正则表达式
一、优缺点
正则的优点:速度快,效率高,准确性高
正则的缺点:新手上手难度有点儿高.
二、常用字符
. 匹配除换行符以外的任意字符
\w 匹配字母或数字或下划线
\s 匹配任意的空白符
\d 匹配数字
\n 匹配一个换行符
\t 匹配一个制表符
^ 匹配字符串的开始
$ 匹配字符串的结尾
\W 匹配非字母或数字或下划线
\D 匹配非数字
\S 匹配非空白符
a|b 匹配字符a或字符b
() 匹配括号内的表达式, 也表示一个组
[...] 匹配字符组中的字符
[^...] 匹配除了字符组中字符的所有字符
三、量词
* 重复零次或更多次
十 重复一次或更多次
? 重复零次或一次
{n} 重复n次
{n,} 重复n次或更多次
{n,m} 重复n到m次
四、贪婪匹配和惰性匹配
.* 贪婪匹配
.*? 惰性匹配
五、re模块
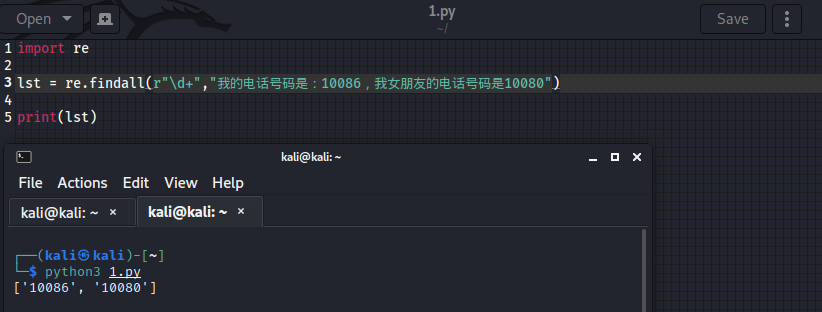
1、findall
import re
# findall:匹配字符串中所有的符合正则的内容
lst = re.findall(r"\d+","我的电话号码是:10086,我女朋友的电话号码是10080")
print(lst)
2、finditer
import re
# finditer:匹配字符串中所有的内容[返回的是迭代器(match)],从迭代器中拿到内容需要,group()
lst = re.finditer(r"\d+","我的电话号码是:10086,我女朋友的电话号码是10080")
for i in lst:
print(i.group())

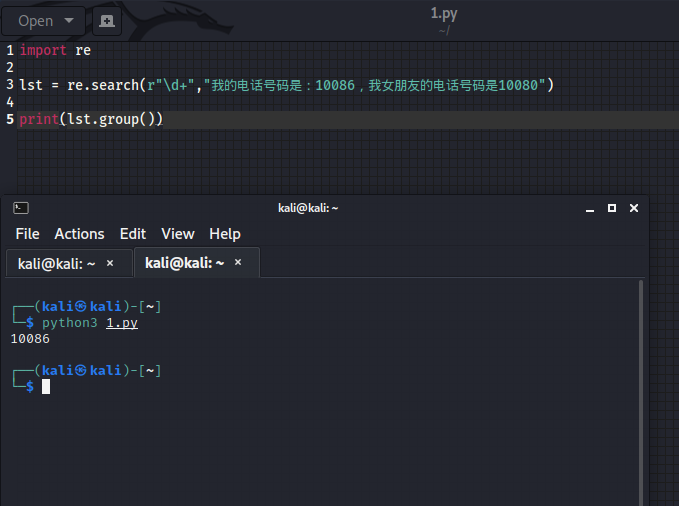
3、search
import re
# search,找到一个结果就返回,返回的结果是match对象,拿数据需要.group()
lst = re.search(r"\d+","我的电话号码是:10086,我女朋友的电话号码是10080")
print(lst.group())
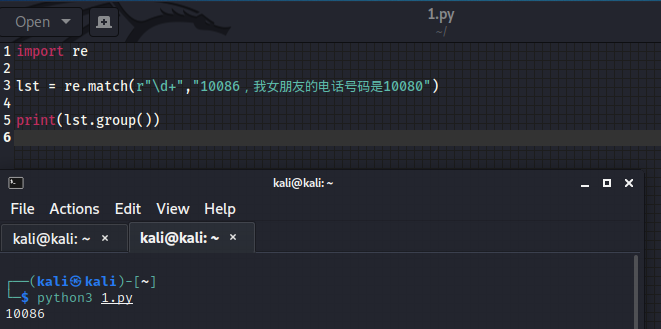
4、match
import re
# match是从头开始匹配,如果没匹配到就报错
lst = re.match(r"\d+","10086,我女朋友的电话号码是10080")
print(lst.group())
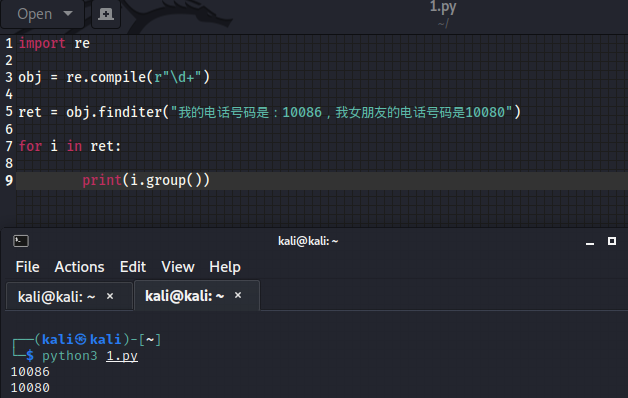
5、预加载正则表达式
import re
obj = re.compile(r"\d+")
ret = obj.finditer("我的电话号码是:10086,我女朋友的电话号码是10080")
for i in ret:
print(i.group())
六、正则匹配
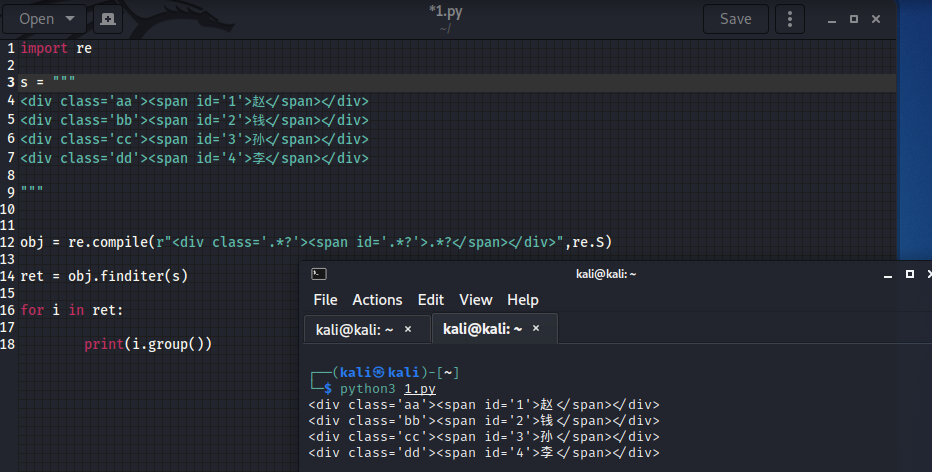
import re
s = """
<div class='aa'><span id='1'>赵</span></div>
<div class='bb'><span id='2'>钱</span></div>
<div class='cc'><span id='3'>孙</span></div>
<div class='dd'><span id='4'>李</span></div>
"""
obj = re.compile(r"<div class='.*?'><span id='.*?'>.*?</span></div>",re.S) # re.S 能让.能匹配换行符(原本.是不能匹配换行符的)
ret = obj.finditer(s)
for i in ret:
print(i.group())
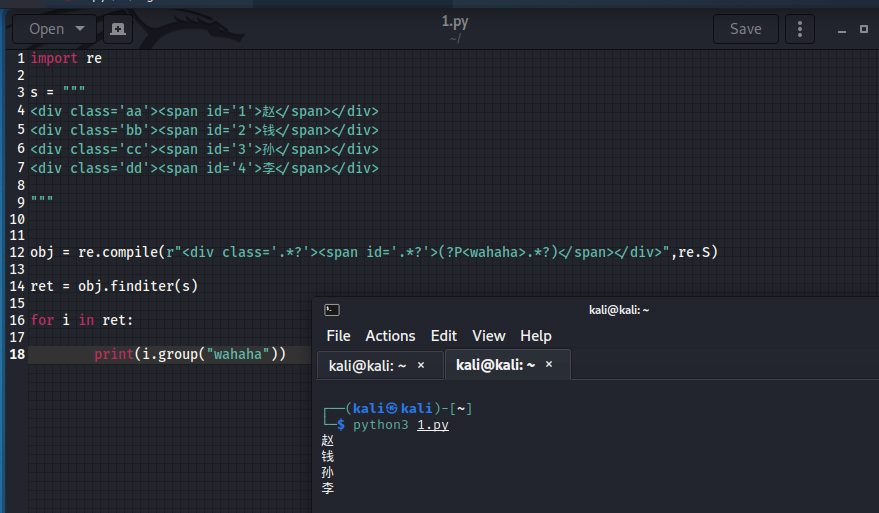
import re
s = """
<div class='aa'><span id='1'>赵</span></div>
<div class='bb'><span id='2'>钱</span></div>
<div class='cc'><span id='3'>孙</span></div>
<div class='dd'><span id='4'>李</span></div>
"""
# 在需要匹配的地方取个别名,如wahaha,(?P<wahaha>.*?)
obj = re.compile(r"<div class='.*?'><span id='.*?'>(?P<wahaha>.*?)</span></div>",re.S)
ret = obj.finditer(s)
for i in ret:
print(i.group("wahaha"))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号