一、网站视屏的流程
1、 <video src="不能播的视频。mp4"></vide0>,视屏小可以这样
2、视屏文件大,就进行切片
3、用户上传->转码(把视频做处理,2K, 1080, 标清) ->切片处理(把单个的文件进行拆分)
4、用户在进行拉动进度条的时候,就是拉倒对应的切片
5、需要一个文件记录: 1,视频播放顺序,2.视频存放的路径。
6、M3U8,是最后我们能看懂的编码是utf-8,MU3加上一个8
7、想要抓取一个视频:
1.找到m3u8 (各种手段)
2.通过m3u8下载到ts文件
3.可以通过各种手段(不仅是编程手段)把ts文件合并为一个mp4文件
二、爬取视频
1、我们要爬取的视屏设置了反爬机制,我们分析下
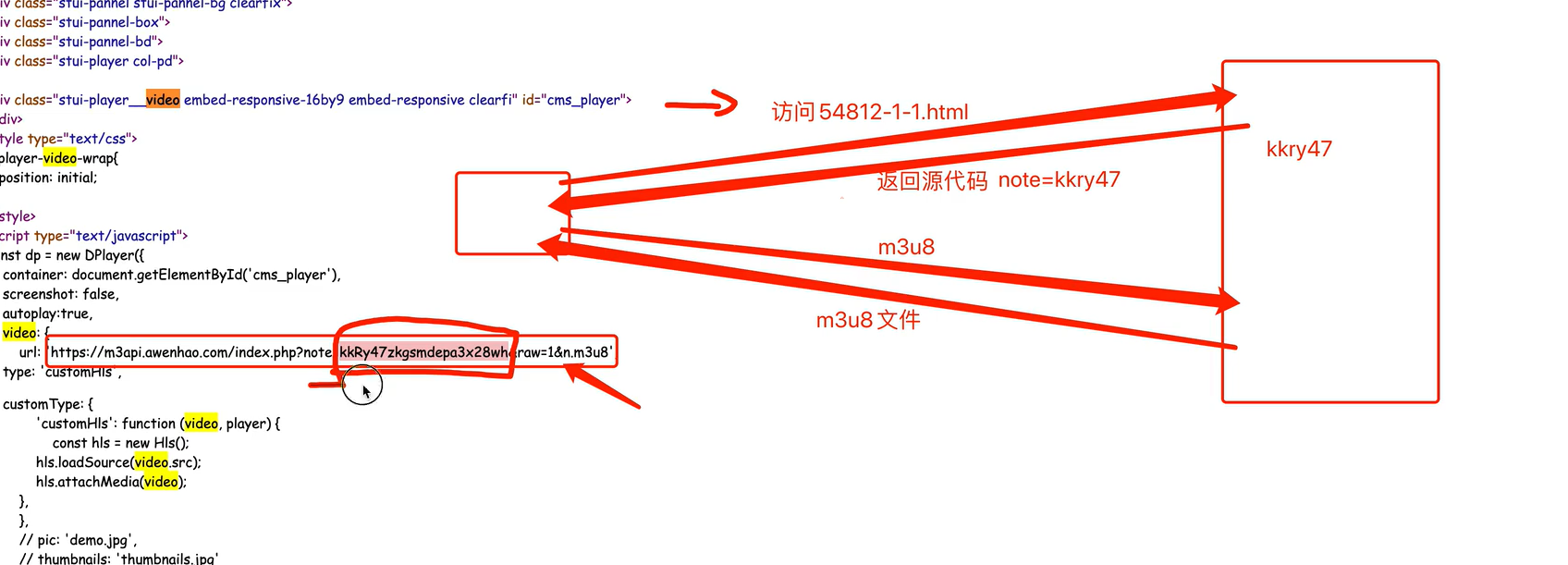
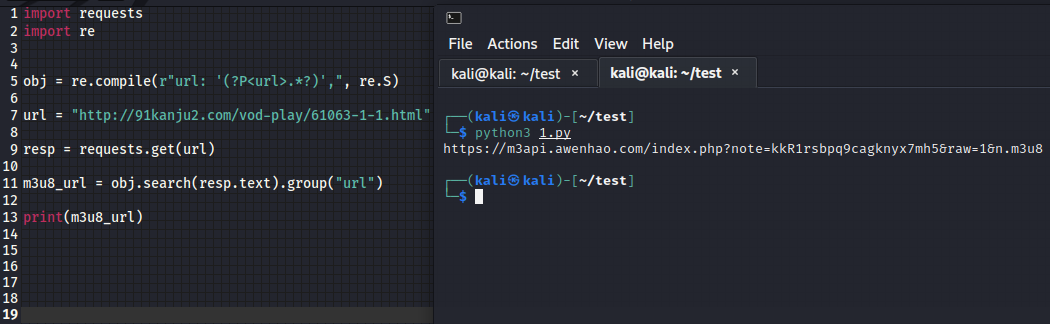
2、获取m3u8文件的网址
import requests
import re
# 因为需要的网址在<script type="text/javascript">标签里,所以用正则匹配
obj = re.compile(r"url: '(?P<url>.*?)',", re.S)
# 要爬取视屏的播放页面
url = "http://91kanju2.com/vod-play/61063-1-1.html"
resp = requests.get(url)
# 获取m3u8
m3u8_url = obj.search(resp.text).group("url")
resp.close()
print(m3u8_url)
3、下载m3u8文件
import requests
import re
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36 Edg/95.0.1020.40",
}
obj = re.compile(r"url: '(?P<url>.*?)',", re.S)
url = "http://91kanju2.com/vod-play/61063-1-1.html"
resp = requests.get(url)
m3u8_url = obj.search(resp.text).group("url")
resp.close()
#下载m3u8文件
resp2 = requests.get(m3u8_url, headers = headers)
with open("北海屠龙记.m3u8", mode="wb") as f:
f.write(resp2.content)
resp2. close()
print("下载完毕")
4、解析m3u8文件并下载视屏切片
import requests
n = 1
with open("北海屠龙记.m3u8", mode="r" , encoding="utf-8") as f:
for line in f:
line = line.strip()
#先去掉空格,空白,换行符
if line.startswith("#"): # 如果以#开头。我不要
continue
#下载视频片段
resp3 = requests.get(line)
f = open(f"{n}.ts",mode="wb")
f.write(resp3.content)
f.close()
resp3.close()
n += 1
5、全部代码
import requests
import re
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36 Edg/95.0.1020.40",
}
obj = re.compile(r"url: '(?P<url>.*?)',", re.S)
url = "http://91kanju2.com/vod-play/61063-1-1.html"
resp = requests.get(url)
m3u8_url = obj.search(resp.text).group("url")
resp.close()
#下载m3u8文件
resp2 = requests.get(m3u8_url, headers = headers)
with open("北海屠龙记.m3u8", mode="wb") as f:
f.write(resp2.content)
resp2. close()
print("下载完毕")
n = 1
with open("北海屠龙记.m3u8", mode="r" , encoding="utf-8") as f:
for line in f:
line = line.strip()
#先去掉空格,空白,换行符
if line.startswith("#"): # 如果以#开头。我不要
continue
#下载视频片段
resp3 = requests.get(line)
f = open(f"{n}.ts",mode="wb")
f.write(resp3.content)
f.close()
resp3.close()
n += 1

 浙公网安备 33010602011771号
浙公网安备 33010602011771号