单张亿级大表分表方案
1、前言
生产环境使用的是postgresql数据库,其中有一张角色表t_role_right,包含了公司各产品的角色和权限项,目前有大约5亿数据,好在建表初期建立了比较合理的索引,查询起来走索引的话速度还是挺快的,目前运行良好。但是单表5亿数据实在是太大了,虽然不知道postgresql单表数据量的极限在哪,估计已经快逼近极限了,一旦此表造成数据库崩溃,将会影响公司所有产品线,这将是灾难性的后果,所以分表迫在眉睫。表结构如下:
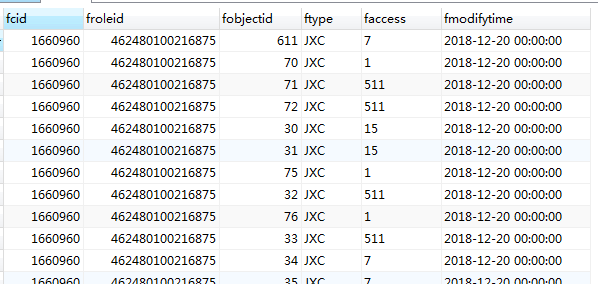
字段说明:
fcid 公司ID
froleid 角色ID
ftype 产品类型
fobjectid 模块ID
faccess 各权限项之和
fmodifytime 修改时间
其中一个公司下面有多个角色,一个角色拥有多个产品下面多个模块的权限,联合主键为(fcid,froleid,ftype,fobjectid)
2、分表方案
首先想到的分表方案就是采用中间件,目前比较流行的中间件有MyCat和当当网的sharding-jdbc1、MyCat
MyCat是一个真正意义上的中间件,它需要单独安装,并且启动一个独立的服务
2、Sharding-Jdbc
Sharding-Jdbc是一个第三方jar包,可以直接植入到项目中,但是它对表之间的left join支持不是很好
因此,以上两种方案均被否定,最后采用的是Mybatis拦截器的分表方案
3、Mybatis
分表方案为:利用公司ID对40取模,将表分到40个新表中(新表和原来的大表结构一模一样),t_role_right_0,t_role_right_1,t_role_right_2 ... t_role_right_39
配置文件:
代码:
@Intercepts({
@Signature(type = StatementHandler.class, method = "prepare", args = {Connection.class, Integer.class})
})
public class ShardingInterceptor implements Interceptor {
private static final String TABLE = "t_role_right";
private static final String EXCLUDE_TABLE = "t_role_right_4upgrade";
private static final int SHARDING_NUM = 40;//分表数量
@Override
public Object intercept(Invocation invocation) throws Throwable {
StatementHandler statementHandler = (StatementHandler) invocation.getTarget();
BoundSql boundSql = statementHandler.getBoundSql();
String sql = boundSql.getSql();
if(sql.contains(TABLE) && !sql.contains(EXCLUDE_TABLE)){
//获取SQL语句参数中的公司ID
ParameterHandler parameterHandler = statementHandler.getParameterHandler();
Object parameter = parameterHandler.getParameterObject();
long cid = 0L;
if(parameter instanceof RoleRight){
RoleRight rr = (RoleRight)parameter;
cid = rr.getCid();
}else if(parameter instanceof Long){
cid = (Long)parameter;
}else{
Map<String,Object> args = (HashMap<String,Object>)parameter;
if(args.containsKey("list")){
List<RoleRight> rrList = (List<RoleRight>)args.get("list");
for(RoleRight rr : rrList){
cid = rr.getCid();
break;
}
}else{
cid = Long.parseLong(String.valueOf(args.get("cid")));
}
}
//公司ID对40取模,得到该公司ID对应的新表
String shardingTable = TABLE + "_" + cid % SHARDING_NUM;
//将原SQL语句中的t_role_right替换成新表
String newSql = sql.replace(TABLE, shardingTable);
//通过反射修改sql语句
Field field = boundSql.getClass().getDeclaredField("sql");
field.setAccessible(true);
field.set(boundSql, newSql);
}
return invocation.proceed();
}
@Override
public Object plugin(Object target) {
return Plugin.wrap(target, this);
}
@Override
public void setProperties(Properties properties) {
//此处可以接收到配置文件中的property参数
}
}
可以看到,上述程序不需要修改xml文件中的SQL语句,即可动态的实现CRUD操作到分表后的表。
3、迁移数据
程序处理完之后,接下来就是要迁移数据了,迁移数据尝试了以下几种方案:1、postgresql存储过程
先查出所有的公司ID,再循环依次以公司ID为单位insert into select from
create or replace function sharding()
returns integer as $$
declare
cidCur cursor for select distinct fcid from t_role_right;
v_tbl varchar;--由于表名不能使用变量,所以需要动态生成sql,再执行
v_sql varchar;
v_cid numeric;
i integer;
begin
open cidCur;
i:=0;
fetch cidCur into v_cid;--必须先fetch一条,否则found为false
while found loop
v_tbl := 't_role_right_' || v_cid % 40;
v_sql := concat('insert into ',v_tbl,' select * from t_role_right where fcid = ',v_cid);
execute(v_sql);
i:= i+1;
raise notice 'cid=%成功迁移到表%',v_cid,v_tbl;
fetch cidCur into v_cid;
end loop;
close cidCur;
return i;
END;
$$
LANGUAGE plpgsql;
在内网环境测试了一下,内网t_role_right表中有50多万条数据,执行存储过程只需要7-9秒,速度还是很快的
但是postgresql这个版本(9.6.1,select version()可查看版本号)有一个很大的问题:就是存储过程是一个整个的事务,无法拆分成多个事务,也就是说insert into select from这条语句执行完之后不会提交,要等所有数据执行完毕之后,一次性提交5亿数据,这种结果无疑是很慢的,一旦发生异常,5亿数据要全部回滚,具有不可预料的风险。
2、多线程
上面的存储过程无法做到一个insert into select from作为一个事务提交,那我就用程序来实现它,多线程。
上网搜了一下,对于IO密集型的应用,则线程池大小设置为2N+1,N是CPU核数,很明显,我们的应用就属于这种,所以线程池大小设置为9
将程序打成jar包放到内网服务器上执行,发现执行时间很慢,同样是内网50多万条数据,用多线程跑完,发现需要20多秒,这个更无法接受了
我分析了一下原因,可能就是应用程序的内存和数据库服务器的IO比较慢,还有网络传输等因素影响了执行时间。
怎么办?上面两种方案都不合理,但是当天晚上就要停机发布,已经提前发布停机公告了,从0点到3点,只有3个小时的时间。
越是到紧要关头,越能想出点子,我灵机一动,不就是要实现把insert into select from作为一个事务提交嘛,为什么不简单粗暴一点呢?
3、SQL
insert into t_role_right_0 select * from t_role_right where mod(fcid,40) = 0;
insert into t_role_right_1 select * from t_role_right where mod(fcid,40) = 1;
insert into t_role_right_2 select * from t_role_right where mod(fcid,40) = 2;
insert into t_role_right_3 select * from t_role_right where mod(fcid,40) = 3;
.....
insert into t_role_right_39 select * from t_role_right where mod(fcid,40) = 39;
直接写出40条SQL语句,分别在不同的窗口执行,这不就相当于多线程吗?并且每个insert into select from还是独立的事务提交,就是工作量大了点,需要点40次执行,但是至少达到了我们的目的。
确定了这个方案,说干就干,马上拉到内网测试,取一个公司ID最多的数据,大约15000条数据,4秒左右就执行完了,大功告成!
后面DBA想到了建一个条件索引的办法,索引建好之后,还是取公司ID最多的数据,执行insert into select from,2秒左右就完成了,效率提升了一倍。
CREATE INDEX index_01_t_role_right ON t_role_right (fcid) WHERE fcid % 40=0;
CREATE INDEX index_01_t_role_right ON t_role_right (fcid) WHERE fcid % 40=1;
CREATE INDEX index_01_t_role_right ON t_role_right (fcid) WHERE fcid % 40=2;
...
CREATE INDEX index_01_t_role_right ON t_role_right (fcid) WHERE fcid % 40=39;
此处建索引还有优化的空间,生产有5亿数据,建一个索引会花很长时间,建40个那就更费时间了,所以,把上面的40条索引合并为1条
CREATE INDEX index_mod_t_role_right ON t_role_right (mod(fcid, 40)) ;
OK!到此,所有的准备工作都做好了,坐等发布和迁移数据了
4、发布生产
运维停机之后,DBA就开始操作了,先把40张表和各自的索引建好,然后重启数据库,清空所有连接,保证没有新的数据写入t_role_right表中 在迁移之前,我先统计了一下t_role_right表中的数据,方便和后面分表后的数据对比理想很丰满,现实很骨感
我们数据库部署在腾讯云上,之前有在内网测试过,5亿数据建索引大约需要32秒左右,但是在腾讯云上建索引快半个小时了,还是没有完,不知道是不是腾讯云的问题,后来DBA找腾讯云的客服,客服找对应的技术人员,鼓捣了一个小时才建好索引,
建好索引之后,就开始多个窗口执行insert into select from了,过程很顺利,一个小时左右就全部执行完了
我写了一个存储过程,专门用来统计分表之后各个新表的数据总和,统计结果和之前记录的t_role_right表中的数据一致
create or replace function count_sharding()
returns integer as $$
declare
v_tbl varchar;--由于表名不能使用变量,所以需要动态生成sql,再执行
v_sql varchar;
v_count numeric;
v_temp_count numeric;
i integer;
begin
i:=0;
v_count :=0;
while i<40 loop
v_tbl := 't_role_right_' || i;
v_sql := concat('select count(1) from ',v_tbl);
execute(v_sql) into v_temp_count;
raise notice '表%数量=%',v_tbl,v_temp_count;
v_count := v_count + v_temp_count;
i:= i+1;
end loop;
return v_count;
END;
$$
LANGUAGE plpgsql;
然后将原来的t_role_right表重命名,防止有数据写进来,启动数据库服务
应用服务恢复之后,通知各产品线的测试,结果一切正常。
至此,分表方案完美成功!

