
重生之我是操作系统(三)----进程&线程
简介
进程是系统资源分配的最小单位,它曾经也是CPU调度的最小单位,但后面被线程所取代。
进程树
Linux系统通过父子进程关系串联起来,所有进程之前构成了一个多叉树结构。

孤儿进程
孤儿进程是指父进程已经结束,子进程还在执行的进程。那么此时此刻,该进程就变成了孤儿进程。
当进程变成孤儿进程后,系统会认领该进程,并为他再分配一个父进程(就近原则,爸爸的爸爸,爸爸的爸爸的爸爸)。
》当孤儿进程被认领后,就很难再进行标准输入输出对其控制了。因为切断了跟终端的联系,所以编码过程中要尽量避免出现孤儿进程
进程通讯(inter -Process Communication,IPC)
多个进程之间的内存相互隔离,多个进程之间通讯方式有如下几种:
管道(pipe)
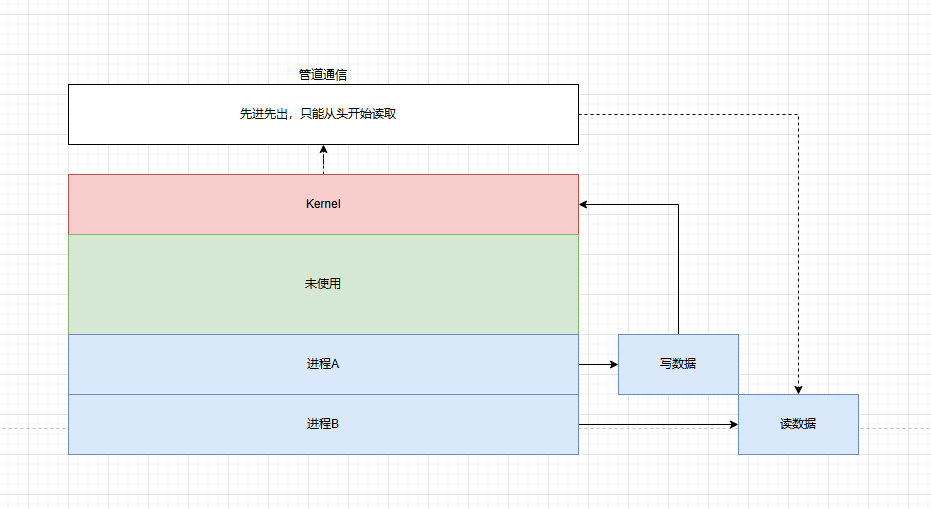
匿名管道
半双工通信,即数据只能在一个方向上流动。只能在具有父子关系的进程之间使用。
其原理为:内核在内存中创建一个缓冲区,写入端将数据写入缓冲区,读取端从缓冲区中读取数据
点击查看代码
#include <stdio.h>
#include <unistd.h>
#include <string.h>
int main() {
int pipefd[2];
pid_t pid;
char buffer[100];
// 创建管道
if (pipe(pipefd) == -1) {
perror("pipe");
return 1;
}
// 创建子进程
pid = fork();
if (pid == -1) {
perror("fork");
return 1;
}
if (pid == 0) {
// 子进程:关闭写端,从管道读取数据
close(pipefd[1]);
read(pipefd[0], buffer, sizeof(buffer));
printf("Child process received: %s\n", buffer);
close(pipefd[0]);
} else {
// 父进程:关闭读端,向管道写入数据
close(pipefd[0]);
const char *message = "Hello, child process!";
write(pipefd[1], message, strlen(message) + 1);
close(pipefd[1]);
}
return 0;
}
命名管道
可以在任意两个进程之间进行通信,不要求进程具有亲缘关系;遵循先进先出(FIFO)原则。
其原理为:在文件系统中创建一个特殊的文件,进程通过读写这个文件来进行通信,因此文件读取是从头开始读,先进先出。
点击查看代码
// 写进程
#include <stdio.h>
#include <fcntl.h>
#include <string.h>
#include <unistd.h>
#define FIFO_NAME "myfifo"
int main() {
int fd;
const char *message = "Hello, named pipe!";
// 创建命名管道
mkfifo(FIFO_NAME, 0666);
// 打开命名管道进行写操作
fd = open(FIFO_NAME, O_WRONLY);
if (fd == -1) {
perror("open");
return 1;
}
// 向命名管道写入数据
write(fd, message, strlen(message) + 1);
close(fd);
return 0;
}
// 读进程
#include <stdio.h>
#include <fcntl.h>
#include <unistd.h>
#define FIFO_NAME "myfifo"
int main() {
int fd;
char buffer[100];
// 打开命名管道进行读操作
fd = open(FIFO_NAME, O_RDONLY);
if (fd == -1) {
perror("open");
return 1;
}
// 从命名管道读取数据
read(fd, buffer, sizeof(buffer));
printf("Received: %s\n", buffer);
close(fd);
// 删除命名管道
// 理论上,命名管道是可以重复使用的,其本质就是操作文件而已。只是不建议这么操作。
unlink(FIFO_NAME);
return 0;
}
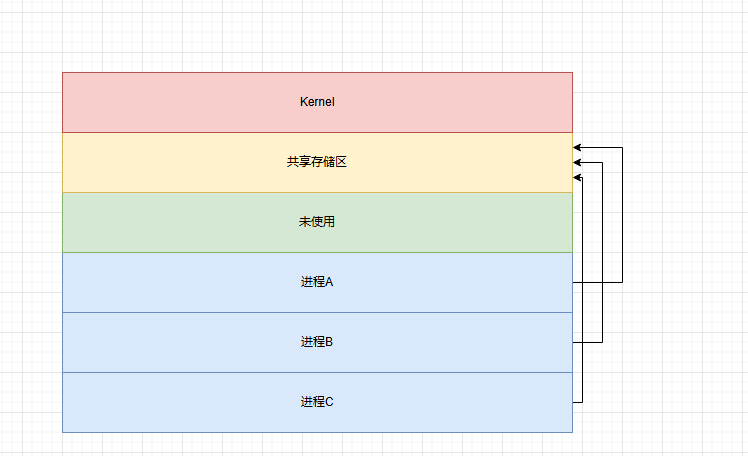
共享内存(Shared Memory)
多个进程共享同一块内存地址,是最快的IPC方式。
其原理为:内核在物理内存中分配一块内存区域,多个进程将内存地址映射到自己的虚拟空间内,从而可以直接读写该区域。
点击查看代码
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <fcntl.h>
#include <sys/mman.h>
#include <sys/wait.h>
#include <string.h>
int main(int argc, char const *argv[])
{
//创建一个共享内存对象
char shm_name[100]={0};
sprintf(shm_name,"/letter%d",getpid());
int fd= shm_open(shm_name,O_RDWR|O_CREAT,0664);
if(fd<0){
perror("shm_open");
exit(EXIT_FAILURE);
}
//给共享内存对象设置大小
ftruncate(fd,1024);
//内存映射
char *share= mmap(NULL,1024,PROT_READ|PROT_WRITE,MAP_SHARED,fd,0);
if(share==MAP_FAILED){
perror("mmap");
exit(EXIT_FAILURE);
}
//映射完成,关闭fd连接
close(fd);
//使用内存,完成进程通讯
pid_t pid=fork();
if(pid<0){
perror("fork");
exit(EXIT_FAILURE);
}
if(pid==0){
//子进程
strcpy(share,"子进程,嘿嘿嘿嘿。");
}
else{
//父进程
waitpid(pid,NULL,0);
printf("收到子进程的信息:%s",share);
}
//释放映射
munmap(share,1024);
//释放共享内存对象
shm_unlink(shm_name);
return 0;
}
临时文件系统
linux的临时文件系统是一种基于内存的文件系统,它将数据存储在RAM中或者SWAP中,共享对象同样也是挂在在临时文件系统中。
我们可以写一段不释放的代码,来眼见为实。
点击查看代码
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <fcntl.h>
#include <sys/mman.h>
#include <sys/wait.h>
#include <string.h>
int main(int argc, char const *argv[])
{
char sh_name[100]={0};
sprintf(sh_name,"/letter%d",getpid());
int fd=shm_open(sh_name,O_CREAT,0664);
if(fd<0){
perror("shm open");
exit(EXIT_FAILURE);
}
while (1)
{
//代码空转,方便查看内存区域。
}
return 0;
}
代码执行中:生成的临时文件

执行后,临时文件也不会消失,因为没有释放。
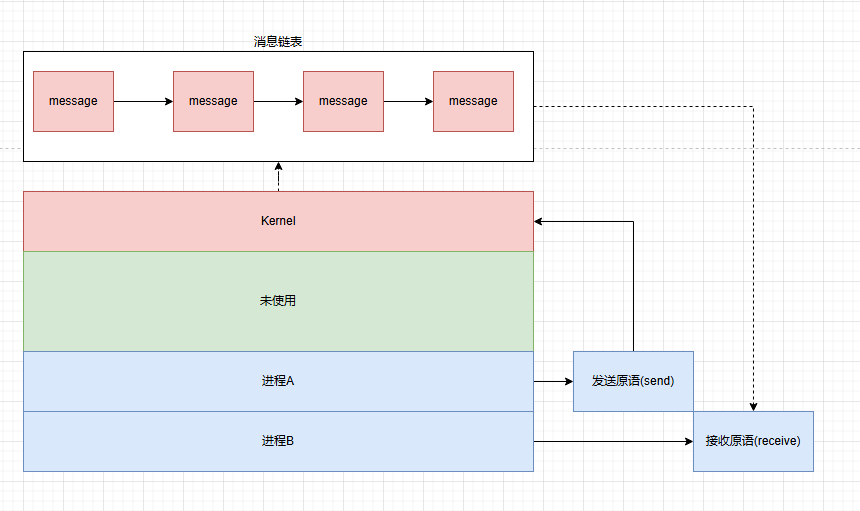
消息队列(message queue)
消息队列是消息的链表,存放在内核中,由消息队列标识符标识。进程可以向队列中添加消息,也可以从队列中读取消息。
其原理为:内核为每个消息队列维护一个消息链表,消息可以按照不同的类型进行分类,进程可以根据消息类型有选择地读取消息。
生产者
#include <fcntl.h>
#include <sys/stat.h>
#include <mqueue.h>
#include <stdio.h>
#include <time.h>
#include <string.h>
#include <unistd.h>
#include <stdlib.h>
int main()
{
struct mq_attr attr;
attr.mq_flags=0;
attr.mq_maxmsg=10;
attr.mq_msgsize=100;
attr.mq_flags=0;
attr.mq_curmsgs;
struct timespec time_info;
//创建消息队列
char * mq_name="/p_c_mq";
mqd_t mqdes=mq_open(mq_name,O_RDWR|O_CREAT,0664,&attr);
if(mqdes==(mqd_t)-1){
perror("mq_open");
exit(EXIT_FAILURE);
}
//从控制台接受数据,并发送给消费者
char write_buff[100];
while (1)
{
memset(write_buff,0,100);
ssize_t read_count= read(STDIN_FILENO,write_buff,100);
clock_gettime(0,&time_info);
time_info.tv_sec+=5;
if(read_count==-1){
perror("read");
continue;
}
else if(read_count==0)
{
printf("控制台停止发送消息");
char eof=EOF;
if(mq_timedsend(mqdes,&eof,1,0,&time_info)==-1){
perror("mq_timedsend");
}
break;
}
else{
if(mq_timedsend(mqdes,write_buff,strlen(write_buff),0,&time_info)==-1){
perror("mq_timedsend");
}
printf("从命令行接受到数据,并发送给消息的队列。");
}
}
//关闭资源
close(mqdes);
//由消费者关闭更加合适,否则消费者可能无法接收到最后一条消息。
//unlink(mq_unlink);
return 0;
}
消费者
#include <fcntl.h>
#include <sys/stat.h>
#include <mqueue.h>
#include <stdio.h>
#include <time.h>
#include <string.h>
#include <unistd.h>
#include <stdlib.h>
int main()
{
struct mq_attr attr;
attr.mq_flags=0;
attr.mq_maxmsg=10;
attr.mq_msgsize=100;
attr.mq_flags=0;
attr.mq_curmsgs;
struct timespec time_info;
//创建消息队列
char * mq_name="/p_c_mq";
mqd_t mqdes=mq_open(mq_name,O_RDWR|O_CREAT,0664,&attr);
if(mqdes==(mqd_t)-1){
perror("mq_open");
exit(EXIT_FAILURE);
}
//从控制台接受数据,并发送给消费者
char read_buff[100];
while (1)
{
memset(read_buff,0,100);
clock_gettime(0,&time_info);
time_info.tv_sec+=5;
//读取数据
if(mq_timedreceive(mqdes,read_buff,100,NULL,&time_info)==-1){
perror("mq_timedreceive");
}
//判断是否结束
else if(read_buff[0]==EOF){
printf("接收到结束信息,准备退出....");
break;
}
else{
printf("接受到来自生产者的信息%s\n",read_buff);
}
}
//关闭资源
close(mqdes);
unlink(mq_unlink);
return 0;
}
临时文件
与内存共享类似,Linux底层也会生成一个临时文件来代表队列。
三者之间的演化关系
在操作系统的发展过程中,最早出现的是管道通信,用于父子进程之间的信息通信。
不足:
- 单向且受限于亲缘关系限制
只能在父子进程之间传递,后面又演化出了命名管道,解决了亲缘关系的限制。 - 传输效率低
依赖内核缓冲区,且内核空间有限,无法传输大数据。 - 缺乏消息分类与异步支持
然后又演化出共享内存,解决了管道在大数据传输的效率问题。成为现在操作系统中最高效的IPC方式,
不足:
- 需要开发者自行处理同步逻辑。
经常听到的Zero Copy也是这个原理。
与共享内存同时推出的还有消息队列,它解决了管道/共享内存在功能上的局限性。
消息可以按照分组来选择性的接收,由内核来处理同步逻辑,并对外提供原子操作。
不足:
- 性能不如共享内存
因为消息队列与管道一样,需要从内核复制数据。
消息队列是对管道的功能增强,共享内存是对管道的性能增强。
| 机制 | 是否复制内核 | 存储位置 | 描述 |
|---|---|---|---|
| 管道 | 是(两次复制) | 内核缓冲区 | 基于字节流,需内核复制数据,效率较低,但实现简单 |
| 共享内存 | 否 | 内核物理地址 | 直接访问,无数据复制,效率最高,但需同步机制 |
| 消息队列 | 是(两次复制) | 内核物理地址 | 消息按类型组织,支持异步通信,但需内核复制数据,适合中小数据量传输 |
进程模型
内核会为每一个进程创建并保存一个名为PCB(Process Control Block)的数据结构,来维护进程运行过程中的一些关键信息。
- PID
- 进程状态
- 进程切换时需要保存和回复的寄存器的值
- 内存管理
当前进程所属哪一块内存,如页表,段表等 - 当前工作目录
- 进程调度信息
比如优先级,进程调度指针 - I/O状态信息
最常见的就是文件描述符表(struct fdtable),I/O设备列表 - 同步和通讯信息
比如信号量,信号等。 - 权限管理
比如所属id与所属group
struct task_struct {
/* 执行环境的必要信息 */
struct thread_info thread_info;
/* 内核栈 */
void *stack;
/* 进程状态 */
volatile long state;
/* 进程标识符 */
pid_t pid;
/* 指向父进程的指针 */
struct task_struct __rcu *parent;
/* 进程的用户和组信息 */
uid_t uid, euid, suid, fsuid;
gid_t gid, egid, sgid, fsgid;
/* 文件系统信息 */
struct fs_struct *fs;
/* 内存管理信息 */
struct fs_struct *mm;
/* 其他成员... */
};
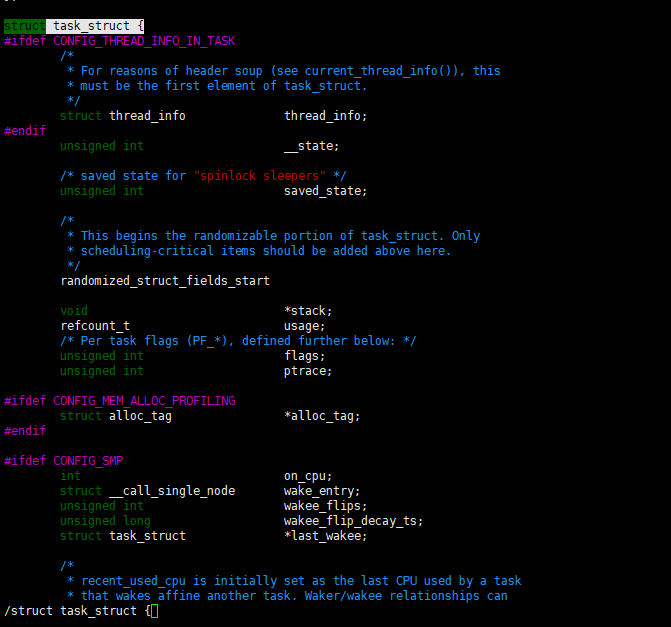
进程创建过程
上面说到,在Linux中,进程PCB实现的是task_struct的实例。
fork
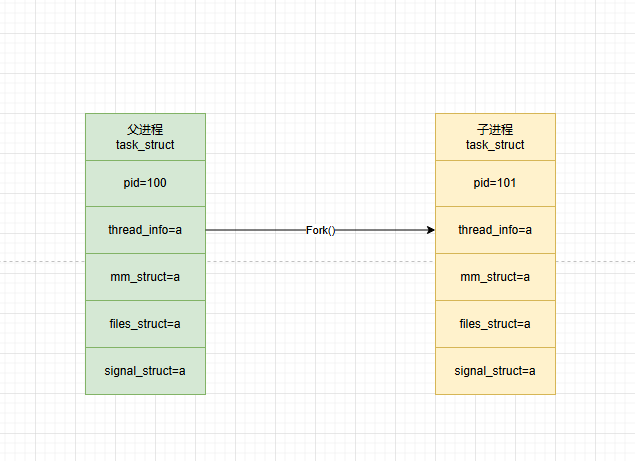
fork创建子进程流程如下
- 为子进程创建内核栈,thread_info实例
- 引用复制父进程的所有信息
注意:此时只是复制了资源的引用 - 清除子进程的统计信息,更新子进程标志位
因为是复制父进程的,所以还要"刷一遍“数据 - 为子进程分配新的PID,并更新PPID
- 清除与fork()返回值相关的寄存器
使得子进程中的fork返回值为0,就是为什么pid=0代表是子进程的原因 - 值复制,文件描述符,文件信息系统,内存信息等。
主要目的是为了引用计数+1 - 修改子进程状态
处于就绪态
execve
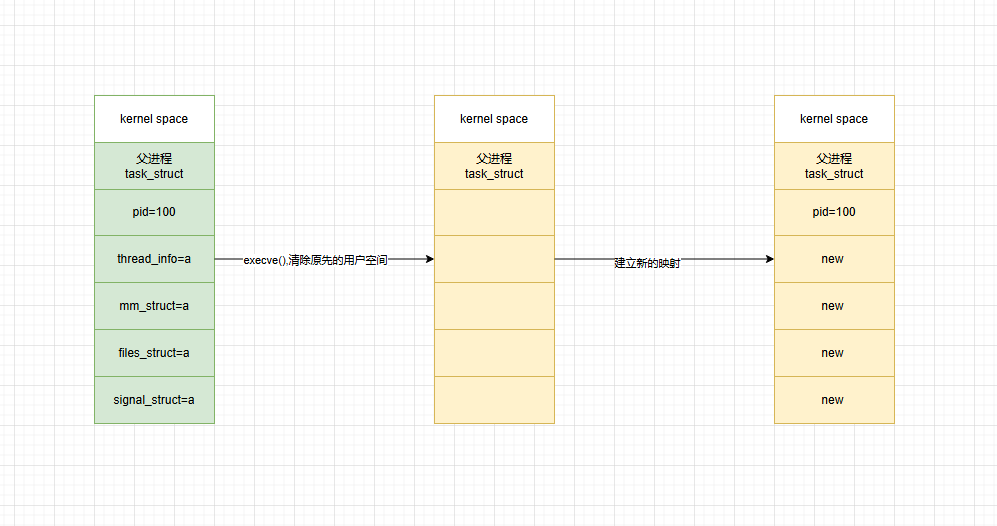
execve创建子进程流程如下
- 在用户态检查基本参数与运行环境
- 进入内核态,创建新的内核映射
清除当前的进程的代码,堆栈,数据,建立一个全新的代码,堆栈,数据。
因为只清用户空间,不清理内核空间。所以PID不会产生变化。 - 初始化上下文
比如程序计数器(IP),栈指针(SP),各种内核资源,文件描述符等。 - 更新堆栈,环境变量等参数
- 执行新程序
写时复制(COW)
为了提高进程的创建效率,初始化时子进程会"引用"父进程的资源,只有当两者之一执行了写入操作,才会真正的复制写入区域的内容。为父子进程维护不同的内存地址。
fork与execve的联系
fork():用于创建一个新的进程,这个新进程是调用 fork() 的进程(父进程)的副本,拥有与父进程几乎相同的代码、数据和堆栈等资源。fork() 调用会返回两次,在父进程中返回子进程的进程 ID,在子进程中返回 0
execve():用于在当前进程的上下文中执行一个新的程序,它会用新程序的代码、数据和堆栈替换当前进程的相应部分,从而使当前进程开始执行新的程序。execve() 调用成功后不会返回,除非调用失败。
单独使用 fork() 只能创建一个与父进程几乎相同的子进程,子进程会继续执行与父进程相同的代码。而单独使用 execve() 会直接在当前进程中执行新程序,覆盖当前进程的执行内容。为了创建一个新的进程并在该进程中执行新的程序,通常会先调用 fork() 创建一个子进程,然后在子进程中调用 execve() 来执行新程序,这样既保留了父进程的执行流程,又能在子进程中执行不同的程序
进程组
进程组ID(Process Group ID,PGID),在Liunx中用来标识多个进程的集合,当使用父进程创建子进程时,它们默认就会是同一个进程组。

在windows下没有此概念,类似是job object。但在概念上不一致。
内存模型
内存模型,基本都大同小异,不再赘述.
以C语言程序为例:
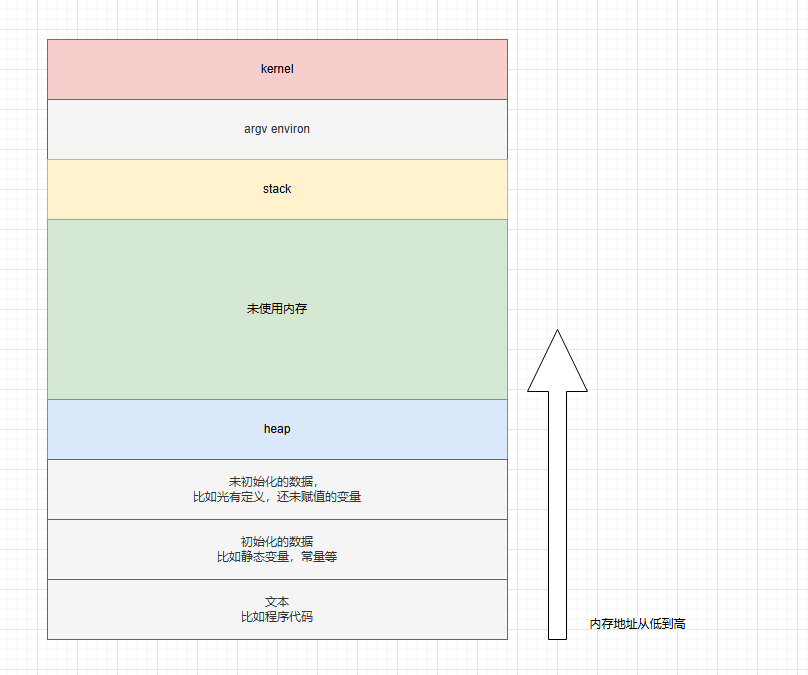
栈指针 SP,表示栈顶
帧指针 BP,表示栈底
命令指针 IP,命令指针,指向下一条要运行的命令
进程状态模型
对于进程状态,有一个抽象的定义。
- 初始状态(initial)
进程刚被创建的初始态,该阶段,操作系统会为进程分配资源 - 就绪态(ready)
进程已经准备就绪,当并未被CPU所调度。 - 运行态(Running)
正在CPU上执行代码 - 阻塞态(Blocked)
进程等待其他事件完成,比如网络I/O,磁盘I/O而无法继续时,就处于阻塞状态 - 终止态(Final)
进程执行完毕,准备释放其占用的资源,PCB信息依旧存在。该状态理论上非常短暂。 - 僵尸态(Zombie)
与终止态非常相似,唯一的区别就是因为未知原因PCB长期不释放。
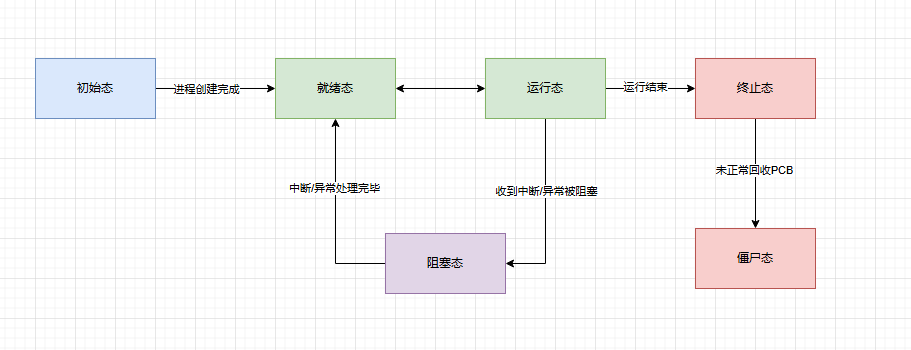
而在Linux中,并未完全遵循上述抽象概念。
不过总体类似,状态主要有如下几种。
- D
不可中断的睡眠状态,比如执行IO操作时,不可中断。 - I
空闲的内核线程 - R
Runnig/Read 运行中或者可以运行的状态 - S
可中断的睡眠状态,比如等待唤醒 - T
由工作控制信号停止 - t
由调试器停止 - W
分页,从2.6内核版本后就不再有效 - X
死亡状态,理论上不会看到,因为相当于整个进程都被回收了,包括PCB,是现实不了的。你如何显示一个不存在的进程? - Z
僵尸进程,已经终止但PCB尚未被回收
| 抽象 | Linux实现 |
|---|---|
| 初始态 | N/A |
| 就绪态 | R |
| 运行态 | R |
| 阻塞态 | D,S,T,t |
| 僵尸态 | Z |
进程状态控制
当一个进程状态变换的时候,通常需要三步。
- 找到PCB
- 设置PCB状态信息
- 将PCB移到响应的队列
比如进程从阻塞态变成就绪态,状态变化后,CPU的调度队列也要变化。
思考一个问题,如果在第二步的时候,突然来了一个中断,导致第三步没有执行。破坏了原子性,从而使得程序出现异常,这时候应该怎么处理?
汇编每执行一行代码,CPU都会检查一次有没有中断。
这个时候,就要依靠特权指令来实现原子性了
cpu提供两个特权指令
- 关中断指令
- 开中断指令
因此,在开/关中断指令中间的汇编代码,CPU不会再检查有没有中断,从而实现操作原子性。
进程切换
懒得再写一遍了,参考此文。
https://www.cnblogs.com/lmy5215006/p/18556052
简单描述一下Linux进程切换过程。
- 触发中断
注意是异步,当中断触发时,会让被中断的进程执行完当前执行,保证原子性。 - CPU暂存寄存器的值
- 栈指针(SP)指向内核态
因为进程切换是内核级操作,无法在用户态完成。 - CPU将暂存的寄存器的值压栈
- CPU将终端编码(error code)的值压栈
- 弹栈,挪动程序计数器(ip)指向中断处理程序
发现中断类型=时钟触发进程切换。 - 保存寄存器的值到老进程的PCB中
- 恢复新进程的PCB
- 栈指针(SP)指向新进程
- 老进程回到CPU调度队列
- 新进程进行必要的权限检擦
- 恢复新进程的cs,ip寄存器
- 恢复新进程的状态寄存器
- 恢复新进程的栈指针(SP)
为什么要引入线程
long long year ago,系统中的程序只能串行执行。为了解决程序并发执行的问题,操作系统引入了进程。
随着软件的发展,有的时候进程需要“同时”做很多事,比如QQ,你可能在视频聊天的同时,还要打字,同时还要传输文件。
由于在进程内部,代码同样也是串行执行,这就导致了上述场景在进程这个维度中,就需要同时启动多个进程来满足需求。
但多个进程的切换会导致系统开销很大,比如PCB的上下文切换,PCB是一个很大的数据结构,内容很多,这对操作系统而言开销并不低。
因此,为了降低进程切换的开销,操作系统引入了线程,在引入线程后,线程成了CPU调度的最小单位。进程只作为资源分配的最小单元
线程也可以理解为"轻量级进程",它的Thread Contral Block, TCB相对PCB来说,瘦身了很多。且如果在同一进程的线程切换,不需要切换进程,所以开销更低。
多线程模型
一对一模型,一个用户线程映射到一个内核线程
- 优点
各个线程可以真正的并行(多核心),单个线程阻塞不影响其它线程 - 缺点
每一个线程的创建于切换都需要内核参与(用户态=>内核态=>用户态,2次切换),开销高。 - 应用
Linux、Windows 等现代操作系统。
多对一模型,多个用户线程映射到一个内核线程
- 优点
线程切换在用户态完成,开销低,速度块。 - 缺点
当内核线程阻塞时,与之关联的用户态线程全部挂起
难以利用多核处理器 - 应用
应用时间最早,比如go语言的协程,C#的Async
多对多模型,用户线程动态映射到多个内核线程
- 优点
上面两种模型的折中,平衡性能于效能。
支持多核心 - 缺点
实现比较复杂 - 应用
应用时间最早,比如JAVA的虚拟线程。
Linux中的线程
在Linux中的,线程被当作特殊的进程。也可以称为轻量级进程。两者都有独立的task_struct结构体,并且fork()和pthread_create()底层都是使用系统调用clone()来创建。
- 创建进程
当我们调用fork()时,等同于调用clone(SIGCHLD,0)。
SIGCHLD:是一个信号,当子进程终止、停止或继续运行时,父进程会收到这个信号。 - 创建线程
pthread_create()时,等同于调用clone(CLONE_VM|CLONE_FS|CLONE_FILES|CLONE_SIGHAND,0)。
CLONE_VM:此标志表示子进程和父进程共享相同的内存空间
CLONE_FS:该标志意味着子进程和父进程共享文件系统信息
CLONE_FILES:此标志表明子进程和父进程共享打开的文件描述符表
CLONE_SIGHAND:该标志表示子进程和父进程共享信号处理函数表
PID,TGID,TID
因从,从上面的角度来看。task_struct结构体中的pid实际上表示的是进程id or 线程id。
- TGID(Thread Group Identifier)
线程标识组,每一个线程的pid都不同,毕竟它们是本质上是轻量级进程,但是它们共享一个TGID,PID与TGID相同代表是主线程。 - TID(Thread Identifier)
即线程标识符,用于唯一标识线程组内的每个线程。在 Linux 系统中,TID 和 PID 的概念在实现上是相同的,每个线程都有一个唯一的 TID,而对于单线程进程,其 TID 等于 PID
内核线程
内核线程是运行在内核态的轻量级进程,它与线程类似。 没有独立的地址空间和大部分用户空间资源。
主要用于管理和执行内核级的任务,比如硬件中断处理,系统调用,内存管理等。
内核线程主要有如下资源:
- 内核栈空间
- Task_struct
内核线程的信息也同样存储在Task_struct中,不过它的mm以及active_mm 的值为NULL,代表没有虚拟内存空间。它们通常是共享内核的空间,而不需要虚拟内存空间。
files_struct为NULL,没有文件描述符
fs_struct为NULL,没有文件信息系统
signal_struct和sigand_struct为NULL,没有信号处理表 - flags
Task_struct中有一个flags字段,值为PF_KTHREAD 表示这是一个内核线程
不同于普通进程 - 内核线程id
内核线程tid,pid,tgid都是相同的,都是0。因为内核线程不参与普通任务,只操作内核。所以在设计上PGID为0,作为一个显著的标识。来确保内核线程在系统中的特殊性与隔离性

 浙公网安备 33010602011771号
浙公网安备 33010602011771号