
Zookeeper与Eureka的区别
Zookeeper与Eureka的区别
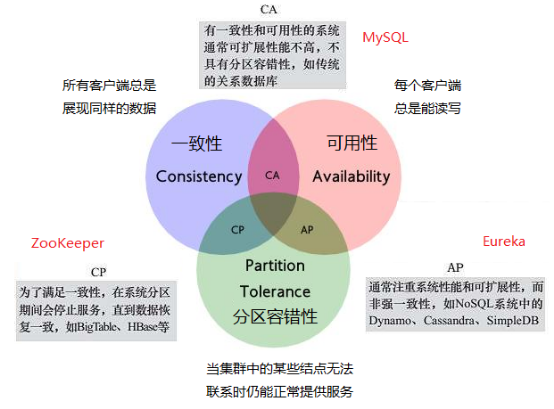
想要了解Zk与eureka的区别首先要知道CAP定理
CAP定理
Mysql强一致性(数据唯一出处),设计数据库设计的三范式
(表必须有主键;表不能有重复的列;列不能是加工而成)
主流数据库表的设计方式:反三范式,冗余设计(性能高,缺点:数据多处,同步数据时间差,短暂时间数据不一致。)
最终一致性,允许短暂时间内数据可以不一致,但过了这个时间阀值必须数据是一致。
可用性,zk主从设计,如果zk节点有一半节点宕机或者有节点正在选举,此时zk集群不可用!
Eureka,p2p点对点设计,每个点的信息都可以用户接入,每个点如果信息变化,它内部会自动同步所有的数据。Eureka即使所有的节点都宕机,
仍然能提供服务。EurekaClient客户端,缓存所有的数据信息,也能找到服务提供者。
为什么不用zookeeper做注册中心 在使用dubbo时,一般都结合zk(作为注册中心)来使用。那为什么SpringCloud中使用Eureka,而不是zk呢?
我们来比较一下,在CAP理论中,zk更看重C和P,即一致性和分区容错性。但Eureka更在意的是A和P,A为高可用。zk中有master和follower区别,
当进入选举模式时,就无法正常对外提供服务。但Eureka中,集群是对等的,地位是相同的,虽不能保证一致性,但至少可以提供注册服务。
根据不同的业务场景,各有取舍吧。ZooKeeper 基于CP设计,侧重一致性而Eureka基于AP设计,侧重可用性
Eureka只有一个8761的注册中心,那么如何避免单点问题呢?
我们可以采用集群的方式来解决。 比如现在有三台机器:Server1、Server2和Server3.在高可用方案中,三台机器要两两注册。
比如S1要向S2、S3分别进行注册,目前他无法实现注册的传递性。 这样一来,如果Server1宕机,我们还可以继续从Server2和3中获取服务。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号