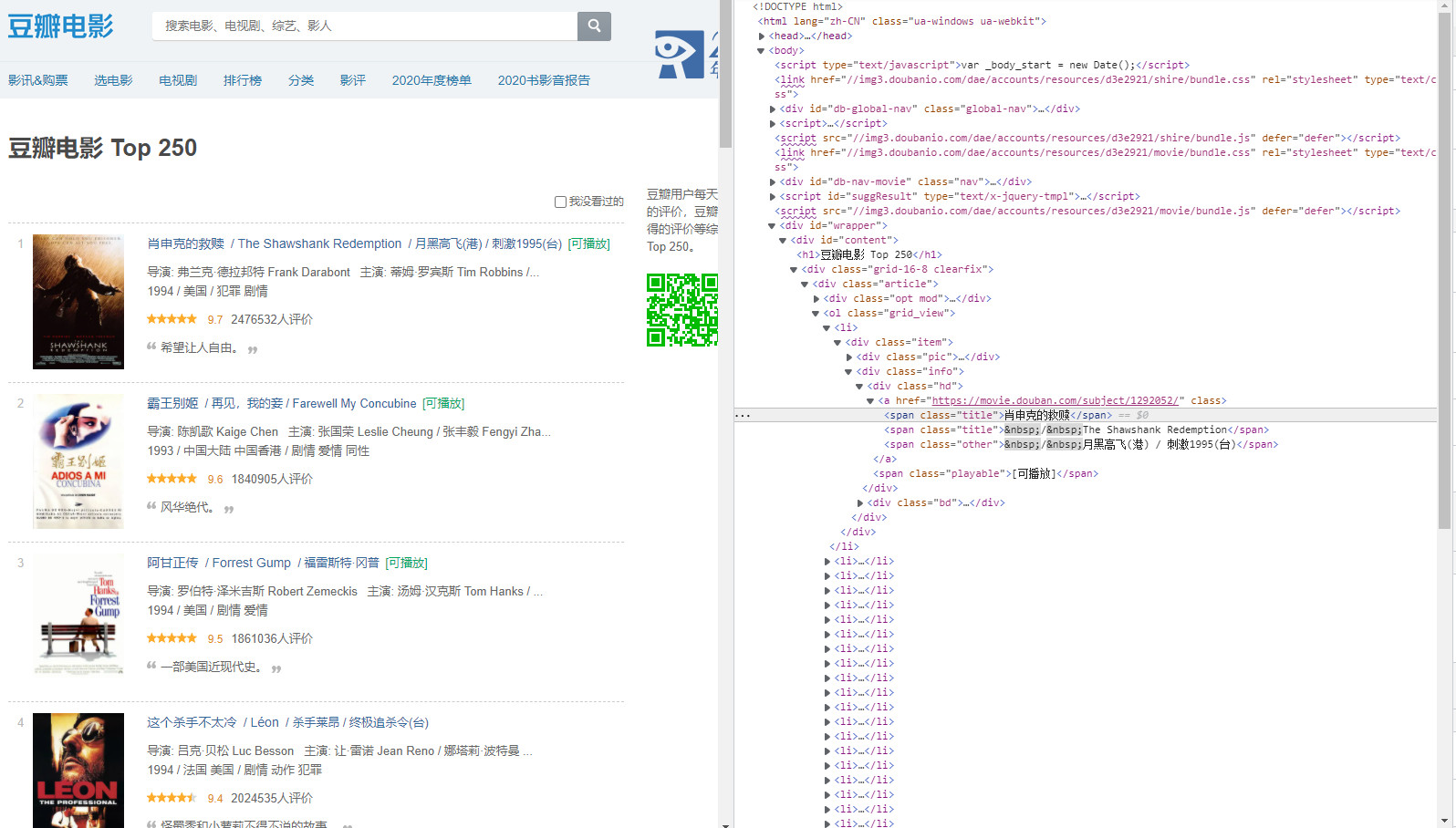
一、电影名字爬取
import requests
import re
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36 Edg/95.0.1020.40"
}
url = "https://movie.douban.com/top250"
# 获取html页面
resp = requests.get(url,headers=headers)
page_contenr = resp.text
# 解析数据
obj = re.compile(r'<li>.*?<span class="title">(?P<name>.*?)</span>',re.S)
# 开始匹配
result = obj.finditer(page_contenr)
for i in result:
print(i.group("name"))
resp.close()

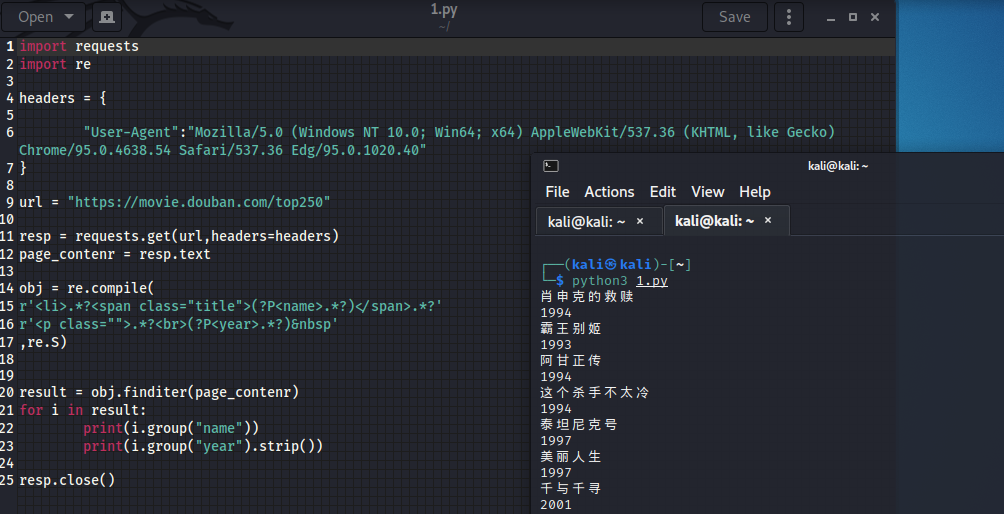
二、爬取年份
import requests
import re
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36 Edg/95.0.1020.40"
}
url = "https://movie.douban.com/top250"
resp = requests.get(url,headers=headers)
page_contenr = resp.text
obj = re.compile(
# 一行写不下时,换行接着写
r'<li>.*?<span class="title">(?P<name>.*?)</span>.*?'
r'<p class="">.*?<br>(?P<year>.*?) '
,re.S)
result = obj.finditer(page_contenr)
for i in result:
print(i.group("name"))
# strip()去除空格
print(i.group("year").strip())
resp.close()
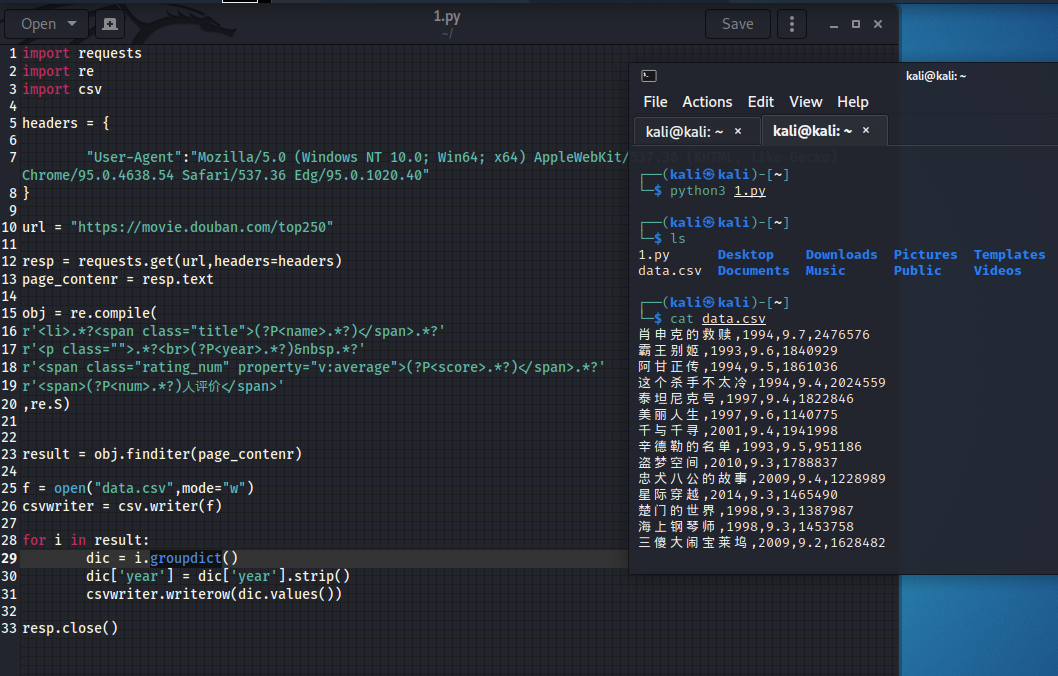
三、将数据存入csv中
import requests
import re
import csv
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36 Edg/95.0.1020.40"
}
url = "https://movie.douban.com/top250"
resp = requests.get(url,headers=headers)
page_contenr = resp.text
obj = re.compile(
r'<li>.*?<span class="title">(?P<name>.*?)</span>.*?'
r'<p class="">.*?<br>(?P<year>.*?) .*?'
r'<span class="rating_num" property="v:average">(?P<score>.*?)</span>.*?'
r'<span>(?P<num>.*?)人评价</span>'
,re.S)
result = obj.finditer(page_contenr)
# 写的模式打开一个文件
f = open("data.csv",mode="w")
# csv一种以逗号分隔按行存储的文本文件,csv方式写入
csvwriter = csv.writer(f)
for i in result:
# 将结果变为字典型
dic = i.groupdict()
# 其中key为year的结果前有大量空格,将空格删除后的结果赋给year
dic['year'] = dic['year'].strip()
# 将数据一行一行写入
csvwriter.writerow(dic.values())
resp.close()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号