异步协程请求
一、异步协程请求
import asyncio
import aiohttp
urls = [
"http://kr.shanghai-jiuxin.com/file/2020/1031/774218be86d832f359637ab120eba52d.jpg",
"http://kr.shanghai-jiuxin.com/file/2020/1031/small563337d07af599a9ea64e620729f367e.jpg",
"http://kr.shanghai-jiuxin.com/file/2020/1031/smalld9c15f81eb732fb2f0087d6141472770.jpg"
]
async def aiodownload(url):
name = url.rsplit("/", 1)[1]
# aiohttp.ClientSession()就相当于requests
async with aiohttp.ClientSession() as session:
# session.get()相当于requests.get()
async with session.get(url) as resp:
#请求回来了。写入文件
with open(name, mode="wb") as f:
f .write (await resp.content.read())
async def main():
tasks = []
for url in urls:
tasks.append(asyncio.create_task(aiodownload(url)))
await asyncio.wait(tasks)
if __name__ == '__main__' :
asyncio.run(main())
二、爬取小说
1、目标网址http://dushu.baidu.com/pc/detail?gid=%204306063500
2、分析页面,二次请求
目标网址http://dushu.baidu.com/api/pc/getCatalog?data={%22book_id%22:%22%204306063500%22}
其中%22是"
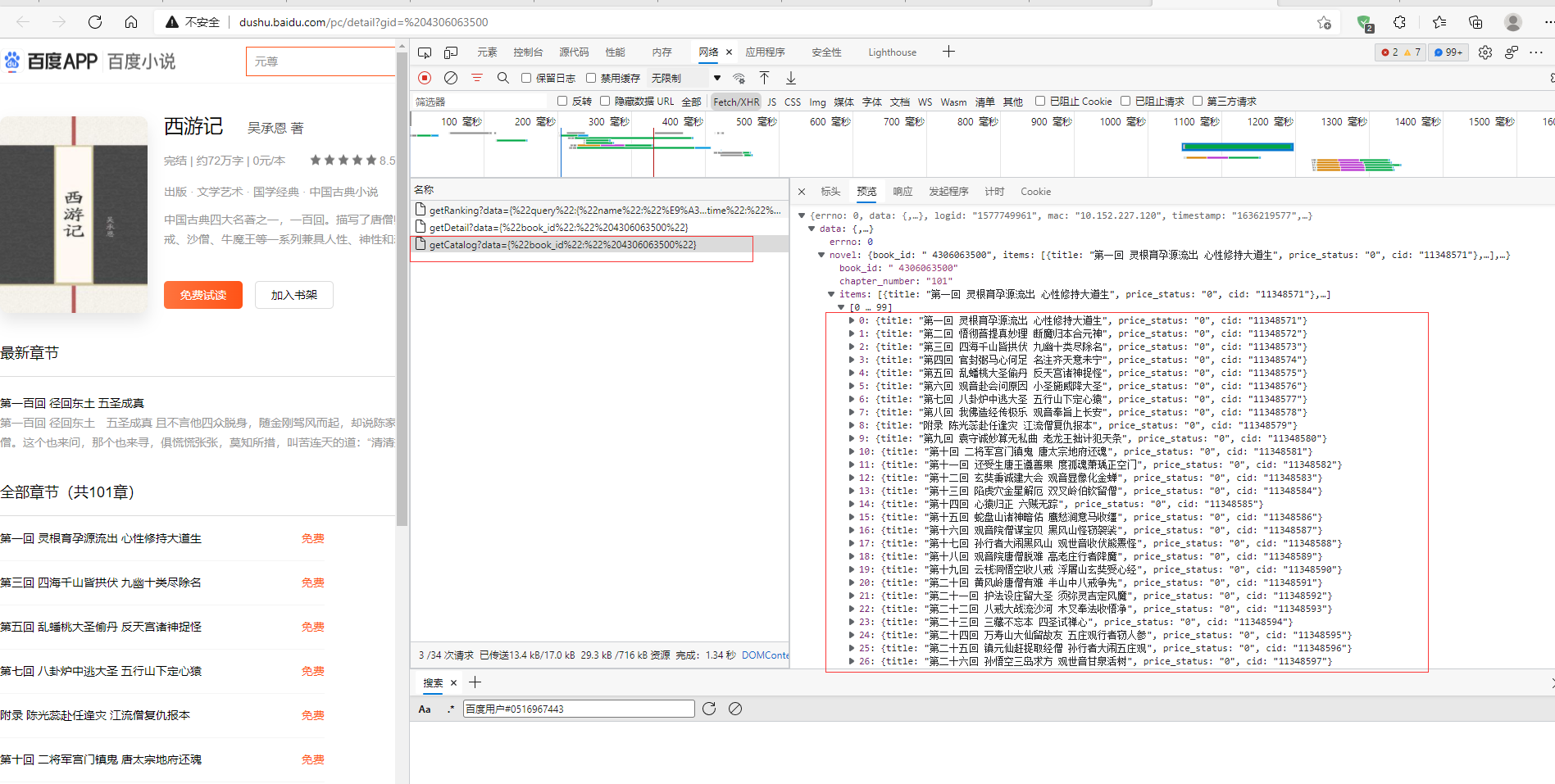
3、我们需要爬取的页面
网址是http://dushu.baidu.com/api/pc/getChapterContent?data={%22book_id%22:%22%204306063500%22,%22cid%22:%22%204306063500|11348571%22,%22need_bookinfo%22:1}
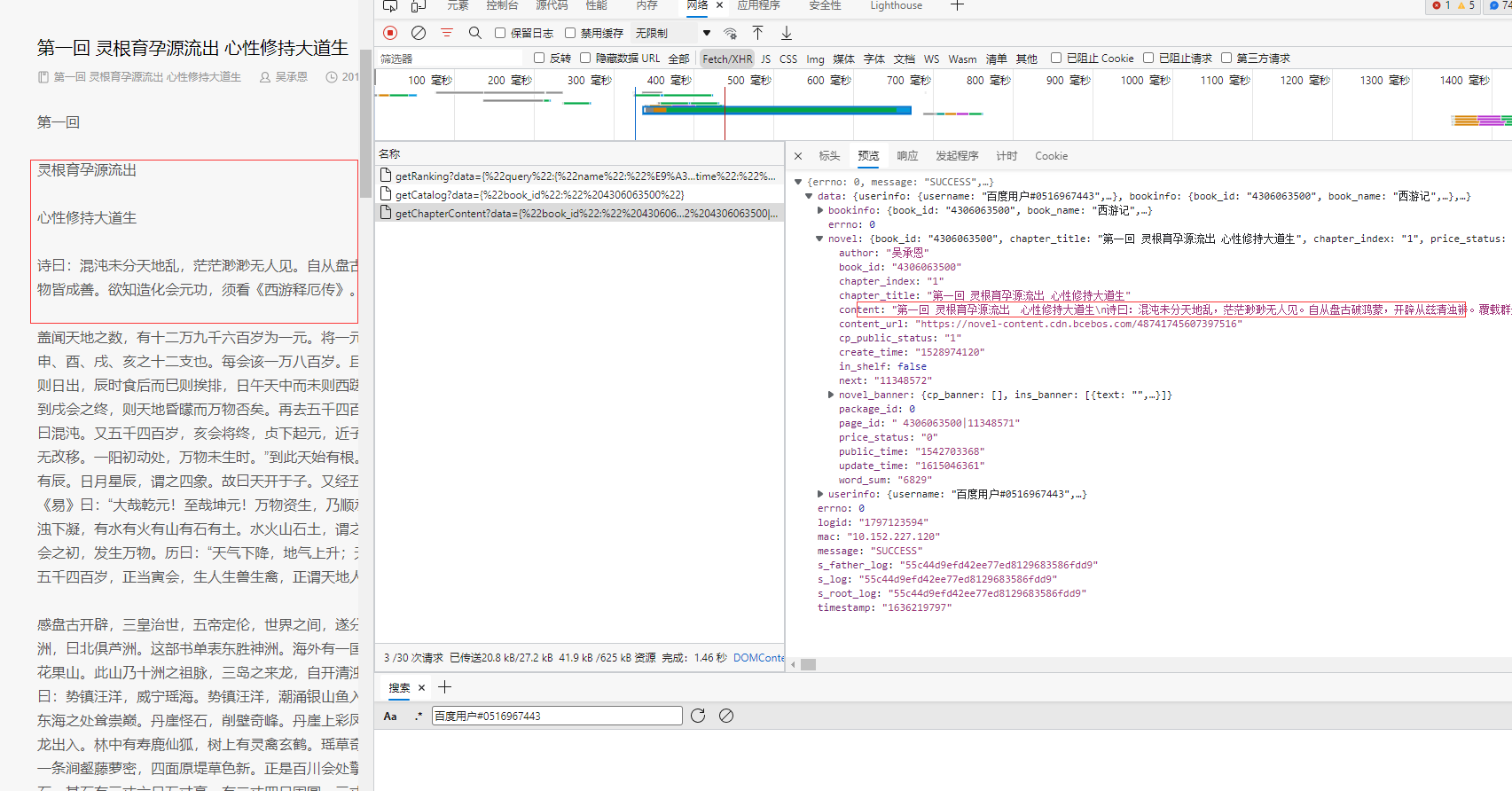
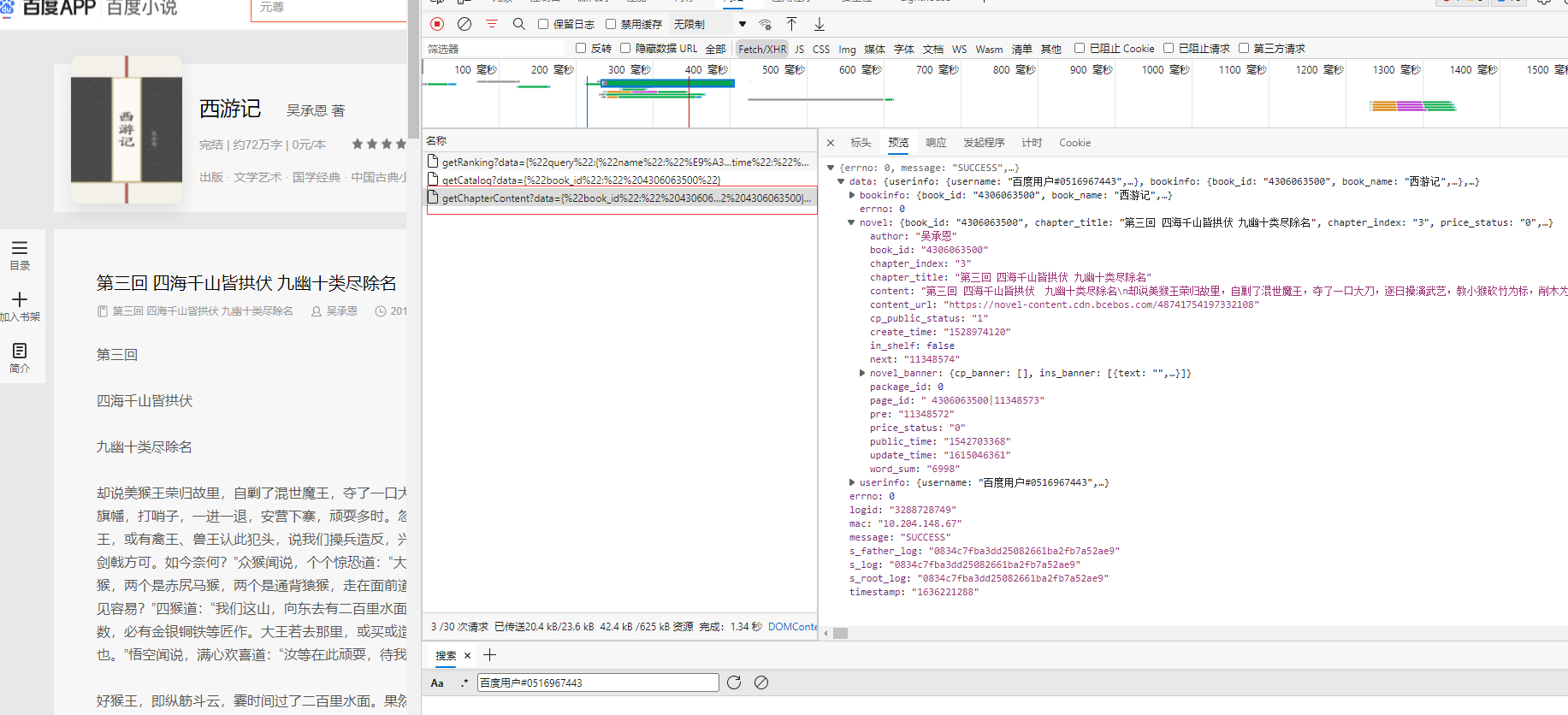
4、分析网址
多看几个页面发现就只有一个cid不同,其他的都一样
5、写代码
import asyncio
import aiohttp
import requests
import json
import aiofiles
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36 Edg/95.0.1020.40",
}
async def aiodownload(cid, b_id , title):
data = {
"book_id": b_id,
"cid":f"{b_id}|{cid}",
"need_ bookinfo":1
}
data = json.dumps(data)
urt = f"http://dushu.baidu.com/api/pc/getChapterContent?data={data}"
async with aiohttp.ClientSession() as session:
async with session.get(urt) as resp:
dic = await resp.json()
async with aiofiles.open(title, mode="w", encoding="utf-8") as f:
await f.write(dic['data']['novel']['content']) # 把小说内容写出
async def getCatalog(url):
resp = requests.get(url)
dic = resp.json()
tasks = []
for item in dic['data']['novel']['items']: # item就是对应每一个章节的名称和cid
title = item['title']
cid = item['cid']
#准备异步任务
tasks.append(asyncio.create_task(aiodownload(cid, b_id, title)))
# 启动协程
await asyncio.wait(tasks)
resp.close()
if __name__ == '__main__' :
b_id ="4306063500"
url = 'http://dushu.baidu.com/api/pc/getCatalog?data={"book_id":"' + b_id + '"}'
asyncio.run(getCatalog(url))
三、爬取视屏
import requests
import re
import asyncio
import aiohttp
import aiofiles
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36 Edg/95.0.1020.40",
}
# 协程下载m3u8
async def download_ts(url,name,session) :
async with session.get(url) as resp:
async with aiofiles.open(f"test/{name}", mode ="wb") as f:
await f.write(await resp.content.read())
#把下载到的内容写入到文件中
print(f"{name}下载完毕")
async def aio_download():
tasks=[]
async with aiohttp.ClientSession() as session:
async with aiofiles.open("test.m3u8", mode="r", encoding= 'utf-8' ) as f:
async for line in f:
if line.startswith("#"):
continue
line = line.strip()
name = line.split('/')[-1]
tasks.append(asyncio.create_task(download_ts(line,name,session)))
await asyncio.wait(tasks)
def main():
url = "https://vod2.bdzybf2.com/20201025/xCvoYyJb/1000kb/hls/index.m3u8"
resp = requests.get(url, headers = headers)
with open("test.m3u8", mode="wb") as f:
f.write(resp.content)
asyncio.run(aio_download())
if __name__ == '__main__' :
main()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号