"EarlyStopping",
"PerformanceEvaluate"
],
"validation_freqs": 1,
"early_stopping_rounds": 5,
"metrics": [
"mean_absolute_error",
"root_mean_squared_error"
],
"use_first_metric_only": false,
"save_freq": 1
}
},
"evaluation_0": {
"eval_type": "regression",
"pos_label": 1
}
},
"role": {
"host": {
"0": {
"data_transform_0": {
"with_label": false
},
"reader_0": {
"table": {
"name": "homo_housing_1_train",
"namespace": "homo_host_housing_train"
}
},
"reader_1": {
"table": {
"name": "homo_housing_1_eval",
"namespace": "homo_host_housing_eval"
}
},
"data_transform_1": {
"with_label": false
}
}
},
"guest": {
"0": {
"data_transform_0": {
"with_label": true,
"label_name": "y",
"label_type": "float",
"output_format": "dense"
},
"reader_0": {
"table": {
"name": "homo_housing_2_train",
"namespace": "homo_guest_housing_train"
}
},
"reader_1": {
"table": {
"name": "homo_housing_2_eval",
"namespace": "homo_guest_housing_eval"
}
},
"data_transform_1": {
"with_label": true,
"label_name": "y",
"label_type": "float",
"output_format": "dense"
}
}
}
}
}
}
- 提交任务:
flow job submit -c ${conf_path} -d ${dsl_path}
flow job submit -c hetero_linr_validate_job_conf.json -d hetero_linr_validate_job_dsl.json
- 查看 DAG 图
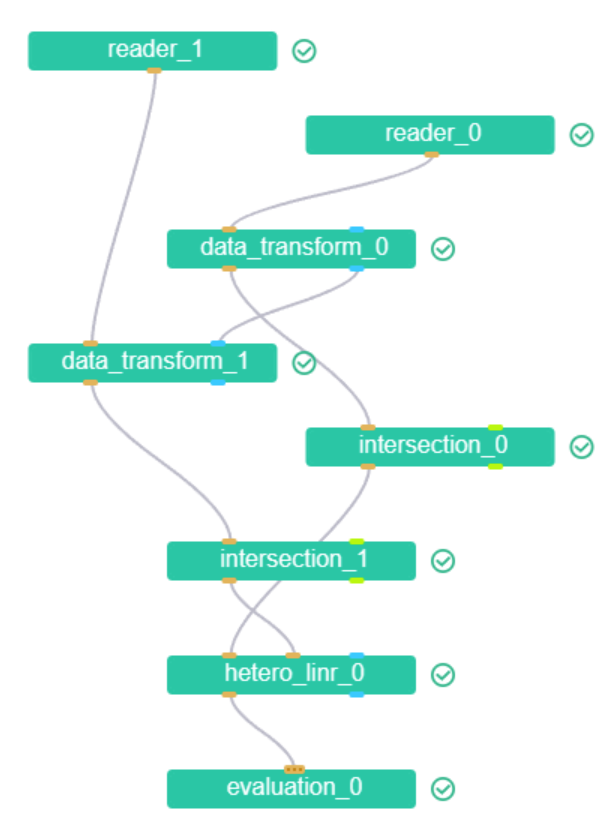
- 查看模型效果

