

stream json output
Summary of Stream JSON parser
通过分析 Promptulate 项目的 issue,对问题进行了深入探讨并给出了相应的处理方案。本文将详细描述该问题的处理过程。
issues目标
-
原文如下
Currently, we cannot enable stream if setting output schema,
so Need to build a json parser to parse stream type json data like this:
![img]()
-
解读
对于 Promptulate 中的 Agent 输出,通常在指定输出格式(Output Formatter)后,只有在 Agent 输出完成后才能得到最终结果。
然而,当输出格式中的某些字段(Field)难以快速生成时,用户可能需要等待较长时间。因此,我们希望在输出过程中,将结果以流的形式逐步输出。

预期结果
如上图所示,我们希望在流式输出过程中,已生成的字段按格式输出,而尚未生成的字段标记为 None。
最终目标:用户可以指定 Output Formatter 并流式输出结果,且可以对结果进行动态处理。
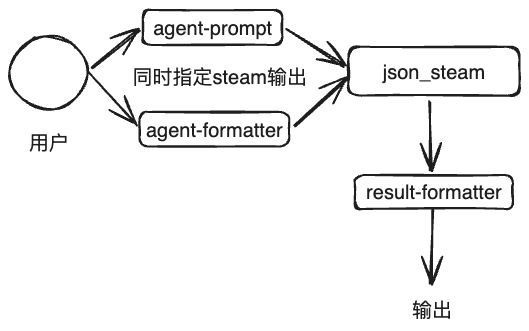
处理流程
1. 开始的时候,存在理解的错误。
误解
起初认为需要在输出多个 Output Formatter 对象时,将这些对象一个一个地流式输出。
在指定 Output Formatter 且 stream=True 的情况下,默认情况下会输出如下格式的流式数据:
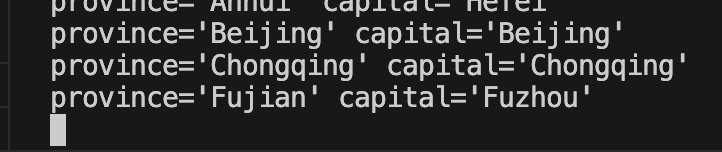

目前,agent在指定Output Formatter以及steam=true的情况下,默认会输出以下格式的流式数据
class LLMBaseResponse(BaseModel):
province: str = Field(description="province in China")
capital: str = Field(description="Capital of the province")
class LLMResponse(BaseModel):
provinces: List[LLMBaseResponse] = Field(description="List of provinces and capitals in China")
response = pne.chat(
api_key=DeepKey,
messages="Please tell me all provinces and Capital in China.",
output_schema=LLMResponse,
model="deepseek/deepseek-chat",
stream=True,
)
输入如下:
```json
{
{province='Sichuan', capital='Chengdu'},
{province='Liaoning', capital='Shenyang'},
……
}
```
这样的话,我们只需要对最外层的对象进行正则匹配。再逐一把内部对象匹配输出就行。
2. Review 反馈
我们需要在流式结果输出的过程中,展示单个json对象的输出流程。
并在没有匹配成功时通过None进行表示
期望结果如下:

3. 将目标进行分解
为了实现这个目标,我们主要应该考虑两点问题。
-
JSON 不完整情况下的处理:
如何将不完整的 JSON 数据补全为完整的 JSON 对象,并转换为指定的 Output Formatter。
-
处理 None 值:
如何将 None 值添加到 Output Formatter 字段中,并解决 Pydantic 中不接受 None 的字段报错问题。
# 产生如下报错 pydantic_core._pydantic_core.ValidationError: 1 validation error for LLMBaseResponse capital Input should be a valid string [type=string_type, input_value=None, input_type=NoneType] For further information visit https://errors.pydantic.dev/2.7/v/string_type
4.解决方案:
-
JSON 修复:
参考开源项目 half-json,该项目对 JSONDecoderError(JSON 解析失败的报错)进行了封装和处理,可以有效修复大部分不完整的 JSON 数据。
以此,我们对比一下修复前后的情况
修复前: { 修复后: {} 修复前: { 修复后: { } 修复前: { " 修复后: { "":null} 修复前: { "province 修复后: { "province":null} 修复前: { "province": 修复后: { "province":null} 修复前: { "province": " 修复后: { "province": ""} 修复前: { "province": "Beijing", 修复后: { "province": "Beijing", "}":null} 修复前: { "province": "Beijing", " 修复后: { "province": "Beijing", "":null} 修复前: { "province": "Beijing", "capital 修复后: { "province": "Beijing", "capital":null} 修复前: { "province": "Beijing", "capital": 修复后: { "province": "Beijing", "capital":null} 修复前: { "province": "Beijing", "capital": " 修复后: { "province": "Beijing", "capital": ""} 修复前: { "province": "Beijing", "capital": "Be 修复后: { "province": "Beijing", "capital": "Be"} 修复前: { "province": "Beijing", "capital": "Beijing 修复后: { "province": "Beijing", "capital": "Beijing"}可以看出,修复完成后的json格式数据,已经可以转化为Output Formatter的结果了。
-
使用 Optional 处理 None 值:
使用 Optional 对 Pydantic 模型进行封装,允许字段接受 None 值。
流程如下
def change_model(model: BaseModel) -> BaseModel: """change pydantic model to BaseModel Args: model (BaseModel): pydantic model Returns: BaseModel: BaseModel """ annotations = { field: Optional[type_] for field, type_ in model.__annotations__.items() } new_model = type(model.__name__, (BaseModel,), {"__annotations__": annotations}) return new_model这样我们得到的值就可以进行转化了
最终结果
通过 pydantic BaseModel 随时获取流式输出的对象的数据。
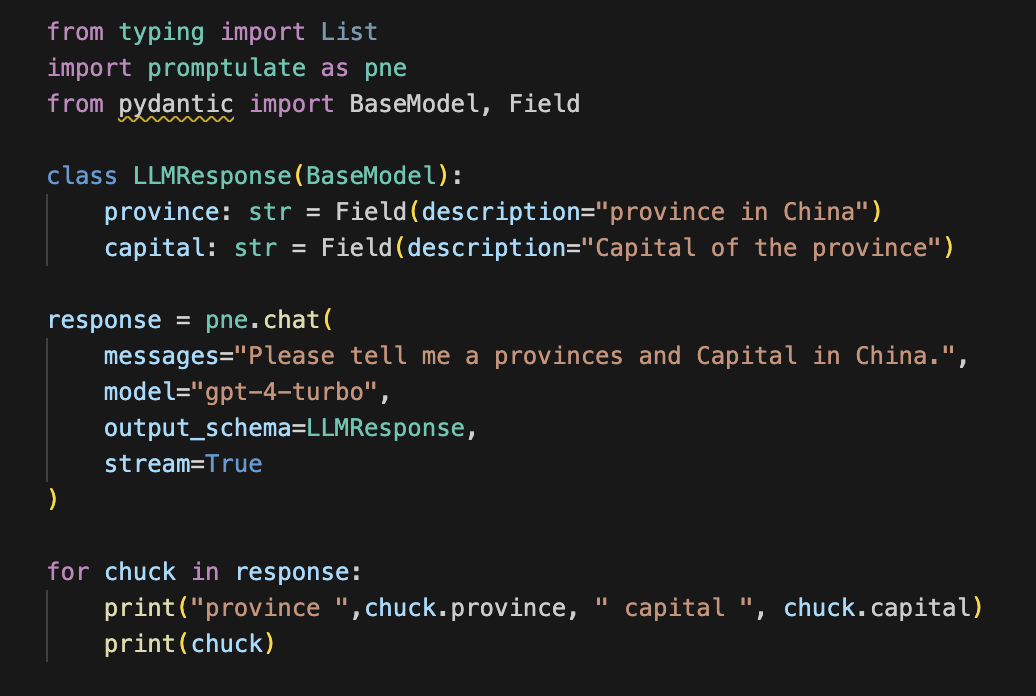
结果如下:

具体可以参考promptlate官方文档:https://www.promptulate.cn/#/use_cases/chat_usage?id=stream-json-parser
展望如下
上方解释了整个issues的完成过程,可是,同样的也存在一些问题。
-
json数据
-
数字的支持比较弱 --> -02 / 0. / .0
-
还不支持分支回溯 --> [{]
-
突然想到, 应该反思一下, 这个是一个fixer, 而不是一个将任何字符串都转为 json 的东西 应该明确 JSONFixer 的能力范围, 对 runratio.sh 也应该比较前后两个的 json 相似程度。 (听起来像无能者的辩白?)
-
也需要吧 parser 也做成 stack 这样可以解决 ["a] --> ["a"] 这样的 case
-
考虑分支回溯的方式来试探
-
解析缺失的 JSON 常量
-
-
由于在进行这样的做法时,返回的response与设置的Output Formatter不一致。
这样会产生什么样的问题呢,如果我需要对流失产生的数据转换会原来的Output Formatter的话,会产生报错。
举出具体的例子的话,就像这样:
class LLMBaseResponse(BaseModel): province: str = Field(None,description="province in China") capital: str = Field(description="Capital of the province") response = pne.chat( api_key=DeepKey, messages="Please tell me a provinces and Capital in China.", output_schema=LLMBaseResponse, model="deepseek/deepseek-chat", stream=True, ) for i in response: print(i.province,i.capital) # 条件转换 di_t = {} if i.province == None: di_t["province"] = "Unknown" if i.capital == None: di_t["capital"] = "Unknown" response = LLMBaseResponse(province=i.province,capital=i.capital) print(response) # 直接转换 response = LLMBaseResponse(province=i.province,capital=i.capital) print(response)报错如下
![img]()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号