

Redis中的数据结构
一、字符串结构SDS
struct sdshdr{
int len;
int free; //记录buf中未使用的字节数
char buf[];
}
相比普通字符串数组的优点:
-
可以O(1)获取字符串长度
-
不用担心缓冲区buf会溢出(有扩容机制)
-
扩容机制(内存重分配)
每次重分配时会预留
free=min(len,1MB)的空间,便于下次使用 -
二进制安全,可以保存二进制数据(图片等文件)
因为不用担心文件中出现'\0',而使字符串的读取提前结束
-
可以使用部分
<string.h>里的函数
二、字典
Redis的数据库和哈希键的底层均是由字典实现
使用纯hash表实现,链地址法解决冲突
hash算法:hashcode & (size-1)
rehash:
-
在hash表头中有个字段trehashidx表示是否处于rehash状态
-
rehash策略:
在表头中有两个指向hash表的指针,一般情况下,ht[0]指向要使用的表,ht[1]指向一个空表。
rehash时,将ht[0]的数据rehash到ht[1]上,结束后,又将ht[0]指向ht[1],ht[1]指向一个新建的空表。
-
渐进式rehash:
即rehash操作不立马执行,而是在查询ht[0]过程中,顺便将走过的节点rehash到ht[1]上,增加节点则直接在ht[1]表上增加,这里就是字段trehashidx的用法了,当然,如果在rehash状态下,在ht[0]中没有查询到数据,则去ht[1]中查询。
三、跳跃表
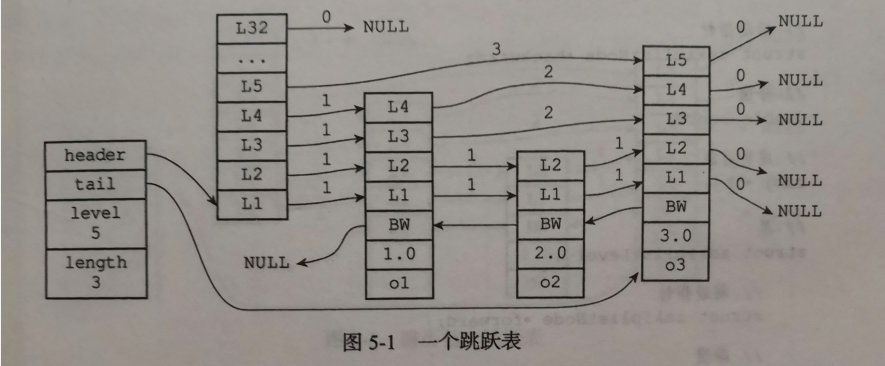
如图所示,由一个单链表扩展成多层链表就是跳跃表了。
给每个节点设一个表示“层”的指针数组,指向同层次的下一个节点,也就是说同一层即为一个链表。
每一层的层数是随机的,随机策略类似为能连续扔多少次硬币都是正面,这也就使层数平均在logN层。
又可以知道高层指向的节点的距离肯定大于等于低层,所以查询策略是:
- 先对层进行二分处理,找一个小于等于查询数的,然后”跳跃“过去,重复这个步骤。。
插入和删除操作?
