
python爬虫案例:使用XPath爬网页图片
用XPath来做一个简单的爬虫,尝试爬取某个贴吧里的所有帖子,并且将该这个帖子里每个楼层发布的图片下载到本地。
# -*- coding:utf-8 -*- import urllib import urllib2 from lxml import etree def loadPage(url): """ 作用:根据url发送请求,获取服务器响应文件 url: 需要爬取的url地址 """ #print url #headers = {"User-Agent" : "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11"} request = urllib2.Request(url) html = urllib2.urlopen(request).read() # 解析HTML文档为HTML DOM模型 content = etree.HTML(html) #print content # 返回所有匹配成功的列表集合 link_list = content.xpath('//div[@class="t_con cleafix"]/div/div/div/a/@href') #link_list = content.xpath('//a[@class="j_th_tit"]/@href') for link in link_list: fulllink = "http://tieba.baidu.com" + link # 组合为每个帖子的链接 #print link loadImage(fulllink) # 取出每个帖子里的每个图片连接 def loadImage(link): headers = {"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"} request = urllib2.Request(link, headers = headers) html = urllib2.urlopen(request).read() # 解析 content = etree.HTML(html) # 取出帖子里每层层主发送的图片连接集合 #link_list = content.xpath('//img[@class="BDE_Image"]/@src') # link_list = content.xpath('//div[@class="post_bubble_middle"]') link_list = content.xpath('//img[@class="BDE_Image"]/@src') # 取出每个图片的连接 for link in link_list: # print link writeImage(link) def writeImage(link): """ 作用:将html内容写入到本地 link:图片连接 """ #print "正在保存 " + filename headers = {"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"} # 文件写入 request = urllib2.Request(link, headers = headers) # 图片原始数据 image = urllib2.urlopen(request).read() # 取出连接后10位做为文件名 filename = link[-10:] # 写入到本地磁盘文件内 with open(filename, "wb") as f: f.write(image) print "已经成功下载 "+ filename def tiebaSpider(url, beginPage, endPage): """ 作用:贴吧爬虫调度器,负责组合处理每个页面的url url : 贴吧url的前部分 beginPage : 起始页 endPage : 结束页 """ for page in range(beginPage, endPage + 1): pn = (page - 1) * 50 #filename = "第" + str(page) + "页.html" fullurl = url + "&pn=" + str(pn) #print fullurl loadPage(fullurl) #print html print "谢谢使用" if __name__ == "__main__": kw = raw_input("请输入需要爬取的贴吧名:") beginPage = int(raw_input("请输入起始页:")) endPage = int(raw_input("请输入结束页:")) url = "http://tieba.baidu.com/f?" key = urllib.urlencode({"kw": kw}) fullurl = url + key tiebaSpider(fullurl, beginPage, endPage)
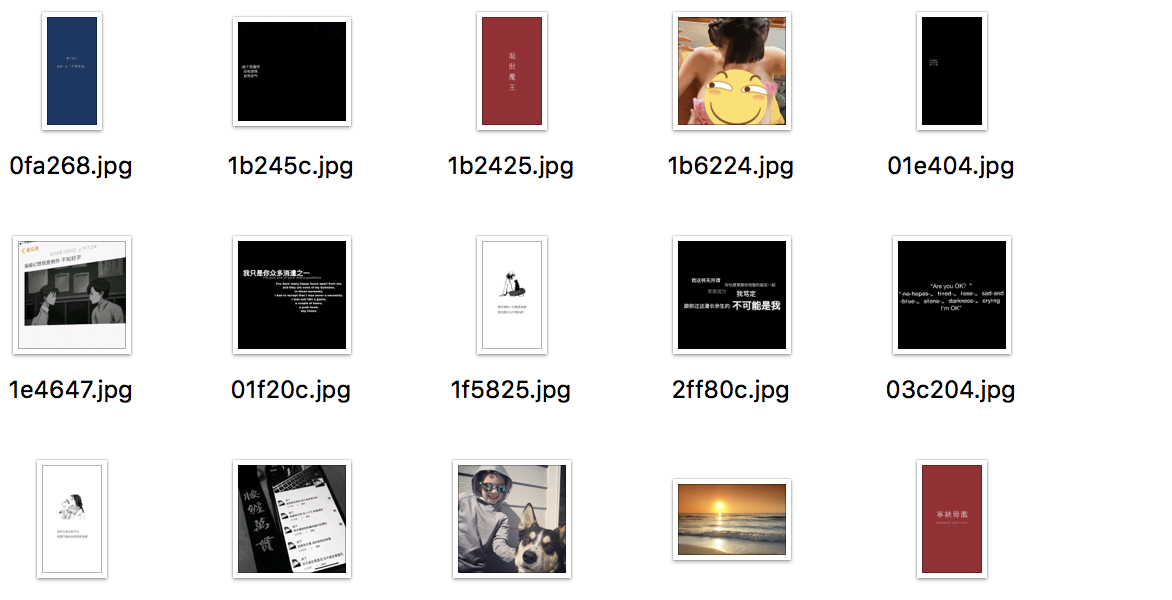
效果:
最后,关注【码上加油站】微信公众号后,有疑惑有问题想加油的小伙伴可以码上加入社群,让我们一起码上加油吧!!!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号