一、步骤
- 定位到2021必看片
- 从2021必看片中提取到子页面的链接地址
- 请求子页面的链接地址。拿到我们想要的下载地址....
二、代码
1、获取页面信息
import requests
import re
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36 Edg/95.0.1020.40"
}
url = "https://dytt89.com"
# verify=False 去掉安全验证
resp = requests.get(url,headers=headers,verify=False)
# 指定字符集
resp.encoding = 'gbk'
print(resp.text)
resp.close()
2、获取子页面链接
import requests
import re
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36 Edg/95.0.1020.40"
}
url = "https://dytt89.com"
resp = requests.get(url,headers=headers,verify=False)
resp.encoding = 'gbk'
# 匹配子页面链接的标签的正则
obj1 = re.compile(r'2021必看热片.*?<ul>(?P<ul>.*?)</ul>',re.S)
# 匹配子页面链接的正则
obj2 = re.compile(r"<a href='(?P<href>.*?)'",re.S)
result1 = obj1.finditer(resp.text)
for i in result1:
ul = i.group('ul')
# 提取子页面链接
result2 = obj2.finditer(ul)
for j in result2:
print(j.group('href'))
resp.close()

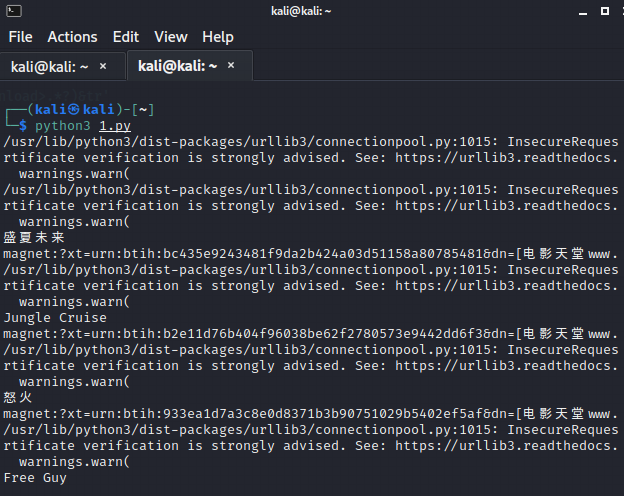
3、提取数据
import requests
import re
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36 Edg/95.0.1020.40"
}
url = "https://dytt89.com"
resp = requests.get(url,headers=headers,verify=False)
resp.encoding = 'gbk'
obj1 = re.compile(r'2021必看热片.*?<ul>(?P<ul>.*?)</ul>',re.S)
obj2 = re.compile(r"<a href='(?P<href>.*?)'",re.S)
obj3 = re.compile(
r'◎片 名(?P<movie>.*?)<br />.*?'
r'<td style="WORD-WRAP: break-word" bgcolor="#fdfddf"><a href="(?P<download>.*?)&tr'
,re.S)
result1 = obj1.finditer(resp.text)
# 定义一个列表存储子页面链接
Child_Href_list = []
for i in result1:
ul = i.group('ul')
result2 = obj2.finditer(ul)
for j in result2:
# 获取完整的子页面链接
Child_Href = url + j.group('href')
# 将链接添加到列表中
Child_Href_list.append(Child_Href)
for k in Child_Href_list:
Child_Resp = requests.get(k,headers=headers,verify=False)
Child_Resp.encoding = 'gbk'
# 提取电影名和种子
result3 = obj3.search(Child_Resp.text)
print(result3.group('movie').strip())
print(result3.group('download'))
resp.close()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号