ML学习十一——机器学习系统的设计
11-1 决定执行的优先级
这些视频将谈及在设计复杂的机器学习系统时,你将遇到的主要问题。同时我们会试着给出一些关于如何巧妙构建一个复杂的机器学习系统的建议。下面的课程的的数学性可能不是那么强,但是我认为我们将要讲到的这些东西是非常有用的,可能在构建大型的机器学习系统时,节省大量的时间。
接下来我们以垃圾邮件分类器算法为例,为了解决这样一个问题,我们首先要做的决定是如何选择并表达特征向量 x 。我们可以选择一个由100个最常出现在垃圾邮件中的词所构成的列表,根据这些词是否有在邮件中出现,来获得我们的特征向量(出现为1,不出现为0),规格为100×1。
-
收集更多的数据
-
基于邮件的标题构建一个复杂的特征
-
基于邮件的正文信息构建一个复杂的特征,包括考虑截词的处理
-
为探测刻意的拼写错误(把watch 写成w4tch)开发复杂的算法
我们无法知道那一种方法更有效,这需要我们自己的实践去证明
11-2 误差分析的思想
我们将会讲到误差分析(Error Analysis)的概念,这会帮助你更系统地在众多的方法中做出选择
构建一个学习算法的推荐方法为:
-
从一个简单的能快速实现的算法开始,实现该算法并用交叉验证集数据测试这个算法,即使不是很完美
-
绘制学习曲线,决定是收集更多数据,还是添加更多特征,还是其他选择
-
进行误差分析
接下来看一个实际的例子,这是我们误差分析的具体实现

如果在我们判断错的邮件类型中,我们的算法对于钓鱼邮件的判断表现很差,这就说明我们应该花更多的时间在研究这类邮件,是否我们可以利用更多的特征来为他们正确分类
11-3 不对称分类的误差评估
类偏斜:表示我们的训练集中有非常多的同一种类的样本,只有很少或没有其他类的样本。
如果在我们的训练集中,只有0.5%的实例是恶性肿瘤。假设我们编写一个非学习而来的算法,在所有情况下都预测肿瘤是良性的,那么误差只有0.5%。然而我们通过训练而得到的神经网络算法却有1%的误差。这时,误差的大小是不能视为评判算法效果的依据的。
所以接下来就是我们这里的重点查准率和查全率
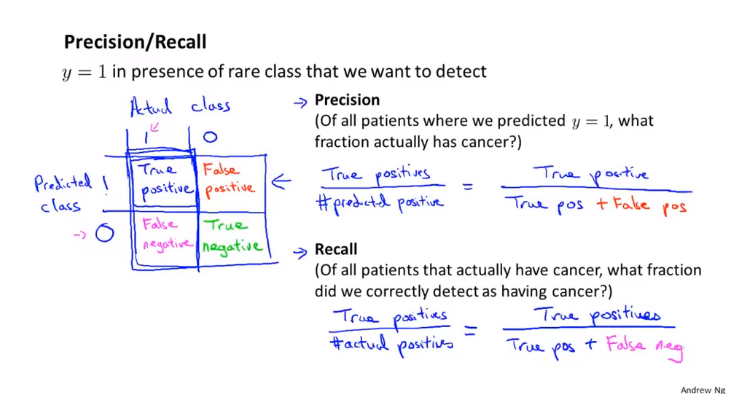
我们可以通过查准率和查全率判断我们的分类算法是否可靠(针对出现 比较少的类)
11-4 精准度和召回率的权衡
如果,我们的算法输出的结果在0-1 之间,我们使用阀值0.5 来预测真和假。

如果我们希望只在非常确信的情况下预测为真(肿瘤为恶性),即我们希望更高的查准率,我们可以使用比0.5更大的阀值,如0.7,0.9。
如果我们希望提高查全率,尽可能地让所有有可能是恶性肿瘤的病人都得到进一步地检查、诊断,我们可以使用比0.5更小的阀值,如0.3。
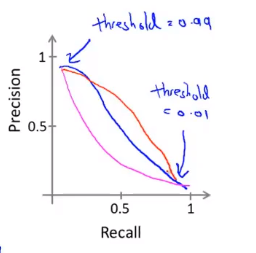
但是我们知道了查准率和查全率,如何决定哪一个算法更好呢?
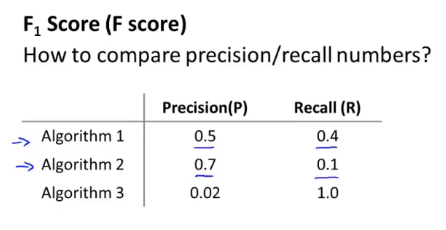
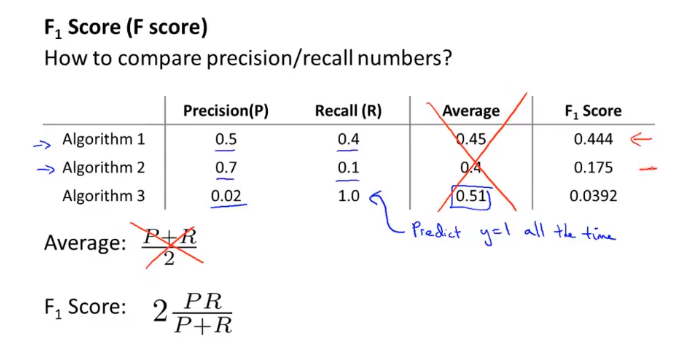
我们可以利用调和平均数来选择更好的算法或者阈值
11-5 机器学习数据
地址链接为:https://www.bilibili.com/video/BV164411S78V?p=69
我曾告诫大家不要盲目地开始花时间来收集大量的数据,因为大量的数据只在一些情况下起到作用。
我认识的两位研究人员进行了一项有趣的研究,他们尝试通过机器学习算法来区分常见的易混淆的单词,他们尝试了许多种不同的算法,并发现数据量非常大时,这些不同类型的算法效果都很好。

记得观看。。。。。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号