

.NET Core 对象分配(Alloc)底层原理浅谈
对象分配策略
.NET程序的对象是由CLR控制并分配在托管堆中,如果是你,会如何设计一个内存分配策略呢?
-
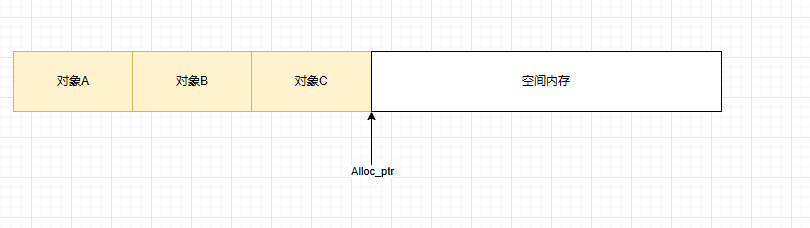
按需分配,要多少分配多少,移动alloc_ptr指针即可,没有任何浪费。缺点是每次都要向OS申请内存,效率低
-
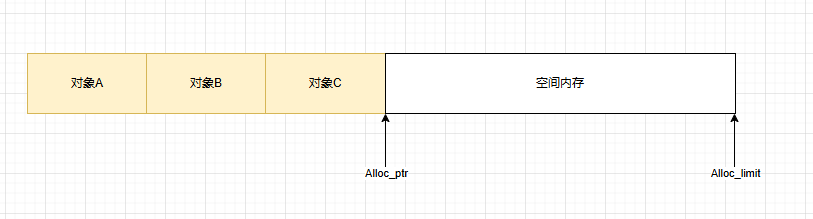
预留缓冲区,降低了向OS申请内存的频次。但在多线程情况下,alloc_ptr锁竞争会非常激烈,同样会降低效率
-
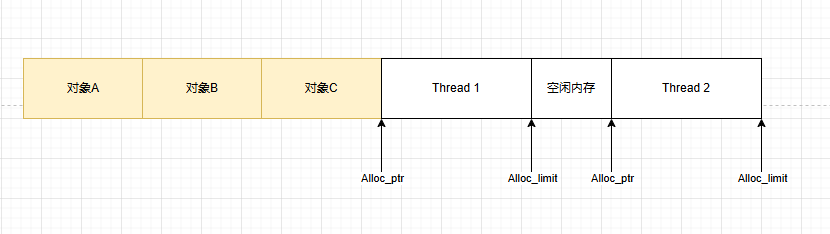
利用TLS,来避免锁竞争,但Thread1与Thread2之间存在Free块,内存空间浪费多。
-
将Free块利用起来,实现最大化能效
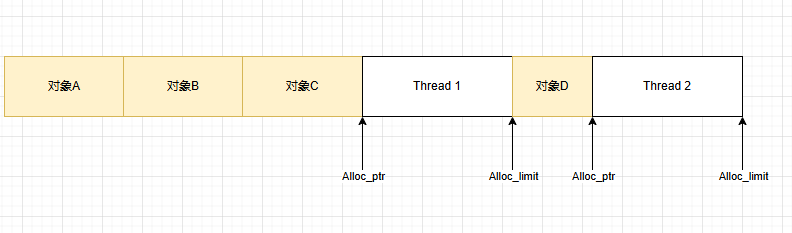
.NET程序就是采用了第四种,来实现空间与时间的最大化。
因此有些alloc_context在段尾,有些在两个已分配对象之间的空余空间
眼见为实
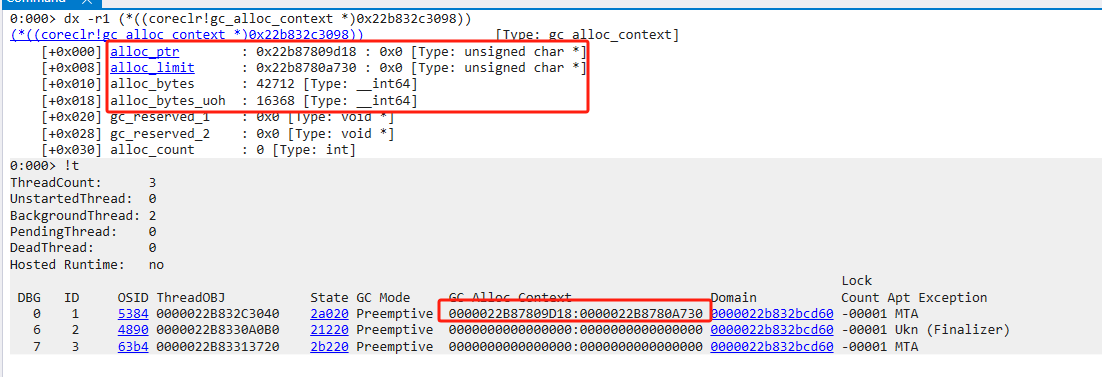

Free块
在上面,我们已经见到了Free块,简单来说,Free就是segment中留下来的空洞。也就是内存碎片。
Free块产生的原因主要有三种
- GC计划阶段,用作特殊目的
- GC标记阶段,将垃圾对象标记为Free
- 多个Free相邻时,GC将多个合并为一个大的Free块
内存碎片的危害:造成内存空间的浪费,降低内存分配效率。
眼见为实
点击查看代码
internal class Program
{
public static byte[] bytes1, bytes2, bytes3, bytes4, bytes5, bytes6;
static void Main(string[] args)
{
Alloc();
Console.WriteLine("分配完毕");
Debugger.Break();
GC.Collect();
Console.WriteLine("GC完成");
Debugger.Break();
}
public static void Alloc()
{
bytes1 = new byte[85000];
bytes2 = new byte[85000];
bytes3 = new byte[85000];
bytes4 = new byte[85000];
bytes5 = new byte[85000];
bytes6 = new byte[85000];
bytes2 = null;
bytes3 = null;//将2,3标记为Free,两个相邻Free会合并
bytes5 = null;
}
}
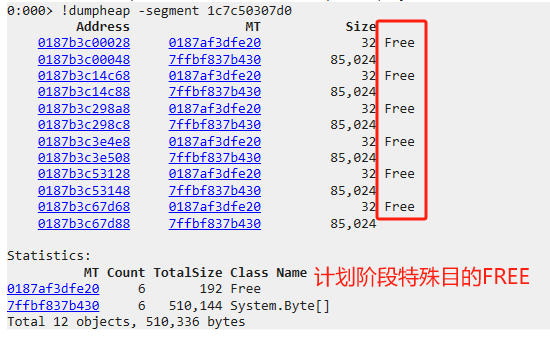
LOH特有的特殊标记
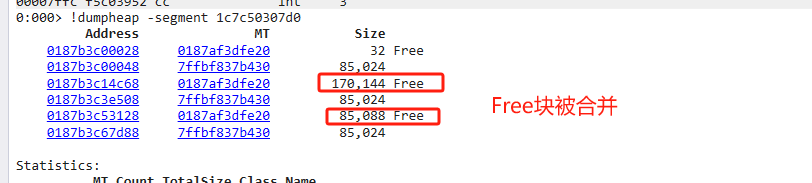
垃圾对象被标记为Free,相邻的Free对象合并。
Free块管理逻辑
CLR对Free块采用数组+链表进行管理,根据size确定对应的bucket,再使用双向链表维系大小相近的Free块。
这样按照大小维度划分,极大提高了查找的性能,拿空间换时间。
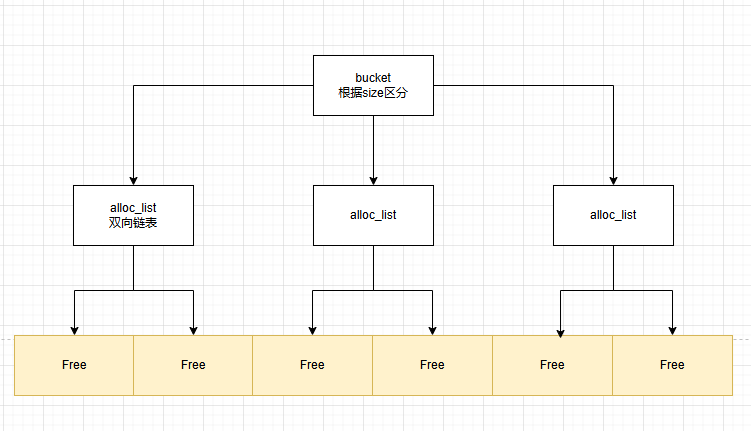
眼见为实
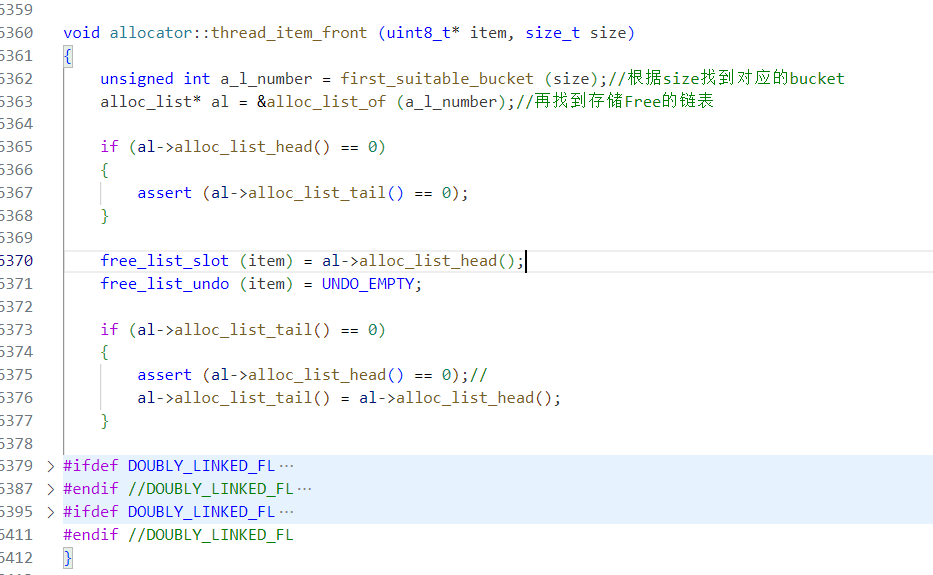
不是所有Free都会被纳入管理,只有 free > 2 * min_obj_size 的对象才能进入bucket集合中,可以思考一下为什么会这么做。
Free块内存结构
与其它普通对象类似,也有对象头与方法表,再附加额外信息。内存结构如下。

眼见为实
点击查看代码
internal class Program
{
public static byte[] bytes1, bytes2, bytes3, bytes4, bytes5, bytes6;
static void Main(string[] args)
{
Alloc();
Console.WriteLine("分配完毕");
Debugger.Break();
GC.Collect();
Console.WriteLine("GC完成");
Debugger.Break();
}
public static void Alloc()
{
bytes1 = new byte[85000];
bytes2 = new byte[85000];
bytes3 = new byte[85000];
bytes4 = new byte[85000];
bytes5 = new byte[85000];
bytes6 = new byte[85000];
bytes2 = null;
bytes4 = null;
bytes6 = null;
}
}
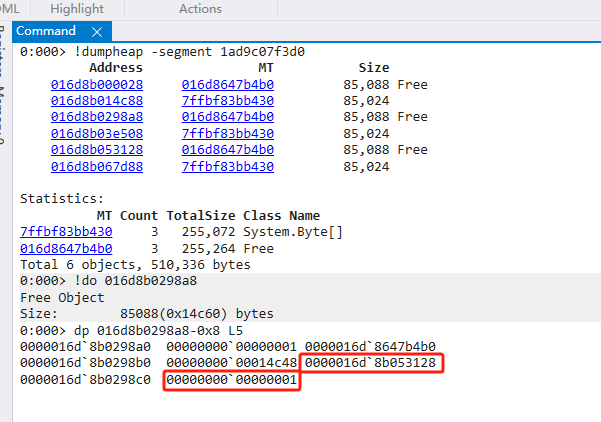
细心的朋友会发现两个问题
- do命令显示的size明明为0x14c60,为什么dp命令显示为0x14c48?
只是计算取值的差异,它们之间差值为24,分别为objectheader/mt/size - 为什么Next Free有值,Prev Free没有值?
在SOH上2代Free记录了Next/Prev Free的双向链表。 其他代只记录了Next Free的单向链表
对象分配过程
点击查看代码
internal class Program
{
static void Main(string[] args)
{
Debugger.Break();
var person = new Person();
Debugger.Break();
}
}
public class Person
{
private long age = 10;
private int age2 = 10;
private int age3 = 10;
}
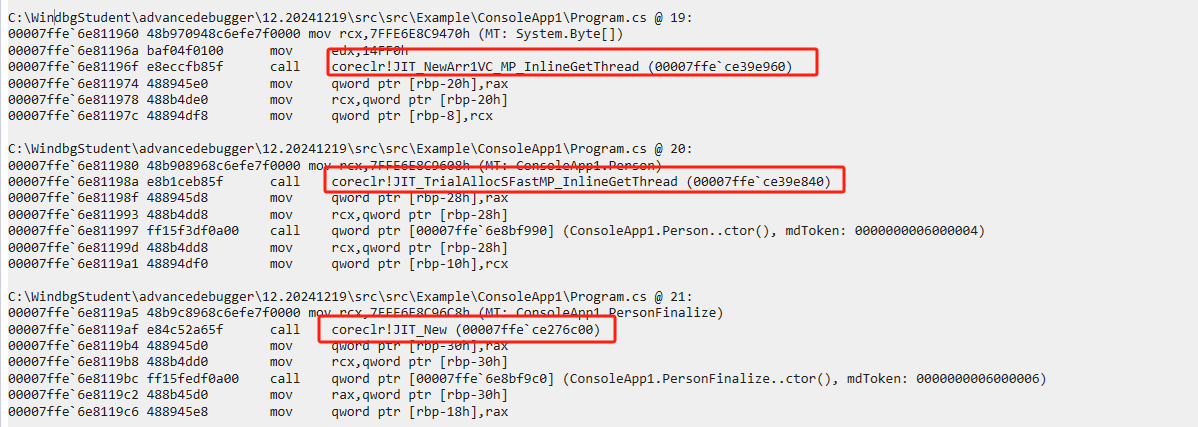
new Person() 的汇编如下
00007ffb`93b8195e 48b9d893c393fb7f0000 mov rcx,7FFB93C393D8h (MT: Example_12_1_4.Person)
00007ffb`93b81968 e8d3ceb65f call coreclr!JIT_TrialAllocSFastMP_InlineGetThread (00007ffb`f36ee840)
00007ffb`93b8196d 488945f0 mov qword ptr [rbp-10h],rax
00007ffb`93b81971 488b4df0 mov rcx,qword ptr [rbp-10h]
00007ffb`93b81975 ff15b5df0a00 call qword ptr [00007ffb`93c2f930 (Example_12_1_4.Person..ctor())
00007ffb`93b8197b 488b45f0 mov rax,qword ptr [rbp-10h]
00007ffb`93b8197f 488945f8 mov qword ptr [rbp-8],rax
可以看到,New对象的创建分为两步:
- 先调用JIT_TrialAllocSFastMP_InlineGetThread进行内存分配
; IN: rcx: MethodTable*
; OUT: rax: new object
LEAF_ENTRY JIT_TrialAllocSFastMP_InlineGetThread, _TEXT
mov edx, [rcx + OFFSET__MethodTable__m_BaseSize]
; m_BaseSize is guaranteed to be a multiple of 8. 以8byte为步进,结合MT得出需要的内存空间
INLINE_GETTHREAD r11
mov r10, [r11 + OFFSET__Thread__m_alloc_context__alloc_limit]
mov rax, [r11 + OFFSET__Thread__m_alloc_context__alloc_ptr]
add rdx, rax ;内存分配后ptr指针的位置
cmp rdx, r10 ;//判断ptr>limit,说明内存不足,执行AllocFailed逻辑。
ja AllocFailed
mov [r11 + OFFSET__Thread__m_alloc_context__alloc_ptr], rdx ;反之更新ptr指针位置,完成内存分配
mov [rax], rcx
ret
AllocFailed:
jmp JIT_NEW ;走慢速路径,尽最大可能保证分配成功
LEAF_END JIT_TrialAllocSFastMP_InlineGetThread, _TEXT
- 再调用构造函数进行值分配
在Example_12_1_4.Person..ctor()处设置断点


快速路径与慢速路径
在上面提到过的JIT_TrialAllocSFastMP_InlineGetThread方法中,可以看到当Alloc_limit不足,不能完成内存分配时,会执行JIT_NEW方法。
JIT_NEW内部有大量判断,来尽最大可能保证分配成功。因此执行速度比较慢,所以称为慢速路径,与之对应的JIT_TrialAllocSFastMP_InlineGetThread方法,判断极其简单且高效,所以被称之为快速路径
JIT在编译期间会根据不同的对象来使用不同的策略,比如带析构函数的类默认是慢速分配。
慢速分配流程图如下:
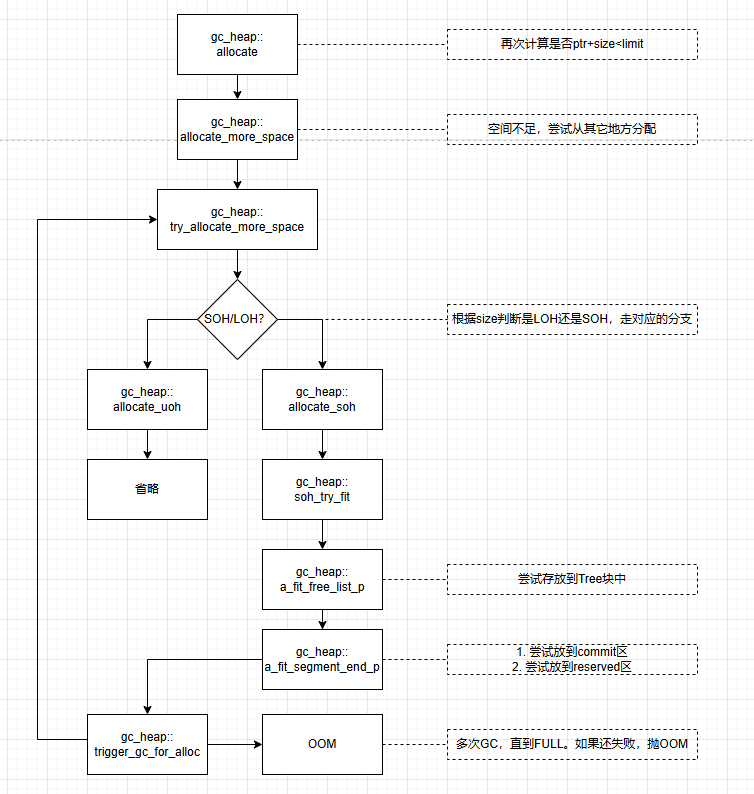
可以看到,快速分配仅仅用8行汇编就完成了分配过程,而慢速分配则复杂得多。
眼见为实
点击查看代码
internal class Program
{
static void Main(string[] args)
{
byte[] b = new byte[86000];//.NET Core 2.1中,大对象会走慢速分配,.NET8中已经优化了
var p = new Person();//不带析构函数,走快速分配
var pf = new PersonFinalize();//带析构函数,走慢速分配
Debugger.Break();
}
}
public class Person
{
}
public class PersonFinalize
{
~PersonFinalize()
{
}
}
避免堆分配
到目前位置,我们讨论都是在托管堆上的分配,也了解到.NET如何尽可能使堆分配更高效。
众所周知,在栈上进行分配与释放的速度明显要快得多,完全避免了堆过程。因此在特定条件下,栈分配是一个非常有空且高效的操作
如果我们希望非常高效地处理数据同时又不想再堆上分配大型数据表,可以显示使用栈分配方式
栈分配方式主要有两种:
- stackalloc
unsafe void Test()
{
int* array = stackalloc int[20];//new int[20] 只是让数据排列更紧密,本质还是分配在堆上。
array[0] = 10;
array[19] = 12;
Debugger.Break();
}
- Span
public void SpanTest()
{
Span<int> array = stackalloc int[20];
array[0] = 10;
array[19] = 12;
Debugger.Break();
}
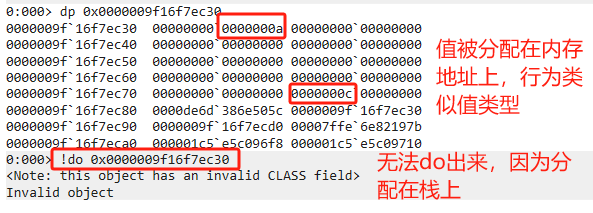
显式使用栈分配能带来两个好处
- 分配在栈上,永远不会进入慢速分支,也完全不受GC管辖,但要注意StaticOverflow
- 由于生命周期跟随栈指针,对象的地址也被变相的固定住(不会移动),所以可以安全的将内存地址传递给非托管代码,且不会产生额外的固定(pinning)
固定(pinning)对象是影响GC速度的大杀手
总结
在性能要求非常高的情况下,尽量避免堆分配。如果条件允许,在栈上分配是更好的选择,如果条件不允许(StaticOverflow),使用对象池机制实现对象复用也是一种好的解决办法
基于这个思路,我们会发现日常编码中,有很多值得优化的地方
- 使用结构传递小型数据
- 使用ValueTuple替代Tuple
- 使用stackalloc分配小型数组,或者使用ArrayPool实现对象复用
- 针对经常被缓存的Task,使用ValueTask
- 闭包带来的值类型提升
- 使用ValueTuple替代匿名对象
- ........................

