
第一次个人编程作业
| 这个作业属于哪个课程 | <班级的链接> |
|---|---|
| 这个作业要求在哪里 | <作业要求的链接> |
| 这个作业的目标 | 使用java语言并配合代码质量和性能分析工具,实现一个能够进行代码查重功能的代码 |
文章目录
一、仓库地址
仓库地址:https://github.com/rookie-FL/rookie-FL
二、PSP表格(预测)
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 15 | |
| · Estimate | 估计这个任务需要多少时间 | 15 | |
| Development | 开发 | 60 | |
| · Analysis | · 需求分析 (包括学习新技术) | 60 | |
| · Design Spec | · 生成设计文档 | 30 | |
| · Design Review | · 设计复审 | 5 | |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 20 | |
| · Design | · 具体设计 | 30 | |
| · Coding | · 具体编码 | 60 | |
| · Code Review | · 代码复审 | 10 | |
| · Test | · 测试(自我测试,修改代码,提交修改) | 30 | |
| Reporting | 报告 | 30 | |
| · Test Repor | · 测试报告 | 30 | |
| · Size Measurement | · 计算工作量 | 20 | |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | |
| ·total | 合计 | 435 |
三、计算模块接口的设计与实现过程
3.1 设计原理
SimHash的主要思想是降维,即将高维的特征向量转化成一个固定长度的二进制指纹。这个指纹在一定程度上能够表征原内容的相似度。具体来说,SimHash算法通过以下几个步骤实现:
- 分词:将文本进行分词处理,形成特征单词序列,并去除噪音词。
- Hash:对每个特征单词使用传统的Hash算法(如MD5、SHA-1等)生成一个固定长度的二进制签名。
- 加权:根据单词的重要性(如使用TF-IDF加权)对Hash签名进行加权处理,形成加权数字串。
- 合并:将所有单词的加权数字串进行累加,得到一个整体的数字串。
- 降维:将累加后的数字串进行降维处理,即将每一位上的数字与0进行比较,大于0则记为1,否则记为0,最终得到一个固定长度的二进制指纹(即SimHash签名)。
3.2 项目的结构
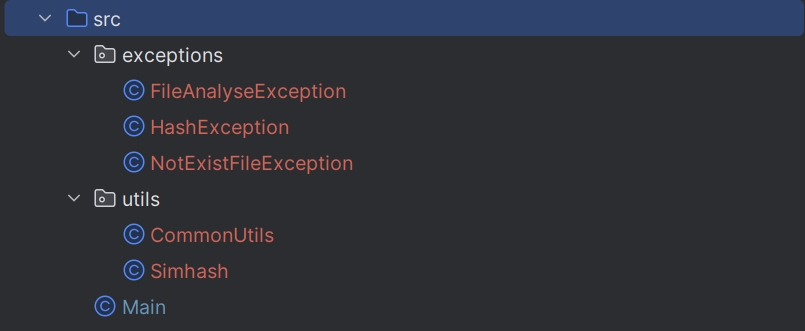
3.3 代码组织
代码中共有两个类,分别是Common和Simhash。
3.3.1 Common类:
-
readFile 函数 ,用以读取传入的绝对路径的文件,将其转化为字符串方便后续读取。
-
analyseText 函数,用以将读取的字符串进行处理,提取关键词并存储。
-
writeFile 函数,用以把内容写入指定文件。
3.3.2 Simhash类
-
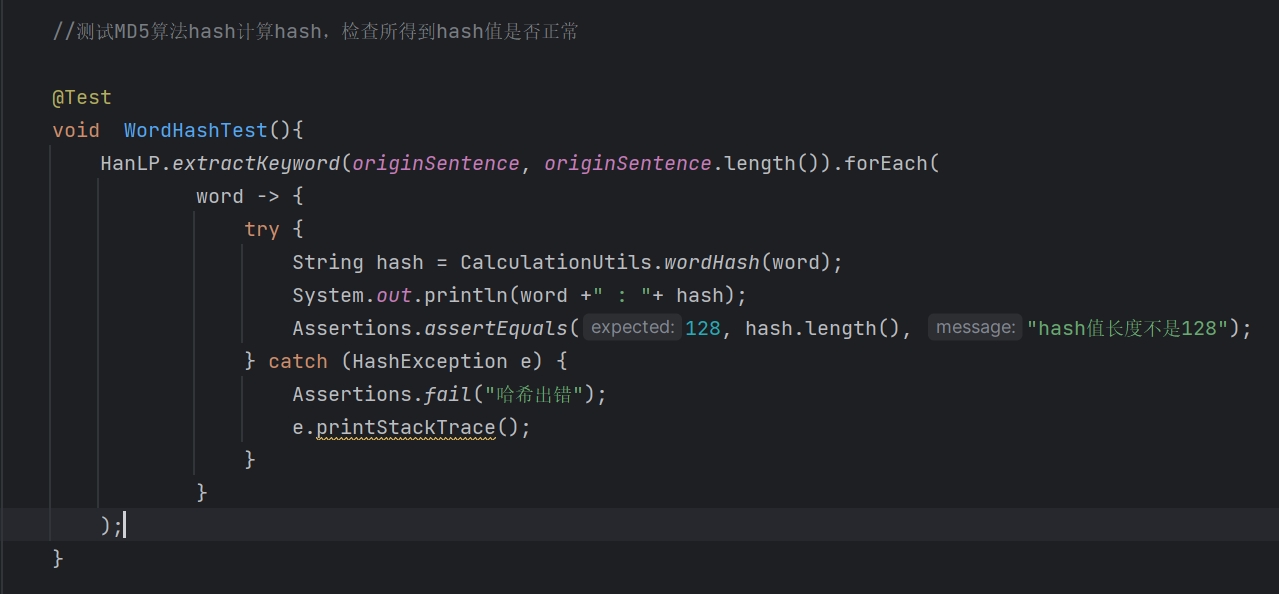
wordHash 函数, 将给定的字符串(单词)转换为MD5哈希值,并进一步将MD5哈希值转换为128位二进制字符串。
-
hashWeight 函数,据给定的二进制哈希值和权重,将二进制中的每一位('0'或'1')转换为相应的加权整数。
-
getSimHash 函数,根据加权后的哈希数组,生成最终的simHash字符串,其中加权后的正值转换为'1',负值转换为'0'。
-
calculateSimHash 函数,根据词语及其出现次数的映射,计算并返回每个词语的simHash,并合并这些simHash以生成最终的simHash。
-
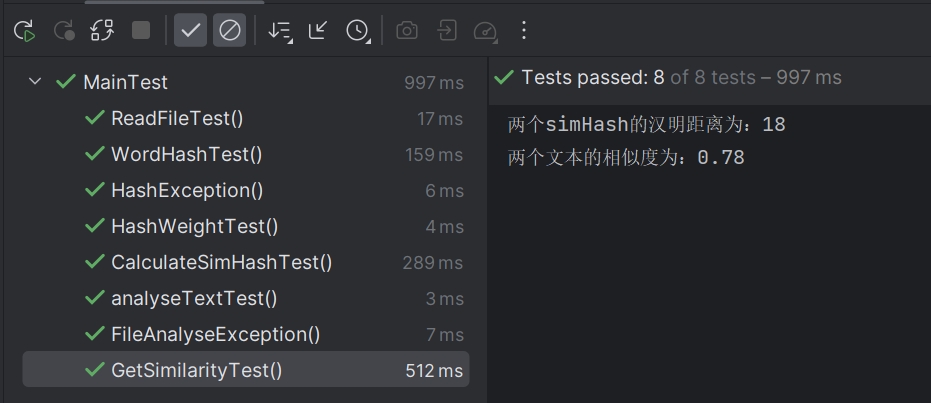
getSimilarity 函数,计算两个simHash之间的相似度,这里使用了汉明距离来计算相似度。
3.3.3 关系图&流程图
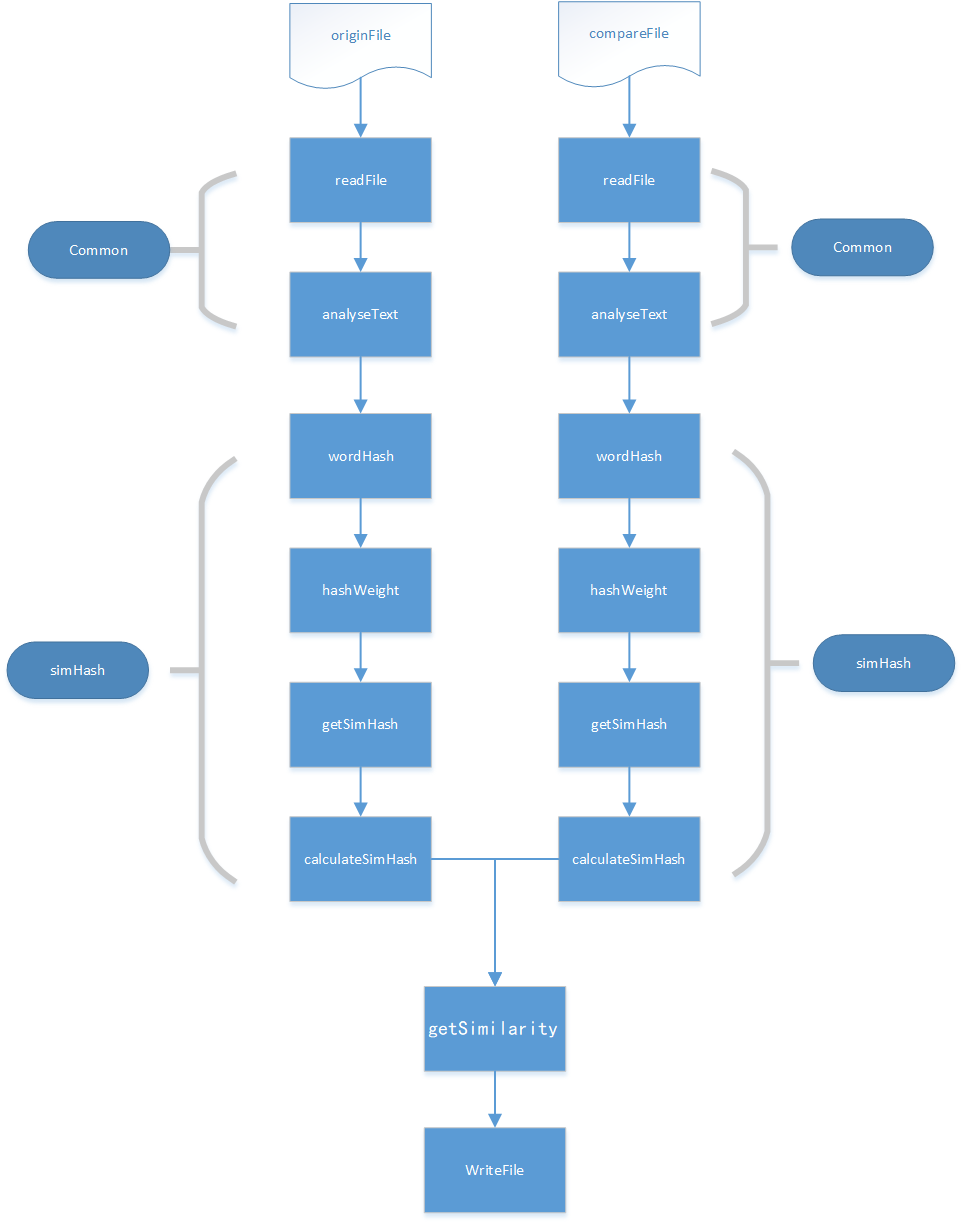
3.3.4
几个关键点与独到之处:
-
wordHash
检查输入词语是否为空或空白。
使用MD5算法对词语进行哈希处理。
将MD5哈希值(原本为16进制)转换为128位的二进制字符串。 -
hashWeight:
将输入的二进制哈希字符串中的每一位('0'或'1')转换为相应的加权整数('1'为正值,'0'为负
值,同时使用加权方式处理二进制哈希值,这在合并多个哈希值以生成SimHash时非常有用。它允许根据词语的重要性来调整其对最终SimHash的贡献。 -
getSimHash:
将加权后的哈希数组中的正值转换为'1',负值转换为'0',生成最终的SimHash字符串,通过简单的正负值转换来降维得到SimHash,这种方法简洁且高效。
-
calculateSimHash:
遍历词语及其出现次数的映射,对每个词语进行哈希加权处理,并将结果合并成一个最终的SimHash,将文本表示为一组词语及其权重的映射,并基于这些权重计算SimHash,这有助于捕捉文本的整体内容特征。 -
getSimilarity
计算两个SimHash之间的汉明距离。
尝试使用一种类似杰卡德系数的变体来计算相似度,但这里的实现方式并不完全遵循杰卡德系数的标准定义。
四、模块接口的性能改进
总览
这里使用idea集成的jprofiler进行
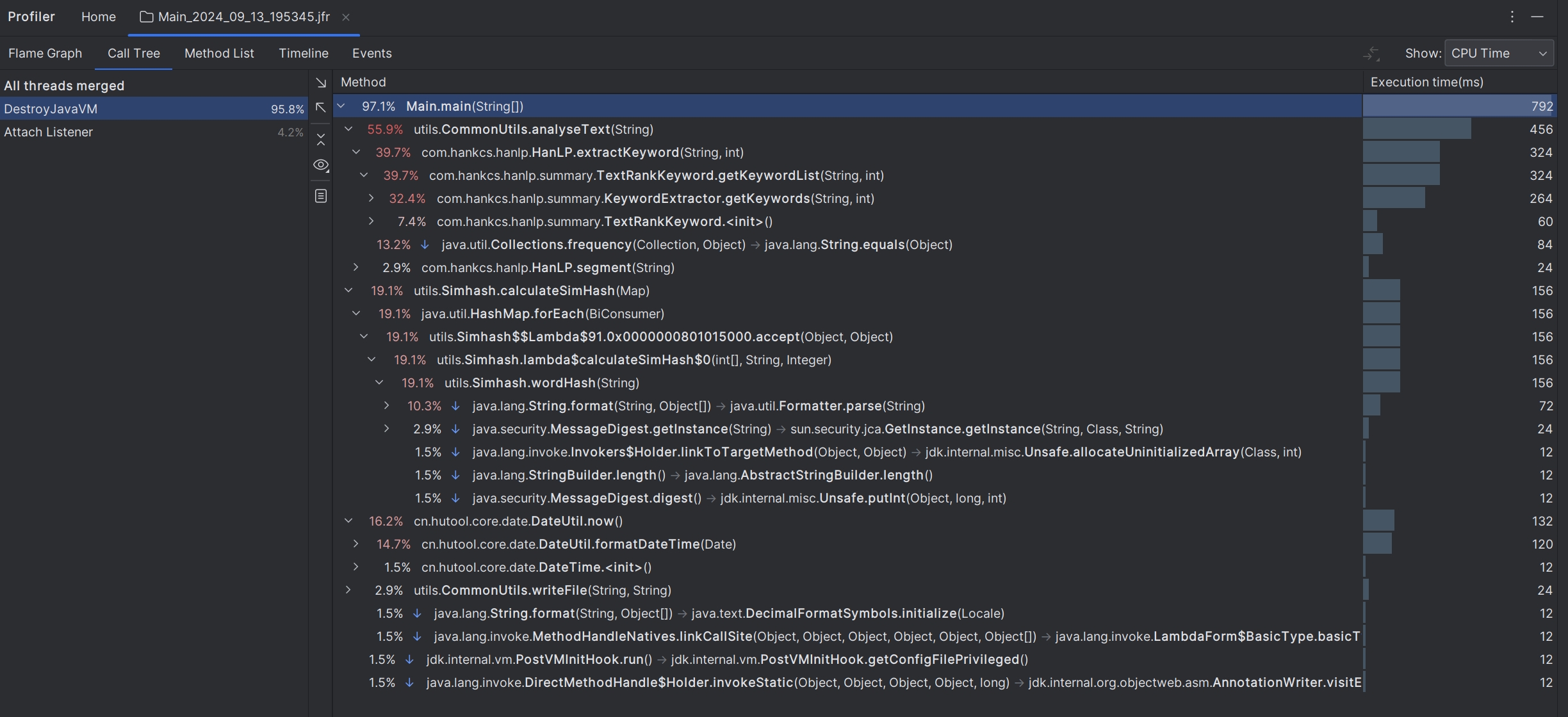
由上图可以看到程序执行所消耗的总时间将近0.8s,其中 common 类中的 analyseText 函数占比最多为 55.9%,其次时 Simhash 类中的 calculateSimHash 函数中调用的 wordHash函数 占比为 19.1%。
改进
- analyseText 函数:
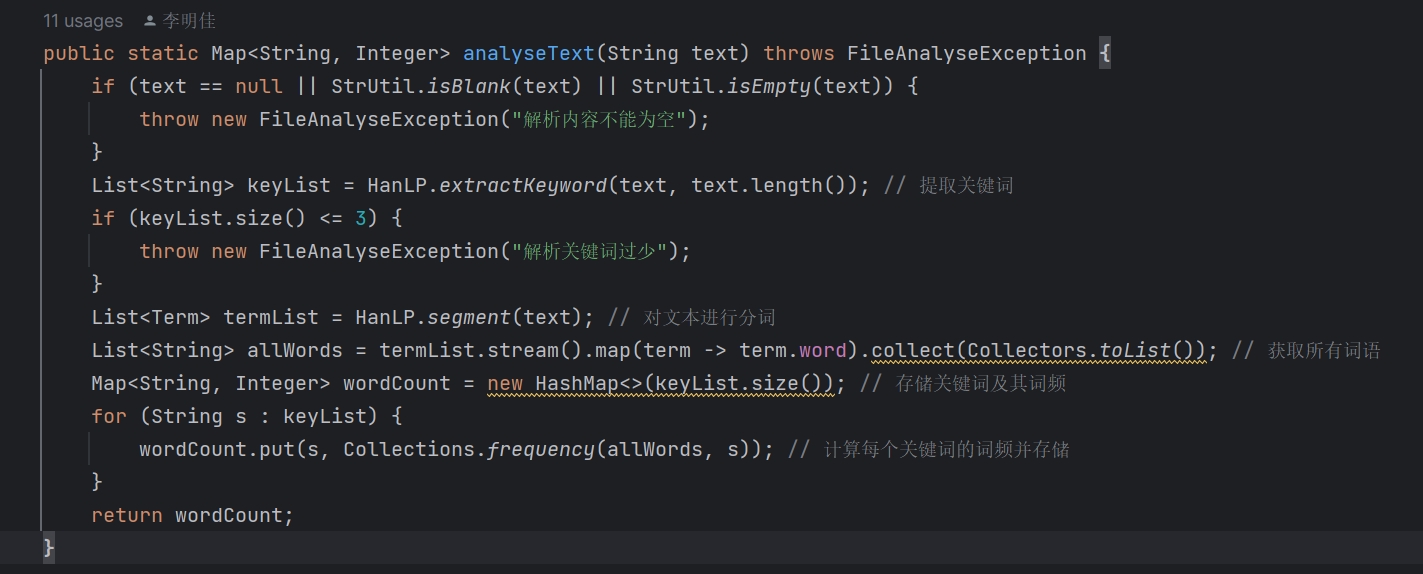
函数 analyseText 的功能主要是接受一个文本字符串作为输入,然后通过HanLP库提取关键词并进行分词,再计算每个关键词在文本中的词频,最后返回一个包含关键词及其词频的映射。
改进策略
这里性能的主要占用是由于HanLP库对全文进行关键词分词,经过查阅在实际应用中,为了降低资源消耗并提高分词效果,通常会结合多种分词方法,如结合基于词典的分词法和基于统计的分词法,或者利用预训练的词向量和深度学习模型来进行分词。这些方法可以在保证分词准确性的同时,通过优化算法和减少不必要的计算来降低资源消耗。
- wordHash 函数
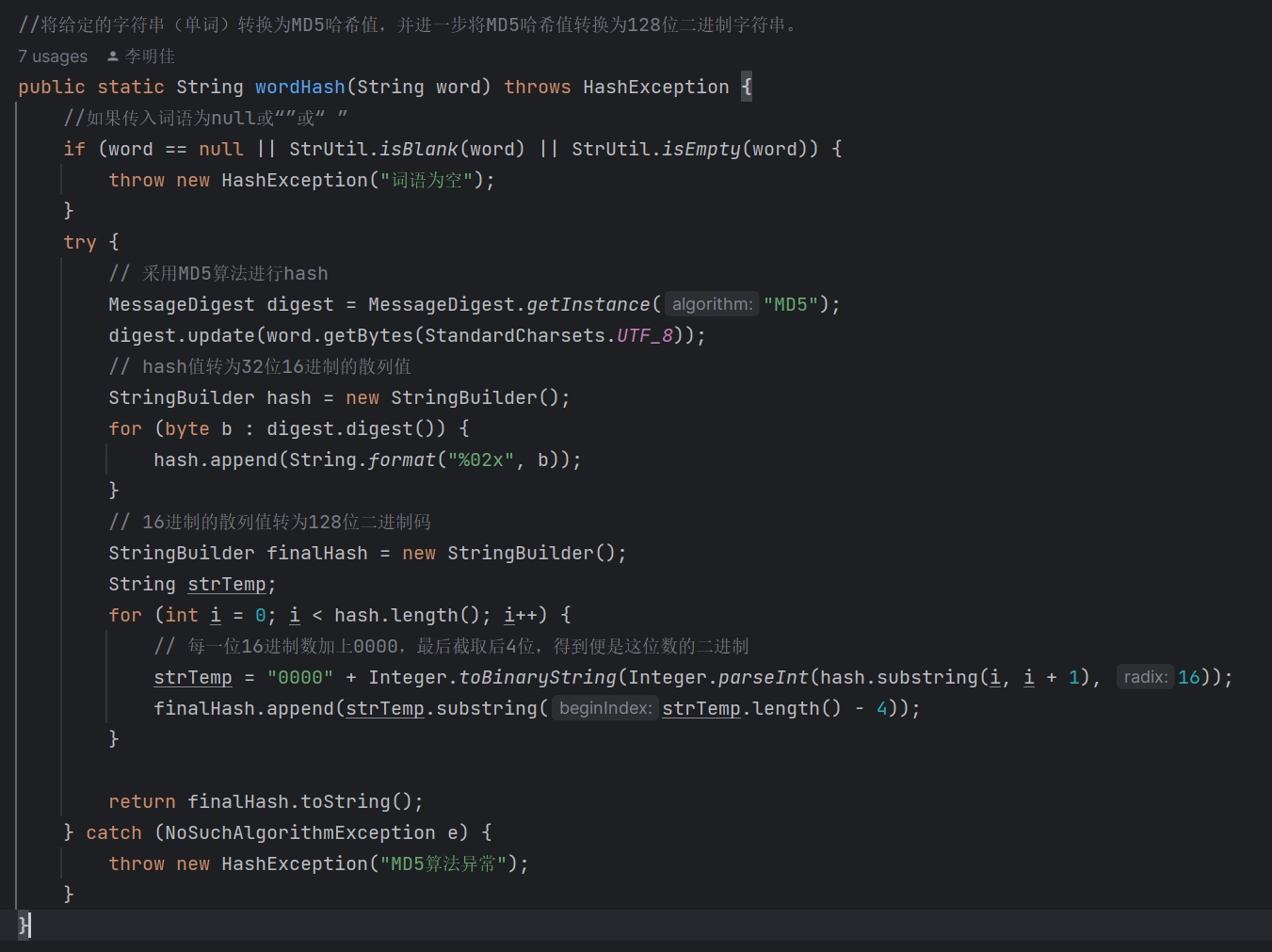
函数 wordHash 的功能是将一个给定的字符串通过MD5算法进行哈希处理,并将得到的MD5哈希值从通常的32位16进制表示转换为128位二进制表示。
改进策略
-
减少遍历次数:由上述分析,计算simhash值过程中大量使用了遍历,占用了许多资源。因此减少遍历次数可以提升算法效率。
-
减少hash码位数:本项目中使用MD5算法将词语转化为不重复的唯一的128位二进制编码,但关键词太多会导致消耗大量存储空间存储数值。因此我认为可以减少哈希码位数,减少存储空间的浪费。
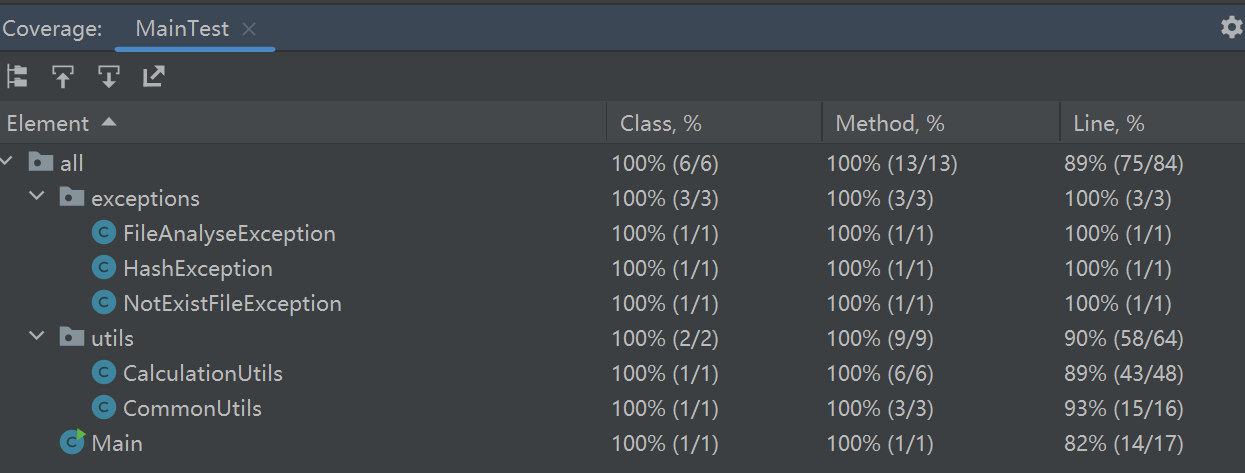
五、模块部分单元测试展示
5.1 单元测试覆盖率
5.2 部分关键点测试展示
总览
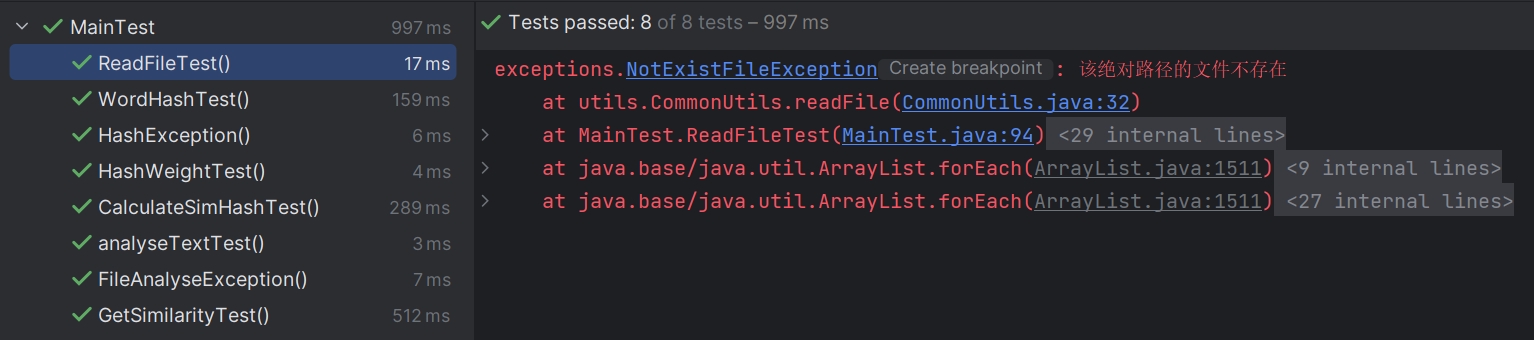
ReadFile测试:
- 代码
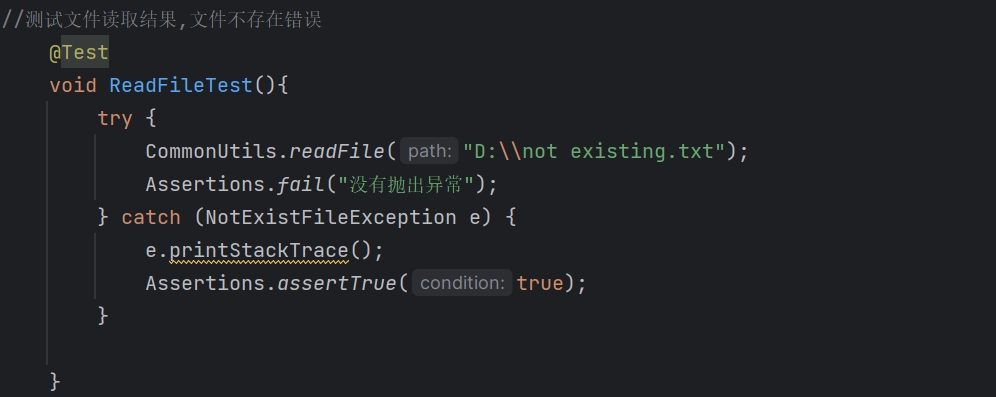
- 结果
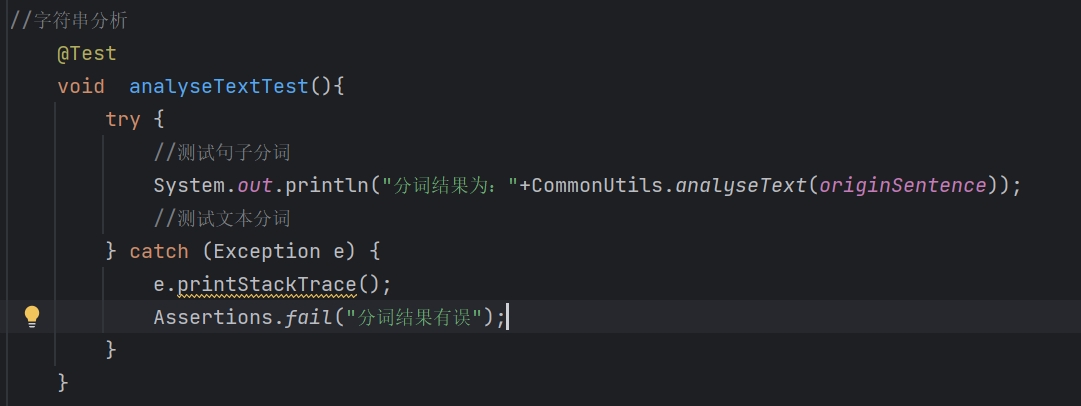
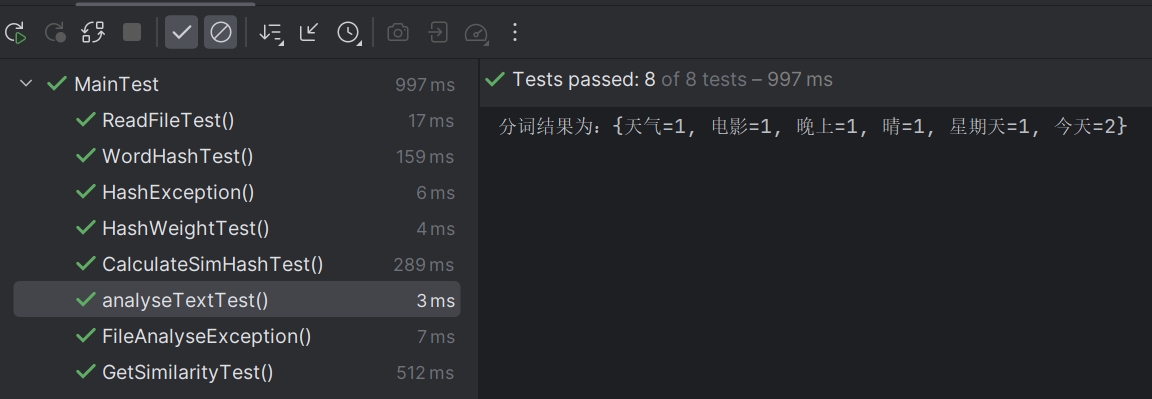
analyseText测试:
- 代码
- 结果
wordHash测试:
- 代码
- 结果

hashWeight测试:
- 代码
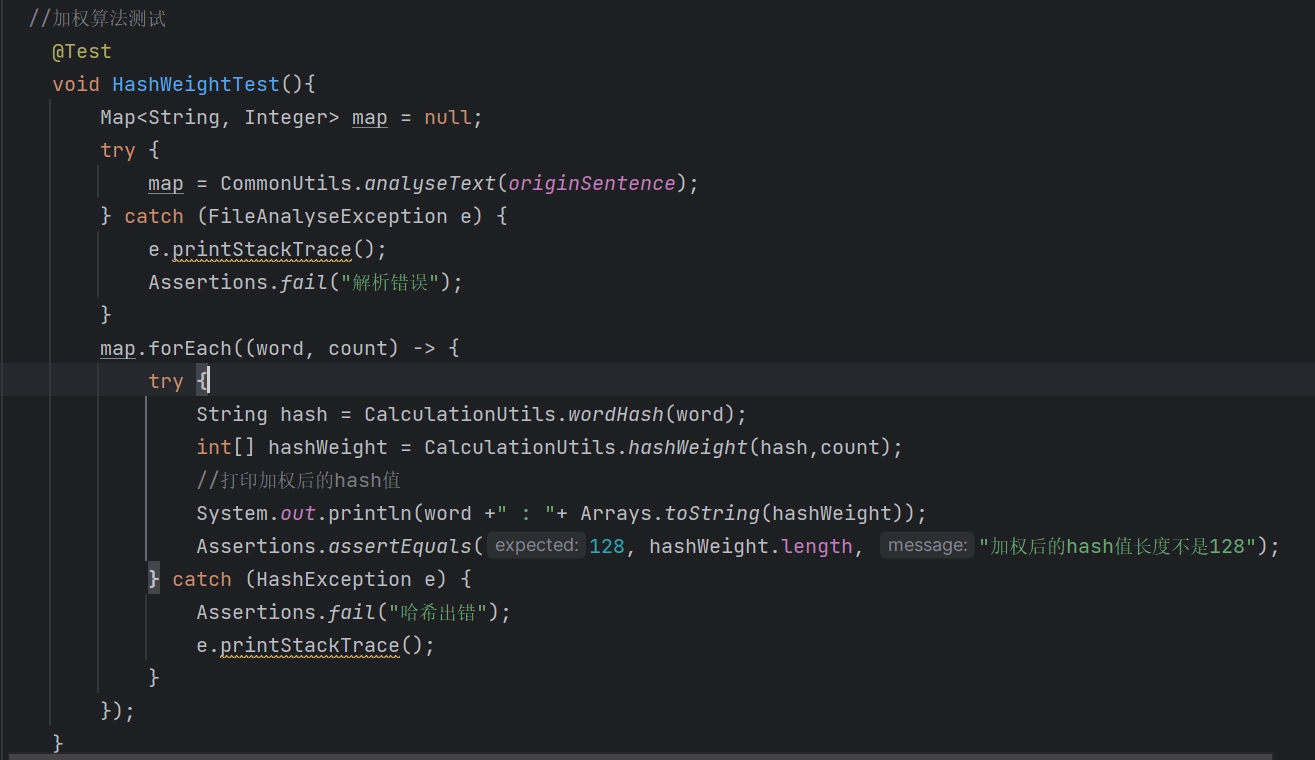
- 结果

calculateSimhash测试:
- 代码
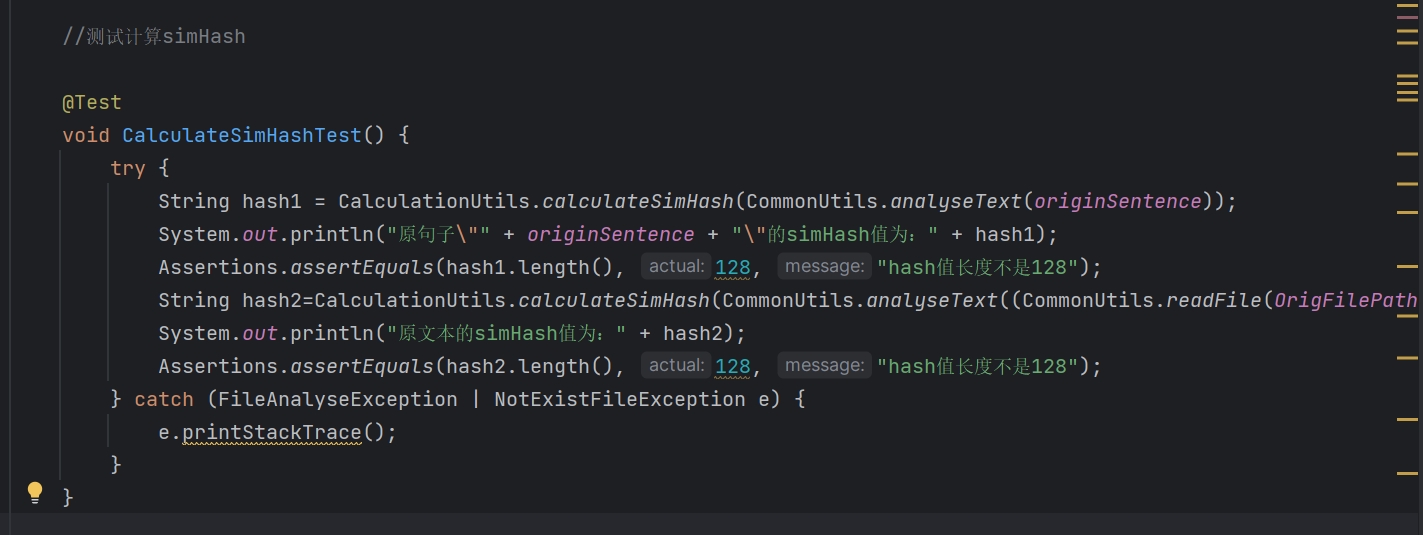
- 结果

getSimilarity测试:
- 代码
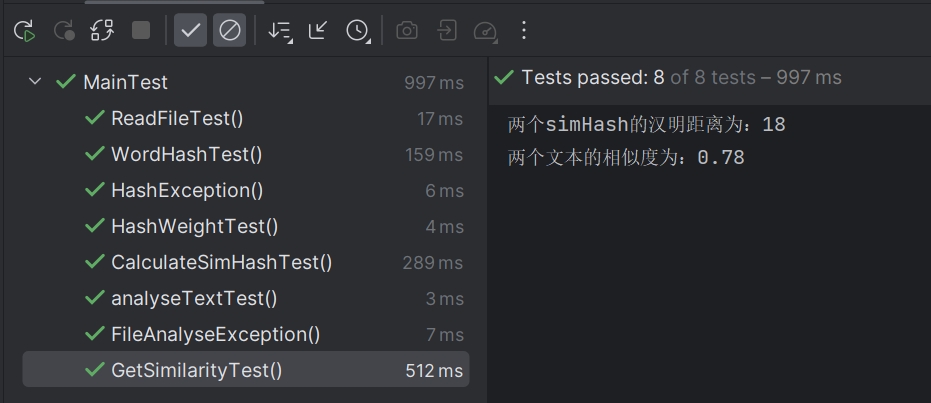
- 结果
六、模块部分异常处理说明
6.1 测试文件读取异常
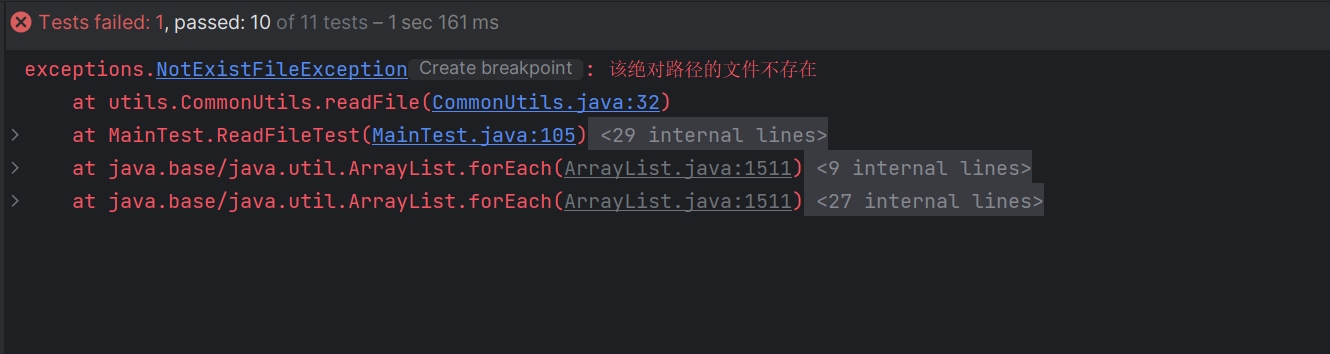
说明:文件在尝试从文件系统中读取文件时发生异常,这些原因包括但不限于:
-
文件不存在:尝试访问的文件在指定路径下不存在。
-
权限问题:程序没有足够的权限来读取文件。
-
资源限制:系统资源(如文件句柄)耗尽,无法打开更多文件。
-
文件被锁定:文件正在被其他进程使用,并且以独占方式锁定,从而阻止当前进程读取。
6.2 测试文本解析异常
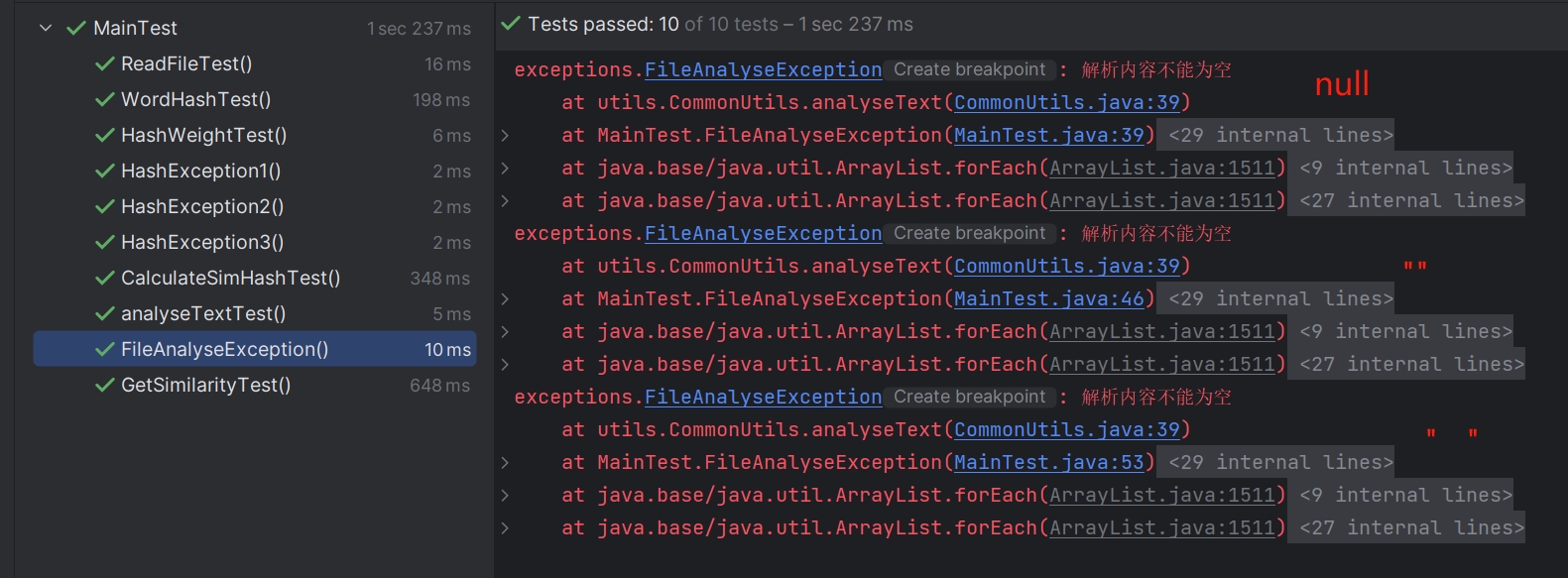
说明:文本解析异常发生在尝试从文本数据中提取信息或将其转换为特定格式时遇到问题。这些问题包括但不限于
-
格式错误:文本数据不符合预期的格式或结构。
-
编码问题:文本数据的编码方式与程序期望的不匹配,导致无法正确解析。
-
数据不完整:文本数据缺少必要的部分,导致无法完成解析过程。
-
语法错误:在解析过程中发现语法上的错误,如 XML、JSON 或其他结构化文本格式中的错误。
6.3 HashException 测试哈希异常
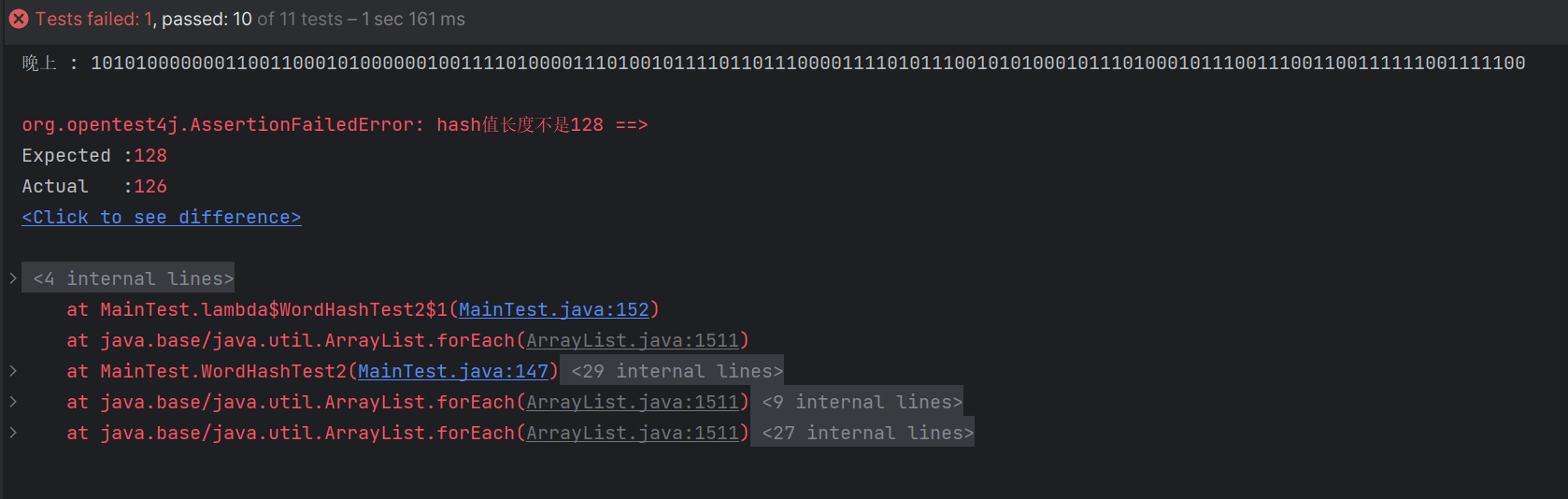
说明:哈希异常在本文中指的是在尝试获取哈希所必备的参数或在计算哈希值遇到的特定问题,这些问题包括但不限于
- 输入参数问题:参数不符合预期,输入数据太大、太小或包含无法处理的字符,导致哈希计算失败。
- 内存不足:哈希值较为复杂的时候,可能导致系统内存不足。
- 内部错误:哈希算法实现中的错误或缺陷导致计算失败。
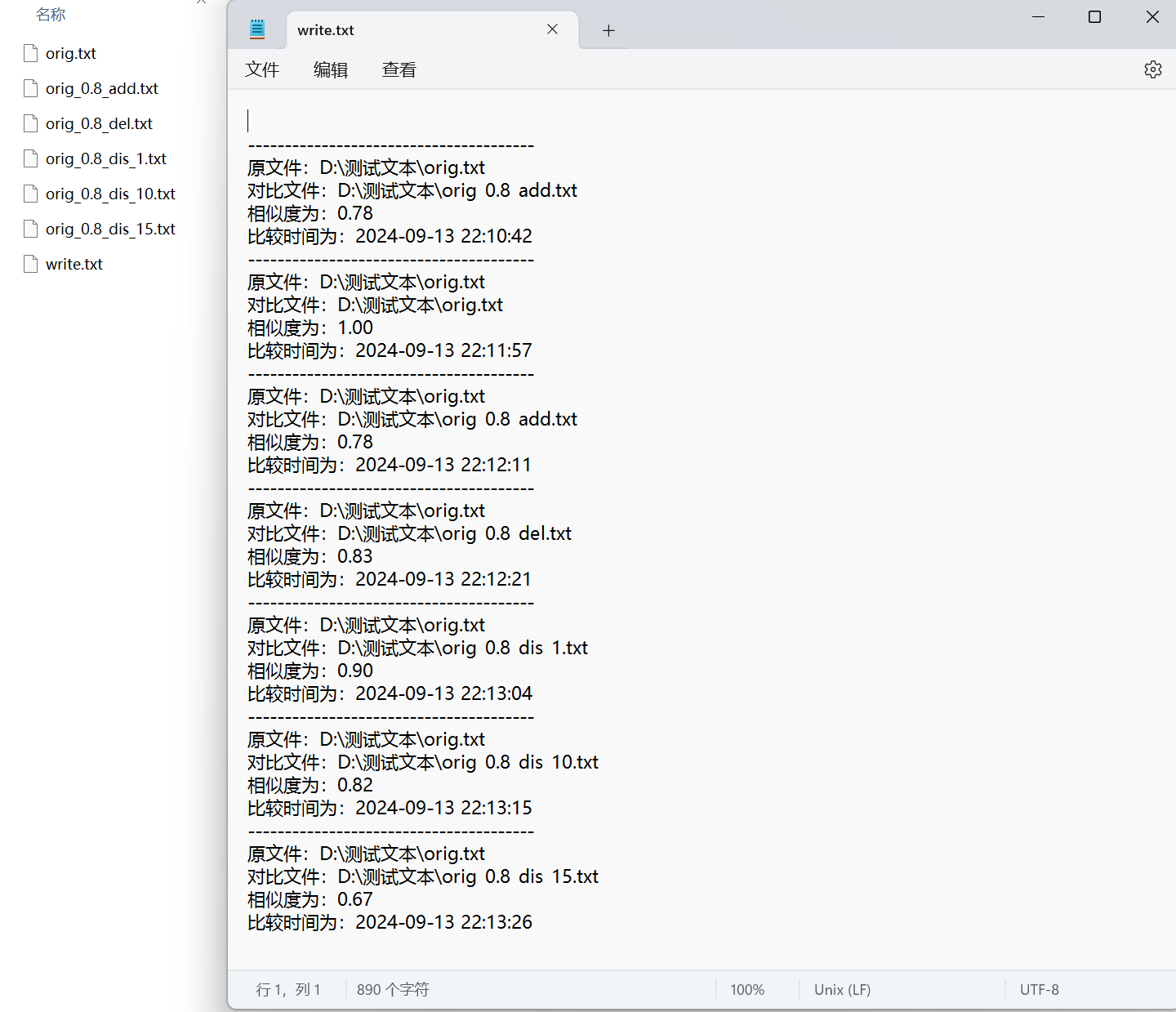
八、各文件结果展示
八、PSP表格(实际)
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 15 | 20 |
| · Estimate | 估计这个任务需要多少时间 | 15 | 20 |
| Development | 开发 | 60 | 120 |
| · Analysis | · 需求分析 (包括学习新技术) | 60 | 600 |
| · Design Spec | · 生成设计文档 | 30 | 30 |
| · Design Review | · 设计复审 | 5 | 5 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 20 | 20 |
| · Design | · 具体设计 | 30 | 60 |
| · Coding | · 具体编码 | 60 | 120 |
| · Code Review | · 代码复审 | 10 | 20 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 30 | 60 |
| Reporting | 报告 | 30 | 30 |
| · Test Repor | · 测试报告 | 30 | 30 |
| · Size Measurement | · 计算工作量 | 20 | 30 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 30 |
| ·total | 合计 | 435 | 1195 |

