


python基础整理1
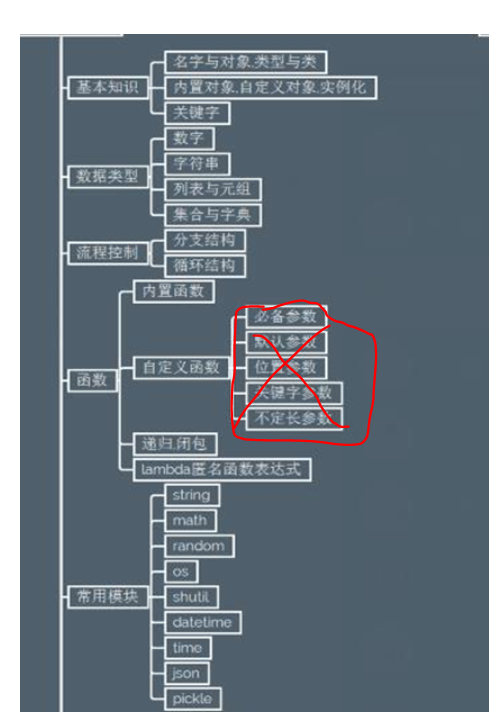
基础知识
名字与对象,类与类型
变量:在Python中,存储一个数据,需要一个叫做变量的东西 num2 = 87 #num2是一个变量
变量的类型:
程序中为了更充分的利用内存空间以及更有效率的管理内存,变量是有不同的类型的,如下所示:

输入:python3版本中 input python2中raw_input()
输出:print
内置对象,自定义对象,实列化

关键字:python一些具有特殊功能的标示符,这就是所谓的关键字
关键字,是python已经使用的了,所以不允许开发者自己定义和关键字相同的名字的标示符

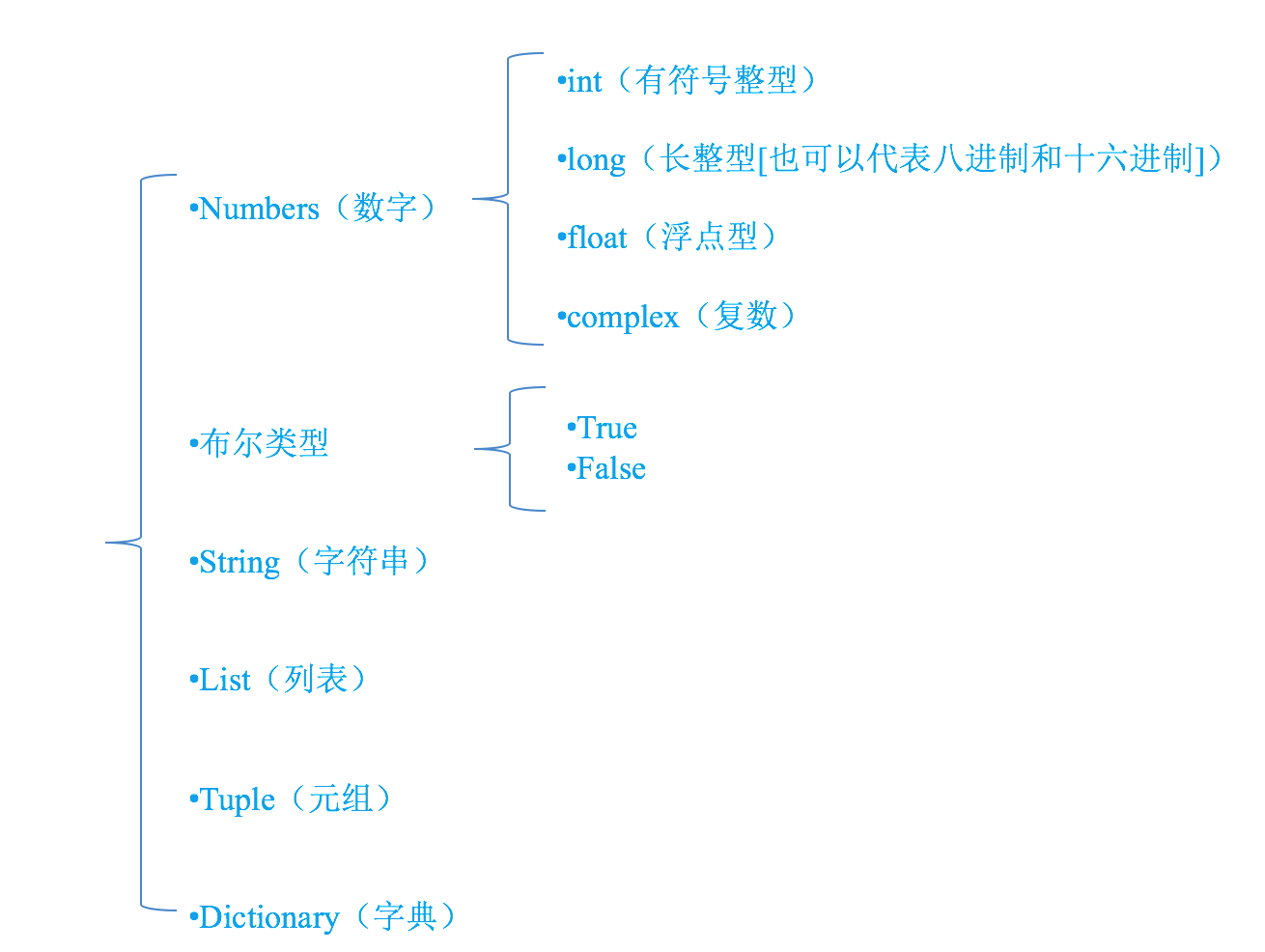
数据类型
1、 数字:用于存储数值。包括整型(Int),长整型(long integers) ,浮点型(floating point real values),复数(complex numbers)
2、 布尔值 真或假 1 或 0
3、 字符串 :双引号或者单引号中的数据,就是字符串
字符串常用功能:
- 移除空白
- 分割
- 长度
- 索引
- 切片
4、 列表:列表使用方括号——[]
基本操作:
- 索引
- 切片
- 追加
- 删除
- 长度
- 循环
- 包含
5、元祖 :元组的元素不能修改。元组使用小括号——()组创建很简单,只需要在括号中添加元素,并使用逗号隔开即可
基本操作:
- 索引
- 切片
- 循环
- 长度
- 包含
6、字典(无序):字典的每个键值 key=>value 对用冒号 : 分割,每个键值对之间用逗号 , 分割,整个字典包括在花括号 {} 中
常用操作:
- 索引
- 新增
- 删除
- 键、值、键值对
- 循环
- 长度
遍历
通过for ... in ...:的语法结构,我们可以遍历字符串、列表、元组、字典等数据结构。
注意python语法的缩进
字符串遍历
>>> a_str = "hello itcast"
>>> for char in a_str:
... print(char,end=' ')
...
h e l l o i t c a s t
列表遍历
>>> a_list = [1, 2, 3, 4, 5]
>>> for num in a_list:
... print(num,end=' ')
...
1 2 3 4 5
元组遍历
>>> a_turple = (1, 2, 3, 4, 5)
>>> for num in a_turple:
... print(num,end=" ")
1 2 3 4 5
字典遍历
<1> 遍历字典的key(键)

<2> 遍历字典的value(值)

<3> 遍历字典的项(元素)

<4> 遍历字典的key-value(键值对)

可变类型与不可变类型
可变类型,值可以改变:
- 列表 list
- 字典 dict
不可变类型,值不可以改变:
- 数值类型 int, long, bool, float
- 字符串 str
- 元组 tuple
流程控制
分支结构
需求一、用户登陆验证
# 提示输入用户名和密码 # 验证用户名和密码# 如果错误,则输出用户名或密码错误# 如果成功,则输出 欢迎,XXX!# 根据用户输入内容打印其权限
# alex --> 超级管理员# eric --> 普通管理员# tony,rain --> 业务主管# 其他 --> 普通用户
循环结构
1:while循环
while 条件:
# 如果条件为假,那么循环体不执行break用于退出所有循环
3、continue
continue用于退出当前循环,继续下一次循环
函数——为了提高编写的效率以及代码的重用,所以把具有独立功能的代码块组织为一个小模块,这就是函数,函数式编程最重要的是增强代码的重用性和可读自性
python内置函数
Python包含了以下内置函数
| 序号 | 方法 | 描述 |
|---|---|---|
| 1 | cmp(item1, item2) | 比较两个值 |
| 2 | len(item) | 计算容器中元素个数 |
| 3 | max(item) | 返回容器中元素最大值 |
| 4 | min(item) | 返回容器中元素最小值 |
| 5 | del(item) | 删除变量 |
注意:cmp在比较字典数据时,先比较键,再比较值。
注意:len在操作字典数据时,返回的是键值对个数。
del有两种用法,一种是del加空格,另一种是del()
Python 内置函数
自定义函数
def 函数名(参数): ... 函数体 ... 返回值 |
函数的定义主要有如下要点:
- def:表示函数的关键字
- 函数名:函数的名称,日后根据函数名调用函数
- 函数体:函数中进行一系列的逻辑计算,如:发送邮件、计算出 [11,22,38,888,2]中的最大数等...
- 参数:为函数体提供数据
- 返回值:当函数执行完毕后,可以给调用者返回数据。(函数是一个功能块,该功能到底执行成功与否,需要通过返回值来告知调用者。)
调用函数
定义了函数之后,就相当于有了一个具有某些功能的代码,想要让这些代码能够执行,需要调用它
调用函数很简单的,通过 函数名() 即可完成调用
函数参数(一)
<1> 定义带有参数的函数
示例如下:
def add2num(a, b):
c = a+b
print c
<2> 调用带有参数的函数
以调用上面的add2num(a, b)函数为例:
def add2num(a, b):
c = a+b
print c
add2num(11, 22) #调用带有参数的函数时,需要在小括号中,传递数据- 定义时小括号中的参数,用来接收参数用的,称为 “形参”
- 调用时小括号中的参数,用来传递给函数用的,称为 “实参”
函数返回值(一)
<1>“返回值”介绍
- 所谓“返回值”,就是程序中函数完成一件事情后,最后给调用者的结果
-
<2>带有返回值的函数
- 想要在函数中把结果返回给调用者,需要在函数中使用return
<3>保存函数的返回值
如果一个函数返回了一个数据,那么想要用这个数据,那么就需要保存
4种函数的类型
函数根据有没有参数,有没有返回值,可以相互组合,一共有4种
- 无参数,无返回值
- 无参数,有返回值
- 有参数,无返回值
- 有参数,有返回值
-
<1>无参数,无返回值的函数
此类函数,不能接收参数,也没有返回值,一般情况下,打印提示灯类似的功能,使用这类的函数
-
<2>无参数,有返回值的函数
此类函数,不能接收参数,但是可以返回某个数据,一般情况下,像采集数据,用此类函数
-
<3>有参数,无返回值的函数
此类函数,能接收参数,但不可以返回数据,一般情况下,对某些变量设置数据而不需结果时,用此类函数
-
<4>有参数,有返回值的函数
此类函数,不仅能接收参数,还可以返回某个数据,一般情况下,像数据处理并需要结果的应用,用此类函数
-
小总结
- 函数根据有没有参数,有没有返回值可以相互组合
- 定义函数时,是根据实际的功能需求来设计的,所以不同开发人员编写的函数类型各不相同
函数的嵌套调用
一个函数里面又调用了另外一个函数,这就是所谓的函数嵌套调用

- 如果函数A中,调用了另外一个函数B,那么先把函数B中的任务都执行完毕之后才会回到上次 函数A执行的位置
局部变量
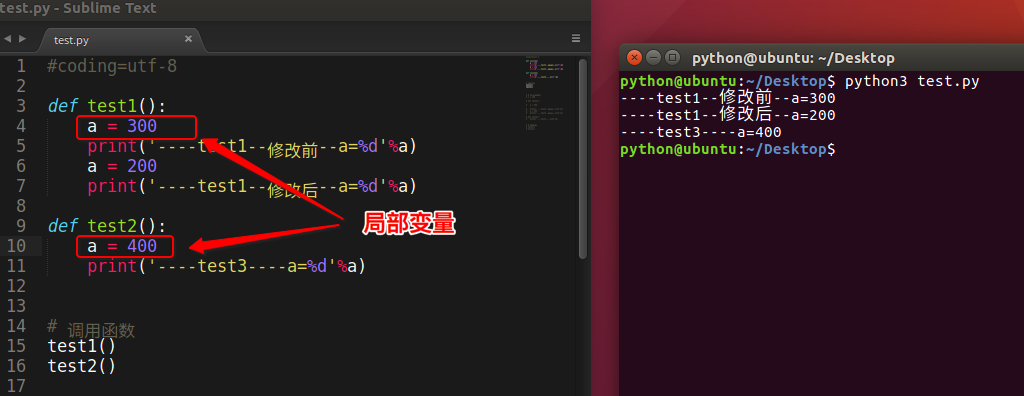
<1>什么是局部变量
如下图所示:

<2>小总结
- 局部变量,就是在函数内部定义的变量
- 不同的函数,可以定义相同的名字的局部变量,但是各用个的不会产生影响
- 局部变量的作用,为了临时保存数据需要在函数中定义变量来进行存储,这就是它的作用
全局变量
<1>什么是全局变量
如果一个变量,既能在一个函数中使用,也能在其他的函数中使用,这样的变量就是全局变量

<4>总结1:
- 在函数外边定义的变量叫做
全局变量 - 全局变量能够在所有的函数中进行访问
- 如果在函数中修改全局变量,那么就需要使用
global进行声明,否则出错 - 如果全局变量的名字和局部变量的名字相同,那么使用的是局部变量的,小技巧
强龙不压地头蛇
<5>可变类型的全局变量
- 函数中不使用global声明全局变量时不能修改全局变量的本质是不能修改全局变量的指向,即不能将全局变量指向新的数据。
- 对于不可变类型的全局变量来说,因其指向的数据不能修改,所以不使用global时无法修改全局变量。
- 对于可变类型的全局变量来说,因其指向的数据可以修改,所以不使用global时也可修改全局变量。
函数参数(二)
1. 缺省参数
调用函数时,缺省参数的值如果没有传入,则被认为是默认值
注意:带有默认值的参数一定要位于参数列表的最后面。
2.不定长参数
有时可能需要一个函数能处理比当初声明时更多的参数。这些参数叫做不定长参数,声明时不会命名。
基本语法如下:
def functionname([formal_args,] *args, **kwargs):
"函数_文档字符串"
function_suite
return [expression]
加了星号(*)的变量args会存放所有未命名的变量参数,args为元组;而加**的变量kwargs会存放命名参数,即形如key=value的参数, kwargs为字典。
3. 引用传参
Python中函数参数是引用传递(注意不是值传递)。对于不可变类型,因变量不能修改,所以运算不会影响到变量自身;而对于可变类型来说,函数体中的运算有可能会更改传入的参数变量。
函数使用注意事项
1. 自定义函数
<1>无参数、无返回值
def 函数名():
语句
<2>无参数、有返回值
def 函数名():
语句
return 需要返回的数值
注意:
- 一个函数到底有没有返回值,就看有没有return,因为只有return才可以返回数据
- 在开发中往往根据需求来设计函数需不需要返回值
- 函数中,可以有多个return语句,但是只要执行到一个return语句,那么就意味着这个函数的调用完成
<3>有参数、无返回值
def 函数名(形参列表):
语句
注意:
- 在调用函数时,如果需要把一些数据一起传递过去,被调用函数就需要用参数来接收
- 参数列表中变量的个数根据实际传递的数据的多少来确定
<4>有参数、有返回值
def 函数名(形参列表):
语句
return 需要返回的数值
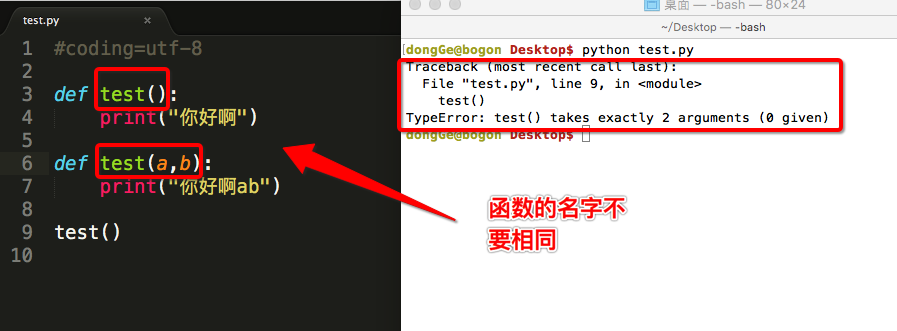
<5>函数名不能重复
2. 调用函数
<1>调用的方式为:
函数名([实参列表])
<2>调用时,到底写不写 实参
- 如果调用的函数 在定义时有形参,那么在调用的时候就应该传递参数
<3>调用时,实参的个数和先后顺序应该和定义函数中要求的一致
<4>如果调用的函数有返回值,那么就可以用一个变量来进行保存这个值
3. 作用域
<1>在一个函数中定义的变量,只能在本函数中用(局部变量)
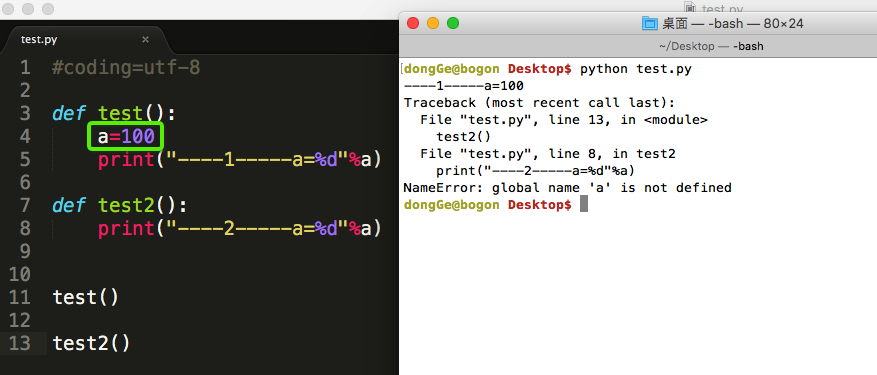
<2>在函数外定义的变量,可以在所有的函数中使用(全局变量)
递归函数
<1>什么是递归函数
通过前面的学习知道一个函数可以调用其他函数。
如果一个函数在内部不调用其它的函数,而是自己本身的话,这个函数就是递归函数。
闭包
什么是闭包:内部函数对外部函数作⽤域⾥变量的引⽤(⾮全局变量),则称内部函数为 闭包。
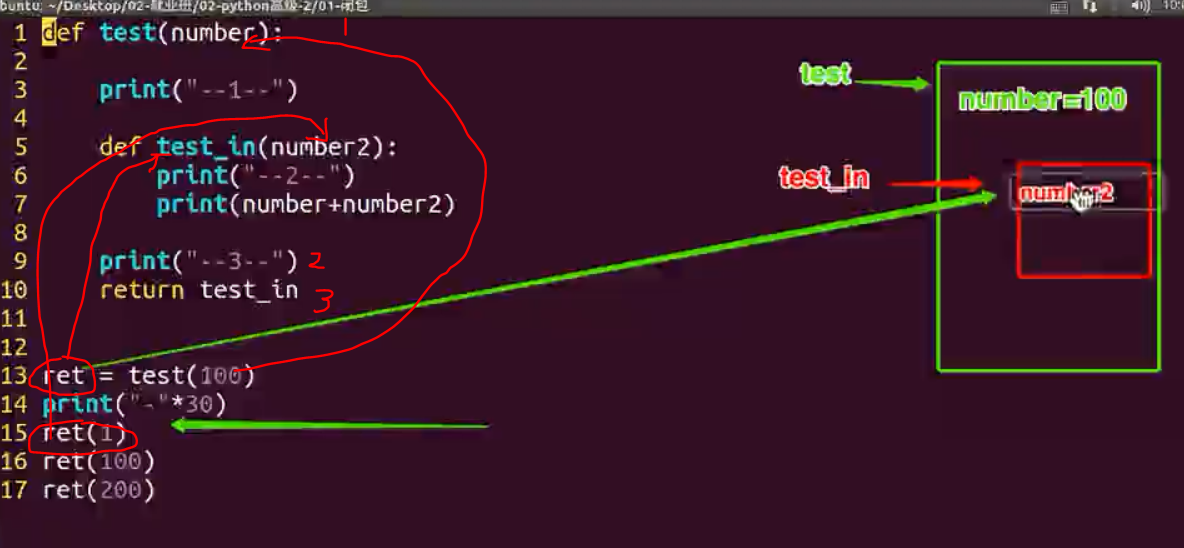
闭包思考:
1.闭包似优化了变量,原来需要类对象完成的⼯作,闭包也可以完成 2.由于闭包引⽤了外部函数的局部变量,则外部函数的局部变量没有及时释放,消耗内存
匿名函数
用lambda关键词能创建小型匿名函数。这种函数得名于省略了用def声明函数的标准步骤。
lambda函数的语法只包含一个语句,如下:
lambda [arg1 [,arg2,.....argn]]:expression
如下实例:
sum = lambda arg1, arg2: arg1 + arg2
#调用sum函数
print "Value of total : ", sum( 10, 20 )
print "Value of total : ", sum( 20, 20 )
以上实例输出结果:
Value of total : 30
Value of total : 40
Lambda函数能接收任何数量的参数但只能返回一个表达式的值
匿名函数不能直接调用print,因为lambda需要一个表达式

应用场合

常用模块
说的通俗点:模块就好比是工具包,要想使用这个工具包中的工具(就好比函数),就需要导入这个模块
<2>import
在Python中用关键字import来引入某个模块,比如要引用模块math,就可以在文件最开始的地方用import math来引入。
形如:
import module1,mudule2...
当解释器遇到import语句,如果模块在当前的搜索路径就会被导入。
在调用math模块中的函数时,必须这样引用:
模块名.函数名
有时候我们只需要用到模块中的某个函数,只需要引入该函数即可,此时可以用下面方法实现:
from 模块名 import 函数名1,函数名2....不仅可以引入函数,还可以引入一些全局变量、类等
-
注意:
-
通过这种方式引入的时候,调用函数时只能给出函数名,不能给出模块名,但是当两个模块中含有相同名称函数的时候,后面一次引入会覆盖前一次引入。也就是说假如模块A中有函数function( ),在模块B中也有函数function( ),如果引入A中的function在先、B中的function在后,那么当调用function函数的时候,是去执行模块B中的function函数。
-
如果想一次性引入math中所有的东西,还可以通过from math import *来实现
-
<3>from…import
Python的from语句让你从模块中导入一个指定的部分到当前命名空间中
语法如下:
from modname import name1[, name2[, ... nameN]]
例如,要导入模块fib的fibonacci函数,使用如下语句:
from fib import fibonacci
注意
- 不会把整个fib模块导入到当前的命名空间中,它只会将fib里的fibonacci单个引入
<4>from … import *
把一个模块的所有内容全都导入到当前的命名空间也是可行的,只需使用如下声明:
from modname import *
注意
- 这提供了一个简单的方法来导入一个模块中的所有项目。然而这种声明不该被过多地使用。
<5> as
In [1]: import time as tt
In [2]: time.sleep(1)<6>定位模块
当你导入一个模块,Python解析器对模块位置的搜索顺序是:
- 当前目录
- 如果不在当前目录,Python则搜索在shell变量PYTHONPATH下的每个目录。
- 如果都找不到,Python会察看默认路径。UNIX下,默认路径一般为/usr/local/lib/python/
- 模块搜索路径存储在system模块的sys.path变量中。变量里包含当前目录,PYTHONPATH和由安装过程决定的默认目录。
模块制作
<1>定义自己的模块
在Python中,每个Python文件都可以作为一个模块,模块的名字就是文件的名字。
比如有这样一个文件test.py,在test.py中定义了函数add
test.py
def add(a,b):
return a+b
<2>调用自己定义的模块
那么在其他文件中就可以先import test,然后通过test.add(a,b)来调用了,当然也可以通过from test import add来引入
main.py
import test
result = test.add(11,22)
print(result)
<3>测试模块
在实际开中,当一个开发人员编写完一个模块后,为了让模块能够在项目中达到想要的效果,这个开发人员会自行在py文件中添加一些测试信息,例如:
test.py
def add(a,b):
return a+b
# 用来进行测试
ret = add(12,22)
print('int test.py file,,,,12+22=%d'%ret)
如果此时,在其他py文件中引入了此文件的话,想想看,测试的那段代码是否也会执行呢!
main.py
import test
result = test.add(11,22)
print(result)
总结:
- 可以根据__name__变量的结果能够判断出,是直接执行的python脚本还是被引入执行的,从而能够有选择性的执行测试代码

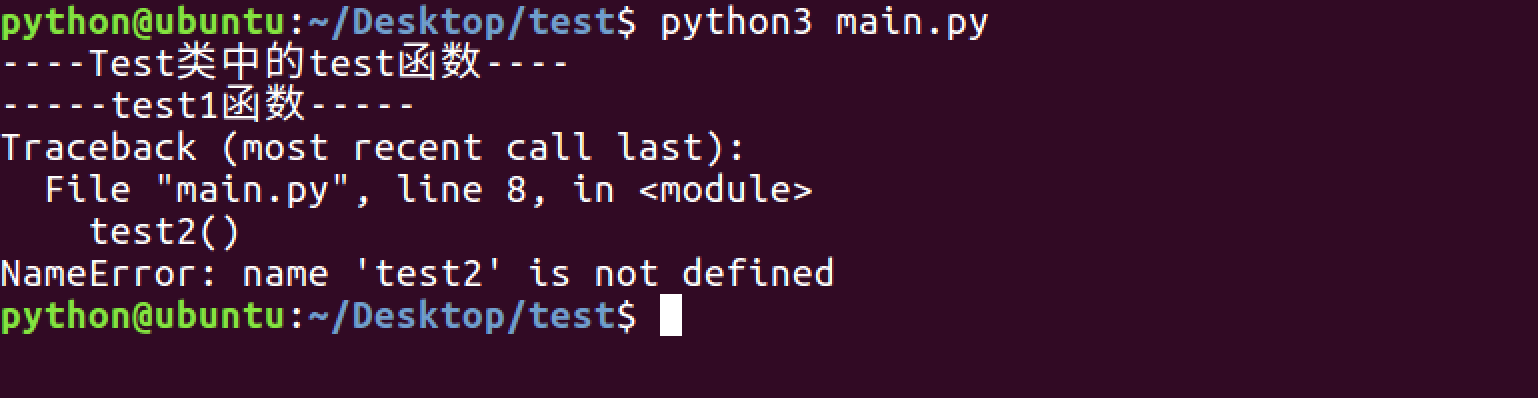
模块中的__all__
1. 没有__all__



2. 模块中有__all__

总结
- 如果一个文件中有__all__变量,那么也就意味着这个变量中的元素,不会被from xxx import *时导入
python中的包
1. 引入包
1.1 有2个模块功能有些联系

1.2 所以将其放到同一个文件夹下
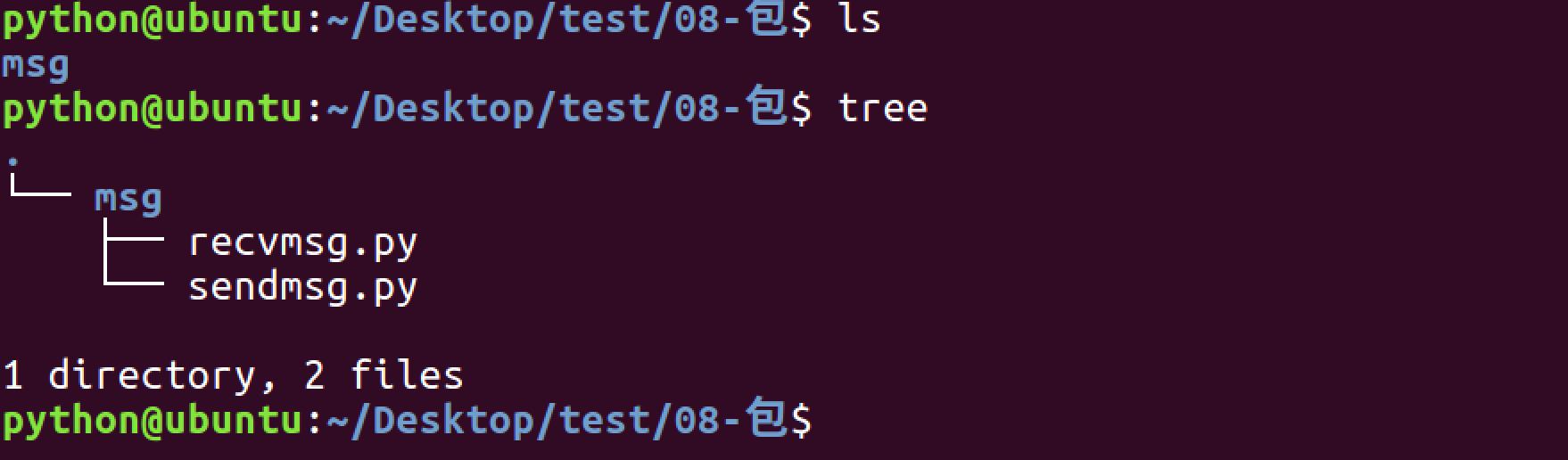
1.3 使用import 文件.模块 的方式导入
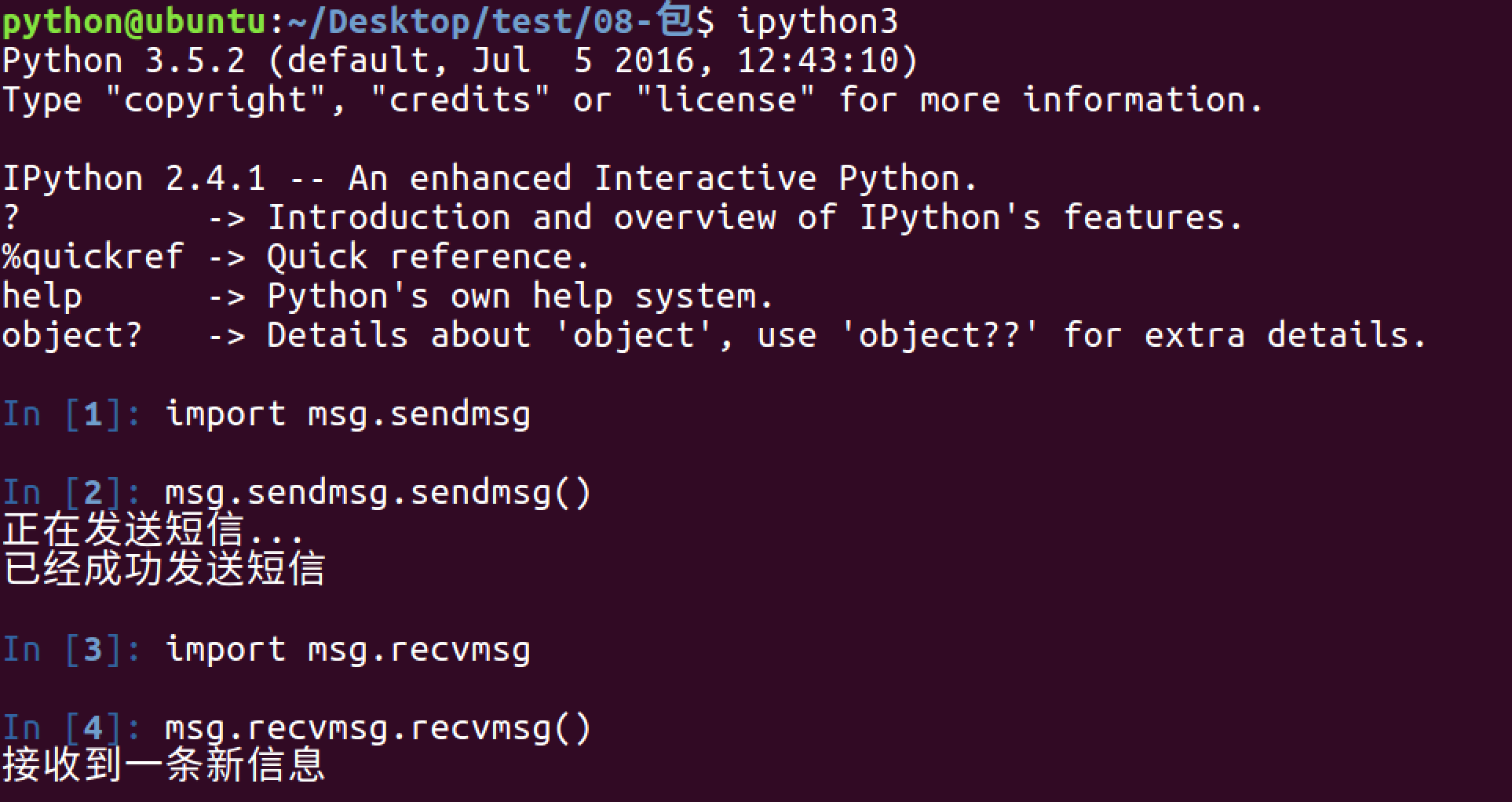
1.4 使用from 文件夹 import 模块 的方式导入
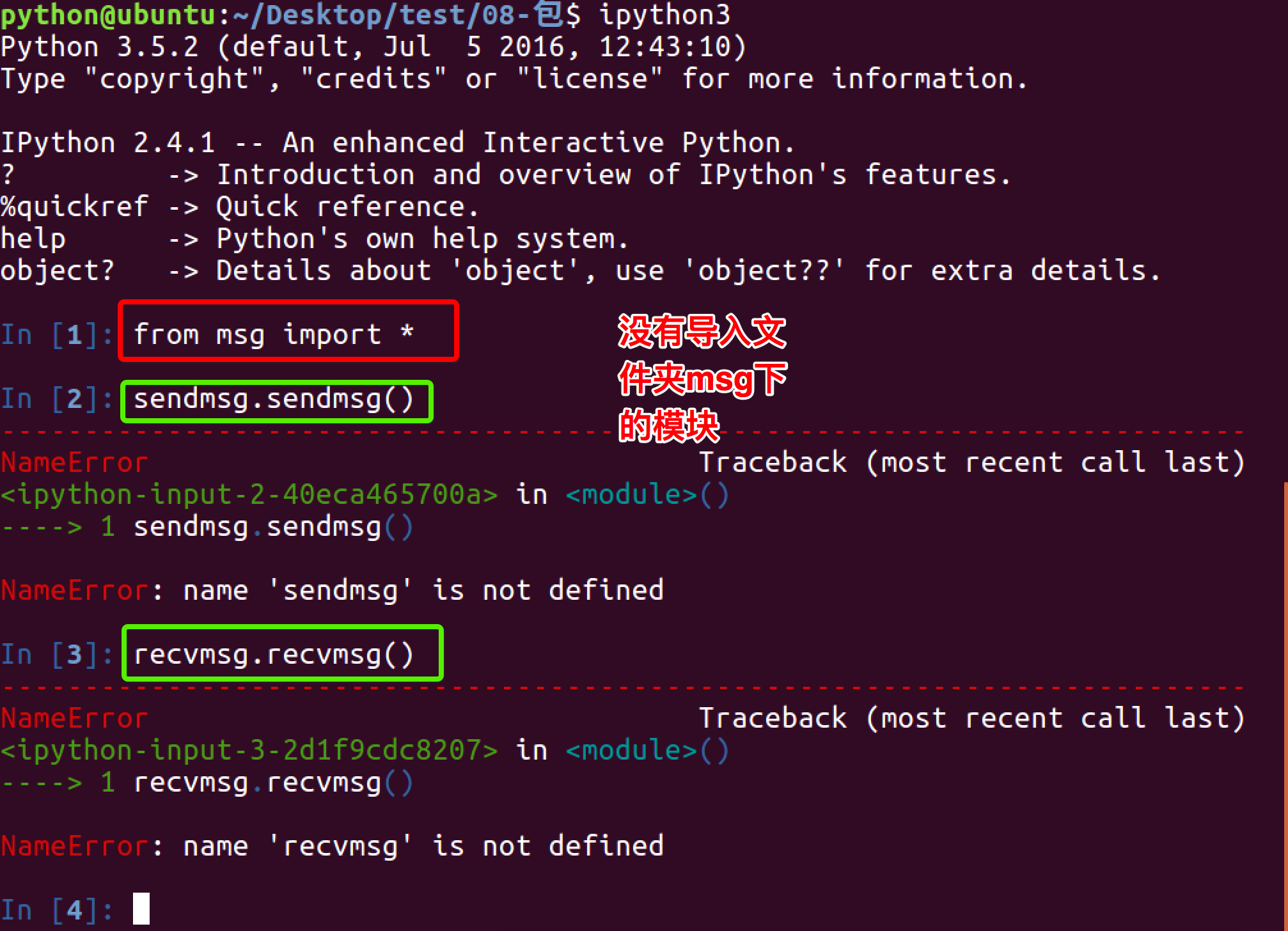
1.5 在msg文件夹下创建__init__.py文件

1.6 在__init__.py文件中写入

1.7 重新使用from 文件夹 import 模块 的方式导入
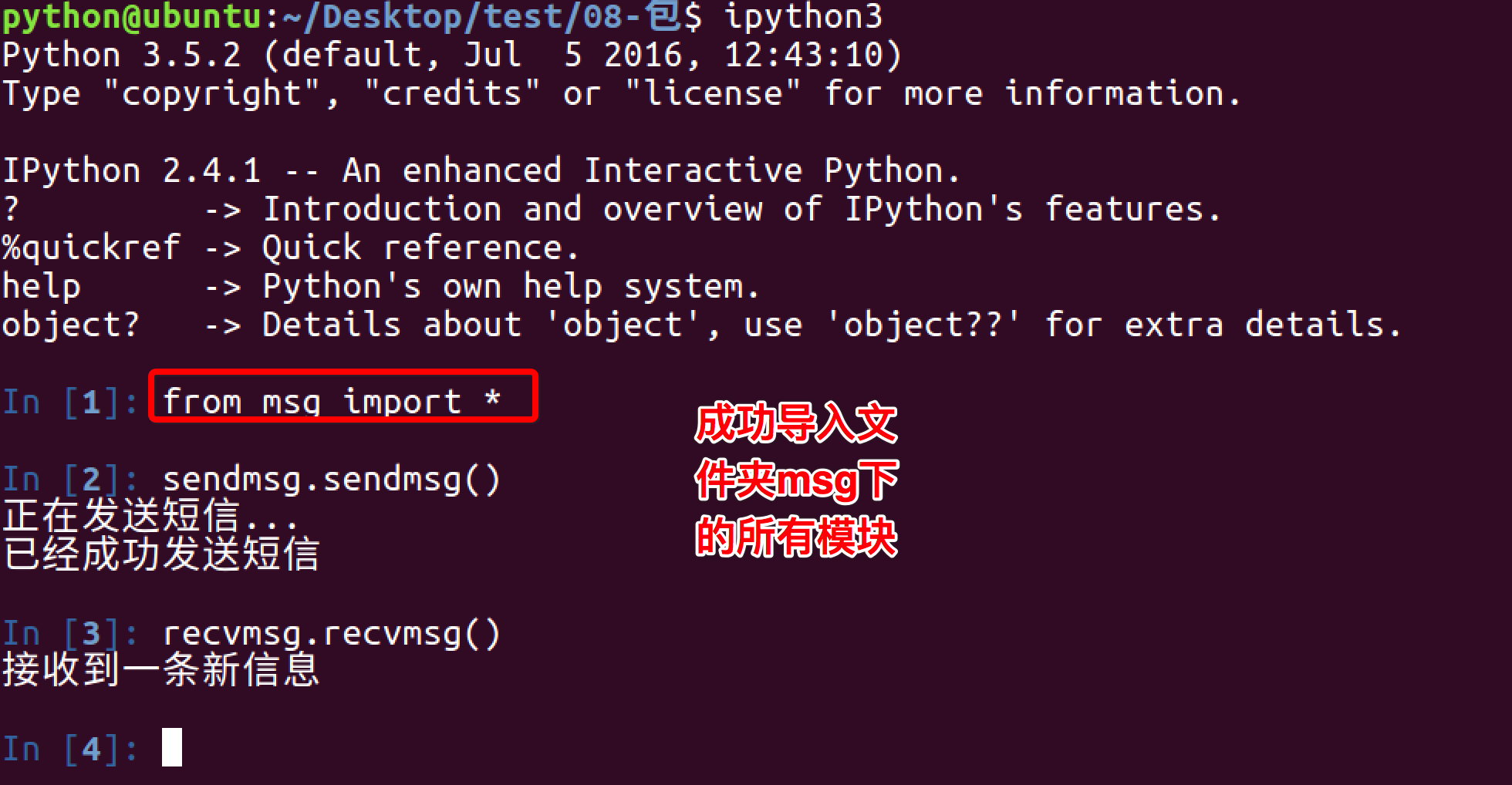
总结:
- 包将有联系的模块组织在一起,即放到同一个文件夹下,并且在这个文件夹创建一个名字为
__init__.py文件,那么这个文件夹就称之为包 - 有效避免模块名称冲突问题,让应用组织结构更加清晰
-
2.
__init__.py文件有什么用__init__.py控制着包的导入行为2.1
__init__.py为空仅仅是把这个包导入,不会导入包中的模块
2.2
__all__在
__init__.py文件中,定义一个__all__变量,它控制着 from 包名 import *时导入的模块2.3 (了解)可以在
__init__.py文件中编写内容可以在这个文件中编写语句,当导入时,这些语句就会被执行
__init__.py文件 -
模块安装、使用
1.安装的方式
- 找到模块的压缩包
- 解压
- 进入文件夹
- 执行命令
python setup.py install
注意:
- 如果在install的时候,执行目录安装,可以使用
python setup.py install --prefix=安装路径
2.模块的引入
在程序中,使用from import 即可完成对安装的模块使用
from 模块名 import 模块名或者*
