Flink部署
Standalone 模式
解压缩 flink-1.10.1-bin-scala_2.12.tgz,进入 conf 目录中。
1)修改 flink/conf/flink-conf.yaml 文件:

2)修改 /conf/slaves 文件:
可以写你的主机名字,比如我的机器是hadoop202,hadoop203,hadoop204,同时hadoop204作为flink的主节点,那么slaves就是hadoop202,hadoop203

3)分发给另外两台机子:
xsync /opt/module/flink-1.10.0
(这里的xsync是自己写的脚本,在评论区展示示)
4)启动:
./start-cluster.sh
访问 http://localhost:8081 可以对 flink 集群和任务进行监控管理。
提交任务(standalone模式)
1) 准备数据文件(如果需要)

2) 把含数据文件的文件夹,分发到 taskmanage 机器中
如 果 从 文 件 中 读 取 数 据 , 由 于 是 从 本 地 磁 盘 读 取 , 实 际 任 务 会 被 分 发 到 taskmanage 的机器中,所以要把目标文件分发。
3) 执行程序(这里程序入口,是flink快速上手中的StreamWC类)
./flink run -c com.test.wc.StreamWC –p 2flinkTest-1.0-SNAPSHOT.jar --Path /opt/software/data/hello.txt
4) 查看计算结果
注意:如果输出到控制台,应该在 taskmanager 下查看;如果计算结果输出到文 件,同样会保存到 taskmanage 的机器下,不会在 jobmanage 下。

Yarn 模式
以 Yarn 模式部署 Flink 任务时,要求 Flink 是有 Hadoop 支持的版本,Hadoop 环境需要保证版本在 2.2 以上,并且集群中安装有 HDFS 服务。
Flink on Yarn Flink 提供了两种在 yarn 上运行的模式,分别为 Session-Cluster 和 Per-Job-Cluster 模式。
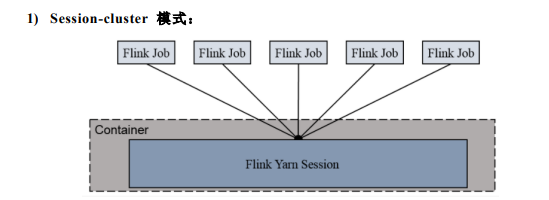
Session-Cluster 模式需要先启动集群,然后再提交作业,接着会向 yarn 申请一 块空间后,资源永远保持不变。如果资源满了,下一个作业就无法提交,只能等到 yarn 中的其中一个作业执行完成后,释放了资源,下个作业才会正常提交。所有作 业共享 Dispatcher 和 ResourceManager;共享资源;适合规模小执行时间短的作业。 在 yarn 中初始化一个 flink 集群,开辟指定的资源,以后提交任务都向这里提 交。这个 flink 集群会常驻在 yarn 集群中,除非手工停止。
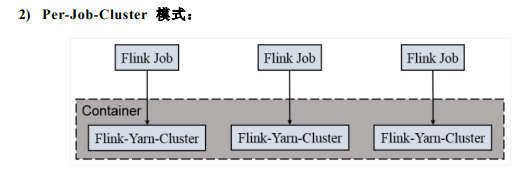
一个 Job 会对应一个集群,每提交一个作业会根据自身的情况,都会单独向 yarn 申请资源,直到作业执行完成,一个作业的失败与否并不会影响下一个作业的正常 提交和运行。独享 Dispatcher 和 ResourceManager,按需接受资源申请;适合规模大 长时间运行的作业。 每次提交都会创建一个新的 flink 集群,任务之间互相独立,互不影响,方便管 理。任务执行完成之后创建的集群也会消失。
Session Cluster
1) 启动 hadoop 集群(略)
2) 启动 yarn-session
./yarn-session.sh -n 2 -s 2 -jm 1024 -tm 1024 -nm test -d
其中:
-n(--container):TaskManager 的数量。
-s(--slots): 每个 TaskManager 的 slot 数量,默认一个 slot 一个 core,默认每个 taskmanager 的 slot 的个数为 1,有时可以多一些 taskmanager,做冗余。
-jm:JobManager 的内存(单位 MB)。
-tm:每个 taskmanager 的内存(单位 MB)。
-nm:yarn 的 appName(现在 yarn 的 ui 上的名字)。
-d:后台执行。
3) 执行任务
./flink run -c com.atguigu.wc.StreamWordCount FlinkTutorial-1.0-SNAPSHOT-jar-with-dependencies.jar --host lcoalhost –port 7777
4) 去 yarn 控制台查看任务状态
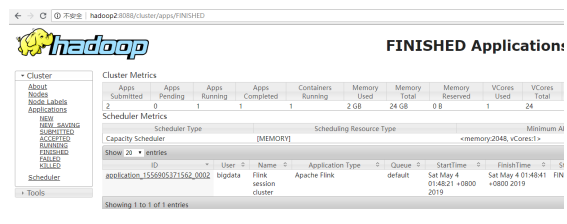
5) 取消 yarn-session
yarn application --kill application_1577588252906_0001
Per Job Cluster
1) 启动 hadoop 集群(略)
2) 不启动 yarn-session,直接执行 job
./flink run –m yarn-cluster -c com.atguigu.wc.StreamWordCount FlinkTutorial-1.0-SNAPSHOT-jar-with-dependencies.jar --host lcoalhost –port 7777
Kubernetes部署
由于博主对k8s不了解,这里就不详细写了 0-0

 浙公网安备 33010602011771号
浙公网安备 33010602011771号