
python面试题库——3数据库和缓存
-
第三部分 数据库和缓存(46题)
-
列举常见的关系型数据库和非关系型都有那些?
关系型数据库:
Oracle、DB2、Microsoft SQL Server、Microsoft Access、MySQL
非关系型数据库:
NoSql、Cloudant、MongoDb、redis、HBase
两种数据库之间的区别:
关系型数据库
关系型数据库的特性
1、关系型数据库,是指采用了关系模型来组织数据的数据库;
2、关系型数据库的最大特点就是事务的一致性;
3、简单来说,关系模型指的就是二维表格模型,而一个关系型数据库就是由二维表及其之间的联系所组成的一个数据组织。
关系型数据库的优点
1、容易理解:二维表结构是非常贴近逻辑世界一个概念,关系模型相对网状、层次等其他模型来说更容易理解;
2、使用方便:通用的SQL语言使得操作关系型数据库非常方便;
3、易于维护:丰富的完整性(实体完整性、参照完整性和用户定义的完整性)大大减低了数据冗余和数据不一致的概率;
4、支持SQL,可用于复杂的查询。
关系型数据库的缺点
1、为了维护一致性所付出的巨大代价就是其读写性能比较差;
2、固定的表结构;
3、高并发读写需求;
4、海量数据的高效率读写;
非关系型数据库
非关系型数据库的特性
1、使用键值对存储数据;
2、分布式;
3、一般不支持ACID特性;
4、非关系型数据库严格上不是一种数据库,应该是一种数据结构化存储方法的集合。
非关系型数据库的优点
1、无需经过sql层的解析,读写性能很高;
2、基于键值对,数据没有耦合性,容易扩展;
3、存储数据的格式:nosql的存储格式是key,value形式、文档形式、图片形式等等,文档形式、图片形式等等,而关系型数据库则只支持基础类型。
非关系型数据库的缺点
1、不提供sql支持,学习和使用成本较高;
2、无事务处理,附加功能bi和报表等支持也不好;
-
MySQL常见数据库引擎及比较?
MySQL存储引擎简介
MySQL支持数个存储引擎作为对不同表的类型的处理器。MySQL存储引擎包括处理事务安全表的引擎和处理非事务安全表的引擎:
MyISAM管理非事务表。它提供高速存储和检索,以及全文搜索能力。MyISAM在所有MySQL配置里被支持,它是默认的存储引擎,除非你配置MySQL默认使用另外一个引擎。
MEMORY存储引擎提供“内存中”表。MERGE存储引擎允许集合将被处理同样的MyISAM表作为一个单独的表。就像MyISAM一样,MEMORY和MERGE存储引擎处理非事务表,这两个引擎也都被默认包含在MySQL中。
注:MEMORY存储引擎正式地被确定为HEAP引擎。
InnoDB和BDB存储引擎提供事务安全表。BDB被包含在为支持它的操作系统发布的MySQL-Max二进制分发版里。InnoDB也默认被包括在所 有MySQL 5.1二进制分发版里,你可以按照喜好通过配置MySQL来允许或禁止任一引擎。
EXAMPLE存储引擎是一个“存根”引擎,它不做什么。你可以用这个引擎创建表,但没有数据被存储于其中或从其中检索。这个引擎的目的是服务,在 MySQL源代码中的一个例子,它演示说明如何开始编写新存储引擎。同样,它的主要兴趣是对开发者。
NDB Cluster是被MySQL Cluster用来实现分割到多台计算机上的表的存储引擎。它在MySQL-Max 5.1二进制分发版里提供。这个存储引擎当前只被Linux, Solaris, 和Mac OS X 支持。在未来的MySQL分发版中,我们想要添加其它平台对这个引擎的支持,包括Windows。
ARCHIVE存储引擎被用来无索引地,非常小地覆盖存储的大量数据。
CSV存储引擎把数据以逗号分隔的格式存储在文本文件中。
BLACKHOLE存储引擎接受但不存储数据,并且检索总是返回一个空集。
FEDERATED存储引擎把数据存在远程数据库中。在MySQL 5.1中,它只和MySQL一起工作,使用MySQL C Client API。在未来的分发版中,我们想要让它使用其它驱动器或客户端连接方法连接到另外的数据源。
如何选择最适合你的存储引擎呢?
MyISAM:默认的MySQL插件式存储引擎,它是在Web、数据仓储和其他应用环境下最常使用的存储引擎之一。注意,通过更改STORAGE_ENGINE配置变量,能够方便地更改MySQL服务器的默认存储引擎。
InnoDB:用于事务处理应用程序,具有众多特性,包括ACID事务支持。(提供行级锁)
BDB:可替代InnoDB的事务引擎,支持COMMIT、ROLLBACK和其他事务特性。
Memory:将所有数据保存在RAM中,在需要快速查找引用和其他类似数据的环境下,可提供极快的访问。
Merge:允许MySQL DBA或开发人员将一系列等同的MyISAM表以逻辑方式组合在一起,并作为1个对象引用它们。对于诸如数据仓储等VLDB环境十分适合。
Archive:为大量很少引用的历史、归档、或安全审计信息的存储和检索提供了完美的解决方案。
Federated:能够将多个分离的MySQL服务器链接起来,从多个物理服务器创建一个逻辑数据库。十分适合于分布式环境或数据集市环境。
Cluster/NDB:MySQL的簇式数据库引擎,尤其适合于具有高性能查找要求的应用程序,这类查找需求还要求具有最高的正常工作时间和可用性。
Other:其他存储引擎包括CSV(引用由逗号隔开的用作数据库表的文件),Blackhole(用于临时禁止对数据库的应用程序输入),以及Example引擎(可为快速创建定制的插件式存储引擎提供帮助)。
MySQL存储引擎比较
MyISAM
MyISAM是MySQL的默认存储引擎。MyISAM不支持事务、也不支持外键,但其访问(读)速度快,对事务完整性没有要求。
MyISAM除了提供ISAM里所没有的索引和字段管理的大量功能,MyISAM还使用一种表格锁定的机制,来优化多个并发的读写操作,其代价是你需要经常运行OPTIMIZE TABLE命令,来恢复被更新机制所浪费的空间。MyISAM还有一些有用的扩展,例如用来修复数据库文件的MyISAMCHK工具和用来恢复浪费空间的MyISAMPACK工具。MYISAM强调了快速读取操作,这可能就是为什么MySQL受到了WEB开发如此青睐的主要原因:在WEB开发中你所进行的大量数据操作都是读取操作。所以,大多数虚拟主机提供商和INTERNET平台提供商只允许使用MYISAM格式。MyISAM格式的一个重要缺陷就是不能在表损坏后恢复数据。
InnoDB存储引擎提供了具有提交、回滚和崩溃恢复能力的事务安全。但是比起MyISAM存储引擎,InnoDB写的处理效率差一些并且会占用更多的磁盘空间以保留数据和索引。
MEMORY/HEAP
MEMORY(又叫HEAP)存储引擎使用存在内存中的内容来创建表。每个MEMORY表只实际对应一个磁盘文件。MEMORY类型的表访问非常得快,因为它的数据是放在内存中的,并且默认使用HASH索引。但是一旦服务关闭,表中的数据就会丢失掉。 HEAP允许只驻留在内存里的临时表格。驻留在内存里让HEAP要比ISAM和MYISAM都快,但是它所管理的数据是不稳定的,而且如果在关机之前没有进行保存,那么所有的数据都会丢失。在数据行被删除的时候,HEAP也不会浪费大量的空间。HEAP表格在你需要使用SELECT表达式来选择和操控数据的时候非常有用。
MEMORY主要用于那些内容变化不频繁的代码表,或者作为统计操作的中间结果表,便于高效地堆中间结果进行分析并得到最终的统计结果。
MERGE
MERGE存储引擎是一组MyISAM表的组合,这些MyISAM表必须结构完全相同。MERGE表本身没有数据,对MERGE类型的表进行查询、更新、删除的操作,就是对内部的MyISAM表进行的。 MERGE用于将一系列等同的MyISAM表以逻辑方式组合在一起,并作为一个对象引用它。MERGE表的优点在于可以突破对单个MyISAM表大小的限制,通过将不同的表分布在多个磁盘上,可以有效的改善MERGE表的访问效率。
MyISAM与InnoDB的区别
InnoDB和MyISAM是许多人在使用MySQL时最常用的两个表类型,这两个表类型各有优劣,视具体应用而定。基本的差别为:MyISAM类型不支持事务处理等高级处理,而InnoDB类型支持。MyISAM类型的表强调的是性能,其执行数度比InnoDB类型更快,但是不提供事务支持,而InnoDB提供事务支持已经外部键等高级数据库功能。
MyISAM表还支持3中不同的存储格式: 静态表 、 动态表 、压缩表
静态表是默认的存储格式,静态表中的字段都是非变长的字段,优点是:存储非常迅速,容易缓存,出现故障容易恢复;缺点是:占用的空间通常比动态表多。(注意: 在存储时,列的宽度不足时,用空格补足,当时在访问的时候并不会得到这些空格)
动态表的字段是变长的,优点是:占用的空间相对较少,但是频繁地更新删除记录会产生碎片,需要定期改善性能,并且出现故障的时候恢复相对比较困难。
压缩表占用磁盘空间小,每个记录是被单独压缩的,所以只有非常小的访问开支。
InnoDB存储方式为两种:使用共享表空间存储 、使用多表空间
-
简述数据三大范式?
什么是范式?
简言之就是,数据库设计对数据的存储性能,还有开发人员对数据的操作都有莫大的关系。所以建立科学的,规范的的数据库是需要满足一些规范的来优化数据数据存储方式。在关系型数据库中这些规范就可以称为范式。(简单来说,就是根据需要,来优化数据存储方式!)
什么是三大范式?
第一范式:当关系模式R的所有属性都不能在分解为更基本的数据单位时,称R是满足第一范式的,简记为1NF。满足第一范式是关系模式规范化的最低要求,否则,将有很多基本操作在这样的关系模式中实现不了。(说白了,就是关系模式R的所有属性不能再分解了,那么R就满足第一范式!)
特性:
1、每一列属性都是不可再分的属性值,确保每一列的原子性
2、两列的属性相近或相似或一样,尽量合并属性一样的列,确保不产生冗余数据。
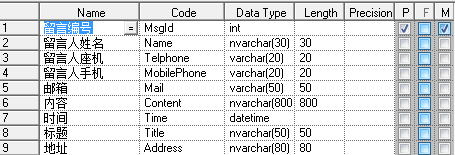
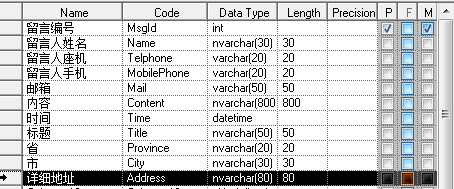
如果需求知道那个省那个市并按其分类,那么显然第一个表格是不容易满足需求的,也不符合第一范式。
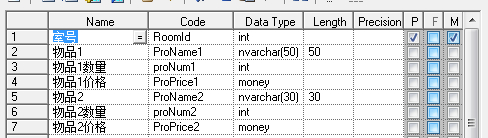

显然第一个表结构不但不能满足足够多物品的要求,还会在物品少时产生冗余。也是不符合第一范式的。
第二范式:如果关系模式R满足第一范式,并且R得所有非主属性都完全依赖于R的每一个候选关键属性,称R满足第二范式,简记为2NF。(说白了,就是非主属性都要依赖于每一个关键属性!)
每一行的数据只能与其中一列相关,即一行数据只做一件事。只要数据列中出现数据重复,就要把表拆分开来。
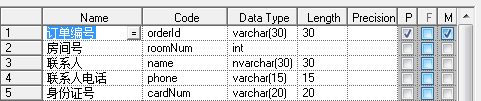
一个人同时订几个房间,就会出来一个订单号多条数据,这样子联系人都是重复的,就会造成数据冗余。我们应该把他拆开来。


这样便实现一条数据做一件事,不掺杂复杂的关系逻辑。同时对表数据的更新维护也更易操作。
第三范式:设R是一个满足第一范式条件的关系模式,X是R的任意属性集,如果X非传递依赖于R的任意一个候选关键字,称R满足第三范式,简记为3NF.
数据不能存在传递关系,即没个属性都跟主键有直接关系而不是间接关系。像:a-->b-->c 属性之间含有这样的关系,是不符合第三范式的。
比如Student表(学号,姓名,年龄,性别,所在院校,院校地址,院校电话)
这样一个表结构,就存在上述关系。 学号--> 所在院校 --> (院校地址,院校电话)
这样的表结构,我们应该拆开来,如下。
(学号,姓名,年龄,性别,所在院校)--(所在院校,院校地址,院校电话)
-
什么是事务?MySQL如何支持事务?
什么是事务?
事务是由一步或几步数据库操作序列组成逻辑执行单元,这系列操作要么全部执行,要么全部放弃执行。程序和事务是两个不同的概念。一般而言:一段程序中可能包含多个事务。(说白了就是几步的数据库操作而构成的逻辑执行单元)
事务具有四个特性:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持续性(Durability)。这四个特性也简称ACID性。
(1)原子性:事务是应用中最小的执行单位,就如原子是自然界最小颗粒,具有不可再分的特征一样。事务是应用中不可再分的最小逻辑执行体。(最小了,不可再分了)
(2)一致性:事务执行的结果,必须使数据库从一个一致性状态,变到另一个一致性状态。当数据库中只包含事务成功提交的结果时,数据库处于一致性状态。一致性是通过原子性来保证的。(说罢了就是白狗变成了黑狗,不能出现斑点狗!)
(3)隔离性:各个事务的执行互不干扰,任意一个事务的内部操作对其他并发的事务,都是隔离的。也就是说:并发执行的事务之间不能看到对方的中间状态,并发执行的事务之间不能相互影响。(说白了,就是你做你的,我做我的!)
(4)持续性:持续性也称为持久性,指事务一旦提交,对数据所做的任何改变,都要记录到永久存储器中,通常是保存进物理数据库。(说白了就是一条道跑到黑)
MySQL如何支持事务?
MYSQL的事务处理主要有两种方法
1.用begin,rollback,commit来实现
begin开始一个事务
rollback事务回滚
commit 事务确认
2.直接用set来改变mysql的自动提交模式
mysql默认是自动提交的,也就是你提交一个query,就直接执行!可以通过
set autocommit = 0 禁止自动提交
set autocommit = 1 开启自动提交
来实现事务的处理
-
简述数据库设计中一对多和多对多的应用场景?
-
如何基于数据库实现商城商品计数器?
-
常见SQL(必备)
-
数据库操作
1、显示数据库
1SHOW DATABASES;2、创建数据库
12345# utf-8CREATE DATABASE 数据库名称 DEFAULT CHARSET utf8 COLLATE utf8_general_ci;# gbkCREATE DATABASE 数据库名称 DEFAULT CHARACTER SET gbk COLLATE gbk_chinese_ci;3、使用数据库
1USE db_name;显示当前使用的数据库中所有表:SHOW TABLES;
4、用户管理
12345678910创建用户create user'用户名'@'IP地址'identified by'密码';删除用户drop user'用户名'@'IP地址';修改用户rename user'用户名'@'IP地址'; to'新用户名'@'IP地址';;修改密码set passwordfor'用户名'@'IP地址'= Password('新密码')PS:用户权限相关数据保存在mysql数据库的user表中,所以也可以直接对其进行操作(不建议)5、授权管理
123show grantsfor'用户'@'IP地址'-- 查看权限grant 权限 on 数据库.表 to'用户'@'IP地址'-- 授权revoke 权限 on 数据库.表 from'用户'@'IP地址'-- 取消权限 -
、数据表基本
1、创建表
1234create table 表名(列名 类型 是否可以为空,列名 类型 是否可以为空)ENGINE=InnoDB DEFAULT CHARSET=utf8 -
2、删除表
1drop table 表名3、清空表
12deletefrom 表名truncate table 表名4、修改表
1234567891011121314151617添加列:alter table 表名 add 列名 类型删除列:alter table 表名 drop column 列名修改列:alter table 表名 modify column 列名 类型; -- 类型alter table 表名 change 原列名 新列名 类型; -- 列名,类型添加主键:alter table 表名 add primary key(列名);删除主键:alter table 表名 drop primary key;alter table 表名 modify 列名 int, drop primary key;添加外键:alter table 从表 add constraint 外键名称(形如:FK_从表_主表) foreign key 从表(外键字段) references 主表(主键字段);删除外键:alter table 表名 drop foreign key 外键名称修改默认值:ALTER TABLE testalter_tbl ALTER i SET DEFAULT 1000;删除默认值:ALTER TABLE testalter_tbl ALTER i DROP DEFAULT;5、基本数据类型
MySQL的数据类型大致分为:数值、时间和字符串
-
表内容操作
1、增
123insertinto表 (列名,列名...)values(值,值,值...)insertinto表 (列名,列名...)values(值,值,值...),(值,值,值...)insertinto表 (列名,列名...)select(列名,列名...)from表2、删
12deletefrom表deletefrom表whereid=1andname='alex'3、改
1update表setname='alex'whereid>14、查
123select*from表select*from表whereid > 1selectnid,name,genderasggfrom表whereid > 15、其他
-
MySQL服务器默认端口是什么?
MySQL服务器的默认端口是3306。
-
什么是数据库约束,常见的约束有哪几种?
数据库约束用于保证数据库表数据的完整性(正确性和一致性)。可以通过定义约束\索引\触发器来保证数据的完整性。总体来讲,约束可以分为:主键约束:primary key;外键约束:foreign key;唯一约束:unique;检查约束:check;空值约束:not null;默认值约束:default; -
MySQL基本语法
增:创建数据表
USE database CREATE TABLE example(id INT, name VARCHAR(20), sex BOOLEAN);删:
ALTER TABLE 表名 DROP 属性名; # 删除字段 DROP TABLE 表名; # 删除表改:
ALTER TABLE 旧表名 RENAME 新表名; # 修改表名 ALTER TABLE 表名 MODIFY 属性名 数据类型; # 修改字段数据类型查:
SELECT * FROM 表名 WHERE id=1; # 条件查询 SELECT * FROM 表名 WHERE 字段名 BETWEEN 条件一 AND 条件二 # 范围查询 SELECT COUNT(*) FROM 表名; # 查询表共有多少条记录触发器:是由INSERT、UPDATE和DELETE等事件来触发某种特定操作,满足触发条件时,数据库系统会执行触发器中定义的语句,这样可以保证某些操作之间的一致性。
CREATE TRIGGER 触发器名称 BEFORE|AFTER 触发事件 ON 表名称 FOR EACH ROW BEGIN 执行语句 END -
简述触发器、函数、视图、存储过程?
1、视图
视图只是一种逻辑对象,是一种虚拟表,它并不是物理对象,因为视图不占物理存储空间,在视图中被查询的表称为视图的基表,大多数的select语句都可以用在创建视图中(说白了,视图就是一种虚拟表,就像是一张电子照片)
优点:集中用户使用的数据,掩码数据的复杂性,简化权限管理以及为向其他应用程序输出而重新组织数据等
2、触发器
(1)触发器是一个特殊的存储过程,它是MySQL在insert、update、delete的时候自动执行的代码块。
(2)触发器必须定义在特定的表上。
(3)自动执行,不能直接调用,
(说白了,触发器其实就是一个神,他会待在自己的庙宇中,当百姓受难了,通过一些祷告仪式,如insert、update、delete,他会自动的进行降妖除魔!)
3、函数
它跟php或js中的函数几乎一样:需要先定义,然后调用(使用)。
只是规定,这个函数,必须要返回数据——要有返回值
4、存储过程
存储过程(procedure),概念类似于函数,就是把一段代码封装起来,当要执行这一段代码的时候,可以通过调用该存储过程来实现。在封装的语句体里面,可以同if/else ,case,while等控制结构,可以进行sql编程,查看现有的存储过程。
-
MySQL索引种类
1、普通索引
这是最基本的索引,它没有任何限制,比如上文中为title字段创建的索引就是一个普通索引,MyIASM中默认的BTREE类型的索引,也是我们大多数情况下用到的索引。

–直接创建索引 CREATE INDEX index_name ON table(column(length)) –修改表结构的方式添加索引 ALTER TABLE table_name ADD INDEX index_name ON (column(length)) –创建表的时候同时创建索引 CREATE TABLE `table` ( `id` int(11) NOT NULL AUTO_INCREMENT , `title` char(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL , `content` text CHARACTER SET utf8 COLLATE utf8_general_ci NULL , `time` int(10) NULL DEFAULT NULL , PRIMARY KEY (`id`), INDEX index_name (title(length)) ) –删除索引 DROP INDEX index_name ON table
2、 唯一索引
与普通索引类似,不同的就是:索引列的值必须唯一,但允许有空值(注意和主键不同)。如果是组合索引,则列值的组合必须唯一,创建方法和普通索引类似。
–创建唯一索引 CREATE UNIQUE INDEX indexName ON table(column(length)) –修改表结构 ALTER TABLE table_name ADD UNIQUE indexName ON (column(length)) –创建表的时候直接指定 CREATE TABLE `table` ( `id` int(11) NOT NULL AUTO_INCREMENT , `title` char(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL , `content` text CHARACTER SET utf8 COLLATE utf8_general_ci NULL , `time` int(10) NULL DEFAULT NULL , PRIMARY KEY (`id`), UNIQUE indexName (title(length)) );
3、全文索引(FULLTEXT)
MySQL从3.23.23版开始支持全文索引和全文检索,FULLTEXT索引仅可用于 MyISAM 表;他们可以从CHAR、VARCHAR或TEXT列中作为CREATE TABLE语句的一部分被创建,或是随后使用ALTER TABLE 或CREATE INDEX被添加。////对于较大的数据集,将你的资料输入一个没有FULLTEXT索引的表中,然后创建索引,其速度比把资料输入现有FULLTEXT索引的速度更为快。不过切记对于大容量的数据表,生成全文索引是一个非常消耗时间非常消耗硬盘空间的做法。
–创建表的适合添加全文索引 CREATE TABLE `table` ( `id` int(11) NOT NULL AUTO_INCREMENT , `title` char(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL , `content` text CHARACTER SET utf8 COLLATE utf8_general_ci NULL , `time` int(10) NULL DEFAULT NULL , PRIMARY KEY (`id`), FULLTEXT (content) ); –修改表结构添加全文索引 ALTER TABLE article ADD FULLTEXT index_content(content) –直接创建索引 CREATE FULLTEXT INDEX index_content ON article(content)
4.、单列索引、多列索引
多个单列索引与单个多列索引的查询效果不同,因为执行查询时,MySQL只能使用一个索引,会从多个索引中选择一个限制最为严格的索引。
5.、组合索引(最左前缀)
平时用的SQL查询语句一般都有比较多的限制条件,所以为了进一步榨取MySQL的效率,就要考虑建立组合索引。例如上表中针对title和time建立一个组合索引:ALTER TABLE article ADD INDEX index_titme_time (title(50),time(10))。建立这样的组合索引,其实是相当于分别建立了下面两组组合索引:
–title,time
–title
为什么没有time这样的组合索引呢?这是因为MySQL组合索引“最左前缀”的结果。简单的理解就是只从最左面的开始组合。并不是只要包含这两列的查询都会用到该组合索引,如下面的几个SQL所示:
–使用到上面的索引 SELECT * FROM article WHREE title='测试' AND time=1234567890; SELECT * FROM article WHREE utitle='测试'; –不使用上面的索引 SELECT * FROM article WHREE time=1234567890;
-
索引在什么情况下遵循最左前缀的规则?
索引的最左前缀原理:
通常我们在建立联合索引的时候,也就是对多个字段建立索引,相信建立过索引的同学们会发现,无论是oralce还是mysql都会让我们选择索引的顺序,比如我们想在a,b,c三个字段上建立一个联合索引,我们可以选择自己想要的优先级,a、b、c,或者是b、a、c 或者是c、a、b等顺序。为什么数据库会让我们选择字段的顺序呢?不都是三个字段的联合索引么?这里就引出了数据库索引的最左前缀原理。
比如:索引index1:(a,b,c)有三个字段,我们在使用sql语句来查询的时候,会发现很多情况下不按照我们想象的来走索引。
select * from table where c = '1'
这个sql语句是不会走index1索引的
select * from table where b =‘1’ and c ='2'
这个语句也不会走index1索引。
什么语句会走index1索引呢?
答案是:
select * from table where a = '1' select * from table where a = '1' and b = ‘2’ select * from table where a = '1' and b = ‘2’ and c='3'
我们可以发现一个共同点,就是所有走索引index1的sql语句的查询条件里面都带有a字段,那么问题来了,index1的索引的最左边的列字段是a,是不是查询条件中包含a就会走索引呢?
例如:
select * from table where a = '1' and c= ‘2’
这个sql语句,按照之前的理解,包含a字段,会走索引,但是是不是所有字段都走了索引呢?
我们来做个实验:
我这里有一个表:

建立了一个联合索引,prinIdAndOrder里面有三个字段 PARENT_ID, MENU_ORDER, MENU_NAME
接下来测试之前的语句:
EXPLAIN SELECT t.* FROM sys_menu t WHERE t.`PARENT_ID` = '0' AND t.`MENU_NAME` = '系统工具'
这一句sql就相当于之前的select * from table where a = '1' and c= ‘2’这个sql语句了,我们来看看解释计划:
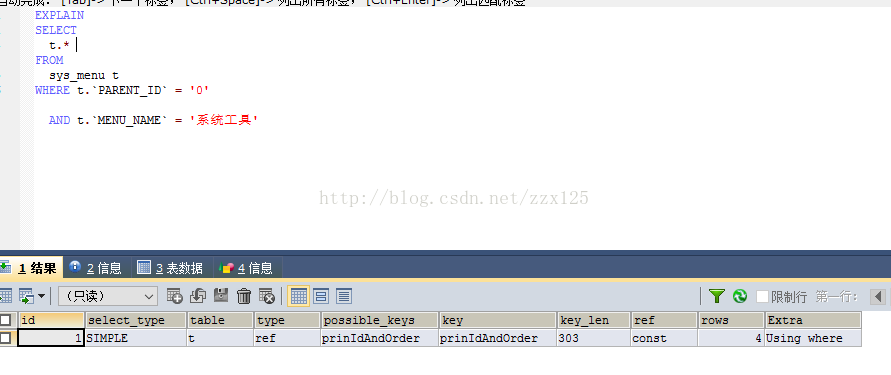
可以看到走了索引prinIdAndOrder,但是旁边的key_len=303,但道理key_len应该是大于303的,为什么呢?因为PARENT_ID字段的类型是varchar(100) NULL,所以key_len=100*3+2+1=303,但是还有MENU_NAME呢!具体的key_len的计算方法,大家可以百度,我的表的字符集是utf-8,不同字符集的表的计算方式不一样。这里的解释计划显示key_len只有303,说明只是走了字段PARENT_ID的索引,没有走MENU_NAME的索引。
这也是最左前缀原理的一部分,索引index1:(a,b,c),只会走a、a,b、a,b,c 三种类型的查询,其实这里说的有一点问题,a,c也走,但是只走a字段索引,不会走c字段。
另外还有一个特殊情况说明下,select * from table where a = '1' and b > ‘2’ and c='3' 这种类型的也只会有a与b走索引,c不会走。
像select * from table where a = '1' and b > ‘2’ and c='3' 这种类型的sql语句,在a、b走完索引后,c肯定是无序了,所以c就没法走索引,数据库会觉得还不如全表扫描c字段来的快。不知道我说明白没,感觉这一块说的始终有点牵强。
-
主键和外键的区别?
主键
定义:唯一标识一条记录,不能有重复的,不允许为空
作用:用来保证数据完整性
个数:主键只能有一个
ALTER TABLE “表名” ADD PRIMARY KEY (字段名)
外键
定义:表的外键是另一表的主键, 外键可以有重复的, 可以是空值
作用:用来和其他表建立联系用的
个数:一个表可以有多个外键
ALTER TABLE “表名” ADD FOREIGN KEY (字段名) REFERENCES “另一张表名”( 字段名)
-
MySQL常见的函数?
-
列举 创建索引但是无法命中索引的8种情况。
1、如果条件中有or,即使其中有条件带索引也不会使用(这也是为什么尽量少用or的原因)
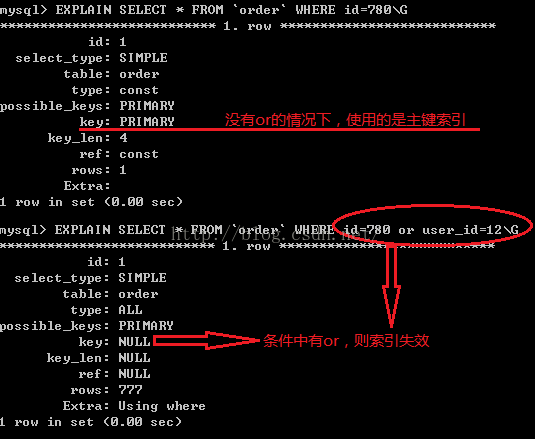
注意:要想使用or,又想让索引生效,只能将or条件中的每个列都加上索引
2、对于多列索引,不是使用的第一部分(第一个),则不会使用索引
3、like查询是以%开头
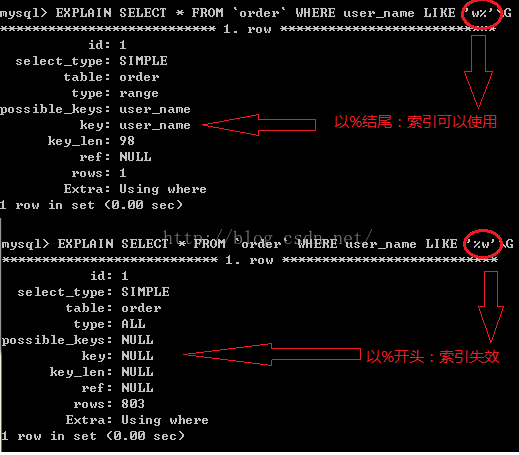
4、如果列类型是字符串,那一定要在条件中将数据使用引号引用起来,否则不使用索引

5、如果mysql估计使用全表扫描要比使用索引快,则不使用索引
其他

-
如何开启慢日志查询?
1、为什么要开启慢日志查询?
开启慢查询日志,可以让MySQL记录下查询超过指定时间的语句,通过定位分析性能的瓶颈,才能更好的优化数据库系统的性能。
2、参数说明
slow_query_log 慢查询开启状态
slow_query_log_file 慢查询日志存放的位置(这个目录需要MySQL的运行帐号的可写权限,一般设置为MySQL的数据存放目录)
long_query_time 查询超过多少秒才记录
3、设置步骤
①.查看慢查询相关参数
mysql> show variables like 'slow_query%'; +---------------------------+----------------------------------+ | Variable_name | Value | +---------------------------+----------------------------------+ | slow_query_log | OFF | | slow_query_log_file | /mysql/data/localhost-slow.log | +---------------------------+----------------------------------+ mysql> show variables like 'long_query_time'; +-----------------+-----------+ | Variable_name | Value | +-----------------+-----------+ | long_query_time | 10.000000 | +-----------------+-----------+
②.设置方法
将 slow_query_log 全局变量设置为“ON”状态
mysql> set global slow_query_log='ON';

设置慢查询日志存放的位置
mysql> set global slow_query_log_file='/var/lib/mysql/test-10-226-slow.log';

查询超过1秒就记录
mysql> set global long_query_time=1;

经过这些操作,则慢日志查询也就开启了!但这种方法只是临时生效,mysql重启后就会失效
所以我们不能让他失效,所以需进行如下操作
编辑配置文件/etc/my.cnf加入如下内容
[mysqld] slow_query_log = ON slow_query_log_file = /var/lib/mysql/test-10-226-slow.log long_query_time = 1
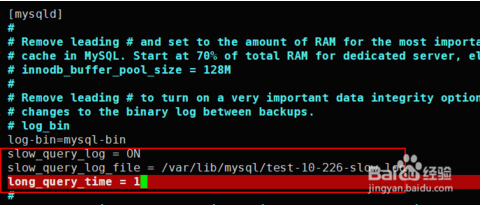
修改配置后重启
mysql
systemctl restart mysqld mysql -uroot -p
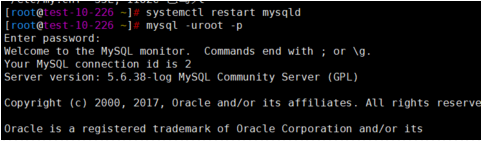
使用下面命令验证
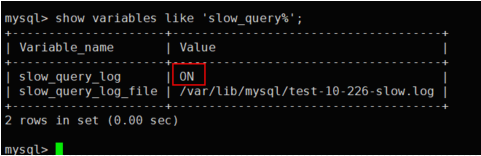
show variables like 'slow_query%';
mysql永久开启了漫查询日志功能
-
数据库导入导出命令(结构+数据)?
在命令行下mysql的数据导出有个很好用命令mysqldump,它的参数有一大把,可以这样查看:
mysqldump
(mysqldump命令位于mysql/bin/目录中) //要专到mysql/bin/目录中才能使用,直接cmd运行命令窗口使用不了,专到数据库所在的mysql/bin/目录中使用.
最常用的:
mysqldump -uroot -pmysql databasefoo table1 table2 > foo.sql
这样就可以将数据库databasefoo的表table1,table2以sql形式导入foo.sql中,其中-uroot参数表示访问数据库的用户名是root,如果有密码还需要加上-p参数
C:\Users\jack> mysqldump -uroot -pmysql sva_rec date_drv > e:\date_drv.sql
mysql的数据导入也是相当便捷的,如:
mysql -uroot databasefoo < foo.sql
这样就可以将foo.sql的数据全部导入数据库databasefoo
导出整个数据库
mysqldump -u用户名 -p密码 数据库名 > 导出的文件名
C:\Users\jack> mysqldump -uroot -pmysql sva_rec > e:\sva_rec.sql
导出一个表,包括表结构和数据
mysqldump -u用户名 -p 密码 数据库名 表名> 导出的文件名
C:\Users\jack> mysqldump -uroot -pmysql sva_rec date_rec_drv> e:\date_rec_drv.sql
导出一个数据库结构
C:\Users\jack> mysqldump -uroot -pmysql -d sva_rec > e:\sva_rec.sql
导出一个表,只有表结构
mysqldump -u用户名 -p 密码 -d数据库名 表名> 导出的文件名
C:\Users\jack> mysqldump -uroot -pmysql -d sva_rec date_rec_drv> e:\date_rec_drv.sql
导入数据库
常用source 命令
进入mysql数据库控制台,
如mysql -u root -p
mysql>use 数据库
然后使用source命令,后面参数为脚本文件(如这里用到的.sql)
mysql>source d:wcnc_db.sql
-
数据库优化方案?
关于数据库的优化方案,可参考下面的链接
-
char和varchar的区别?
就长度来说:
♣ char的长度是不可变的;
♣ 而varchar的长度是可变的,也就是说,定义一个char[10]和varchar[10],如果存进去的是‘csdn’,那么char所占的长度依然为10,除了字符‘csdn’外,后面跟六个空格,而varchar就立马把长度变为4了,取数据的时候,char类型的要用trim()去掉多余的空格,而varchar是不需要的,尽管如此,char的存取速度还是要比varchar要快得多,因为其长度固定,方便程序的存储与查找;但是char也为此付出的是空间的代价,因为其长度固定,所以难免会有多余的空格占位符占据空间,可谓是以空间换取时间效率,而varchar是以空间效率为首位的。
就存储方式来说:
♣ char的存储方式是,对英文字符(ASCII)占用1个字节,对一个汉字占用两个字节;
♣ 而varchar的存储方式是,对每个英文字符占用2个字节,汉字也占用2个字节,两者的存储数据都非unicode的字符数据。
-
简述MySQL的执行计划?
https://www.cnblogs.com/xinysu/p/7860609.html
-
在对name做了唯一索引前提下,简述以下区别:
select * from tb where name = ‘Oldboy-Wupeiqi’
select * from tb where name = ‘Oldboy-Wupeiqi’ limit 1 -
1000w条数据,使用limit offset 分页时,为什么越往后翻越慢?如何解决?
在mysql中limit可以实现快速分页,但是如果数据到了几百万时我们的limit必须优化才能有效的合理的实现分页了,否则可能卡死你的服务器哦。
当一个表数据有几百万的数据的时候成了问题!
如 * from table limit 0,10 这个没有问题 当 limit 200000,10 的时候数据读取就很慢,可以按照一下方法解决第一页会很快
PERCONA PERFORMANCE CONFERENCE 2009上,来自雅虎的几位工程师带来了一篇”EfficientPagination Using MySQL”的报告
limit10000,20的意思扫描满足条件的10020行,扔掉前面的10000行,返回最后的20行,问题就在这里。
LIMIT 451350 , 30 扫描了45万多行,怪不得慢的都堵死了。
但是,limit 30 这样的语句仅仅扫描30行。
那么如果我们之前记录了最大ID,就可以在这里做文章
举个例子
日常分页SQL语句
select id,name,content from users order by id asc limit 100000,20
扫描100020行
如果记录了上次的最大ID
select id,name,content from users where id>10073 order by id asc limit 20
扫描20行。
总数据有500万左右
以下例子 当 select * from wl_tagindex where byname='f' order by id limit 300000,10 执行时间是 3.21s
优化后:
select * from ( select id from wl_tagindex where byname='f' order by id limit 300000,10 ) a left join wl_tagindex b on a.id=b.id
执行时间为 0.11s 速度明显提升
这里需要说明的是 我这里用到的字段是 byname ,id 需要把这两个字段做复合索引,否则的话效果提升不明显
总结
当一个数据库表过于庞大,LIMIT offset, length中的offset值过大,则SQL查询语句会非常缓慢,你需增加order by,并且order by字段需要建立索引。
如果使用子查询去优化LIMIT的话,则子查询必须是连续的,某种意义来讲,子查询不应该有where条件,where会过滤数据,使数据失去连续性。
如果你查询的记录比较大,并且数据传输量比较大,比如包含了text类型的field,则可以通过建立子查询。
SELECT id,title,content FROM items WHERE id IN (SELECT id FROM items ORDER BY id limit 900000, 10);
如果limit语句的offset较大,你可以通过传递pk键值来减小offset = 0,这个主键最好是int类型并且auto_increment
SELECT * FROM users WHERE uid > 456891 ORDER BY uid LIMIT 0, 10;
这条语句,大意如下:
SELECT * FROM users WHERE uid >= (SELECT uid FROM users ORDER BY uid limit 895682, 1) limit 0, 10;
如果limit的offset值过大,用户也会翻页疲劳,你可以设置一个offset最大的,超过了可以另行处理,一般连续翻页过大,用户体验很差,则应该提供更优的用户体验给用户。
关于limit 分页优化方法请参考下面的链接:
MYSQL分页limit速度太慢的优化方法
-
什么是索引合并?
什么是索引合并?
下面我们看下mysql文档中对索引合并的说明:
The Index Merge method is used to retrieve rows with several range scans and to merge their results into one. The merge can produce unions, intersections, or unions-of-intersections of its underlying scans. This access method merges index scans from a single table; it does not merge scans across multiple tables.
根据官方文档中的说明,我们可以了解到:
1、索引合并是把几个索引的范围扫描合并成一个索引。
2、索引合并的时候,会对索引进行并集,交集或者先交集再并集操作,以便合并成一个索引。
3、这些需要合并的索引只能是一个表的。不能对多表进行索引合并。
怎么确定使用了索引合并?
在使用explain对sql语句进行操作时,如果使用了索引合并,那么在输出内容的type列会显示 index_merge,key列会显示出所有使用的索引。如下:
使用索引合并的示例
数据表结构:
mysql> show create table test\G
*************************** 1. row ***************************
Table: test
Create Table: CREATE TABLE `test` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`key1_part1` int(11) NOT NULL DEFAULT '0',
`key1_part2` int(11) NOT NULL DEFAULT '0',
`key2_part1` int(11) NOT NULL DEFAULT '0',
`key2_part2` int(11) NOT NULL DEFAULT '0',
PRIMARY KEY (`id`),
KEY `key1` (`key1_part1`,`key1_part2`),
KEY `key2` (`key2_part1`,`key2_part2`)
) ENGINE=MyISAM AUTO_INCREMENT=18 DEFAULT CHARSET=utf8
1 row in set (0.00 sec)
数据

使用索引合并的案例
mysql> explain select * from test where (key1_part1=4 and key1_part2=4) or key2_part1=4\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: test
type: index_merge
possible_keys: key1,key2
key: key1,key2
key_len: 8,4
ref: NULL
rows: 3
Extra: Using sort_union(key1,key2); Using where
1 row in set (0.00 sec)
未使用索引合并的案例
mysql> explain select * from test where (key1_part1=1 and key1_part2=1) or key2_part1=4\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: test
type: ALL
possible_keys: key1,key2
key: NULL
key_len: NULL
ref: NULL
rows: 29
Extra: Using where
1 row in set (0.00 sec)
从上面的两个案例大家可以发现,相同模式的sql语句,可能有时能使用索引,有时不能使用索引。是否能使用索引,取决于mysql查询优化器对统计数据分析后,是否认为使用索引更快。因此,单纯的讨论一条sql是否可以使用索引有点片面,还需要考虑数据。
注意事项
mysql5.6.7之前的版本遵守range优先的原则。也就是说,当一个索引的一个连续段,包含所有符合查询要求的数据时,哪怕索引合并能提供效率,也不再使用索引合并。举个例子:
mysql> explain select * from test where (key1_part1=1 and key1_part2=1) and key2_part1=1\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: test
type: ref
possible_keys: key1,key2
key: key2
key_len: 4
ref: const
rows: 9
Extra: Using where
1 row in set (0.00 sec)
上面符合查询要求的结果只有一条,而这一条记录被索引key2所包含。
可以看到这条sql语句使用了key2索引。但是这个并不是最快的执行方式。其实,把索引key1和索引key2进行索引合并,取交集后,就发现只有一条记录适合。应该查询效率会更快。
tips:这条sql语句未在mysql5.6.7之后版本执行验证,以上为理论推导。有兴趣的话,您可以到mysql5.6.7之后版本上验证下。
-
什么是覆盖索引?
什么是覆盖索引?
通常开发人员会根据查询的where条件来创建合适的索引,但是优秀的索引设计应该考虑到整个查询。其实mysql可以使用索引来直接获取列的数据。如果索引的叶子节点包含了要查询的数据,那么就不用回表查询了,也就是说这种索引包含(亦称覆盖)所有需要查询的字段的值,我们称这种索引为覆盖索引。
注:引入数据表t_user,插入约1千万条记录,用作下文例子使用。

1、工欲善其事,必先利其器
explain命令是查看查询优化器如何决定执行查询的主要方法。要使用此命令,只需要在select关键字之前添加这个命令即可。当执行查询时,它会返回信息,显示出执行计划中的每一部分和执行的次序,而并非真正执行这个查询。如下所示,是执行explain的显示结果,其中sql语句中的\G表示将输出按列显示:

当发起一个被索引覆盖的查询时,在explain的Extra列可以看到 Using index的标识。
2、场景查询表中name列有值的记录数
(1)查询表中name列有值的记录数
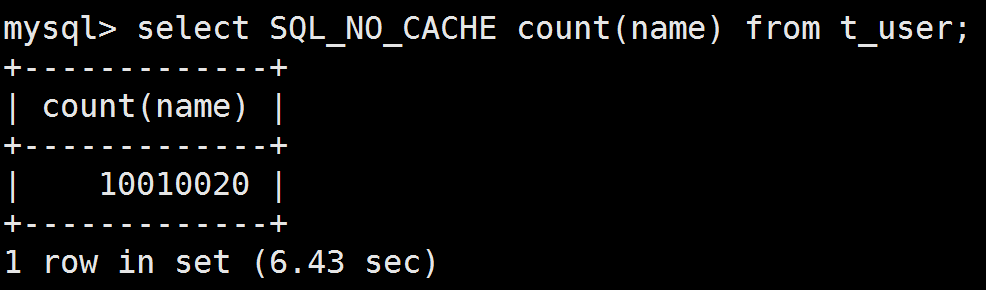
查询语句用SQL_NO_CACHE关键字来禁止缓存查询结果。此查询耗时6.43秒
(2)执行计划

从图的执行计划得知,type:ALL,表示MySQL扫描整张表,从头到尾去找到需要的行。下面对此查询列建立索引。
(3)为name列建立索引

(4)重新执行的查询sql
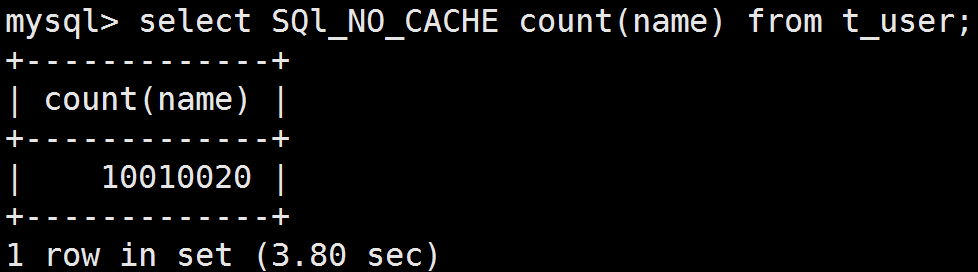
如图所示,为name列建立索引之后,重新执行查询。此时查询耗时3.80秒,比未加索引提高了2.63秒
(5)重新查看执行计划

从图的查询计划可知,type:index,这个跟全表扫描一样,只是MySQL扫描表时按索引次序进行而不是行。但是看到Extra:Using index,说明MySQL正在使用覆盖索引,它只扫描索引的数据,而不是按索引次序的每一行。它比按索引次序全表扫描的开销少很多。
3、分页查询email
(1)分页查询email

从图可知,分页查询耗时53.99
(2)分页查询执行计划
如图所示,type:All,说明MySQL进行了全表扫描。下面在password和email列上创建联合索引。

(3)添加联合索引

(4)重新分页查询

如图所示,分页查询基本不耗时间。
(5)重新执行查询计划

从图可知,Extra:Using index,MySQL使用了覆盖索引进行查询。查询效率得到极大的提升。
4、覆盖索引总结
回想一下,如果查询只需要扫描索引而无须回表,将带来诸多好处。
(1)索引条目通常远小于数据行大小,如果只读取索引,MySQL就会极大地减少数据访问量。
(2)索引按照列值顺序存储,对于I/O密集的范围查询会比随机从磁盘中读取每一行数据的I/O要少很多。
(3)InnoDB的辅助索引(亦称二级索引)在叶子节点中保存了行的主键值,如果二级索引能够覆盖查询,则可不必对主键索引进行二次查询了。
覆盖索引就是从索引中直接获取查询结果,要使用覆盖索引需要注意select查询列中包含在索引列中;where条件包含索引列或者复合索引的前导列;查询结果的字段长度尽可能少。
-
简述数据库读写分离?
什么是读写分离?
MySQL Proxy最强大的一项功能是实现“读写分离(Read/Write Splitting)”。基本的原理是让主数据库处理事务性查询,而从数据库处理SELECT查询。数据库复制被用来把事务性查询导致的变更同步到集群中的从数据库。 当然,主服务器也可以提供查询服务。使用读写分离最大的作用无非是环境服务器压力。可以看下这张图:

读写分离的好处
1、增加冗余
2、增加了机器的处理能力
3、对于读操作为主的应用,使用读写分离是最好的场景,因为可以确保写的服务器压力更小,而读又可以接受点时间上的延迟。
读写分离提高性能之原因
1、物理服务器增加,负荷增加
2、主从只负责各自的写和读,极大程度的缓解X锁和S锁争用
3、从库可配置myisam引擎,提升查询性能以及节约系统开销
4、从库同步主库的数据和主库直接写还是有区别的,通过主库发送来的binlog恢复数据,但是,最重要区别在于主库向从库发送binlog是异步的,从库恢复数据也是异步的
5、读写分离适用与读远大于写的场景,如果只有一台服务器,当select很多时,update和delete会被这些select访问中的数据堵塞,等待select结束,并发性能不高。 对于写和读比例相近的应用,应该部署双主相互复制
6、可以在从库启动是增加一些参数来提高其读的性能,例如--skip-innodb、--skip-bdb、--low-priority-updates以及--delay-key-write=ALL。当然这些设置也是需要根据具体业务需求来定得,不一定能用上
7、分摊读取。假如我们有1主3从,不考虑上述1中提到的从库单方面设置,假设现在1分钟内有10条写入,150条读取。那么,1主3从相当于共计40条写入,而读取总数没变,因此平均下来每台服务器承担了10条写入和50条读取(主库不承担读取操作)。因此,虽然写入没变,但是读取大大分摊了,提高了系统性能。另外,当读取被分摊后,又间接提高了写入的性能。所以,总体性能提高了,说白了就是拿机器和带宽换性能。MySQL官方文档中有相关演算公式:官方文档 见6.9FAQ之“MySQL复制能够何时和多大程度提高系统性能”
8、MySQL复制另外一大功能是增加冗余,提高可用性,当一台数据库服务器宕机后能通过调整另外一台从库来以最快的速度恢复服务,因此不能光看性能,也就是说1主1从也是可以的。
读写分离示意图
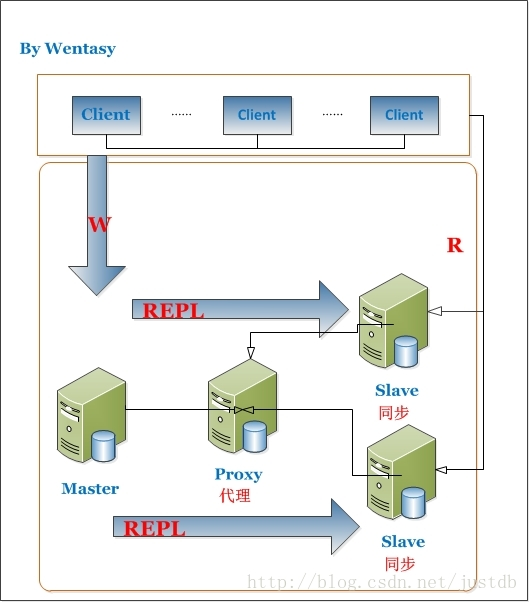
-
简述数据库分库分表?(水平、垂直)
-
Redis是什么
- 是一个完全开源免费的key-value内存数据库
- 通常被认为是一个数据结构服务器,主要是因为其有着丰富的数据结构 strings、map、 list、sets、 sorted sets
redis和memcached比较?
1、Redis和Memcache都是将数据存放在内存中,都是内存数据库。不过memcache还可用于缓存其他东西,例如图片、视频等等;
2、Redis不仅仅支持简单的k/v类型的数据,同时还提供list,set,hash等数据结构的存储;
3、虚拟内存--Redis当物理内存用完时,可以将一些很久没用到的value 交换到磁盘;
4、过期策略--memcache在set时就指定,例如set key1 0 0 8,即永不过期。Redis可以通过例如expire 设定,例如expire name 10;
5、分布式--设定memcache集群,利用magent做一主多从;redis可以做一主多从。都可以一主一从;
6、存储数据安全--memcache挂掉后,数据没了;redis可以定期保存到磁盘(持久化);
7、灾难恢复--memcache挂掉后,数据不可恢复; redis数据丢失后可以通过aof恢复;
8、Redis支持数据的备份,即master-slave模式的数据备份;
-
redis中数据库默认是多少个db 及作用?
redis下,数据库是由一个整数索引标识,而不是由一个数据库名称。默认情况下,一个客户端连接到数据库0。redis配置文件中下面的参数来控制数据库总数:
/etc/redis/redis.conf
文件中,有个配置项 databases = 16 //默认有16个数据库

-
python操作redis的模块?
什么是redis?
redis是一个key-value存储系统。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排序。与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
上面的话好像很专业的样子,这里我们简单的理解为,其实redis就是一个消息中间件,可以作为多个进程的消息中转站,是比之前我们用的manage模块更方便自由的共享内存。
1、基本操作
之前我们已经知道,redis是以key-value的形式存储的,所以我们在操作的时候。首先我们将redis所在主机的ip和发布端口作为参数实例化了一个对象r,然后执行set('name','Eva_J'),这样我们就在内存中存储了一个key为name,值为‘Eva_J’的项。我们可以理解为{'name':'Eva_J'},当我们要读取的之后,只需要get('name'),就会得到'Eva_J'的值。

2、连接池
redis-py使用connection pool来管理对一个redis server的所有连接,避免每次建立、释放连接的开销。默认,每个Redis实例都会维护一个自己的连接池。可以直接建立一个连接池,然后作为参数Redis,这样就可以实现多个Redis实例共享一个连接池。

3、管道
redis-py默认在执行每次请求都会创建(连接池申请连接)和断开(归还连接池)一次连接操作,如果想要在一次请求中指定多个命令,则可以使用pipline实现一次请求指定多个命令,并且默认情况下一次pipline 是原子性操作。
4、发布订阅

发布者:服务器
订阅者:Dashboad和数据处理
Demo如下:
定义一个redishelper类,建立与redis连接,定义频道为fm92.4,定义发布public及订阅subscribe方法。

订阅者:导入刚刚我们写好的类,实例化对象,调用订阅方法,就可以使用while True接收信息了。

发布者:导入刚刚我们写好的类,实例化对象,调用发布方法,下例发布了一条消息‘hello’

-
如果redis中的某个列表中的数据量非常大,如果实现循环显示每一个值?
-
redis如何实现主从复制?以及数据同步机制?
redis主从复制
和Mysql主从复制的原因一样,Redis虽然读取写入的速度都特别快,但是也会产生读压力特别大的情况。为了分担读压力,Redis支持主从复制,Redis的主从结构可以采用一主多从或者级联结构,Redis主从复制可以根据是否是全量分为全量同步和增量同步。下图为级联结构。
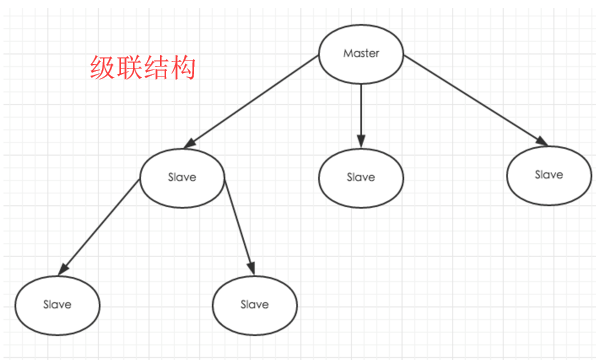
全量同步
Redis全量复制一般发生在Slave初始化阶段,这时Slave需要将Master上的所有数据都复制一份。具体步骤如下:
- 从服务器连接主服务器,发送SYNC命令;
- 主服务器接收到SYNC命名后,开始执行BGSAVE命令生成RDB文件并使用缓冲区记录此后执行的所有写命令;
- 主服务器BGSAVE执行完后,向所有从服务器发送快照文件,并在发送期间继续记录被执行的写命令;
- 从服务器收到快照文件后丢弃所有旧数据,载入收到的快照;
- 主服务器快照发送完毕后开始向从服务器发送缓冲区中的写命令;
- 从服务器完成对快照的载入,开始接收命令请求,并执行来自主服务器缓冲区的写命令;

完成上面几个步骤后就完成了从服务器数据初始化的所有操作,从服务器此时可以接收来自用户的读请求。
增量同步
Redis增量复制是指Slave初始化后开始正常工作时主服务器发生的写操作同步到从服务器的过程。
增量复制的过程主要是主服务器每执行一个写命令就会向从服务器发送相同的写命令,从服务器接收并执行收到的写命令。
Redis主从同步策略
主从刚刚连接的时候,进行全量同步;全同步结束后,进行增量同步。当然,如果有需要,slave 在任何时候都可以发起全量同步。redis 策略是,无论如何,首先会尝试进行增量同步,如不成功,要求从机进行全量同步。
关于其同步机制,请点击这里
-
redis中的sentinel的作用?
Redis-Sentinel是Redis官方推荐的高可用性(HA)解决方案,当用Redis做Master-slave的高可用方案时,假如master宕机了,Redis本身(包括它的很多客户端)都没有实现自动进行主备切换,而Redis-sentinel本身也是一个独立运行的进程,它能监控多个master-slave集群,发现master宕机后能进行自动切换。
它的主要功能有以下几点:
不时地监控redis是否按照预期良好地运行;
如果发现某个redis节点运行出现状况,能够通知另外一个进程(例如它的客户端);
能够进行自动切换。当一个master节点不可用时,能够选举出master的多个slave(如果有超过一个slave的话)中的一个来作为新的master,其它的slave节点会将它所追随的master的地址改为被提升为master的slave的新地址。
Sentinel支持集群
很显然,只使用单个sentinel进程来监控redis集群是不可靠的,当sentinel进程宕掉后(sentinel本身也有单点问题,single-point-of-failure)整个集群系统将无法按照预期的方式运行。所以有必要将sentinel集群,这样有几个好处:
-
即使有一些sentinel进程宕掉了,依然可以进行redis集群的主备切换;
-
如果只有一个sentinel进程,如果这个进程运行出错,或者是网络堵塞,那么将无法实现redis集群的主备切换(单点问题);
-
如果有多个sentinel,redis的客户端可以随意地连接任意一个sentinel来获得关于redis集群中的信息。
Sentinel版本
Sentinel当前最新的稳定版本称为Sentinel 2(与之前的Sentinel 1区分开来)。随着redis2.8的安装包一起发行。安装完Redis2.8后,可以在redis2.8/src/里面找到Redis-sentinel的启动程序。
强烈建议:
如果你使用的是redis2.6(sentinel版本为sentinel 1),你最好应该使用redis2.8版本的sentinel 2,因为sentinel 1有很多的Bug,已经被官方弃用,所以强烈建议使用redis2.8以及sentinel 2。
运行Sentinel
运行sentinel有两种方式:
第一种
redis-sentinel /path/to/sentinel.conf
第二种
redis-server /path/to/sentinel.conf --sentinel
以上两种方式,都必须指定一个sentinel的配置文件sentinel.conf,如果不指定,将无法启动sentinel。sentinel默认监听26379端口,
所以运行前必须确定该端口没有被别的进程占用。
Sentinel的配置
Redis源码包中包含了一个sentinel.conf文件作为sentinel的配置文件,配置文件自带了关于各个配置项的解释。典型的配置项如下所示:
sentinel monitor mymaster 127.0.0.1 6379 2 sentinel down-after-milliseconds mymaster 60000 sentinel failover-timeout mymaster 180000 sentinel parallel-syncs mymaster 1 sentinel monitor resque 192.168.1.3 6380 4 sentinel down-after-milliseconds resque 10000 sentinel failover-timeout resque 180000 sentinel parallel-syncs resque 5
上面的配置项配置了两个名字分别为mymaster和resque的master,配置文件只需要配置master的信息就好啦,不用配置slave的信息,因为slave能够被自动检测到(master节点会有关于slave的消息)。需要注意的是,配置文件在sentinel运行期间是会被动态修改的,例如当发生主备切换时候,配置文件中的master会被修改为另外一个slave。这样,之后sentinel如果重启时,就可以根据这个配置来恢复其之前所监控的redis集群的状态。
sentinel monitor mymaster 127.0.0.1 6379 2
这一行代表sentinel监控的master的名字叫做mymaster,地址为127.0.0.1:6379,行尾最后的一个2代表什么意思呢?我们知道,网络是不可靠的,有时候一个sentinel会因为网络堵塞而误以为一个master redis已经死掉了,当sentinel集群式,解决这个问题的方法就变得很简单,只需要多个sentinel互相沟通来确认某个master是否真的死了,这个2代表,当集群中有2个sentinel认为master死了时,才能真正认为该master已经不可用了。(sentinel集群中各个sentinel也有互相通信,通过gossip协议)。
除了第一行配置,我们发现剩下的配置都有一个统一的格式:
sentinel <option_name> <master_name> <option_value>
接下来我们根据上面格式中的option_name一个一个来解释这些配置项:
down-after-milliseconds
sentinel会向master发送心跳PING来确认master是否存活,如果master在“一定时间范围”内不回应PONG 或者是回复了一个错误消息,那么这个sentinel会主观地(单方面地)认为这个master已经不可用了(subjectively down, 也简称为SDOWN)。而这个down-after-milliseconds就是用来指定这个“一定时间范围”的,单位是毫秒。
不过需要注意的是,这个时候sentinel并不会马上进行failover主备切换,这个sentinel还需要参考sentinel集群中其他sentinel的意见,如果超过某个数量的sentinel也主观地认为该master死了,那么这个master就会被客观地(注意哦,这次不是主观,是客观,与刚才的subjectively down相对,这次是objectively down,简称为ODOWN)认为已经死了。需要一起做出决定的sentinel数量在上一条配置中进行配置。
parallel-syncs
在发生failover主备切换时,这个选项指定了最多可以有多少个slave同时对新的master进行同步,这个数字越小,完成failover所需的时间就越长,但是如果这个数字越大,就意味着越多的slave因为replication而不可用。可以通过将这个值设为 1 来保证每次只有一个slave处于不能处理命令请求的状态。
其他配置项在sentinel.conf中都有很详细的解释。
所有的配置都可以在运行时用命令SENTINEL SET command动态修改。
Sentinel的“仲裁会”
前面我们谈到,当一个master被sentinel集群监控时,需要为它指定一个参数,这个参数指定了当需要判决master为不可用,并且进行failover时,所需要的sentinel数量,本文中我们暂时称这个参数为票数
不过,当failover主备切换真正被触发后,failover并不会马上进行,还需要sentinel中的大多数sentinel授权后才可以进行failover。
当ODOWN时,failover被触发。failover一旦被触发,尝试去进行failover的sentinel会去获得“大多数”sentinel的授权(如果票数比大多数还要大的时候,则询问更多的sentinel)
这个区别看起来很微妙,但是很容易理解和使用。例如,集群中有5个sentinel,票数被设置为2,当2个sentinel认为一个master已经不可用了以后,将会触发failover,但是,进行failover的那个sentinel必须先获得至少3个sentinel的授权才可以实行failover。
如果票数被设置为5,要达到ODOWN状态,必须所有5个sentinel都主观认为master为不可用,要进行failover,那么得获得所有5个sentinel的授权。
配置版本号
为什么要先获得大多数sentinel的认可时才能真正去执行failover呢?
当一个sentinel被授权后,它将会获得宕掉的master的一份最新配置版本号,当failover执行结束以后,这个版本号将会被用于最新的配置。因为大多数sentinel都已经知道该版本号已经被要执行failover的sentinel拿走了,所以其他的sentinel都不能再去使用这个版本号。这意味着,每次failover都会附带有一个独一无二的版本号。我们将会看到这样做的重要性。
而且,sentinel集群都遵守一个规则:如果sentinel A推荐sentinel B去执行failover,B会等待一段时间后,自行再次去对同一个master执行failover,这个等待的时间是通过failover-timeout配置项去配置的。从这个规则可以看出,sentinel集群中的sentinel不会再同一时刻并发去failover同一个master,第一个进行failover的sentinel如果失败了,另外一个将会在一定时间内进行重新进行failover,以此类推。
redis sentinel保证了活跃性:如果大多数sentinel能够互相通信,最终将会有一个被授权去进行failover.
redis sentinel也保证了安全性:每个试图去failover同一个master的sentinel都会得到一个独一无二的版本号。
配置传播
一旦一个sentinel成功地对一个master进行了failover,它将会把关于master的最新配置通过广播形式通知其它sentinel,其它的sentinel则更新对应master的配置。
一个faiover要想被成功实行,sentinel必须能够向选为master的slave发送SLAVEOF NO ONE命令,然后能够通过INFO命令看到新master的配置信息。
当将一个slave选举为master并发送SLAVEOF NO ONE后,即使其它的slave还没针对新master重新配置自己,failover也被认为是成功了的,然后所有sentinels将会发布新的配置信息。
新配在集群中相互传播的方式,就是为什么我们需要当一个sentinel进行failover时必须被授权一个版本号的原因。
每个sentinel使用##发布/订阅##的方式持续地传播master的配置版本信息,配置传播的##发布/订阅##管道是:__sentinel__:hello。
因为每一个配置都有一个版本号,所以以版本号最大的那个为标准。
举个栗子:假设有一个名为mymaster的地址为192.168.1.50:6379。一开始,集群中所有的sentinel都知道这个地址,于是为mymaster的配置打上版本号1。一段时候后mymaster死了,有一个sentinel被授权用版本号2对其进行failover。如果failover成功了,假设地址改为了192.168.1.50:9000,此时配置的版本号为2,进行failover的sentinel会将新配置广播给其他的sentinel,由于其他sentinel维护的版本号为1,发现新配置的版本号为2时,版本号变大了,说明配置更新了,于是就会采用最新的版本号为2的配置。
这意味着sentinel集群保证了第二种活跃性:一个能够互相通信的sentinel集群最终会采用版本号最高且相同的配置。
SDOWN和ODOWN的更多细节
sentinel对于不可用有两种不同的看法,一个叫主观不可用(SDOWN),另外一个叫客观不可用(ODOWN)。SDOWN是sentinel自己主观上检测到的关于master的状态,ODOWN需要一定数量的sentinel达成一致意见才能认为一个master客观上已经宕掉,各个sentinel之间通过命令SENTINEL is_master_down_by_addr来获得其它sentinel对master的检测结果。
从sentinel的角度来看,如果发送了PING心跳后,在一定时间内没有收到合法的回复,就达到了SDOWN的条件。这个时间在配置中通过is-master-down-after-milliseconds参数配置。
当sentinel发送PING后,以下回复之一都被认为是合法的:
PING replied with +PONG.
PING replied with -LOADING error.
PING replied with -MASTERDOWN error.
其它任何回复(或者根本没有回复)都是不合法的。
从SDOWN切换到ODOWN不需要任何一致性算法,只需要一个gossip协议:如果一个sentinel收到了足够多的sentinel发来消息告诉它某个master已经down掉了,SDOWN状态就会变成ODOWN状态。如果之后master可用了,这个状态就会相应地被清理掉。
正如之前已经解释过了,真正进行failover需要一个授权的过程,但是所有的failover都开始于一个ODOWN状态。
ODOWN状态只适用于master,对于不是master的redis节点sentinel之间不需要任何协商,slaves和sentinel不会有ODOWN状态。
Sentinel之间和Slaves之间的自动发现机制
虽然sentinel集群中各个sentinel都互相连接彼此来检查对方的可用性以及互相发送消息。但是你不用在任何一个sentinel配置任何其它的sentinel的节点。因为sentinel利用了master的发布/订阅机制去自动发现其它也监控了统一master的sentinel节点。
通过向名为__sentinel__:hello的管道中发送消息来实现。
同样,你也不需要在sentinel中配置某个master的所有slave的地址,sentinel会通过询问master来得到这些slave的地址的。
每个sentinel通过向每个master和slave的发布/订阅频道__sentinel__:hello每秒发送一次消息,来宣布它的存在。
每个sentinel也订阅了每个master和slave的频道__sentinel__:hello的内容,来发现未知的sentinel,当检测到了新的sentinel,则将其加入到自身维护的master监控列表中。
每个sentinel发送的消息中也包含了其当前维护的最新的master配置。如果某个sentinel发现
自己的配置版本低于接收到的配置版本,则会用新的配置更新自己的master配置。
在为一个master添加一个新的sentinel前,sentinel总是检查是否已经有sentinel与新的sentinel的进程号或者是地址是一样的。如果是那样,这个sentinel将会被删除,而把新的sentinel添加上去。
网络隔离时的一致性
redis sentinel集群的配置的一致性模型为最终一致性,集群中每个sentinel最终都会采用最高版本的配置。然而,在实际的应用环境中,有三个不同的角色会与sentinel打交道:
-
Redis实例.
-
Sentinel实例.
-
客户端.
为了考察整个系统的行为我们必须同时考虑到这三个角色。
下面有个简单的例子,有三个主机,每个主机分别运行一个redis和一个sentinel:
+-------------+
| Sentinel 1 | <--- Client A
| Redis 1 (M) |
+-------------+
|
|
+-------------+ | +------------+
| Sentinel 2 |-----+-- / partition / ----| Sentinel 3 | <--- Client B
| Redis 2 (S) | | Redis 3 (M)|
+-------------+ +------------+
在这个系统中,初始状态下redis3是master, redis1和redis2是slave。之后redis3所在的主机网络不可用了,sentinel1和sentinel2启动了failover并把redis1选举为master。
Sentinel集群的特性保证了sentinel1和sentinel2得到了关于master的最新配置。但是sentinel3依然持着的是就的配置,因为它与外界隔离了。
当网络恢复以后,我们知道sentinel3将会更新它的配置。但是,如果客户端所连接的master被网络隔离,会发生什么呢?
客户端将依然可以向redis3写数据,但是当网络恢复后,redis3就会变成redis的一个slave,那么,在网络隔离期间,客户端向redis3写的数据将会丢失。
也许你不会希望这个场景发生:
-
如果你把redis当做缓存来使用,那么你也许能容忍这部分数据的丢失。
-
但如果你把redis当做一个存储系统来使用,你也许就无法容忍这部分数据的丢失了。
因为redis采用的是异步复制,在这样的场景下,没有办法避免数据的丢失。然而,你可以通过以下配置来配置redis3和redis1,使得数据不会丢失。
min-slaves-to-write 1
min-slaves-max-lag 10
通过上面的配置,当一个redis是master时,如果它不能向至少一个slave写数据(上面的min-slaves-to-write指定了slave的数量),它将会拒绝接受客户端的写请求。由于复制是异步的,master无法向slave写数据意味着slave要么断开连接了,要么不在指定时间内向master发送同步数据的请求了(上面的min-slaves-max-lag指定了这个时间)。
Sentinel状态持久化
snetinel的状态会被持久化地写入sentinel的配置文件中。每次当收到一个新的配置时,或者新创建一个配置时,配置会被持久化到硬盘中,并带上配置的版本戳。这意味着,可以安全的停止和重启sentinel进程。
无failover时的配置纠正
即使当前没有failover正在进行,sentinel依然会使用当前配置去设置监控的master。特别是:
-
根据最新配置确认为slaves的节点却声称自己是master(上文例子中被网络隔离后的的redis3),这时它们会被重新配置为当前master的slave。
-
如果slaves连接了一个错误的master,将会被改正过来,连接到正确的master。
Slave选举与优先级
当一个sentinel准备好了要进行failover,并且收到了其他sentinel的授权,那么就需要选举出一个合适的slave来做为新的master。
slave的选举主要会评估slave的以下几个方面:
-
与master断开连接的次数
-
Slave的优先级
-
数据复制的下标(用来评估slave当前拥有多少master的数据)
-
进程ID
如果一个slave与master失去联系超过10次,并且每次都超过了配置的最大失联时间(down-after-milliseconds),如果sentinel在进行failover时发现slave失联,那么这个slave就会被sentinel认为不适合用来做新master的。
更严格的定义是,如果一个slave持续断开连接的时间超过
(down-after-milliseconds * 10) + milliseconds_since_master_is_in_SDOWN_state
就会被认为失去选举资格。
符合上述条件的slave才会被列入master候选人列表,并根据以下顺序来进行排序:
-
sentinel首先会根据slaves的优先级来进行排序,优先级越小排名越靠前。
-
如果优先级相同,则查看复制的下标,哪个从master接收的复制数据多,哪个就靠前。
-
如果优先级和下标都相同,就选择进程ID较小的那个。
一个redis无论是master还是slave,都必须在配置中指定一个slave优先级。要注意到master也是有可能通过failover变成slave的。
如果一个redis的slave优先级配置为0,那么它将永远不会被选为master。但是它依然会从master哪里复制数据。
Sentinel和Redis身份验证
当一个master配置为需要密码才能连接时,客户端和slave在连接时都需要提供密码。
master通过requirepass设置自身的密码,不提供密码无法连接到这个master。
slave通过masterauth来设置访问master时的密码。
但是当使用了sentinel时,由于一个master可能会变成一个slave,一个slave也可能会变成master,所以需要同时设置上述两个配置项。
详细信息,请点击这里
-
如何实现redis集群?
由于Redis出众的性能,其在众多的移动互联网企业中得到广泛的应用。Redis在3.0版本前只支持单实例模式,虽然现在的服务器内存可以到100GB、200GB的规模,但是单实例模式限制了Redis没法满足业务的需求(例如新浪微博就曾经用Redis存储了超过1TB的数据)。Redis的开发者Antirez早在博客上就提出在Redis 3.0版本中加入集群的功能,但3.0版本等到2015年才发布正式版。各大企业在3.0版本还没发布前为了解决Redis的存储瓶颈,纷纷推出了各自的Redis集群方案。这些方案的核心思想是把数据分片(sharding)存储在多个Redis实例中,每一片就是一个Redis实例。
下面介绍Redis的集群方案。
1、客户端分片
客户端分片是把分片的逻辑放在Redis客户端实现,通过Redis客户端预先定义好的路由规则,把对Key的访问转发到不同的Redis实例中,最后把返回结果汇集。这种方案的模式如下图所示。
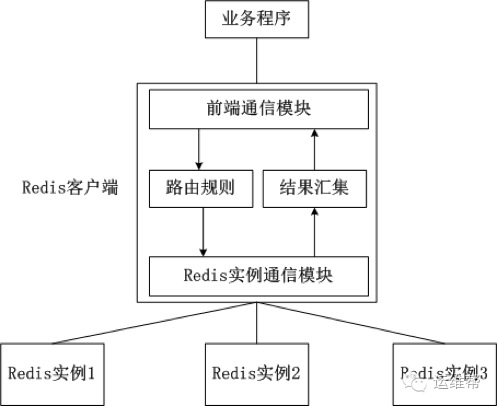
客户端分片的好处是所有的逻辑都是可控的,不依赖于第三方分布式中间件。开发人员清楚怎么实现分片、路由的规则,不用担心踩坑。
客户端分片方案有下面这些缺点:
●这是一种静态的分片方案,需要增加或者减少Redis实例的数量,需要手工调整分片的程序。
●可运维性差,集群的数据出了任何问题都需要运维人员和开发人员一起合作,减缓了解决问题的速度,增加了跨部门沟通的成本。
●在不同的客户端程序中,维护相同的分片逻辑成本巨大。例如,系统中有两套业务系统共用一套Redis集群,一套业务系统用Java实现,另一套业务系统用PHP实现。为了保证分片逻辑的一致性,在Java客户端中实现的分片逻辑也需要在PHP客户端实现一次。相同的逻辑在不同的系统中分别实现,这种设计本来就非常糟糕,而且需要耗费巨大的开发成本保证两套业务系统分片逻辑的一致性。
2、Twemproxy
Twemproxy是由Twitter开源的Redis代理,其基本原理是:Redis客户端把请求发送到Twemproxy,Twemproxy根据路由规则发送到正确的Redis实例,最后Twemproxy把结果汇集返回给客户端。
Twemproxy通过引入一个代理层,将多个Redis实例进行统一管理,使Redis客户端只需要在Twemproxy上进行操作,而不需要关心后面有多少个Redis实例,从而实现了Redis集群。
Twemproxy集群架构如下图所示:
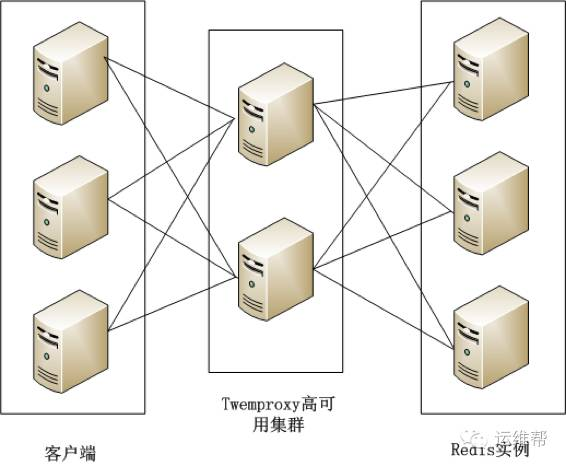
Twemproxy的优点如下:
●客户端像连接Redis实例一样连接Twemproxy,不需要改任何的代码逻辑。
●支持无效Redis实例的自动删除。
●Twemproxy与Redis实例保持连接,减少了客户端与Redis实例的连接数。
Twemproxy的缺点如下:
●由于Redis客户端的每个请求都经过Twemproxy代理才能到达Redis服务器,这个过程中会产生性能损失。
●没有友好的监控管理后台界面,不利于运维监控。
●最大的问题是Twemproxy无法平滑地增加Redis实例。对于运维人员来说,当因为业务需要增加Redis实例时工作量非常大。
Twemproxy作为最被广泛使用、最久经考验、稳定性最高的Redis代理,在业界被广泛使用。
3、Redis 3.0集群
Redis 3.0集群采用了P2P的模式,完全去中心化。Redis把所有的Key分成了16384个slot,每个Redis实例负责其中一部分slot。集群中的所有信息(节点、端口、slot等),都通过节点之间定期的数据交换而更新。
Redis客户端在任意一个Redis实例发出请求,如果所需数据不在该实例中,通过重定向命令引导客户端访问所需的实例。
Redis 3.0集群的工作流程如下图所示:
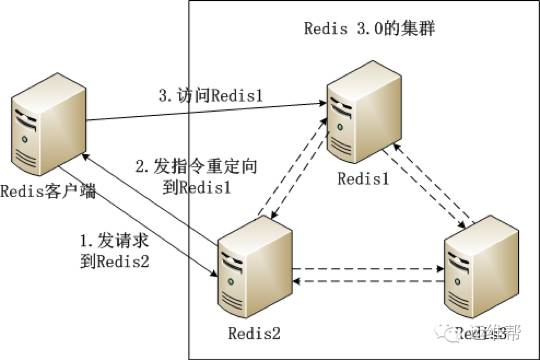
如图所示Redis集群内的机器定期交换数据,工作流程如下:
(1) Redis客户端在Redis2实例上访问某个数据。
(2) 在Redis2内发现这个数据是在Redis3这个实例中,给Redis客户端发送一个重定向的命令。
(3) Redis客户端收到重定向命令后,访问Redis3实例获取所需的数据。
Redis 3.0的集群方案有以下两个问题:
●一个Redis实例具备了“数据存储”和“路由重定向”,完全去中心化的设计。这带来的好处是部署非常简单,直接部署Redis就行,不像Codis有那么多的组件和依赖。但带来的问题是很难对业务进行无痛的升级,如果哪天Redis集群出了什么严重的Bug,就只能回滚整个Redis集群。
●对协议进行了较大的修改,对应的Redis客户端也需要升级。升级Redis客户端后谁能确保没有Bug?而且对于线上已经大规模运行的业务,升级代码中的Redis客户端也是一个很麻烦的事情。
综合上面所述的两个问题,Redis 3.0集群在业界并没有被大规模使用。
4、云服务器上的集群服务
国内的云服务器提供商阿里云、UCloud等均推出了基于Redis的云存储服务。
这个服务的特性如下。
(1)动态扩容
用户可以通过控制面板升级所需的Redis存储空间,扩容的过程中服务部不需要中断或停止,整个扩容过程对用户透明、无感知,这点是非常实用的,在前面介绍的方案中,解决Redis平滑扩容是个很烦琐的任务,现在按几下鼠标就能搞定,大大减少了运维的负担。
(2)数据多备
数据保存在一主一备两台机器中,其中一台机器宕机了,数据还在另外一台机器上有备份。
(3)自动容灾
主机宕机后系统能自动检测并切换到备机上,实现服务的高可用。
(4)实惠
很多情况下为了使Redis的性能更高,需要购买一台专门的服务器用于Redis的存储服务,但这样子CPU、内存等资源就浪费了,购买Redis云存储服务就很好地解决了这个问题。
有了Redis云存储服务,能使App后台开发人员从烦琐运维中解放出来。App后台要搭建一个高可用、高性能的Redis服务,需要投入相当的运维成本和精力。如果使用云存储服务,就没必要投入这些成本和精力,可以让App后台开发人员更专注于业务。
-
redis中默认有多少个哈希槽?
Redis 集群中内置了 16384 个哈希槽,当需要在 Redis 集群中放置一个 key-value时,redis 先对 key 使用 crc16 算法算出一个结果,然后把结果对 16384 求余数,这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,redis 会根据节点数量大致均等的将哈希槽映射到不同的节点。
Redis 集群没有使用一致性hash, 而是引入了哈希槽的概念。
Redis 集群有16384个哈希槽,每个key通过CRC16校验后对16384取模来决定放置哪个槽.集群的每个节点负责一部分hash槽。这种结构很容易添加或者删除节点,并且无论是添加删除或者修改某一个节点,都不会造成集群不可用的状态。
使用哈希槽的好处就在于可以方便的添加或移除节点。
当需要增加节点时,只需要把其他节点的某些哈希槽挪到新节点就可以了;
当需要移除节点时,只需要把移除节点上的哈希槽挪到其他节点就行了;
在这一点上,我们以后新增或移除节点的时候不用先停掉所有的 redis 服务。
"用了哈希槽的概念,而没有用一致性哈希算法,不都是哈希么?这样做的原因是为什么呢?"
Redis Cluster是自己做的crc16的简单hash算法,没有用一致性hash。Redis的作者认为它的crc16(key) mod 16384的效果已经不错了,虽然没有一致性hash灵活,但实现很简单,节点增删时处理起来也很方便。
"为了动态增删节点的时候,不至于丢失数据么?"
节点增删时不丢失数据和hash算法没什么关系,不丢失数据要求的是一份数据有多个副本。
“还有集群总共有2的14次方,16384个哈希槽,那么每一个哈希槽中存的key 和 value是什么?”
当你往Redis Cluster中加入一个Key时,会根据crc16(key) mod 16384计算这个key应该分布到哪个hash slot中,一个hash slot中会有很多key和value。你可以理解成表的分区,使用单节点时的redis时只有一个表,所有的key都放在这个表里;改用Redis Cluster以后会自动为你生成16384个分区表,你insert数据时会根据上面的简单算法来决定你的key应该存在哪个分区,每个分区里有很多key。
-
简述redis的有哪几种持久化策略及比较?
Redis 提供了多种不同级别的持久化方式:
RDB 持久化可以在指定的时间间隔内生成数据集的时间点快照(point-in-time snapshot)。
AOF 持久化记录服务器执行的所有写操作命令,并在服务器启动时,通过重新执行这些命令来还原数据集。 AOF 文件中的命令全部以 Redis 协议的格式来保存,新命令会被追加到文件的末尾。 Redis 还可以在后台对 AOF 文件进行重写(rewrite),使得 AOF 文件的体积不会超出保存数据集状态所需的实际大小。
Redis 还可以同时使用 AOF 持久化和 RDB 持久化。 在这种情况下, 当 Redis 重启时, 它会优先使用 AOF 文件来还原数据集, 因为 AOF 文件保存的数据集通常比 RDB 文件所保存的数据集更完整。
你甚至可以关闭持久化功能,让数据只在服务器运行时存在。
RDB知识点
RDB 的优点
RDB 是一个非常紧凑(compact)的文件,它保存了 Redis 在某个时间点上的数据集。 这种文件非常适合用于进行备份: 比如说,你可以在最近的 24 小时内,每小时备份一次 RDB 文件,并且在每个月的每一天,也备份一个 RDB 文件。 这样的话,即使遇上问题,也可以随时将数据集还原到不同的版本。
RDB 非常适用于灾难恢复(disaster recovery):它只有一个文件,并且内容都非常紧凑,可以(在加密后)将它传送到别的数据中心,或者亚马逊 S3 中。
RDB 可以最大化 Redis 的性能:父进程在保存 RDB 文件时唯一要做的就是 fork 出一个子进程,然后这个子进程就会处理接下来的所有保存工作,父进程无须执行任何磁盘 I/O 操作。
RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快。
RDB 的缺点
如果你需要尽量避免在服务器故障时丢失数据,那么 RDB 不适合你。 虽然 Redis 允许你设置不同的保存点(save point)来控制保存 RDB 文件的频率, 但是, 因为RDB 文件需要保存整个数据集的状态, 所以它并不是一个轻松的操作。 因此你可能会至少 5 分钟才保存一次 RDB 文件。 在这种情况下, 一旦发生故障停机, 你就可能会丢失好几分钟的数据。
每次保存 RDB 的时候,Redis 都要 fork() 出一个子进程,并由子进程来进行实际的持久化工作。 在数据集比较庞大时, fork() 可能会非常耗时,造成服务器在某某毫秒内停止处理客户端; 如果数据集非常巨大,并且 CPU 时间非常紧张的话,那么这种停止时间甚至可能会长达整整一秒。 虽然 AOF 重写也需要进行 fork() ,但无论 AOF 重写的执行间隔有多长,数据的耐久性都不会有任何损失。
AOF知识点
AOF 的优点
使用 AOF 持久化会让 Redis 变得非常耐久(much more durable):你可以设置不同的 fsync 策略,比如无 fsync ,每秒钟一次 fsync ,或者每次执行写入命令时 fsync 。 AOF 的默认策略为每秒钟 fsync 一次,在这种配置下,Redis 仍然可以保持良好的性能,并且就算发生故障停机,也最多只会丢失一秒钟的数据( fsync 会在后台线程执行,所以主线程可以继续努力地处理命令请求)。
AOF 文件是一个只进行追加操作的日志文件(append only log), 因此对 AOF 文件的写入不需要进行 seek , 即使日志因为某些原因而包含了未写入完整的命令(比如写入时磁盘已满,写入中途停机,等等), redis-check-aof 工具也可以轻易地修复这种问题。
Redis 可以在 AOF 文件体积变得过大时,自动地在后台对 AOF 进行重写: 重写后的新 AOF 文件包含了恢复当前数据集所需的最小命令集合。 整个重写操作是绝对安全的,因为 Redis 在创建新 AOF 文件的过程中,会继续将命令追加到现有的 AOF 文件里面,即使重写过程中发生停机,现有的 AOF 文件也不会丢失。 而一旦新 AOF 文件创建完毕,Redis 就会从旧 AOF 文件切换到新 AOF 文件,并开始对新 AOF 文件进行追加操作。
AOF 文件有序地保存了对数据库执行的所有写入操作, 这些写入操作以 Redis 协议的格式保存, 因此 AOF 文件的内容非常容易被人读懂, 对文件进行分析(parse)也很轻松。 导出(export) AOF 文件也非常简单: 举个例子, 如果你不小心执行了 FLUSHALL 命令, 但只要 AOF 文件未被重写, 那么只要停止服务器, 移除 AOF 文件末尾的 FLUSHALL 命令, 并重启 Redis , 就可以将数据集恢复到 FLUSHALL 执行之前的状态。
AOF 的缺点
对于相同的数据集来说,AOF 文件的体积通常要大于 RDB 文件的体积。
根据所使用的 fsync 策略,AOF 的速度可能会慢于 RDB 。 在一般情况下, 每秒 fsync 的性能依然非常高, 而关闭 fsync 可以让 AOF 的速度和 RDB 一样快, 即使在高负荷之下也是如此。 不过在处理巨大的写入载入时,RDB 可以提供更有保证的最大延迟时间(latency)。
AOF 在过去曾经发生过这样的 bug : 因为个别命令的原因,导致 AOF 文件在重新载入时,无法将数据集恢复成保存时的原样。 (举个例子,阻塞命令 BRPOPLPUSH 就曾经引起过这样的 bug 。) 测试套件里为这种情况添加了测试: 它们会自动生成随机的、复杂的数据集, 并通过重新载入这些数据来确保一切正常。 虽然这种 bug 在 AOF 文件中并不常见, 但是对比来说, RDB 几乎是不可能出现这种 bug 的。
-
列举redis支持的过期策略。
-
MySQL 里有 2000w 数据,redis 中只存 20w 的数据,如何保证 redis 中都是热点数据?
-
写代码,基于redis的列表实现 先进先出、后进先出队列、优先级队列。
-
如何基于redis实现消息队列?
-
如何基于redis实现发布和订阅?以及发布订阅和消息队列的区别?
-
什么是codis及作用?
-
什么是twemproxy及作用?
-
写代码实现redis事务操作。
-
redis中的watch的命令的作用?
-
基于redis如何实现商城商品数量计数器?
-
简述redis分布式锁和redlock的实现机制。
-
什么是一致性哈希?Python中是否有相应模块?
-
如何高效的找到redis中所有以oldboy开头的key?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号