深入浅出SSD
感谢文文姐的好书推荐
第一章 SSD综述
SSD(Solid State Drive)固态硬盘,以半导体闪存(NAND Flash)作为介质的存储设备。
主要由:主控,内存,缓存芯片DRAM,PCB(电源芯片,电阻,电容等),接口(SATA,SAS,PCIe等)。主体为PCB。
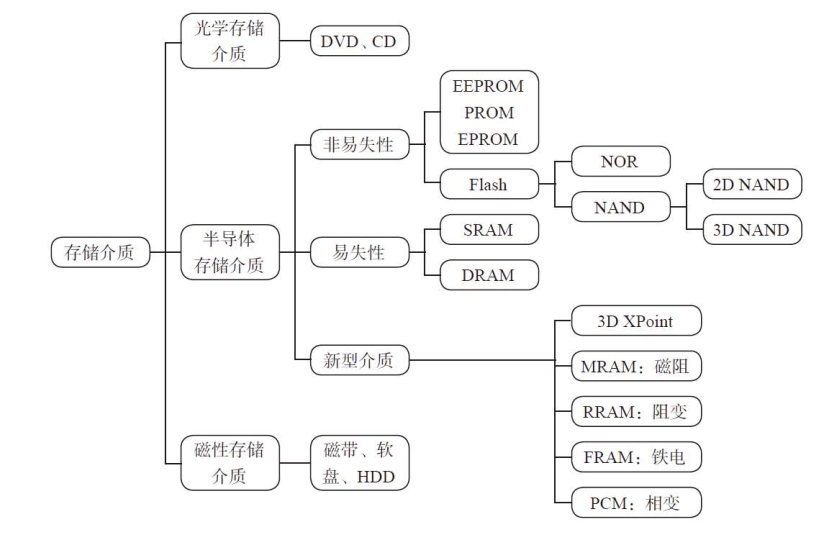
存储介质:1. 光学存储介质:DVD,CD等光盘介质,靠光驱等主机读取或写入。
2. 磁性存储介质:HDD。
3. 半导体芯片存储介质:SSD。主要是:闪存,3DX Point,MRAM,RRAM等。
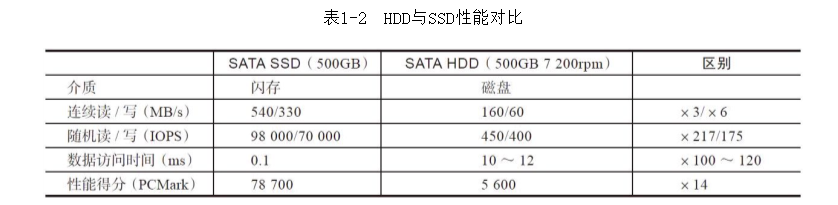
SSD相对HDD的优势:性能好:能超过几倍甚至几百倍,特别是在随机读写上。
功耗低:HDD为6~8W,SATA SSD为5W,待机时SSD可以降到mW。
抗震防摔:SSD内部没有机械部件,而HDD磁头和磁片发送碰撞,会产生物理损坏。
无噪音:因为SSD不需要HDD的马达。
小巧:HDD一般3.5/2.5寸。SSD除此之外还有可以贴在主板的M.2,甚至16mm*30mm的芯片级别。
SSD的三大模块:前端接口和相关协议模块。中间FTL层(包含:坏块管理,地址转换,垃圾回收,磨损均衡)。后端和闪存通信模块。
SSD前端负责和主机通信,接收数据和命令,返回状态和数据给主机。采用如:SATA(ATA协议),SAS(SCSI协议),PCIe(NVMe协议)等接口与主机连接。

SSD的几大核心参数:
1. 基本信息:容量,介质信息,外观尺寸,重量,环境温度,震动可靠性,认证,加密等。
2. 性能指标:连续读写带宽,随机读写IOPS,时延,最大时延。
3. 数据可靠性和寿命:可靠性,寿命。
4. 功耗:Power Management,Active Power和Idle Power。
5. 兼容性:Compliance,Compatibility。
基本信息:
1. 容量:对于128GB十进制和二进制中,二进制会比十进制多7%。一般称二进制为裸容量,十进制为用户容量,多的7%用于空间管理和存储内部数据。
2. 介质信息:如寿命,擦除和读取时间,温度的影响等。如表1-6.
SLC单位存储1bit速度快,寿命长,但价格为MLC的3倍。MLC单位存储2bit,速度一般,寿命一般,价格一般。TLC单位存储3bit,速度慢,寿命短,价格便宜。

3. 外观尺寸:如2.5寸,3.5寸,M.2,PCIe,mSATA,U.2等标准。
4. 温度:工作温度0~7°,开机后。非工作温度-50~90°,运输时。
性能剖析:
1. 性能指标:IOPS:单位处理IO次数。吞吐量:每秒处理数据量。响应时间:时延,即发出到收到的时间。
2. 访问模式:随机和连续,随机就是连续的命令LBA不连续。Block Size块大小,一般随机测试4k,顺序测试512k。读写命令混合,将读写按照比例混合进行测试。
3. 时延指标:平均时延指总时间除以总命令。最大时延则是响应时间最长的,直接影响用户体验。
4. 服务质量:Quality of Service,QoS。通过记录2个9(99%)以及5个9(99.999%)的查看分布。
5. 性能数据一览:对SSD来说满盘和空盘写入速度相差很大(会触发垃圾回收)。对HDD来说由于覆盖写,因此满盘和空盘写相差不大。
寿命剖析:总寿命是多少,能写入多少数据量
1. DWPD:每天可以把盘写满多少次。如:200GB SSD 五年使用期限内对应寿命是3600TB,平均每天1972GB。相当于每天可以写入10次。
2. TBW:SSD的生命周期内可以写入的字节数。TWB=单盘容量 * NAND鞋擦出寿命 / 写放大。 DWPD = TWB / (年限 * 365 * 单盘容量 )
数据可靠性剖析:
1. UBER:不可修复的错误比特率。即应用了纠错机制后仍产生的错误数。原因在于:擦写磨损,读取干扰,编程干扰,数据保持。
2. RBER:原始错误比特率
3. MTBF:平均故障间隔时间。主要考虑失效率,由于不同环境区别很大,因此需要借助软件进行测试。
功耗和其他剖析:
1. SSD产品功耗:空闲功耗(Idle):SSD没有接受命令,但也不进入省电模式。Max active功耗:最大工作负载的功耗,如连续写。
Standy/Sleep功耗:Standy,Sleep下,尽量把不工作的模块关闭,一般100~500mW。 DevSleep功耗:这是在Standy和Sleep在降一级,配合操作系统完成休眠,一般10mW以下。
对于SSD的功耗模式需要和主机配对,当主机切换到某功耗模式下,SSD也进行切换。
S0:工作模式,OS可以管理SATA的Power State。
S1:低唤醒模式,系统上下文不会丢失,硬件负责维持。
S2:与S1相似,但处理器和系统Cache上下文会丢失。需要从系统的reset vector开始。
S3:睡眠模式,CPU不执行命令,SATA SSD关闭,除了内存之外的所有上下文丢失。保存一部分处理器和L2Cache配置上下文。
S4:休眠模式,CPU不执行命令,DDR写入SSD中,所有上下文丢失。
S5:相似S4,但不会保存和恢复任何上下文,消耗电量很少,可通过鼠标唤醒。
2. 最大工作功耗与发热控制:因为功耗主要在于主控和闪存,其也是发热大户。若热量积累到一定程度,器件就会损坏,50~60度不加以控制概率就会增大,因此控制温度需要设计降温算法。
SSD温度传感器感受到70度,启动算法,限制闪存后端并发写的个数,但也带来性能的下降。
SSD的兼容性:
1. BIOS和操作系统的兼容性:SSD上电后,主机BIOS开始自检。与SSD发送连接,识别并读取盘信息(产品号等),验证格式和数据的正确性,读取其他信息,直到读取到MBR(主引导程序)
再读取硬盘分区表(PDT),找到活动分区中分区引导记录(PBR),并将控制权给PBR。(若任意一步出错都会导致蓝屏等)
兼容性认知:OS种类,主板上CPU南北桥芯片组信号和各个版本。BIOS各个版本。特殊应用程序各个版本。
2. 电信号兼容性和硬件兼容性:主机提供的电信号出于非稳定状态,存在抖动但仍在误差内。此时需要SSD设计,并能正常工作。
3. 容错处理:即主机发生错误的条件下,若能提供足够日志就更好了。
接口形态:为了统一规范,制定了Form Factor规范。
SATA SSD为消费级产品和企业级低端产品。
PCIe借助高性能,以及NVMe的的定制和普及,开始兴起。
SAS SSD基本用于企业级,由于成熟的SAS协议和软件生态,从HDD到SSD,虽然介质变了,但接口没变。
mSATA与标准SATA相比体积减小,用于消费级笔记本,但M.2出现后,基本替代了M.2。
M.2作为超极本量身定制的接口标准,用于替代mSATA,具备小巧等特点。
U.2 起步于PCIe,后用于统一SATA,SAS,PCIe物理接口,减少下游SSD应用场合的接口复杂度。
2.5寸:主流企业的SSD,包括SATA,SAS,PCIe接口。由于闪存密度逐年增大,容量会越来越大。
M.2:B和M key,是两种主流M.2的定义。B为Socket 2,M为Socket 3。M可以多支持PCIe 4通道。
BGA SSD:随着高度集成化,封装技术越来越成熟,PCB 2.5寸大小的存储器可以放到16*20 mm^2 BGA中。
M.2 BGA相对M.2 节约15%空间,增加10%电池寿命,节约0.5~1.5mm的高度。具有更好散热性(封装后,由ball pin传导走)
江波龙P900PCIe BGA SSD:率先发布目前世界最小尺寸的NVMe PCIe SSD(11.5mm*13mm)。容量方面可以提供512G~60G的选择。支持PCIe接口,NVMe协议,主控配备硬件加速器。
支持微软HMB功能,支持Boot Partition功能,采用了64层3D TLC,相对2D有更高存储密度。
SDP(SATA Disk in Package):将SSD主控,闪存芯片封装成一体化模块,只需要加上外壳就成为了SSD产品。
相对传统PCBA品质高,灵活性好,CKD适合,库存管理轻松。同时SSD成品生产时间从15天缩短到1天。产能15k/天变为100k/天。
U.2:目的统一SAS,SATA,PCIe接口,方便部署。
固态存储市场:SSD正在取代HDD。
HDD与SSD应用场合:SSD主要存放热数据,需求小,但性能优先的。HDD存放温和或冷数据。容量大价格优先的。
数据加速层:PCIe接口的高性能SSD
热数据:普通SATA SSD和SAS SSD
温数据层:高性能HDD
冷数据:HDD
归档层:大容量廉价HDD甚至磁带。
第二章 SSD主控和全闪存阵列


前端:主机接口:用来与主机通信,主要为SATA,SAS,PCIe。
SATA为Serial Advanced Technology Attachment 串行高级技术附件。
SAS 为Serial Attached SCSI 串行连接SCSI。SAS可以向下兼容SATA,接口标准上看,SATA为SAS的子标准,SAS控制器可以控制SATA盘,SATA控制器不能控制SAS盘。
SAS由3种协议构成:SSP用于传输SCSI命令。SCSI管理协议SMP用于对连接设备的维护和管理。STP用于SAS和SATA直接的数据传输。 因此可以和SATA以及部分SCSI设备结合。
PCIe 作为高速串行计算机扩展总线标准。提供电源管理,错误报告,端对端的可靠性传输,热插拔,服务质量(Qos)等功能。单道最高可达2GB/s,最多有32个通道。
前端接收串行比特数据流,转为数据信号给前端后续模块处理。其中涉及数据搬移会使用DMA。命令信息放到队列,数据放到SRAM。若涉及加密压缩会进行处理,但可能造成瓶颈。
以一条SATA Write FPDMA命令为例:主机发送写命令,请求到达南桥AHCI寄存器,AHCI执行请求进行写操作。
1. 主机在总线发出Write FPDMA命令FIS(实现异步传输而使用的封包)
2. SSD收到命令后,判断内部写缓存(Write Buffer)是否有空间去接受新数据,有则发送DMA Setup FIS到主机,否则什么也不发,主机处于等待。
3. 主机端收到DMA Setup FIS,发送不大于8k数据的Data FIS给设备。
4. 重复2~3直到数据发送完毕。
5. 设备发送Status FIS给主机,表示操作完成。Status可以是good 或 bad表示正常或者异常。
SSD接收命令和数据放到SSD内部缓冲区后,前端固件模块需要进行解析,并分派任务给中端FTL,判断是读/写命令,其实LBA位置和长度,是否有其他属性。命令解析完放到队列,排队等待中断FTL排队处理。由于拥有了LBA和数据长度重要信息,可以准确映射到物理空间。
(多核CPU,软件分为对称多处理(SMP)多核共享OS和执行同一份代码。非对称多处理(AMP)多核分别执行不同代码)
主控CPU:即SSD控制器SoC模块,由一个或多核CPU构成。代码存储区为I-RAM,数据存储区D-RAM。外围模块如UART,GPIO,JTAG,以及定时模块等。
后端:ECC模块和闪存控制器。
ECC模块为数据编码单元,为了保证数据正确性,给原数据进行校验保护。包括BCH和LDPC,LDPC逐渐成为主流。
闪存控制器负责管理数据从缓存到闪存的读写。从闪存控制器角度看,为了并发可以配置多个通道,一个通道挂多个闪存(取决于SSD容量和性能)。
(闪存芯片 Die/LUN是一个闪存命令执行的基本单元,外部接口:8个IO接口,5个使能信号(ALE,CLE,WE#,RE#,CE#),1个状态引脚(R/B#),1个写保护引脚(WP#)。命令,地址,数据通过8个IO接口输入输出,写入数据需要WE#,CE#信号拉低,数据在WE#上升沿锁存,CLE/ALE区别数据还是地址)
-----------------------TODO SSD主控厂商-----------------------------------------
桂格(SiliconGo)SG9081主控
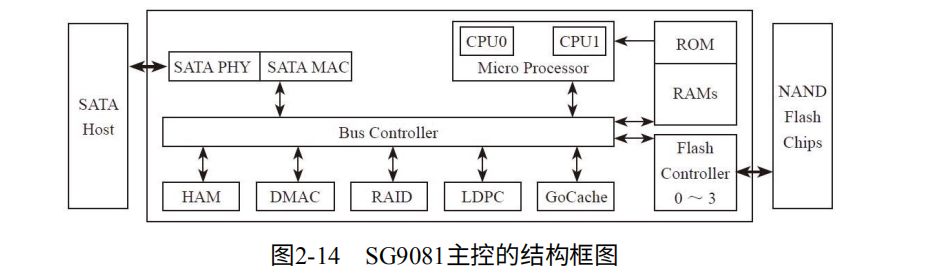
1. HAM+GoCache加速随机读写IOPS:HAM作为硬件加速器,释放了MCU的资源,加速了算法的实现。主控集中了GoCache高效实现了映射关系。
2. DMAC加速顺序读写:在数据传输时不用一直占据MCU资源,DMA启动后,将总线交给DMAC,此时MCU可以做其他工作。
3. LDPC+RAID提高可靠性,增强闪存耐久度和数据留存能力:由于2D向3D转换,纠错能力已经无法满足了,LDPC+RAID可以提高稳定性。
企业级与消费级归一化设计:通常企业级SSD更注重随机性能,延迟,IO Qos的保障。消费级注重顺序性能,功耗,价格等。
1. 成本方面:企业级SSD对控制器价格不敏感,因此需要注重消费级成本,优化硬件资源。
2. 性能方面:在数据中心对数据流做了大量优化,数据以顺序方式写入SSD,降低了企业级随机性能的需求。
3. 寿命:主要原因在闪存的耐久能力。SSD控制器则能确保加强闪存的纠错能力。
4. 容量:控制器需要较小的代价支持大容量的闪存。
5. 可靠性:企业级一般要求ECC与DIE-RAID两次保护。随着3D发展,消费级也开始提供DIE-RAID,因此目标趋于一致。
6. 功耗:消耗级如平板,笔记本等,对功耗要求严格,随着企业 SSD大规模部署,低功耗也成为企业级的追求目标。
全闪存阵列AFA:包含两个X-Brick(一个高级UPS电源,两个存储控制器,磁盘阵列柜DAE(包含了多个SSD用SAS连接到存储控制器)),一个Infiniband交换机(连接多个X-Brick)。
存储控制器:配有两个电源,两个CPU(256G内存),两个Infiniband控制器,两个SAS HBA卡。
配置:内部容量10TB,可用容量7.5TB。但考虑去重和压缩大约5:1。实际使用37.5TB。
性能:平均带宽350~400MB/s,20k IOPS,最高20GB/s 200k IOPS。
硬件架构:EMC XtremIO完全根据闪存特性设计,一个X-Brick包含两个存储控制器,封装了25个400G的SSD,原始容量10TB,拥有两个电池备用电源。
擦除寿命为普通MLC长了一个数量级。X-Brick支持级联,如Scale-Out架构可以达到4/8个
40Gbps Infiniband接口用于后端连接数据库。阵列和主机控制端可以使用8Gbps的FC,或10Gbps的iSCSI。
同时采用为每块数据Hash唯一值,来进行去重,剩下大量空间。一个X-Brick,4KB写,100k IOPS。 4KB读,250k IOPS。

软件架构:XtremIO (XIO)硬件构造的核心在软件。XIO软件几大杀器:
1. 去重提高性能,降低写放大延长了寿命。2. 分区容量随着使用自动增长(直到写满)。3. 先进的镜像架构保障容量和性能不会受损。4. XDP数据保护:RAID6保护数据。5. VAAI集成。
XIO核心设计思想:
1. 一切为了随机性能:任何节点访问任何数据块,不会增加额外成本。使得节点增加性能也会线性增长。
2. 尽量减少写放大:由于SSD的写放大,不仅导致寿命缩短,还会因擦除次数上升,导致质量下降,数据可靠性下降。XIO设计目的让实际写入数据量减少。
3. 不做全局垃圾回收:XIO使用的是SSD阵列,SSD内部有高性能企业级控制芯片,当前SSD主控非常强大,因此效率很高。不必全部做垃圾回收,节约了时间。
4. 按照内容存放数据:数据存放的地址由数据内容生成,跟逻辑地址无关。使得数据可以放在任何位置,提高随机性能。让数据随机放置在整个系统中。
5. True Active/Active 数据访问:LUN没有所有者一说,所有节点都可以为任何卷服务,因此不会因为一个节点出问题而影响性能。
6. 扩展性好:性能容量都可以线性扩展。
XIO软件运行在用户态的优势:
1. 避免内核态的进程切换。
2. 开发简单,不需要借助内核接口,以及复杂的内存管理。
3. 不必受到GPL约束。Linux是开源系统,程序运行在内核必然运用内核代码,按照GPL规定,必须开源,而在用户态就不必了。
工作流程:
XIO分为6个模块。三个数据模块R,C,D,三个控制模块P,M,L
1. P(Platform 平台模块):监控系统硬件,每个节点都一个P模块在运行。
2. M(Management 管理模块):实现系统配置,如创建卷,LUN等。
3. L(Cluster 集群模块):管理集群成员,每个节点运行一个L模块。
4. R(Routing 路由模块):将SCSI翻译成XIO内部命令。负责接管FC和SCSI命令,将读写数据大小拆成4k,通过SHA-1算法计算Hash值。每个节点运行一个R模块。
5. C(Control 控制模块):记录了映射表A2H(数据逻辑地址-Hash值),具备镜像去重扩容等功能。
6. D(Data 数据库):包含了另一个映射表H2P(Hash值-SSD物理存放地址)。可以看出了,数据的存放地址和逻辑无关,只跟数据有关。负责对SSD的读写,负责RAID技术。
读数据流程:
1. 主机将命令通过FC或iSCSI接口发送给R模块,包含了数据块逻辑地址和大小。
2. R模块将命令拆分成4KB大小,转给C模块。
3. C模块查询A2H表得到Hash值。转发给D模块。
4. D模块查询H2P表得到SSD的物理地址,读取。
不重复的写流程:
1. 主机将命令通过FC或iSCSI接口发送给R模块,包含了数据块逻辑地址和大小。
2. R模块将命令拆分成4KB大小,转给C模块。
3. C发现Hash值没有重复,插入表中,交给D。
4. D模块分配物理地址,写下去。
可去重的写流程:
1. 主机将命令通过FC或iSCSI接口发送给R模块,包含了数据块逻辑地址和大小。
2. R模块将命令拆分成4KB大小,转给C模块。
3. C模块查询A2H表,发现重复块,转给D模块。
4. D模块知道有重复数据,不写了,引用次数加一。
这种情况下,复制数据仅仅计数修改一下即可。
EXSi和VAAI:对于虚拟化产品中VMware Server按照在操作系统之上。ESXi则内嵌在操作系统。相当于虚拟平台,上面有多个虚拟机。
VAAI:是虚拟化的标准语言之一,其实就是EXSi发送命令的协议。
复制流程:如图2-32
1. EXSi虚拟主机用VAAI语言发送一个虚拟机(VM)复制的命令。
2. R模块通过iSCSI或FC收到命令,选择一个C模块进行复制。
3. C模块解析出命令内容,将VM地址0~6复制到7~D并把结果发送给D模块。
4. D模块查询Hash表,发现数据重复,没有写数据,仅仅引用+1.
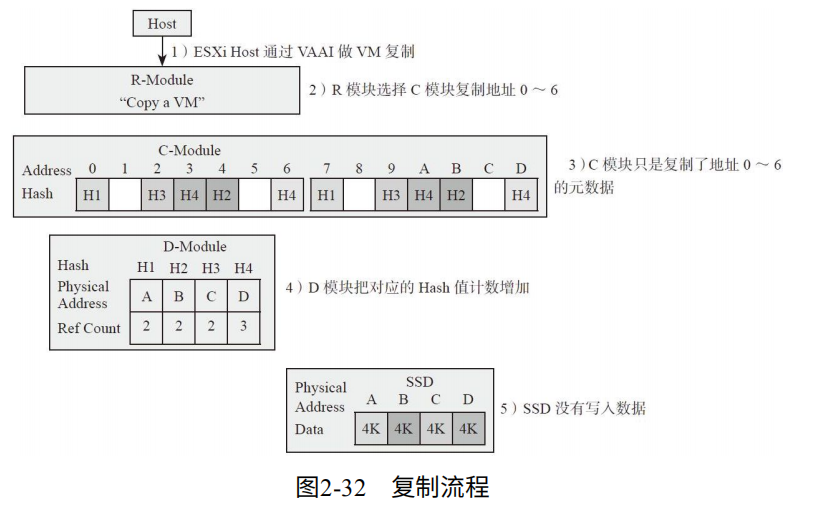
因此,R和上层打交道,C作为中间层,D与SSD打交道。对于R,C,D不在同一CPU下,模块间通过Infiniband来通信,数据使用RDMA,控制通过RPC实现。Infiniband使得X-Brick增加,延迟也不增加。因为Hash会随意落到C上,性能会线性改变。
应用场景:对于数据库来说性能高,复制不占用空间,可以创建多个副本。对于虚拟机来说很多数据也是重复的。
带有计算功能的固态硬盘:如带有FPGA的SSD-CFS。采用PCIe 3.0 * 8性能可达5GB/s。FPGA提供计算加速,数据从SSD出来就已经算好,释放了CPU。
对于人工智能来说,FPGA的人工智能硬件算法直接对SSD内部海量数据进行分析,并把结果发给主机。
第三章 SSD存储介质:闪存
闪存器件原理:一般采用NAND闪存。由于闪存写入之前必须擦除,不能覆盖写,所以需要垃圾回收。每个块写入次数有限,所以要做到磨损平衡。
但闪存是一种非易失性存储器。掉电不丢数据。闪存基本单元Cell是一种类NMOS的双层浮栅MOS管。如图3-1.
在源级和漏级直接形成存储电子的浮栅,上下被绝缘层包裹,因此不会丢失数据。
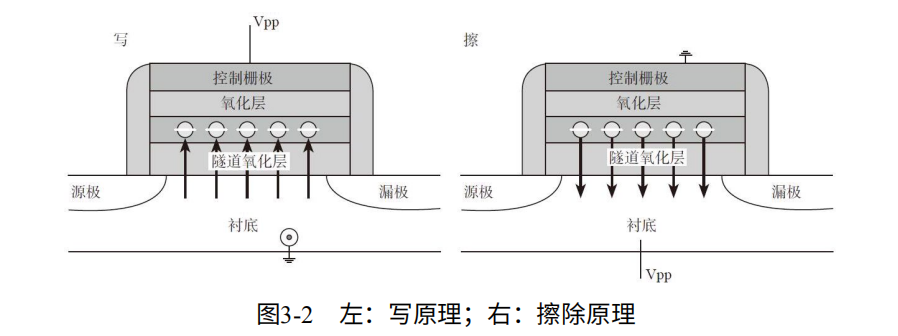
写操作在控制层加正电压,让电子进入浮栅极。擦除在底部加正电压,将电子吸出。如图3-2.

对于一个存储单元存储1bit数据的闪存称为SLC。2bit为MLC。3bit为TLC。甚至有研发存储4个为QLC。
对于存储状态,将内部含有电子数进行划分,如MLC来说,低于10个电子为0;11~20个为1;21~30为2;多于30为3。
因此bit越多,闪存容量越大。但电子划分越多,控制的越精细,耗时越长。读取时也要采用不同电压进行读取,因此性能TLC不如MLC,MLC不如SLC。
闪存芯片架构:将存储单元按照组织结构进行组成。
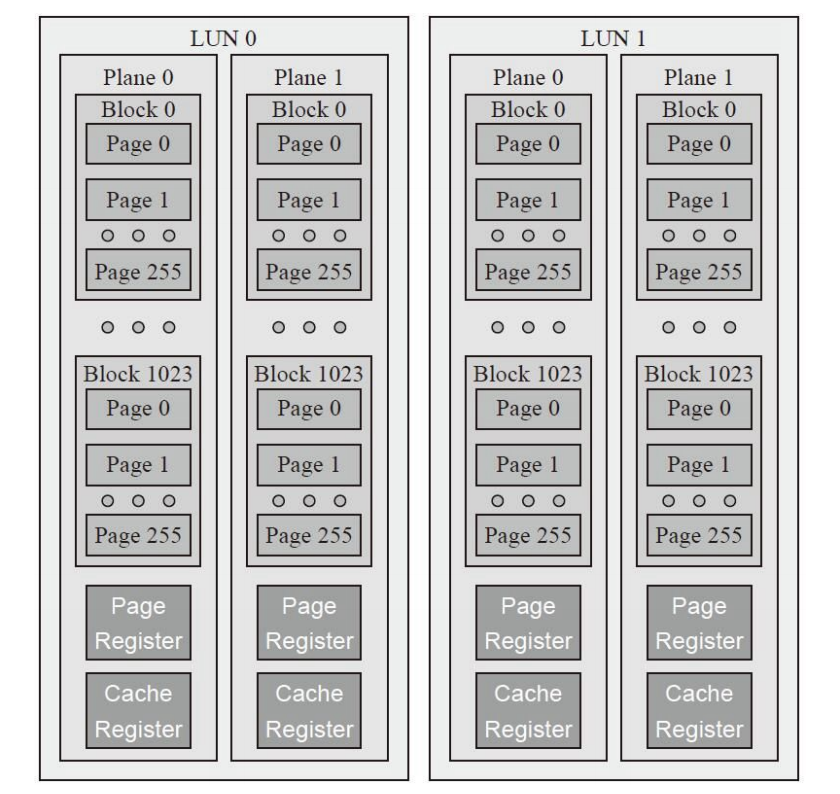
一个闪存有若干DIE(或叫LUN),每个DIE有若干Plane,每个Plane有若干Block,每个Block有若干Page,每个Page对应一个Wordline,Wordline有成千上万存储单元。
DIE/LUN是接收命令的基本单元。1个LUN有多个Plane,每个Plane有独立Cache Register和Page Register相当于一个Page大小,当读写数据时,将数据放到Cache Register。
Page Register则用于优化速度,使得读时,在传输前一个数据到主控时,可以从闪存获取下一个数据。
由于同一Block共用一个衬底,所以在擦除时,加一个强电压,同一Block的电子都被吸取。
读写擦原理:
1. 擦除:擦除前浮栅上可能有电子,Pwell加20V电压,由于量子隧道效应,电子从浮栅到达沟道。一个LUN上的MOS管公用一个Pwell,但其他不用擦除的Block的栅极电压是悬空,不会有隧道效应。
2. 写:写入时要写的单元Wordline为高电压,Bitline=0V则成为0,不写Bitline=2V成为1。
3. 读:不读的Wordline为5V,读的为0V,Bitline端可以进行检测。
三维闪存:随着二维尺寸减少,干扰增加。开始采用高堆叠栅极结构来提高集成密度。
三维通过堆叠增加密度,但导致串电流减小,高低层特征差异增大。
由于层数增加,Block的page数增加,Block的读取数增加,读取干扰严重。若要降低干扰,只能降低电压,减少电流,导致信号更弱。
单元模具厚度减小,尺寸不断减少,干扰越来越强。
Charge Trap(CT)闪存:对于浮栅晶体管中间采用导体。CT则采用绝缘体。区别在于存储电荷的元素不同。因此浮栅内电子可以移动,但CT内电子如同落入陷阱,很难移动。
由于浮栅对于下层绝缘层很敏感,若制程不断变薄或者老化,会导致进出容易。但CT即使老化,电子也不易出来。
浮栅材料为导体。任何两个导体中间有绝缘体都可能成为电容器,影响其他单元的电荷变化。随着厚度减小,距离减小,影响越来越大。
因此CT对隧道氧化层要求不那么苛刻。有更小的单元间距。隧道氧化层磨损更慢。更节能。工艺更容易,小尺寸更容易实现。
3D XPoint:最新DDR4内存,读写速度可达61GB/s和46GB/s。PCIe单通道理论1GB/s或0.5GB/s。一般仅仅4通道,即4GB/s或2GB/s。SATA理论只有600MB/s。机械硬盘读写215MB/s和140MB/s。
当前的器件多之又多:
1. 忆阻器:ReRAM
2. 铁电存储器:FeRAM
3. 磁阻RAM:MRAM
4. 相变存储器:PRAM,PCM
5. 导电桥接RAM:cbRAM,又称可编程金属元存储器PMC
6. SONOS RAM:Silicon-Oxide-Nitride-Oxide-Silicon
7. 导电金属氧化物存储器:CMOx
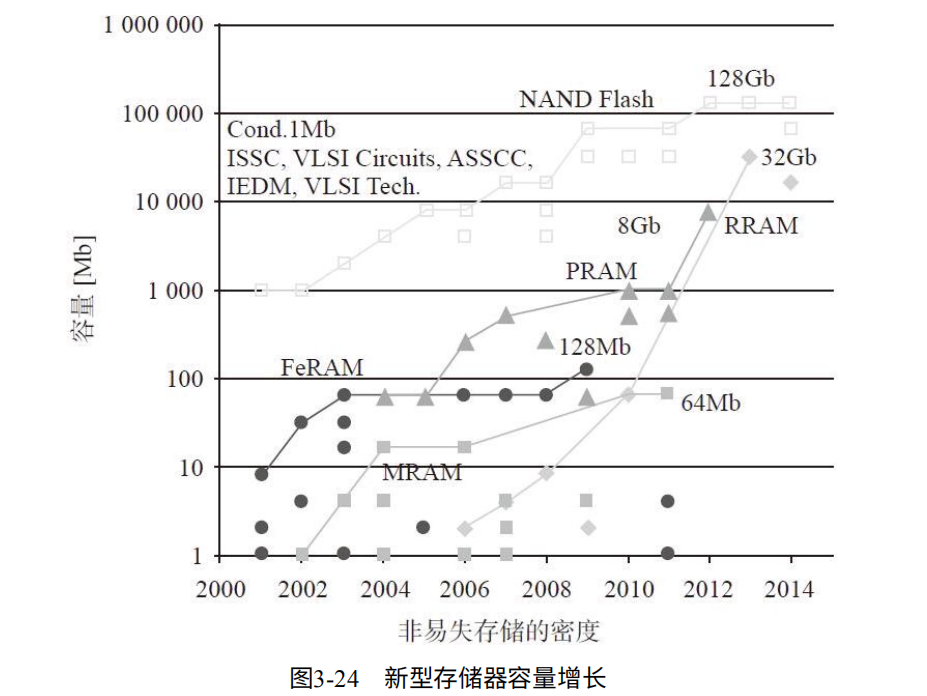
如图3-24, 目前比较成熟的是相变存储器PCM-PRAM。
想变存储器:原理则是如水从液体(不顶形态)变成固体(晶体),PCM通过微小的电阻让玻璃融化变为晶体,如GXT在不同形态下电阻差距较大,因而出现了0/1。
写的时候通过加热完成相变,读的时候通过测量Bitline的电压值判断电阻高低。
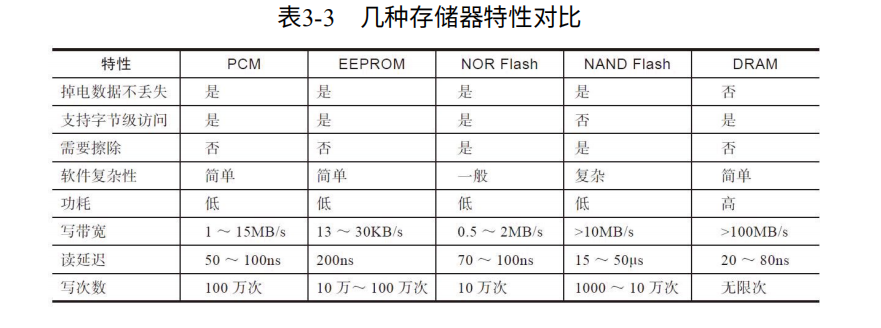
异步时序:对于闪存一般来说,异步传输速率慢,同步快。异步没有时钟,读数据通过RE_n触发,写通过WE_n触发。同步有一个时钟信号,数据读写和时钟同步。
CLE:CLE有效时,IOx发送命令。
CE_n:用来选通一个逻辑芯片(Target)。
WE_n:写使能,用户发给闪存,意味着发过来的写数据可以采样了
ALE:ALE有效时,IOx发送地址。
IOx:数据总线
时间参数如下:
twp:WE_n低电平的宽度。 twh:WE_n高电平的时间。twc:twp+twh的时间。tds:数据建立时间,8bit都达到稳定的时间。tdh:数据稳定的时间,可以用来采样。
如图3-32,可以看出数据写入时,数据不能传地址和命令,因此ALE和CLE都无效,CE有效,每个WE周期对应一次有效数据传输。
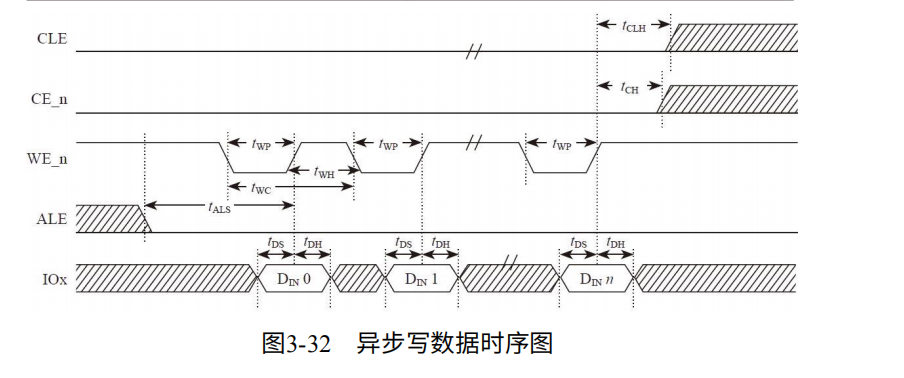
RE_n:读使能,用户发给闪存,意味着闪存准备好数据,等待用户采样。
RB/_n:Ready/Busy,闪存在内部读取Busy_n有效,数据准备好后可以来读Ready_n有效。
如图3-33,对于读取:用户发送读信号Ready拉高,意味着数据准备好了。发送RE_n每个RE_n周期,闪存发送数据到数据总线,供用户采样。
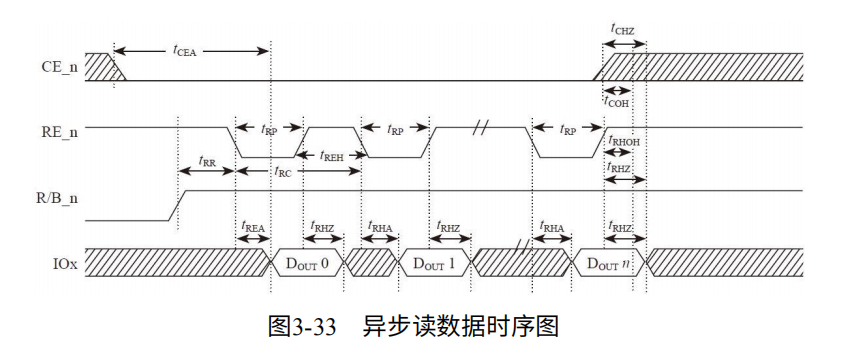
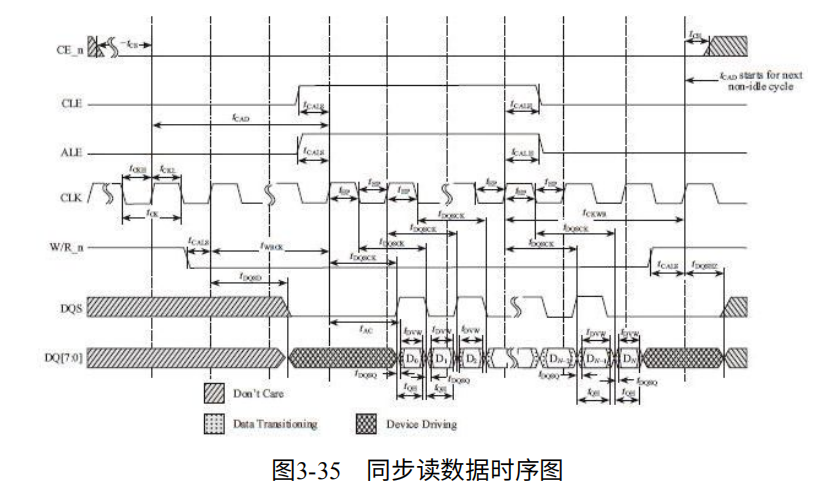
同步时序:闪存基本使用DDR(Double Data Rate)技术,每个时钟周期传两拨数据。
CLE:时钟,上升沿和下降沿有数据触发。意味着100MHz的时钟频率,速率为200MT/s。
W/R_n:写时高电平,读时低电平。
DQS:用于区分数据传输周期,便于接收数据。读数据时,DQS由闪存产生。写数据时,有用户产生。
DQ【7:0】:数据总线。
时间参数:tcals:CLE,W/R_n和ALE的建立时间。tdqss:数据输入到第一个DQS跳变沿的时间。
如图3-34,对于写入ALE和CLE有效后,第一个CLK上升沿,数据准备传输。经过tDQSS时间后,DQS开始跳变,位于DQ数据信号稳定位置后。每半个时钟周期,输出一组数据。
如图3-35,对于读取只不过W/R_n是低电平。
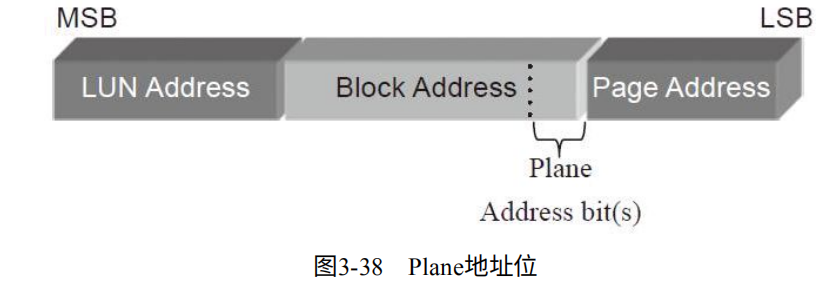
闪存寻址:一个Target作为独立工作芯片。包含多个LUN,每个LUN包含多个Plane,每个Plane包含多个Block。每个Block包含多个Page。
闪存采用行地址和列地址。列地址则是Page内部偏移。行地址为LUN,Block,Page地址。位宽与芯片容量有关。(Plane是在Block地址的最低位)
读写擦时序:读时序:00~30h时间,传输了地址如2个列地址,3个行地址。命令发送后状态转为Busy,一段时间后转为Ready,可以读取。
写时序:一般列地址为0,因为要把一个Page写满。发送地址后发送数据。
擦时序:在命令60h~D0h之间,发送LUN和Block即可。
闪存特性:
1. 闪存坏块:闪存具有一定寿命,接近或超过最大擦除次数,会导致永久性损伤。
闪存中的存储单元先天有一些就是坏的,随着使用越来越多。必须ECC纠错码进行保护。
2. 读干扰:当读取闪存页Page时,未选择的页需要加正电压,使得未选中的MOS管是导通的。因此频繁的加正电压,可能导致电子吸入浮栅,形成轻微写。因此读干扰会影响同一闪存块其他闪存页。
3. 写干扰:写干扰也会导致比特翻转。对于初始存储单元都为1,只需要写0的单元。因此闪存页加正电压后,即使不需要写的也会被迫加上。
4. 存储单元间的耦合:如之前提到的 电荷是导体,中间绝缘体,因此存在耦合电容。
5. 电荷泄漏:长期不使用存在电荷泄漏,导致非永久性损伤。
寿命:对于写入后电压值高,Biline不导通读取0。未写入电压低,Bitline能获得电流读取1。一定要让两个峰值有足够距离。随着擦写会导致三种故障:
1. 擦过的晶体管电压变大,从-Vt向0靠近,导致电流变小,检测不出
2. 写过的晶体管电压变小,从+Vt向0靠近,可能误检测为擦除
3. 写过的电压变大,可能其他单元读取时,把整个Bitline关闭。
浮栅晶体管氧化层变薄,对浮栅极内部电荷也有影响。
一般解决办法:
1. Wear Leveling:磨损平衡,让闪存块均衡擦写。
2. 降低写放大:写放大越低,磨损速度越慢。
3. 用更好的纠错算法:纠错能力越强,允许出错率越高。
MLC:擦除闪存块约几毫秒。读写以闪存页为单位。包含4KB,8KB,16KB等。对于MLC和TLC,Page应该顺序写入:一个存储单元有两个闪存页数据,相邻单元存在耦合,因此写后面需要保证前面写完。
对于一个单元有2bit数据。必须先写Lower在写Upper,若写入Upper时掉电,会导致Lower数据也丢失。同时对于写Lower时间短,Upper时间长。
对于常识规定,若已经写入的数据,应该就是安全放心的。但对于MLC,若写入Lower后,再写入Upper出现故障,也可能导致之前写入Lower的数据损坏。
因此方式:1. 只写Lower,适合土豪。2. 定期填充Upper,若发现Lower写入,将Upper也写入。3. 写Lower时,将数据备份到其他闪存,当Upper写入后,再将备份删除。
4. MLC当做SLC使用,随后将SLC数据以垃圾回收方式搬到MLC。
读干扰:读干扰会让浮栅极进入电子,使电压出现偏移。影响读取,存在误判。主要原因在于闪存块上读取次数以及闪存块擦除次数。
可以在读取次数达到阈值前,数据刷新一遍(读取,擦除并写回)。
闪存数据保存期:数据不可能永久保存,闪存中数据期限为Data Retention。超过期限数据出错,标志为无法使用ECC纠错成功。主要原因:
1. 焊接问题:虚焊或芯片故障,导致命令无法执行。
2. 读写擦失败:基本命令执行失败。
3. ECC纠错失败:错误率太高,超过了纠错能力。Data Retention作为元凶。(原因则是电压导入的电子,泄漏)
闪存数据完整性:闪存随着使用以及存储时间变长,容易发生比特翻转,出现随机性错误。随着制程变小越发严重。
常用技术:1. ECC纠错 2. RAID数据恢复 3. 重读 4. 扫描重写技术 5. 数据随机化
读错误来源:1. 擦写次数增多:氧化层老化,电子进出容易,电荷发生异常。
2. Data Retention :电子丢失,电压偏移发生误判。
3. 读干扰:读一个wordline时,对其他闪存页出现轻微写。
4. 存储单元之间干扰:浮栅极是导体,中间绝缘体,形成电容。
5. 写错误:写Upper时导致Lower错误。
重读:对于电压平移,因为只是平移,间隔还在,可以不断改变参考电压。甚至可以读取附近确定状态的电压,再来判断。
ECC纠错码:固态硬盘控制器有ECC纠删模块,部分闪存内部也集成了纠错模块。常用算法有BCH、LDPC等。用户数据都写在闪存页(page)上,内部有预留空间由于ECC纠错。
静态ECC纠错:即ECC模块空间不变,纠错能力也是不变的。但随着闪存的使用,出错概率逐渐变大。但预留空间也是不变的(OP,Over Provisioning)
动态ECC纠错:ECC模块空间越来越大,纠错能力越来越强。甚至不同Die不同Page都有不同纠错能力,对MLC来说,Lower比Upper更稳定一些,可以使用弱一些的ECC保护。
RAID:RAID内部就是闪存阵列,因此可以借鉴磁盘阵列。如RAID5,将多个Die进行异或做校验值,这样有一个出错,仍可以进行恢复数据。
但固态硬盘架构不同磁盘阵列,很难实现。对于条带来说,不能覆盖写,每次写入都写到新地方。如果条带上某个Die被垃圾回收,整个条带都需要重写。同时为了写满一个条带,更是增加了写放大。
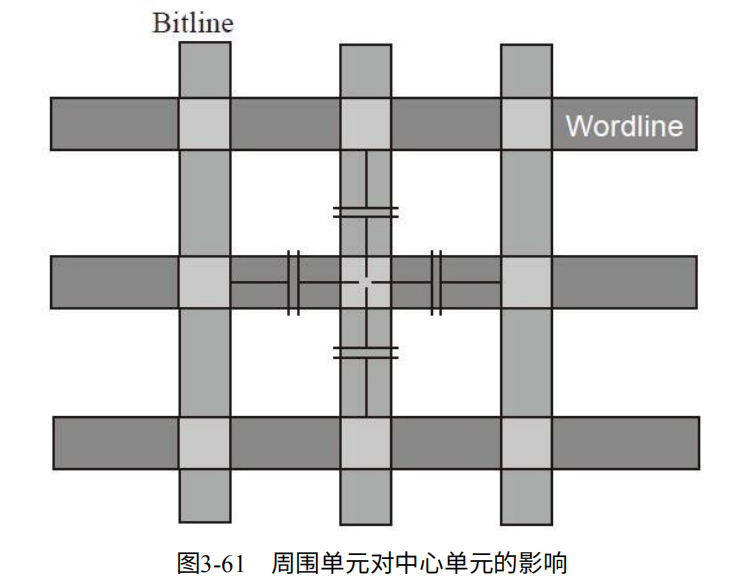
数据随机化:对于不断输入全0或全1很容易导致电量不均衡,造成抗干扰能力下降,数据可靠性变差。如图3-61可以看出每个单元都受到周围4个直接相邻的单元影响。
因此部分厂商采用加入干扰码(对数据随机化),让写入闪存的0和1尽量均衡。一般使用AES加密。如图3-62,在数据进入闪存前进行加密。

第四章 SSD核心技术 FTL
FTL算法的好坏,直接决定了SSD在性能,可靠性,耐用性等方面的好坏。
FTL完成了用户逻辑空间,到闪存物理空间的翻译 、映射。除此之外,SSD中的FTL还有很多事情。SSD使用的存储介质一般为NAND Flash闪存(除此还有RAM,3D XPoint)
闪存的特性:
1. 擦除才能写入,不能覆盖写。因此写入新数据时不能直接更改需要更改位置。FW需要维护一张逻辑地址到物理地址的映射表。当往新地址写数据后,旧地址数据变为垃圾数据。FTL会进行垃圾回收。
2. 闪存块都是寿命的。采用PE数衡量每个闪存块擦除所造成的磨损。因此不能集中向几个闪存块写数据。FTL需要做Wear Leveling让数据均摊到每个闪存块。
3. 闪存块读取次数有限,读太多数据便会出错,造成读干扰。当某个闪存块读取次数到达一定阈值,FTL需要将数据从闪存块上搬走。
4. 闪存的数据保持问题。由于电荷的丢失,闪存的数据会发送丢失。SSD若连接电源后,FTL会扫描闪存,发现是否有数据保持问题,如果有则需要搬动数据。
5. 闪存天生的坏块。坏块管理是FTL的任务。
6. MLC或TCL中Lower问题。对于Upper写入会导致Lower失效。FTL需要擦去策略。
7. MLC或TLC读写速度不如SLC,但可以配合成SLC来使用。 FTL会利用该特性改善性能。
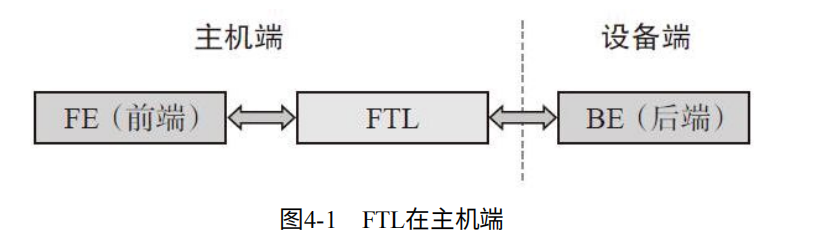
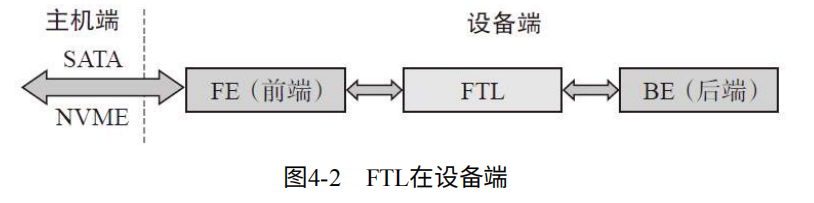
FTL分为Host Based(基于主机)和Device Based(基于设备)
Host Based:说明使用主机的CPU和内存资源。如图4-1.
Device Based:说明在设备端实现。 如图4-2.
映射管理:根据力度不同,存在基于块的映射,也有基于页的映射,还有混合映射。
由于块比较大,映射表空间小,但写入少量数据也会读取整个物理块,修改页的数据,再写入整个物理块。用户空间划分成Region,Region大小和块大小相同。
页为映射粒度,每个页都有对应映射关系,因此需要更多空间存储映射表,但性能更好。
混合映射,对于一个逻辑块映射到一个物理块,在块内,每个页不是固定的,采用映射的方式。
映射原理:用户通过LBA访问SSD。每个LBA代表一个逻辑块(512B/4KB/8KB),将用户访问SSD的基本单位称为逻辑页。SSD内部以闪存页为基本单元,读写闪存,称为物理页。
用户每写一个数据页,SSD就会找到一个物理页将数据写入。记录了映射。
由于闪存页和逻辑页大小不同,一般前者大,所以一般多个逻辑页写到一个物理页。逻辑页和子物理页一一对应。
对于256GB的SSD,4KB大小的逻辑页为例。用户共有64M个逻辑页,若映射关系为4B,约256MB。因此,一般来说映射表是SSD容量的千分之一。
SSD中的DRAM则用来存储这张表。部分不带DRAM的,采用二级映射。一级映射表常驻SRAM,二级映射小部分在SRAM,大部分在闪存。
HMB:映射表除了放在DRAM,SRAM,内存外,还可以放在主机内存。
SSD一种带有DRAM用于存放映射和缓存数据,另一种不带DRAM,缓存数据用主控的SRAM,映射表采用二级映射,占用部分SRAM。NVMe则允许使用主机的DRAM。
映射表的刷新:在SSD掉电前,需要将其写入到闪存,下次上电初始化时再将其加载。为了防止异常掉电导致映射丢失,采用一定策略,在运行时就将映射写入。
写入触发:1. 新产生映射累积一定的阈值。2. 用户写入数据量到达一定阈值。3. 闪存写完闪存块的数量达到一定阈值。 4. 其他。
写入策略:全量更新,增量更新。
垃圾回收:作为FTL重要任务。
模拟场景:SSD底层有4个通道(CH0~CH3),连接4个Die(每个通道Die可并行),每个Die有6个块,每个块有9个小方块(大小等于逻辑页)24个块中20个为SSD容量4个为预留空间。
顺序写到4个逻辑页,分别写到不同通道,增加并行性。数据将不断交错写入,直到SSD写满。如图4-16

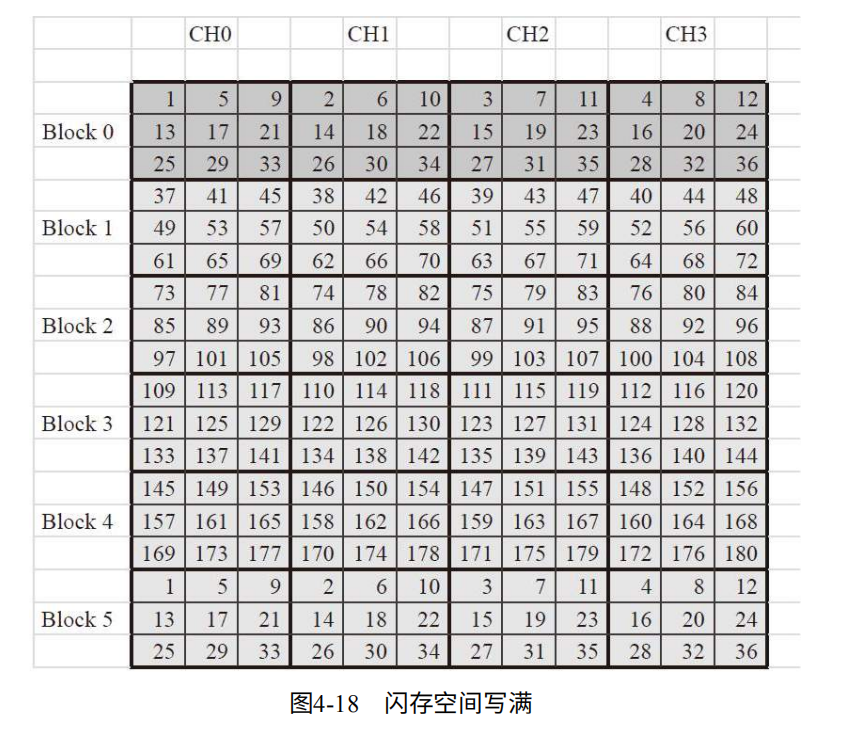
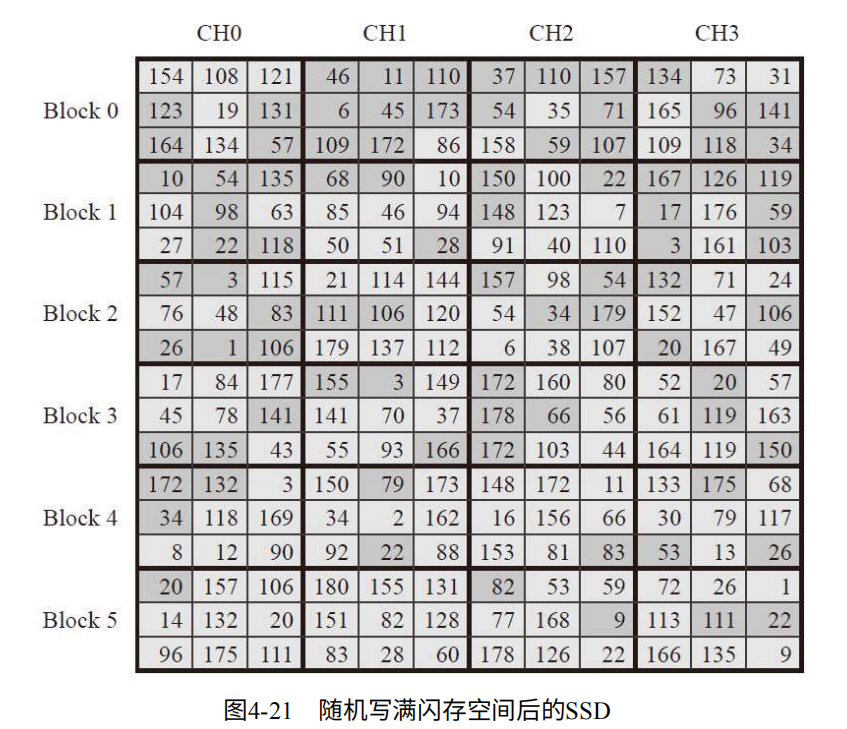
盘虽然从用户看来写满,但由于OP的存在,并未写满。这时继续写入必须删除之前的内容。但由于不能直接覆盖,因此需要先写到其他位置(即OP)深色代表无效数据,当OP也写满,如图4-18.则触发GC(实际中在满之前就会触发)将深色数据垃圾回收,进行擦除。
但现实中,数据通常随机写入,如图4-21,每个块中都有部分垃圾,部分数据。因此通常采用选择先将垃圾多的块进行回收。多出的空闲块,用户就可以继续写入数据了
写放大(WA, Write Amplification):由于GC原因,为了腾出空间,需要额外数据的搬移。 写放大 = 写入闪存的数据量 / 用户写入的数据量。
对于空盘写放大一般为1.但如果存在压缩,写放大可能小于1.
写放大越大,意味着写入多,影响寿命。同时占用底层带宽,影响性能。因此尽量让WA小,可以采用压缩方方法(主控决定),顺序写,增加OP。
影响写放大因素:
1. OP:OP越大,WA越小。
2. 用户写入Pattern:顺序写入GC就小。
3. GC策略:挑选有效数据最少,垃圾数据最多的。控制GC产生空闲块的数量。
4. 磨损平衡:为了平衡闪存擦除次数,需要进行数据迁移。
5. 读干扰和数据保存处理:将数据搬移增加写放大。
6. 主控:带有压缩与否
7. Trim:有没有Trim。
垃圾回收实现: 1. 挑选源闪存块。 2. 找出有效数据。 3. 将有效数据写入目标闪存块。
为了有利于挑选源闪存块,需要维护闪存块中有效数据量。甚至有的把闪存的擦写次数也考虑进去(暗藏,磨损平衡)
找出有效数据时,若将Block全部读取,浪费资源。因此可以在维护有效数据量的同时,用bitmap记录有效数据,标识物理页。当覆盖写时,不仅把当前bitmap置1,还需要把之前的清0
若没有bitmap可以选择将其全部读取。但如何分辨呢?由于SSD写入数据时,同时写入了元数据(逻辑地址,数据长度,时间戳等),因此根据物理地址与逻辑地址映射,判断是否和映射表一致可以判断是否有效。
垃圾回收机制:可用内存块小于阈值,SSD空闲,主机控制SSD进行垃圾回收。
Saber 1000HMS作为企业级SATA接口,具有主机控制SSD功能(Host Managed SSD)。使得在SSD空闲时,进行垃圾回收,提升了系统的稳定性。
Trim:对于用户删除文件,只是断开了用用户与操作系统的联系,但在SSD内部,逻辑页与物理地址映射还存在,认为数据有效。只有当操作系统在相同地方写下数据时,才知道数据被删除了。
Trim作为ATA命令,当用户删除文件,操作系统会发送Trim给SSD。之后SSD就可以删除数据,不必当做有效数据进行迁移等。
在SCSI中叫UNMAP,NVMe中叫Deallocate。
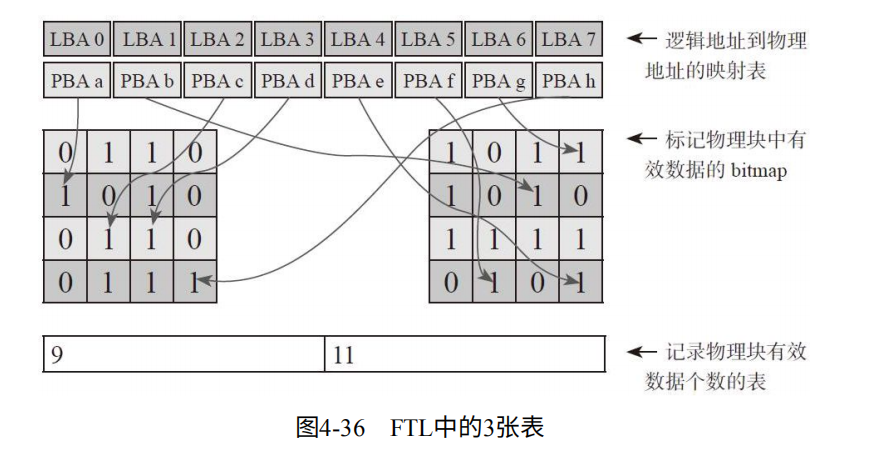

FTL一般存储这三张表,FTL映射表L2P记录LBA对应物理页位置。VPBM记录每个物理块上哪个物理页有效。VPC记录物理块上有效页的个数(垃圾回收时,排序找到数量最少的)。如图4-36.
Trim工作:如图4-37
1. 清除L2P table映射到空地址
2. 清除VPBM上对应的bit
3. 更新VPC的Count数
4. 重复1~3对每个LBA
5. 根据新的VPC重新计算GC优先级
6. 回收最少VPC的block
7. 擦除全是垃圾的block
磨损平衡:让每个块擦除保持均衡。SLC拥有十万次,MLC几千次,TLC一两千甚至几百次。
冷数据:不经常更新,基本只读。热数据:用户频繁更新,产生大量垃圾数据。年老的块:擦除次数比较多。年轻的块:擦除次数比较少。
动态磨损平衡:将热数据写到年轻的块上。静态磨损平衡:将冷数据搬到年老的块上。
固件做静态磨损平衡采用GC来做,但是选的不是有效数据少得,而是冷数据所在的闪存块。
若冷数据(SWL)和热数据(Host)甚至GC数据(热数据)混合在一个Block内,会使热数据无效后,冷数据也需要做GC,增加了写放大。因此可以采用冷热数据分离的方式。
掉电恢复:对于正常掉电,主机会通知SSD,比如SATA中:将buffer缓存的用户数据刷入闪存。将映射表刷入闪存。将闪存块信息写入闪存。写入SSD其他信息。处理完才会停电。
对于异常掉电,主机根本不会通知。简单方法则是加电容,在掉电后,电容放电。或将内部RAM替换成掉电不丢失数据的东西,如3DX Point。
掉电会导致RAM映射表丢失,如果没有映射表,就无法读出物理地址。但可以进行重建。由于数据写入时,顺带了元数据(LBA,时间戳,其他内容)因此可以全盘扫描,就能获得所有映射关系。
对于全盘扫描可能花上几分钟甚至几十分钟。因此可以采用CheckPoint,定期将SSD中RAM的数据和SSD相关状态写入闪存。这样只需要找到最后快照,并恢复后面部分映射即可。
坏块:包括:出厂坏块(从工厂出来就坏了),增长坏块(随着闪存的使用,好块也变成了坏块)。
坏块鉴别:对于坏块会将其第一个闪存页和最后一个闪存页的第一个字节和Spare区第一个字节上写非0xFF的值。
用户使用时,会先扫描所有块,建立坏块表。甚至存储到特定区域,方便查询。
坏块管理策略:第一是略过Skip策略。第二是替换Replace策略。
对于略过策略,会直接写到下一个块上。对于替换策略则将好的块进行替换(如 预留空间OP)。对于替换策略,需要维护一张重映射表。
对于略过策略可能导致并行度低于4,对于替换策略并行度不变,但如果某个Die比较差,整个SSD受限于那个坏的Die。
SLC Cache:由于SLC有更好的寿命,以及速度优势。因此有些SSD用他来做Cache。
SLC Cache的优势在于:1. 性能好 2. 防止Lower数据被损坏 3. 解决闪存缺陷,如MLC、TLC没写满就读可能读到ECC错误。 4. 更多数据写入量。
写入策略:1. 强制写入,必须先写入SLC闪存块再到MLC、TLC闪存。 2. 非强制:如果有SLC闪存,则写SLC。否则可以直接写MLC、TLC。
写SLC Cache的优势在于,MLC、TLC没写时满发生Lower出错,可以通过SLC恢复,只有无误后再清楚SLC。
SLC的选择:1. 拿出一些Block专门做SLC Cache。2. 所有MLC和TLC都可以作为SLC。3. 两者混合。
RD和DR:RD是Read Distub,DR是 Data Retention。两者都能导致数据丢失。
RD:对于读闪存页时,需要对其他Wordline也加入高电压,出现轻微写(1 -> 0)。由于是积累的效果,可以定期重新写入。
DR:对于长时间,电子会穿过绝缘层,导致比特翻转(0 -> 1)。
Device Based FTL:将FTL放入SSD主控。 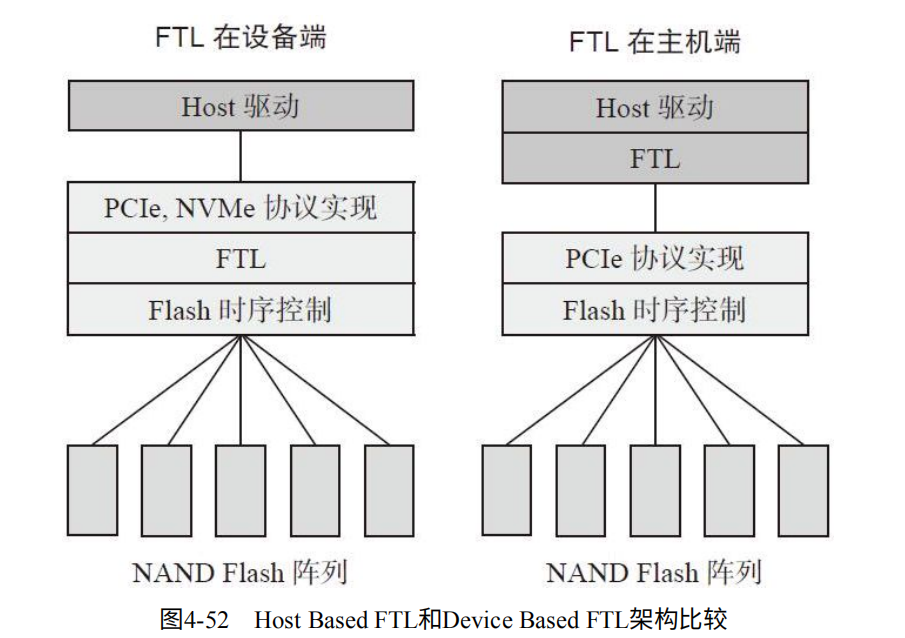
在SATA,NVMe等协议的普及下,越来越标准化了。
缺点:FTL架构通用,不能具体做出定制化。控制芯片功能复杂,设计难度大,研发成本高。闪存更新快,需要控制芯片修改,成本高。企业级需要大容量,高性能,通用芯片支持有限。企业市场需要多种多样。

Host Based FTL:将FTL放入主机驱动。
控制器大部分仅需FPGA,实现ECC纠错和时序控制即可。
百度的软件定义闪存:推出的SDP特点:
1. 没有垃圾回收:使用大小为块的整数倍,比如8MB。不需要垃圾回收,也不需要预留空间,没有内部数据搬移的写操作。
2. 没有闪存级的RAID:互联网公司一般有3个备份,不需要SSD的RAID了。
3. FPGA作为控制芯片:功能少:ECC,坏块管理,地址转换,动态磨损。实现了PCIe接口和DMA。
4. 每个通道向用户开放:可以选择写入哪个通道。
5. 软件接口层定义简单:省略了文件系统,块设备,IO调度,SATA协议等。直接发送同步命令到PCIe驱动。如图4-57.
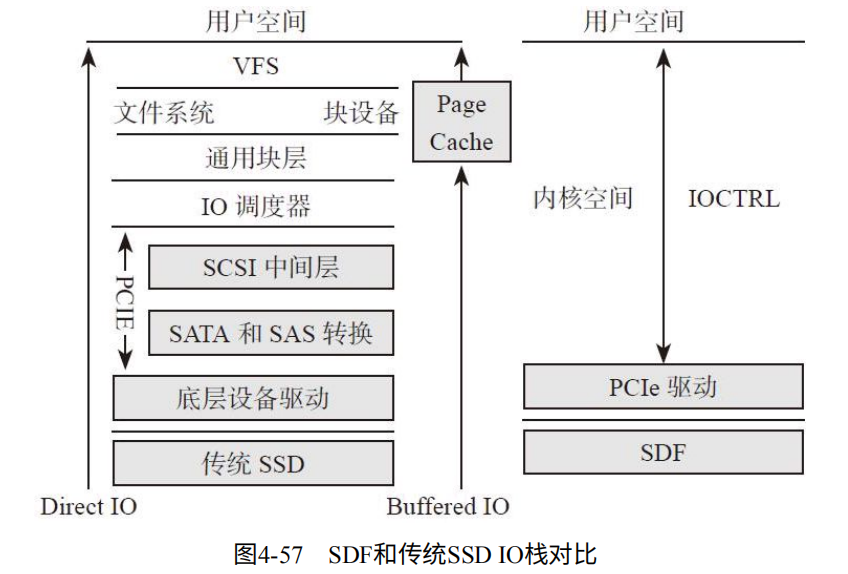
百度的软件定义闪存,针对了自己的特性,保留了关键功能,节约了资源。
第5章 PCIe介绍
PCIe的速度:从PCIe版本1.0到3.0。速度从0.5,1,2GB/s,通道也存在1~32不等。因此若是3.0配上32通道速度可达64GB/s。
对于两个设备之间的PCIe连接,叫做Link。具有全双工特性(即拥有独立的发送接收通道,并可以同时传输),如图5-2.
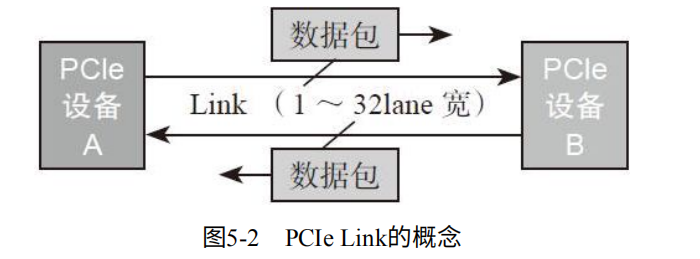
SATA虽然也有两个通道,但只能同时一个工作,因此为半双工。
因此测出的速度是读写速度之和,若单值读或者写,速度应该减半。
计算方式:对于PCIe 1.0,比特传输速率为2.5Gbps,物理层采用8/10编码(8bit数据传输10bit,多2位用于校验)。带宽=(2.5Gbps * 2(双通道 ) ) /10 = 0.5GB/s。多个Lane再乘Lane个数
PCIe由PCI发展,express为快的含义。PCI采用的并行传输,PCIe采用的串行传输。
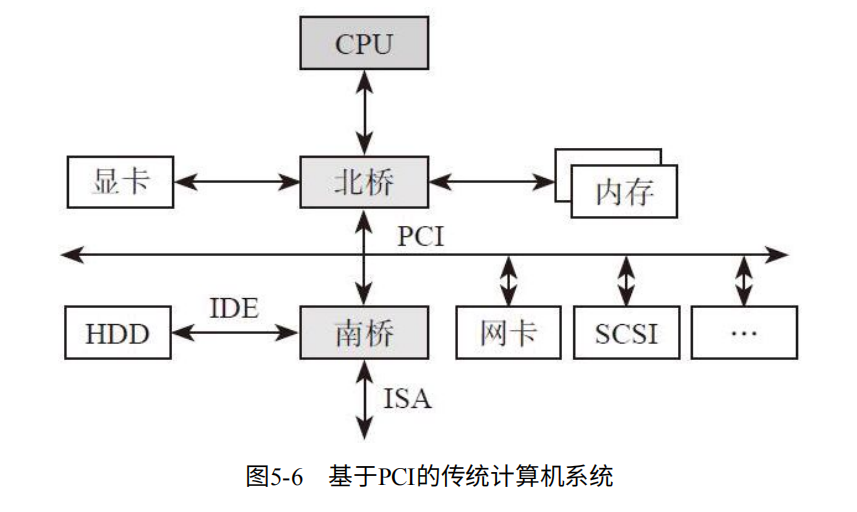
计算机的拓扑结构分为总线拓扑、环形拓扑、树形拓扑、星型拓扑、网状拓扑。
PCI采用的是总线拓扑,一条PCI总线挂在多个PCI设备,只有拥有总线使用权,才能发言。如图5-6.(北桥下的PCI总线,挂载了以太网设备、SCSI设备、南桥等。)

PCIe采用的树形拓扑,Root Complex(RX)作为根,代替CPU与内存以及PCIe系统中的设备通信。如图5-8。而Swtich用于扩展链路,提供更多端口(Endpoint)来连接。
虽然PCIe采用点对点通信,但不同设备的数据格式可能不同,实际很少这么做。
PCIe定义了三层:数据从上到下都以包(Packet)的形式传输。如图5-12
1. 事务层:创建(发送)或解析(接收)TLP(Transaction Layer Packet)、流量控制、Qos、事务排序等。、
2. 数据链路层:创建(发送)或解析(接收)DLLP(Data Link Layer Packet)、Ack/Nak协议(数据链路层检错和纠错)、流控、电源管理等。
3. 物理层处理Packet数据物理传输,发送端数据分发到各个Lane传输(Stripe)。
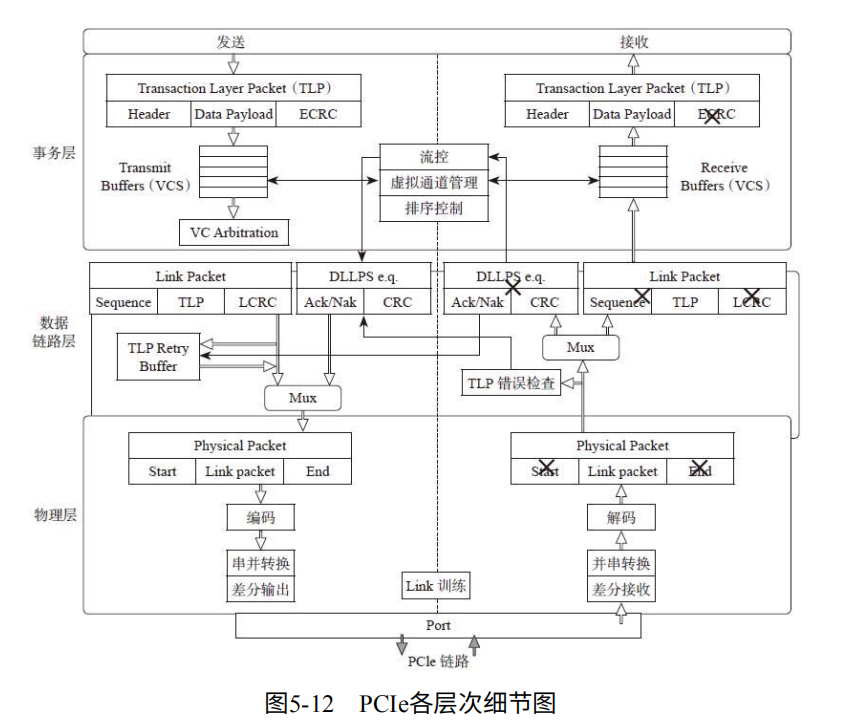
Data作为上层命令(命令层、NVMe层),为其加上Header以及CRC校验,形成了TLP。数据链路层加上包序列号,以及CRC校验。最后物理层加上Start和End标号,在Lane上加入干扰码,经过8/10编码或128/130编码,最后通过介质发送到接收方。
因此PCIe相对PCI更有生命,每个EndPoint都需要实现这三层。如果把数据接收和发送(掐头去尾,检验CRC等工作)称为脱衣和穿衣,那么RC和Swtich都需要做这种操作,传输过程可能有多次操作。
PCIe TLP类型:
1. Memory:内存访问。物理设备可通过内存映射方式映射到主机内存,甚至存在映射到IO空间。但新PCIe设备只支持内存映射。IO映射将逐渐取消。(TLP常见)
2. IO:IO空间
3. Configuration:配置空间。都是主机(RC)发起的,往往只是上电枚举和配置阶段。(很重要,但不是常态)
4. Message:中断信息、错误信息等。(非主流的)
对于请求需要相应,称为Non-Posted TLP。不需要响应,称为Posted TLP。只有Memory Write(ACK/NAK很大程度保障了正确)和Message是Posted。
对于拓扑结构中,除了EndPoint还有Switch,作为PCIe设备,但是配置种类不同,因此Configuration 分为Type 0/1.
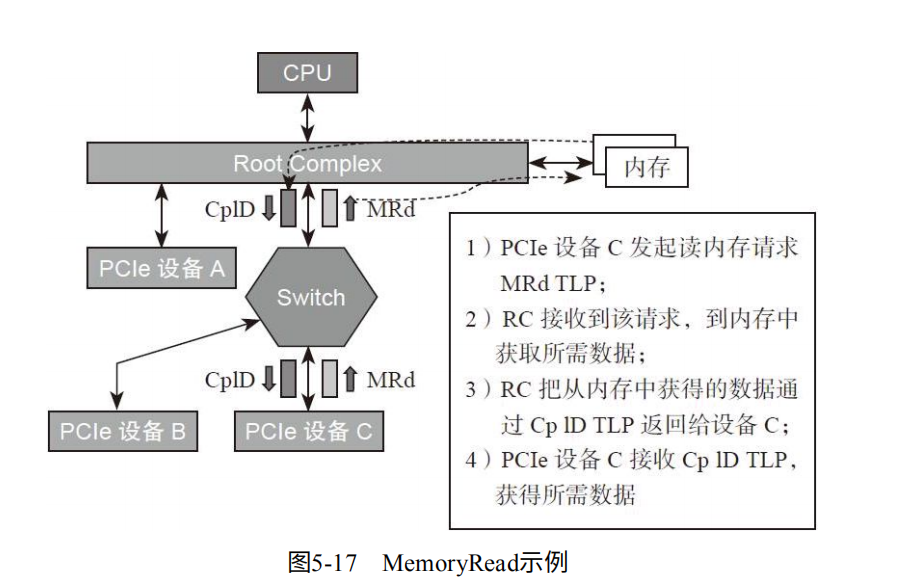

如图 5-17。对于PCIe设备C 发起Memory Read。 回到RC进行请求,RC将内存数据发送给设备C。
如图5-18。对于设备B发起Memory Write。数据到达内存后即可,不需要返回。(对于TLP只能携带4KB数据,无论是读返回,还是写入,如果超过必须分割。)
PCIe TLP结构:包括Header(必须有:包含目标地址、TLP类型、数据长度)、Data(可选,如读取数据时就没有要发送的数据)、ECRC(可选,根据Header和Data生成)。
Header(4DW):1. Fmt(Format,TLP是否有数据,Header是3DW还是4DW)2. Type(TLP类型)3. R(Reserved等于0)4. TC(优先级,数字大优先级高)5. Atrr(属性)
6. TD(是否包含ECRC),7. EP(有毒数据)8. (AT 地址种类)9. Length (数据长度)。如图5-20

对于PCIe设备,主机想要访问,必须映射到内存空间。Header地址为主机内存的映射地址。内存小于4GB用3DW,大于4GB用4DW。对于PCIe设备拥有唯一ID(总线(Bus)、设备、功能)缺点
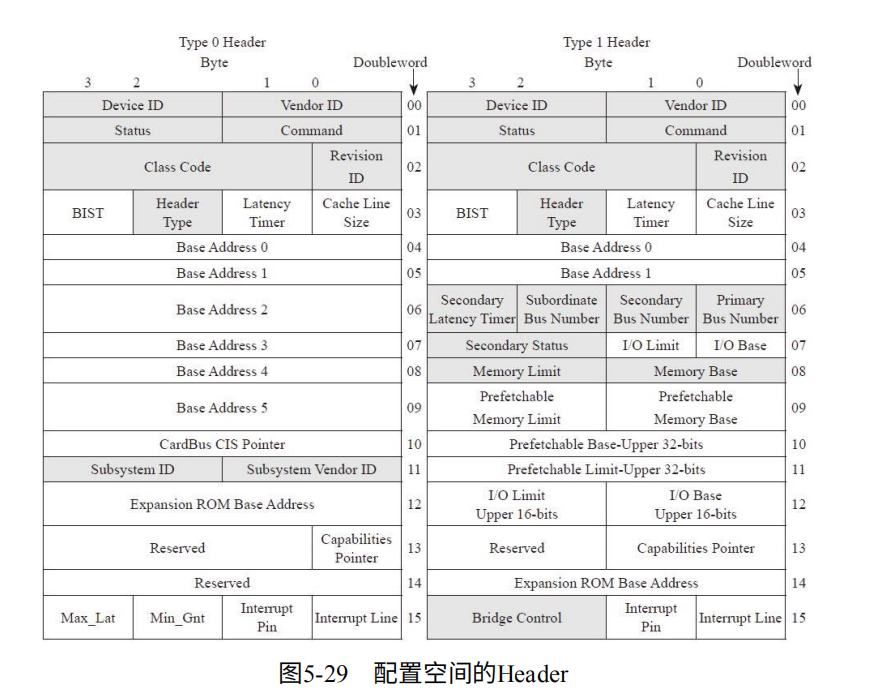
PCIe配置和地址空间:每个PCIe设备都有一段空间,主机通过它获得设备的信息。(对于PCI或PCI-X时代就有配置空间:64B的Header和192B的Capability)
进入PCIe时代,192B不足够使用,因此将配置空间从256B扩展到4KB,前256B保持不变。
由于CPU只能直接访问内存空间(或IO空间),不能直接操作外设。因此需要RC将内存想要访问的外设数据,通过TLP读到内存。
在机器上电时,系统会把PCIe设备开放的空间映射到内存空间,当CPU想要访问时,只需要访问对应的内存空间。RC若检测该空间为PCIe设备空间的映射,则触发TLP。
如图5-29,则是Header。Device ID等记录了设备信息。Base Address(BAR)用于分配映射空间。
而空间的大小属性都写在Configuration BAR上。通过读取BAR,为其分配系统的内存空间和地址空间。(BAR前部分用于存储内存地址,后部分为设备空间和属性)
对于每个PCIe设备可能对用多个配置空间(他可能具有多个功能,如硬盘,网卡等)如图,一条总线可以有多个设备,每个设备有多个功能。
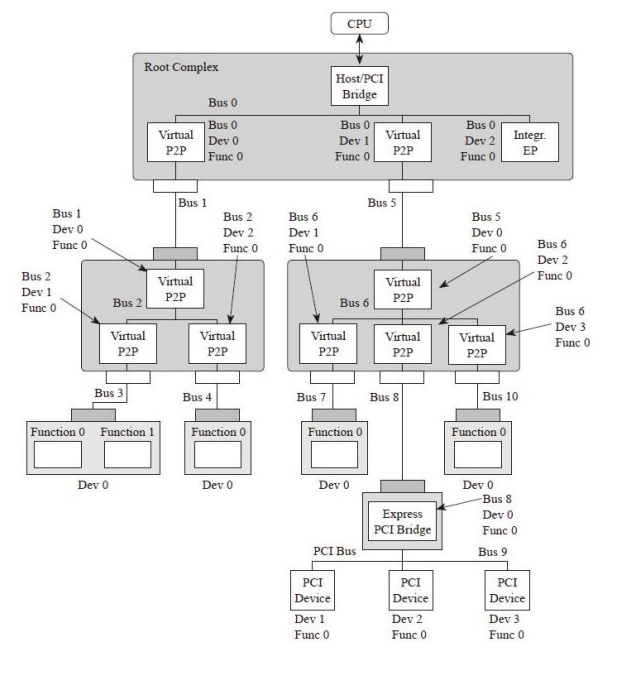
因此,在PCIe系统,根据 Bus+Device+Function可以找到唯一的Function
TLP的路由:基于地址(Memory address),基于设备ID(Bus+Device+Function),隐式。如表5-6.
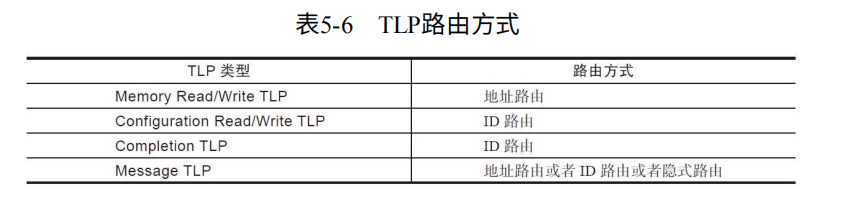
1. 地址路由:Switch负责转发路由,路由信息存储在Configuration。
BAR0和 BAR1与EndPoint一样,对于上游端口(RC)和下游端口,每个作为Bridge,有一个Configuration,描述了下面设备空间映射的范围。对于上游端口则是下游所有映射空间范围。
因此收到TLP时,首先判断是否是自己的,再判断是否是下游设备地址范围,若地址落到这些BAR中,则完成路由转发,并向下传递。否则不接受TLP。
对于向上传递时,先判断收到的是否是自己的,其次判断是否为下游其他设备,最后只能扔给上游。
2. ID路由:ID=bus+device+function。其中Configuration等则是根据这种方式。对于EndPoint收到这样TLP,会用其和自己ID进行比较,如果是则收下TLP。
对于Switch会记录上游Bus(Pri),下游Bus(Sec),下游中最大的Bus(Sub)。对于请求先判断是否为自己的,不是则判断是否在Sec~Bus之间,是的话说明在其之间。
3. 隐式路由:对于部分Message与RC通信,不需要声明ID等。
数据链路层:发送端:接收上层传来的TLP,为其加上Seq(序列号),LCRC。然后转给物理层。
接收端:接收物理层传来的TLP,检测CRC和序列号,若有问题则拒绝接收该TLP,并通知重传。如果没问题则去掉序列号和LCRC,并交给事务层,并通知发送端正确接收。
因此,数据链路层保障了正确传输,使用了握手协议(ACK/NAK)和重传(Retry),除此之外还包括TLP的流量控制,电源管理等,需要借助DLLP,处于事务层是感知不到的。
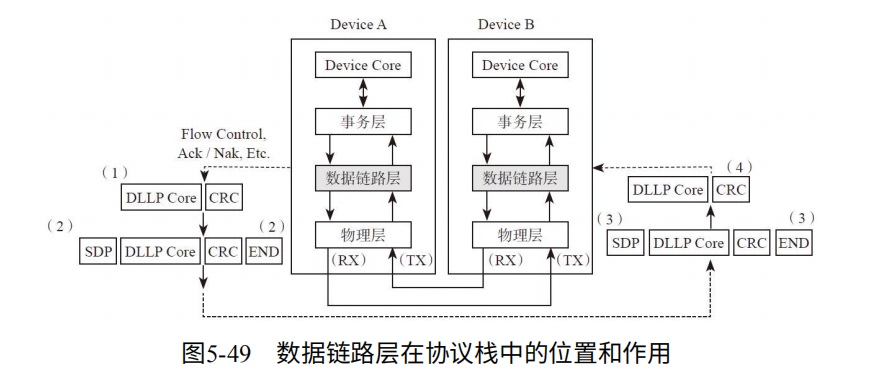
如图5-49,DLLP的作用。
发送端:数据链路层生成DLLP,交给物理层。物理层将其加SDP和技术标志(GEN 1/2加END,GEN 3不加),并传给对方。
接受端:对DLLP掐头去尾,并进行校验。
对于DLLP,仅能支持端到端的传输,不需要路由信息(谁发出,给谁),因此也只能对于相邻端口进行(如:RC与Switch上游Port,Swtich上游Port与下游Port,Switch下游Port与连接的设备EP1)。
四大类型DLLP:
1. 确保传输完整性:ACK/NAK。
2. 流控相关:DLLP。
3. 电源管理:DLLP。
4. 厂家自定义:DLLP。
所有DLLP大小为6B,加上物理层则是8B,不同类型DLLP,格式不同。
ACK/NAK:发送方会对TLP加上序列号和LCRC后,会把该TLP放到Replay Buffer中。接收端收到TLP后,进行校验。无误,则返回ACK给发送端,发送端清除在Replay Buffer相关的TLP
否则返回NAK DLLP,发送方知道出错,重传Replay Buffer相关的TLP。只有正确的TLP才会交个事务层。
对于发送方发送了10,11,12,13.(目前都在Replay Buffer中),接收到上一个成功接收TLP序号为11,期望下一个是12.
(1)CRC校验:如果失败,会发送一个NAK,其中ACKNAKSEQ设置为11(代表11之前都成功了)。发送端移除Buffer中1之前的,并知道12和之后需要重发。成功则直接下一步。
(2)检查序列号:如果收到12,与预期相符,可以返回ACK,也可以不返回(不返回可以减少DLLP的传输,可以等若干个之后返回一个ACK)
如果收到13,说明12丢失了,发送NAK,其中ACKNAKSEQ设置11。发送端移除Buffer中1之前的,并知道12和之后需要重发。
如果收到10,说明发送端长期没收到ACK,自动重发了。可以发送ACK,其中ACKNAKSEQ设置11。
TLP流控:由于接收端处理TLP速度可能赶不上发送速度,因此需要告诉发送端我有多少空间,发送端根据情况判断发送数据还是Hold住,直到空间足够。
仅针对TLP,DLLP不需要流控(才6B)。
电源管理:看第八章....。
物理层:由电器模块(串行总线传输+差分信号(两条线的差值作0/1,防干扰能力强,如果两条线都受干扰,差值几乎不变))和逻辑模块组成。
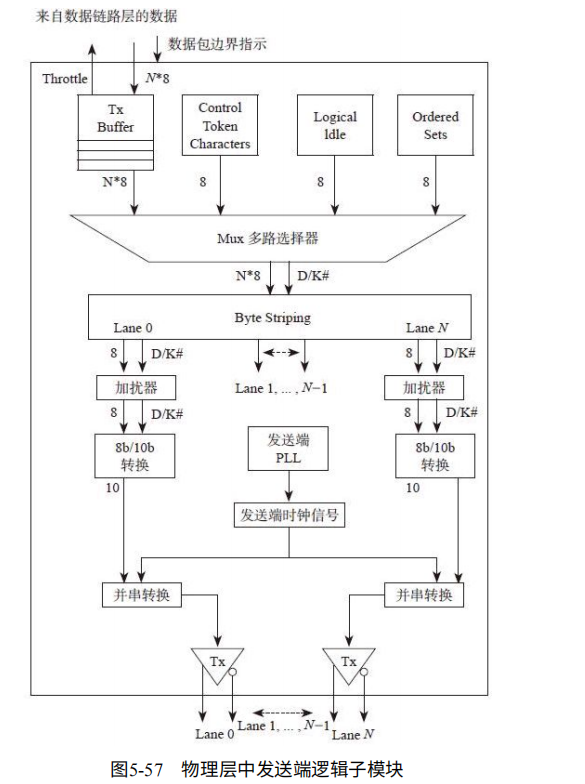
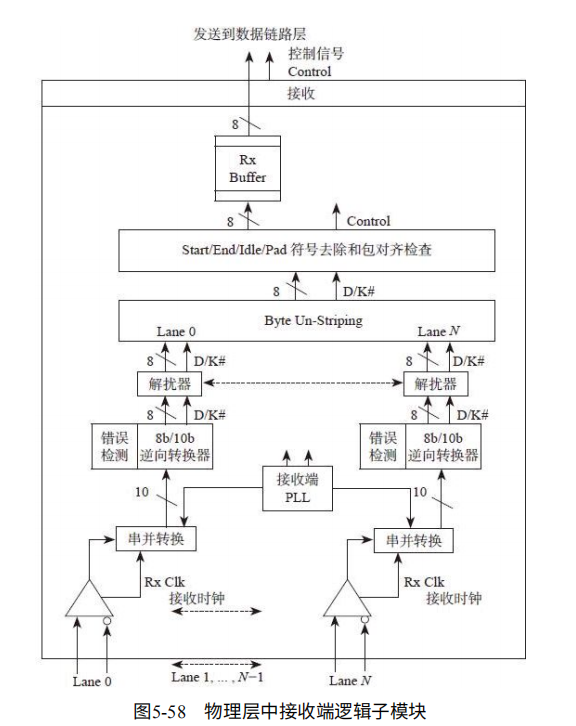
逻辑模块:物理层对于TLP/DLLP放到Buffer,并加上头,尾,以及符号边界,用以区分TLP和DLLP。对于多个Lane,会将TLP/DLLP分派到每个Lane独立传输。并加上串扰(随机数,减少干扰)
并用8/10编码(GEN3是128/130),让0和1的个数相当。嵌入时钟信息。最后并串转换发送到串行总线。
PCIe Rest:总线规定了两个复位方式:Conventional Rest和Function Level Reset(FLR)。
其中Conventional Reset又进一步分为Fundamental Reset和Non-Fundamental Reset。其中Fundamental Reset分为Cold Reset和Warm Reset。而Non-Fundamental则为Host Reset。
Fundamental Reset:由硬件控制,重启整个设备。对于Cold:Pwer Off/On Device的VCC。Warm:保持VCC下由系统触发,比如修改电源管理。
FLR:对于PCIe link上的各种Function,如果某个Function出问题,将整个Link都Reset不太必要,因此可以直接让该Function Reset。
PCIe MAX Payload Size和MAX Read Request:都在设备控制寄存器中。
MPS:控制一个TLP最大传输 大小,接受放方需要能处理MPS大小的数据包,发送方不能超过MPS。
PCIe协议允许最大为4KB,但是若有低MSP的,只能采用低MPS的大小。MPS设定不能超过任意设备的MPS处理能力。
MPS设置是在枚举配置阶段完成。
Max Read Requeset Size:用于控制Memory Reade的最大Size。最大4KB,可以超过MPS,但需要返回成多个小于MPS的Cpld。
PCIe的热插拔:
早期PCIe SSD以闪存卡被广泛使用,闪存卡的缺点:PCIe插槽有限。通过插槽供电单卡容量受限制。容易导致散热不均出现宕机。不能热插拔,必须停止服务,打开机箱,拔出闪存卡。
因此推出了U.2:支持热插拔。对于U.2组成的阵列,通过面板知识灯判断哪个SSD故障,可以直接更换。
对于热插拔的PCIe SSD需要几方面支持:1硬件支持,防止电流波峰导致硬件损坏,并能检测拔盘操作,防止数据丢失。操作系统,确定热插拔为操作系统还是BIOS处理。PCIe SSD驱动。
基本流程:
1. 配置应用程序,停止所有对目标SSD的访问。
2. umount目标SSD上所有文件系统。
3. 卸载SSD,删除注册的块设备和disk。
4. 拔出SSD。
链路层性能损坏:
1. Encode和Decode:如8/10编码,保障0/1数量相近。带来了20%性能损耗。对于GEN3已经采用了128/130,性能损耗几乎可以忽略。
2. TLP Packet Overhead:TLP有效数据为Data,外层带来了大约20~30B的额外开销。
3. Traffic Overhead:进行时钟偏差补偿,定期发送Skip。Gen1/Gen2的Skip是4B,Gen3是16B。Gen2采用1538个symbol time(一个Byte发送的试卷)发送,只能在两个TLP间发送。
4. Link Protocol Overhead:对于TLP要发送DLLP,造成了性能损耗。
5. Flow control:对于流量控制,显然会占用带宽。
6. System Parameters:MPS,Max Read Request Size,Read Completion Boundary(RCB)。其中RCB是因为允许多个CqID回复一个Read Request,因此需要在Memory进行对齐。
第六章 NVMe
HDD和早期SSD大多数使用SATA接口,跑AHCI。AHCI支持NCQ和热插拔技术。NCQ最大深度32,即主机可以发送32条命令给HDD和SSD。
随着闪存速度越来越快,性能已经转移到接口上。因此出现了NVMe,运行在PCIe上的协议标准。
NVMe相对AHCI的优势:
1. 低时延:影响硬盘存储时延的三大因素为 存储介质本身,控制器,软件接口标准。
存储介质采用闪存速度相对机械硬盘飞快。
控制器采用PCIe,主控与CPU相连,不需要南桥再连接CPU。
软件协议NVMe缩短了CPU到SSD的指令路径,减少了寄存器访问次数。使用MSI-X中断管理。并行多线程优化,减少了锁同步操作。
2. 高性能:IOPS=队列深度/IO延迟,故队列深度与IOPS有较大关系(但不成正比,随着深度增加,IO延迟也会提升)。AHCI最多队列深度32,但PCIe通常到128甚至256才能发挥极限。
NVMe下,深度可达64K,队列数量也从AHCI的1提高到64K。
3. 低功耗:看第八章。
NVMe作为主机与SSD的协议,在PCIe事务层协议之上。
NVMe作为命令称和应用层协议,理论上可以适配任何接口协议,但原配是PCIe。
SATA速度不超过600MB/s甚至560MB/s。

跟ATA命令规范相比,NVMe命令数少了很多。(SATA时代,只有HDD用的命令也需要兼容实现,但没必要的)。
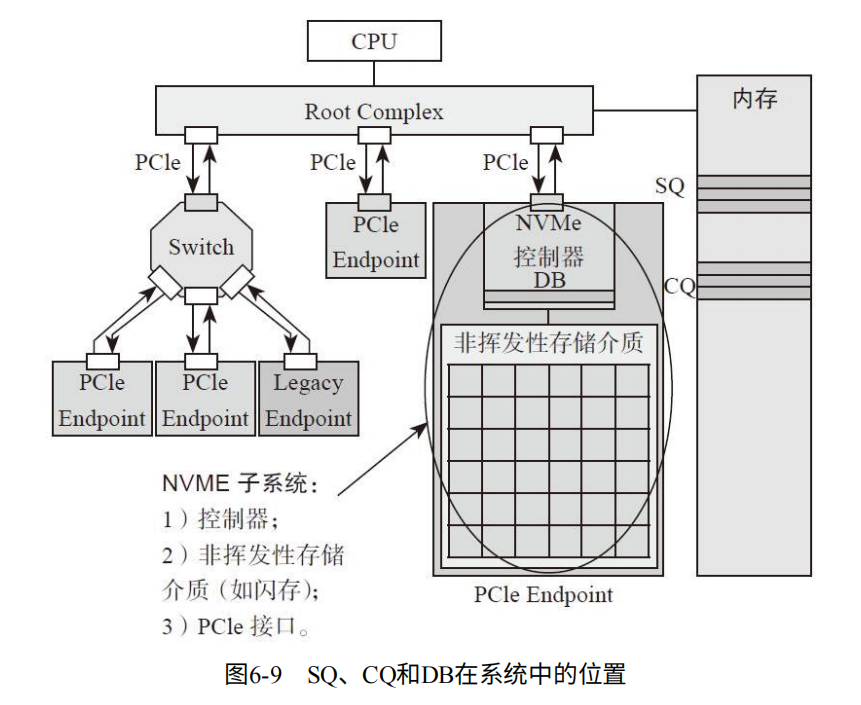
NVMe的三宝:Submission Queue(SQ), Completion Queue(CQ), Doorbell Register(DB)。
如图6-9,其中SQ和CQ位于主机内存。DB位于SSD控制器。
主机发送给SSD的命令存储在SQ中,SSD将命令执行成功或失败的状态存到CQ中。因为发送的命令在主机SQ中,因此还需要写向SSD的DB用于通知。
如图6-10。1. 主机写命令到SQ。2. 主机写DB通知SSD。3. SSD控制器取指。4. 控制器执行指令。5. 写入CQ。6. 产生中断通知主机。7. 主机处理CQ。8. 处理CQ的结果,通过DB通知SSD。
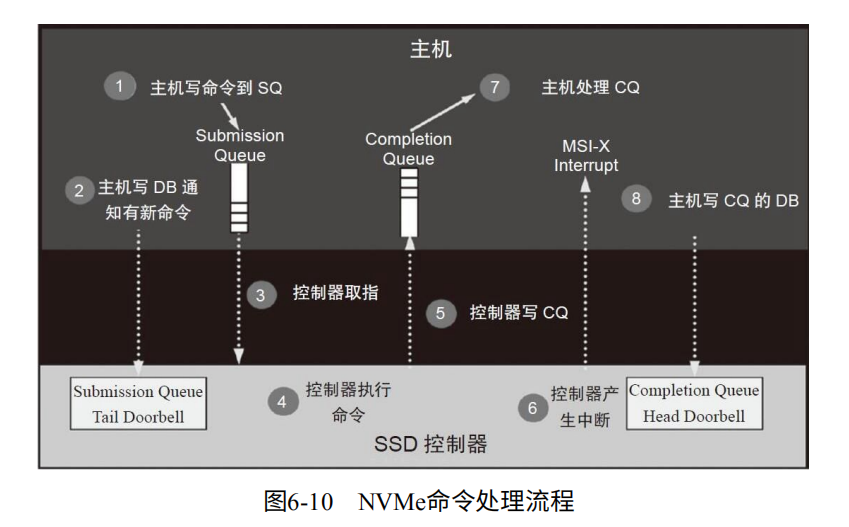
SQ、 CQ、DB:对于SQ与CQ可以是一对一,也可以是多对一。但有SQ必然有CQ。
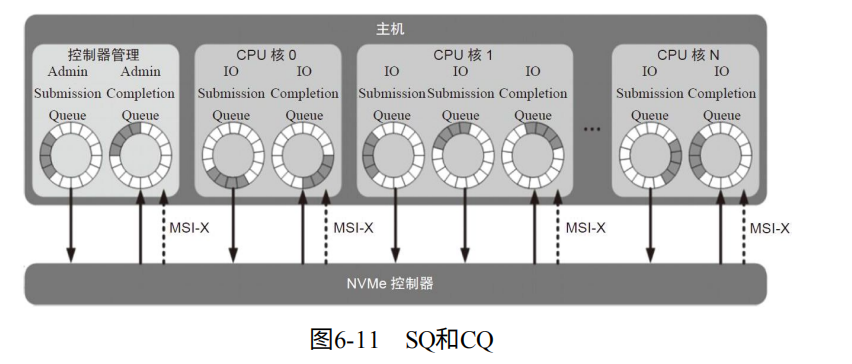
SQ与CQ,一种为Admin,一种为IO。Admin用于主机管理SSD。IO用于放IO命令,传输数据,由Admin创建。并且不能交叉使用。
如图6-11。Admin只有一对SQ/CQ。IO的却可以很多。(64K-1即65535对)。(对于NVMe over Fabrics,SQ和CQ只能一对一,并且IO SQ/CQ不是Admin创建。)
主机每个CPU核可以有一个或多个SQ(用于不同线程,甚至存在优先级),只有一个CQ。
队列深度:Admin中2~4K。IO中2~64K。其中SQ中命令大小为64B,CQ中状态大小是16B。
对于SQ/CQ,都作为环形队列,因此包含头和尾。DB则是用来记录SQ/CQ的头和尾,每个SQ或者CQ都有两个对应的Head DB和Tail DB。DB存在SSD端的寄存器,记录位置。
对于SQ,主机为生产着,向尾部写入,SSD从头部取出指令。CQ来说,SSD是生产者,主机是消费者。
如:
1. 开始SQ和CQ都为空,Head=Tail=0。
2. 主机向SQ写入3条命令,SQ的tail变成3。通知SSD寄存器端的SQ Tail,值为3.(用于告知有新命令)
3. SSD将SQ中的3条命令取回,并将SQ的Head更新为3。写入本地SQ Head寄存器。
4. SSD执行完两条命令,将完成信息写入CQ,并更新CQ的Tail,值为2.通知主机。
5.收到通知(中断),取出两条信息。告知SSD的CQ Head寄存器值为2。
因此 DB记录了Head和Tail。对于SQ,SSD只知道头在哪,尾巴在哪需要主机插入数据后并更新。对于CQ,SSD知道尾巴在哪,并告知主机。
对于主机只会写入SQ Tail DB和CQ Head DB。如何知道其他的。因此,在SSD写入CQ的状态中会包含SQ Head DB信息。对于CQ Tail DB信息,则是通过每个状态一个P位,对于执行完置0,未执行是1。CQ在主机中,因此挨个判断一次即可。
寻址:PRP和SGL
对于主机向SSD写入数据,需要告诉数据在内存中地址,即LBA。对于读取,需要根据LBA查找闪存的物理块,获得数据。
因此无论读写,都需要内存地址。对于寻址方式一种为PRP(Physical Region Page,物理区域页),一种SGL(Scatter/Gather List,分散/聚集列表)
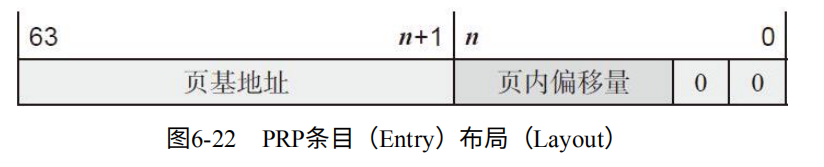
RPR:将内存划分为物理页(大小可以是4KB~128MB)。如图6-22 PRP Entry则是64位内存物理地址,包含页起始地址和页内偏移。最后两bit表示只能4字节对齐。
对于若干PRP Entry连接,构成了PRP链表。其中每个PRP必须是物理页。即偏移为0,而且链表中不能有相同物理页。
NVMe命令中两个域:PRP1、PRP2代表数据所在位置和数据写入位置。PRP1和PRP2可能是链表,也可能是数据。(如同C指针)
对于Admin来说只能用PRP来告诉SSD内存物理地址。对于IO命令除了PRP还可以用SGL。
SGL:SGL优势在于,可以存储任意大小的数据,不需要以物理页为单位。
SGL作为数据结构,由链表构成,每个节点作为一个SGL段(Segment)组成,而每个SGL段又包含一个或多个SGL 描述符(Descriptor)。
SGL描述符作为最基本单位,描述了连续的物理内存空间:起始地址+大小。每个描述符16字节。分4种类型。
1. 数据块。 2. 段描述符,作为链表记录下一个SGL段所在位置。3. 末段描述符,用于链表倒数第二个段。 4. SGL位桶,由于跳过不需要读的数据。
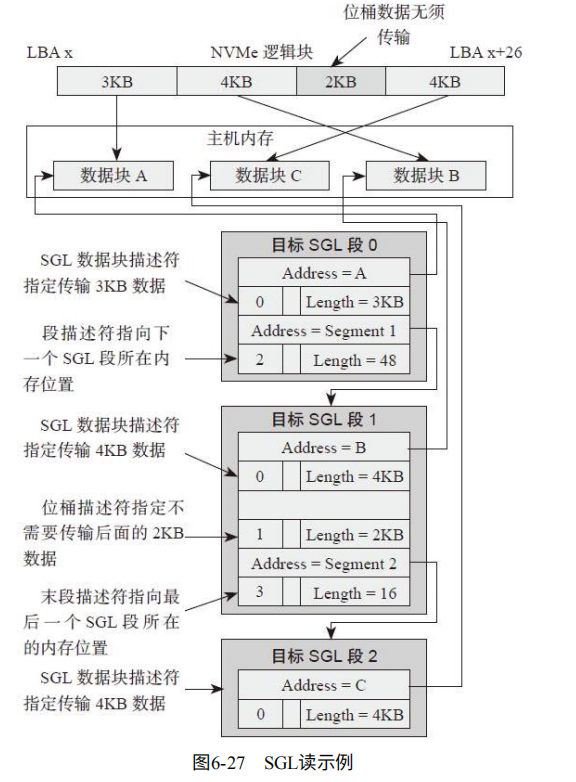
如图6-27,主机需要读取13KB(真正需要11KB),存放到3个不同内存地址,3KB,4KB,4KB。
第一个SGL段(本数据位置,下一个SGL段)。第二个SGL段(本数据位置,下一个SGL段(并设置了作为末尾段描述符),SGL桶记录了跳过2KB)。第三个SGL段(数据位置)。
分析Trace:(...............TODO................)

对于一条读命令如图6-31。
1.(第1行) 主机需要从LBA 0x20E0448(SLBA)位置读取128个DWORD的数据。读到PRP1的地址。命令放在编号为3的SQ里(SQID=3)。CQ编号也为3(CQID=3)。
2. (2~3行)主机写SQ的Tail DB通知SSD取命令。而由于所有EndPoint都会映射到内存中,因此Tail DB寄存器也被映射到内存中,只需要写入映射地址就可以准确写到寄存器地址。
3. (4~7行)SSD收到通知,去主机的SQ取指。可以看到,读取了16DWORD
4. (8~12行)SSD执行读命令,把数据从闪存读到缓存,传给主机。
5. (13~14行)SSD向主机CQ写返回状态。
6. (15~16行)SSD采用中断的方式告诉主机处理CQ。
NVMe端到端的数据保护:(主机端到SSD的闪存空间)
对于主机与SSD的最小单元逻辑块(LB)是512B~4096B,在主机格式化SSD时就确定了。
为了确保数据正确的,采用了元数据来保障数据。元数据的存在方式一般分为:元数据和逻辑块数据在一起传输,或元数据和逻辑块数据分开传输。NVMe只支持前者。
元数据包括:Guard(16bit的CRC),Application Tag(控制器不可见,主机使用),Reference Tag(用户数据和地址(LBA)相关联)
在传输过程,可以让数据都带上元数据,也可以选择不带,甚至部分传输地带不带。(对于不重要数据可以选择不带,减少带宽的浪费)
副作用在于:每个块需要8字节的保护信息,数据块越小,带宽影响越大。SSD控制器需要做数据校验,影响性能。
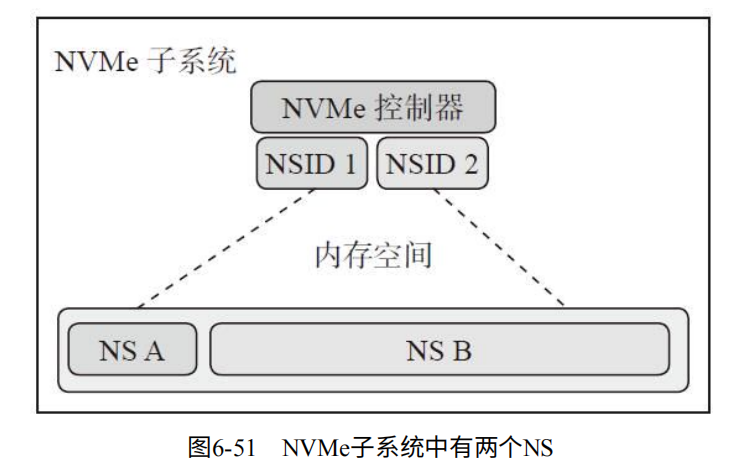
Namespace(NS):对于闪存空间划分成N个LBA,成为一个NS。对于SATA SSD一个闪存空间只能有一个NS。但NVMe SSD一个闪存空间可以存着多个NS。每个NS有唯一的名字和ID。
如图6-51,每个NS在主机看来就是一个独立的磁盘。
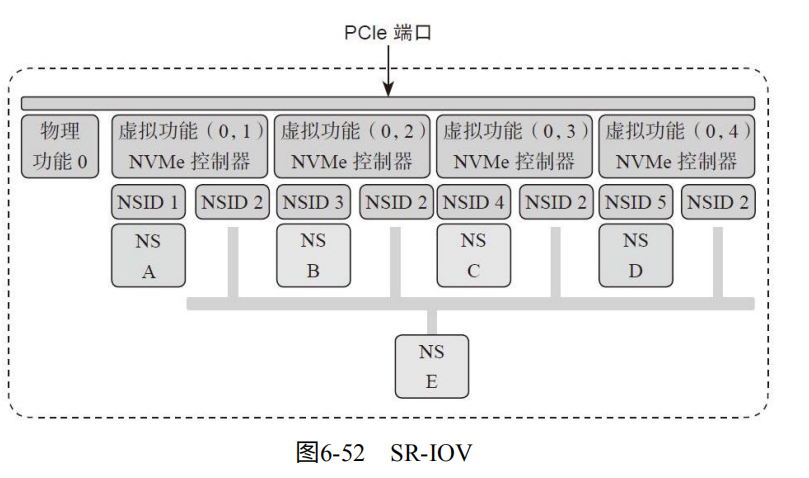
SR-IOV:允许虚拟机之间共享PCIe设备。并且在硬件实现。单个IO(SSD)资源可以被多个虚拟机共享。如图6-52.
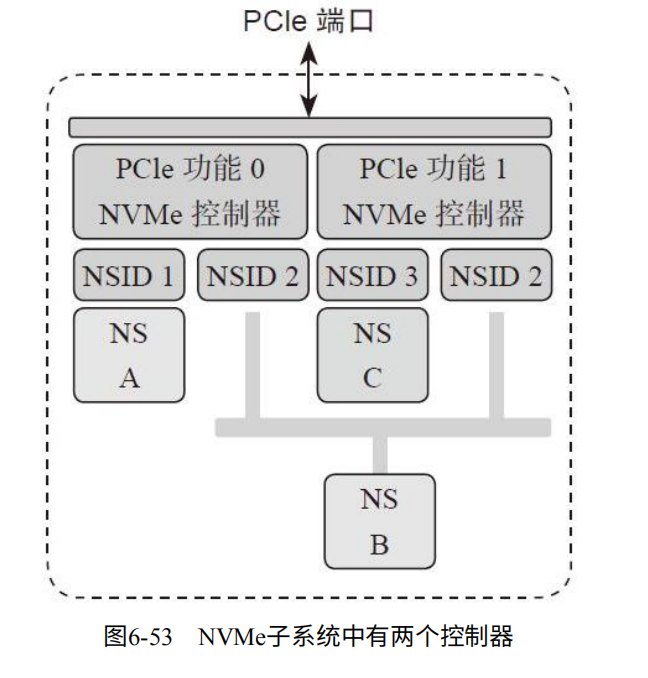
除了多个NS,甚至可以有多个SSD控制器(不是一个SSD控制器有多个CPU,而是有多少实现NVMe功能的控制器)
如图6-53。NVMe包含两个控制器,内存划分为3份。NS A由控制器0独享,NS C由控制器1独享,NS B由两个控制器共享。
除了NS,控制器可以多个,PCIe端口也可以多个。连接相同主机或不同主机。
如Z-Drive 6000采用了双PCIe端口,可以连接独立主机,如果一个数据通道出现故障,OCZ的主机热交换技术可以让另一个主机无缝低延迟接管任务。如金融,OLTP,OLAP等需要实时性非常高。
NVMe over Fabrics:
NVMe针对新型Non-Volatile Memory(如:闪存,3D XPoint等)而设计。用于低延迟(10us以内),对于全闪存阵列若还采用ISCSI(时延最低100us)无法充分发挥性能。
NVMe over Fabrics定义了各种通用的事务层协议:RDMA,Fibre Channel,PCIe Fabrics等。
目前的互联方式分为:内存(Memory),消息(Message),消息内存混合(Memory&Message)。如图6-62.
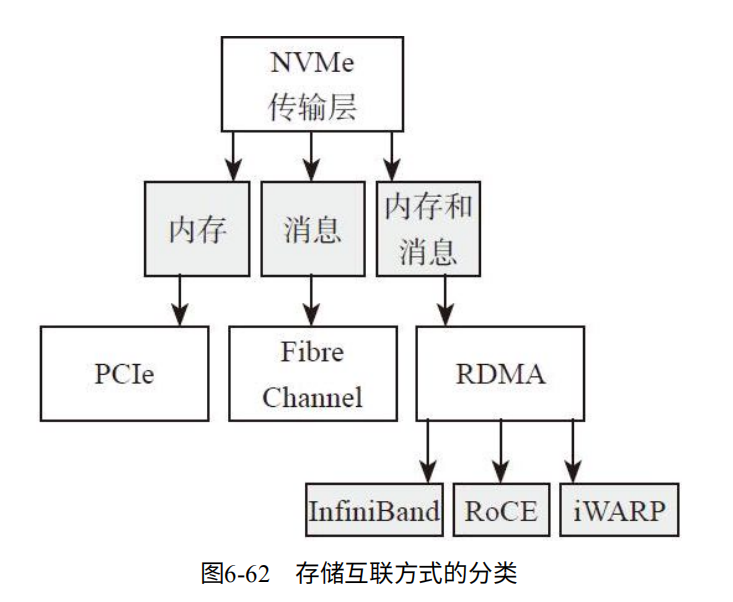
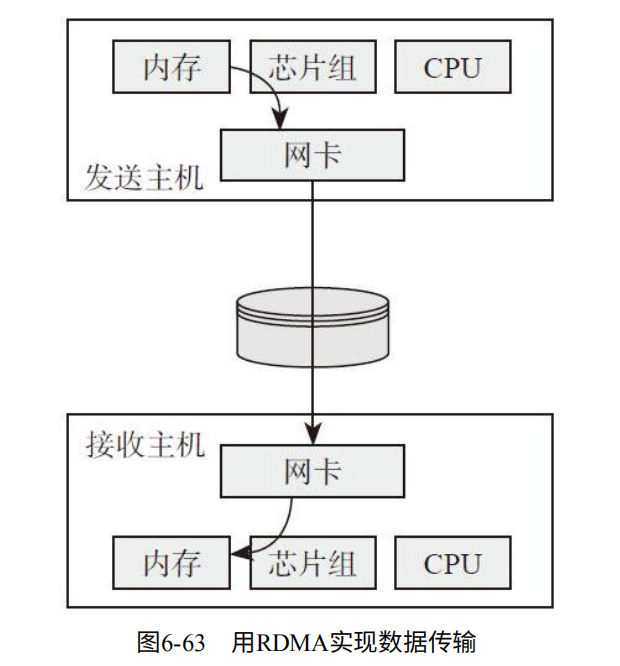
RMDA:通过网络将数据直接传输到计算机的存储区域。如图6-63
1. 提供了低延迟,低抖动,低CPU使用率。
2. 最大限度利用了硬件,避免软件栈的开销。
3. 定义了丰富的可异步访问的接口。
但由于网络的传输模式和本地PCIe有大量差异,因此综合了RDMA,FC等特点,提出了NVMe over Fabrics。解决几个问题:
1. 提供不同互联透明的消息和数据的封装格式。
2. 将NVMe操作所需的接口映射到互联网络。
3. 解决节点发现,多路径互联的问题。
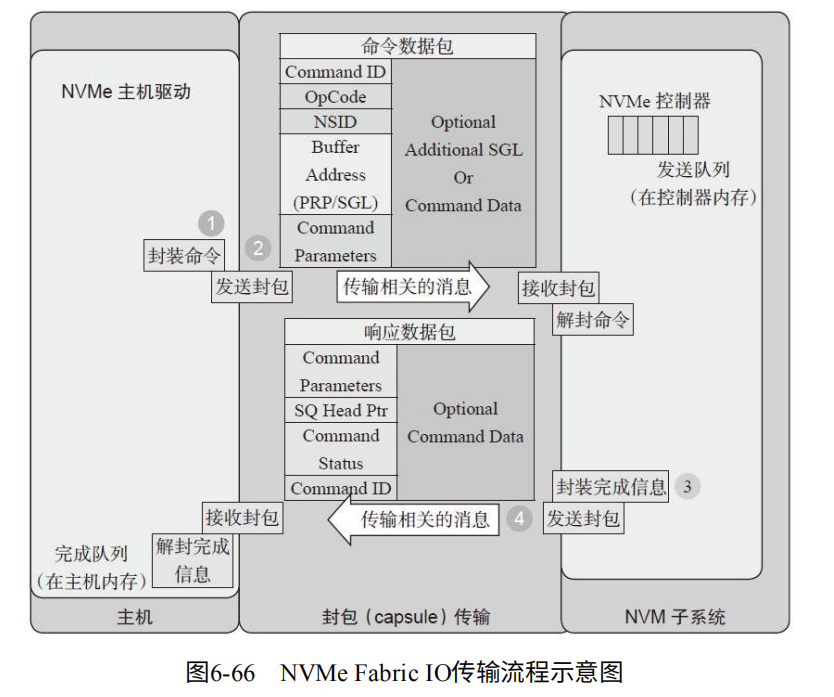
如图6-66,作为一次IO传输过程。
1. 发送端驱动程序封装请求派发给硬件
2. 发送端硬件将请求发送给目标的发送队列
3. 目标端控制器处理IO请求,并准备完成请求派发给硬件。
4. 目标端硬件将完成请求发送给发送端。‘
由于发送请求和完成请求可以带数据,降低了交互时间。
第七章 SSD测试
1. FIO:强大的性能测试工具。
线程:多少个读写任务并行执行,一般来说,一个CPU一个核心同一时间只能运行一个线程,除非使用时间切片划分给多个线程。
Linux采用Jiffes代表一秒划分了多少时间片,1000则是1毫秒,100则是10毫秒。
同步模式:一般来说主机发送一个命令到SSD仅需几微秒,但SSD处理需要几百微妙,若主机发送一个命令,线程就休眠等待,则称为同步模式。
但SSD有很多并行单元,若采用同步模式,简直是暴殄天物。
异步模式:为了提高并行性,一般采取异步模式。线程发送命令后继续往下执行,SSD完成后通过中断或轮询方式告诉CPU,这时CPU再用回调函数来处理结果。
队列深度:但是如果不断发送命令,可能SSD也撑不住,因此采用队列深度,限制最多有多少命令,一般64的队列,如果队列满了就不能再发,等处理完有空位再继续发送。
Offset:设置offset可以从某个偏移开始测试,比如offset=4G的偏移地址。
DIrect IO:对于内核维护了缓存,数据一般先写到缓存在写到SSD。读也是先读缓存,但机器一旦掉电就丢数据了,因此采用Direct IO,直接读写SSD。
BIO:Linux读写SSD设备使用的是BIO(Block-IO),包含了LBA,数据大小和内存地址等。
fio初体验:fio -rw=randwrite -ioengine=libaio -direct=1 –thread–numjobs=1 -iodepth=64 -filename=/dev/sdb4 -size=10G -name=job1 -offset=0MB
fio:软件名
rw:读写模式,randwrite是随机写,除此还有顺序读,顺序写等。
ioengine:libaio则是异步,同步是sync
direct:是否使用Direct IO
thread:使用phread-create创建线程,另一种是fork
numjobs:每个job一个线程,每个-name指定的任务就会开启这么多线程,因此线程数=任务数*numjobs。
iodepth:队列深度
filename:数据位置,可以是块设备,文件名,分区,SSD设备。
size:每个线程写入数据量
name:任务的名字
offset:从某个偏移地址开始写
bs:每个BIO包含的数据大小。
output:日志输出

FIO会为每个Job打出统计信息,可以看到带宽,IOPS等。
延迟:slat是发出命令的时间,包含最短,最长,平均,标准差。clat是命令执行时间。
FIO可以设置verify来做数据校验。
2. AS SSD Benchmark
SSD专用测试软件,用来测试连续读写,4K对齐等,并给出综合评分。
除了测试性能,还可以检测固件算法,是否打开AHCI模式,是否4K对齐等。
3. ATTO Disk Benchmark
作为简单易用的磁盘传输速率检测软件,用来检测硬盘,U盘,存储卡等速率。
4. CrystalDiskMark
用来测试硬盘或存储设备的小巧工具,默认运行5次,取最好成绩。
5. PCMark Vantage
衡量PC的综合性能。
1. 处理器测试:数据加密解密,压缩,解压等。
2. 图形测试:高清视频播放,游戏测试等。
3. 硬盘测试:使用游戏,图片等导入。
6. IOMeter
单机或集群IO子系统的测量和描述工具。
---------- TODO 测试仪器---------------
回归测试
保障新的代码不会影响旧功能。
-----------TODO PCIe,WA,耐久度测试,认证测试(哪天可以去认证都说了.....)----------------
第八章 电源管理
SATA电源管理可以让SATA链路的PHY进入低功耗模式,与硬盘,SSD,CPU等其他部分的电源管理是独立。
SATA提供了两种低功耗模式
1. Partial:PHY处于低功耗模式,让部分物理层(PHY)进入休眠模式,能够在10us内被唤醒。在不太影响传输性能的情况下忙里偷闲。
2. Slumber:PHY处于更低功耗,可以关闭更多电路,恢复时间大约10ms。
Partial/Slumber可以让功耗从Active的1000mW降低到100mW。
对于链路的电源管理,主机和设备都可以发起:HIPM(Host Initiated Power Management),DIPM(Device Initiated Power Management)。
对于主机发起PMREQ_P/PMREQ_S,设备同意则进入Partial/Slumber,否则拉倒。若想退出Partial/Slumber则通过OOB重新建立。
Listen Mode(监听模式):支持用端口监听新接入的盘,功耗只是Slumber。
Auto Partial to Slumber:让链路不需回到Active,直接从Partial进入Slumber。
SATA超级省电模式
DevSlp:在Partial/Slumber下,盘必须保持工作模式,以便于把自己唤醒,SATA总线的发送模块和接收模块也需要保持工作状态,因此省电效果不好。
DevSlp则将传输电路完全关掉,专门加入一个低速管脚来唤醒。DevSlp的功耗降到5mW,唤醒时间变成20ms。
SATA终极省电模式
RTD3:DevSlp时Vcc还在,因此还有功耗。因此主机想在长期Idle后把Power完全关掉。
通常是主机处于S0,SSD进入D3 Cold状态,因此就是Runtime D3,简称RTD3
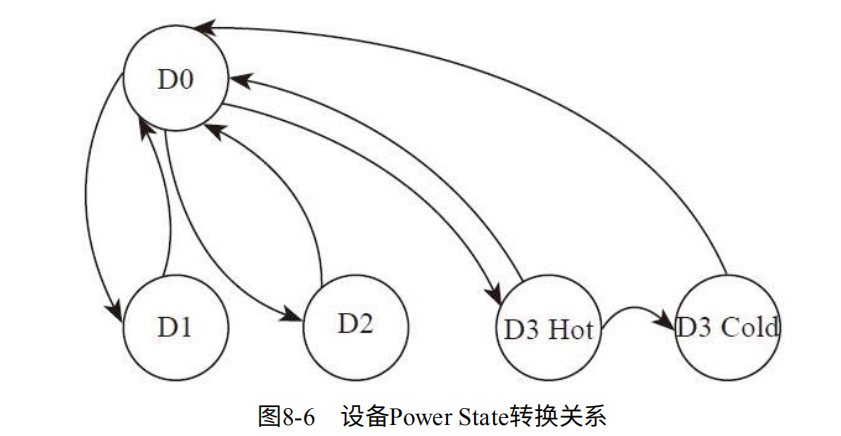
ACPI规定的Device Power State:(对于设备如SSD的规定)
1. D0:设备处于工作状态,所有功能可用,功耗最高,所有设备都支持。
2. D0 active:设备完成配置,随时准备工作。
3. D1和D2:介于D0和D3之间,D1比D2消耗更多电,能保存更多的设备上下文。D1和D2是可选的,很多设备不支持。
4. D3 Hot:设备进入D3,Vcc还在,设备可以被枚举。
5. D3 Cold:设备完全切断电源,重新上电需要初始化设备。
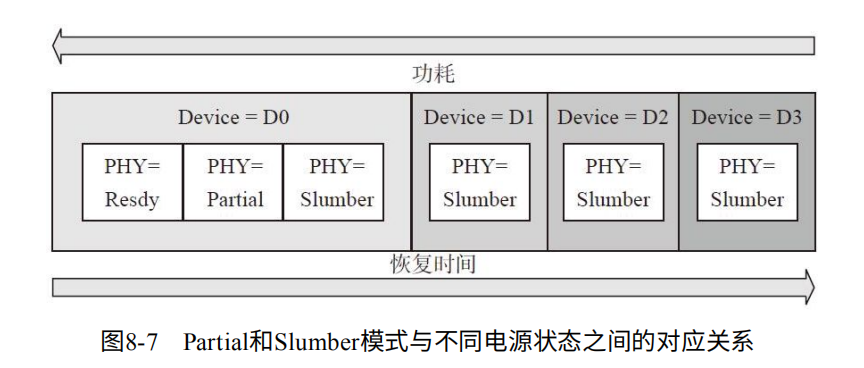
系统电源状态:(主机的规定)
1. S0:工作模式,操作系统可以管理SATA SSD的电源状态(D0或D3都可以)。
2. S1:低唤醒模式,系统上下文不会丢失。
3. S2:与S1相似,但处理器和系统的Cache上下文会丢失。
4. S3:睡眠模式(Sleep),CPU不运行命令,SATA SSD断电,除了内存之外所有上下文丢失,硬件会保存一部分处理器和L2 Cache配置上下文。
5 S4:休眠模式(Hibernate),CPU不运行命令,SATA SSD断电,内存写入SSD,系统上下文丢失,操作系统负责保存与恢复。
6. S5:Soft off state,类似S4,但操作系统不会保存和恢复系统上下文,消耗很少电,可通过鼠标等设备唤醒。
PCIe省电模式:ASPM
ASPM让PCIe在某种情况下,能给从工作状态(D0)通过把自身PCIe链路切换到·低功耗模式,并通知对方也这么干,从而达到整条链路低功耗的目的。
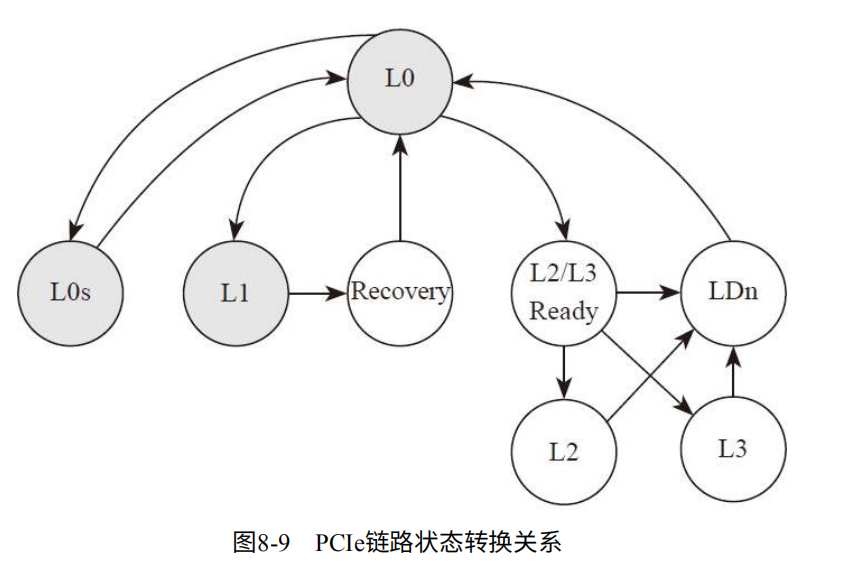
ASPM的低功耗模式有两种,L0s和L1。如图8-9
1. L0:正常工作状态。
2. L0s:低功耗模式,恢复时间短。
3. L1:更低功耗模式,恢复时间长。
4. L2/L3Ready:断电前的过渡状态。
5. L2:链路处于辅助供电模式,极省电。
6. L3:链路完全没电,功耗为0.
7. Ln:刚上电,还未完成前链路所处状态。
其中链路寄存器中可以进行设置L0s/L1 或读取当前状态
PCIe其他省电模式:
处于L2下,所有时钟和电源全部关闭,省电效果很好,但是恢复时间达到毫秒级。
因此需要处于L1和L2之间的模式:L1.1和L1.2。区别在于Common Mode Voltage是否打开。
-----------------TODO NVMe电源控制----------------
第九章 ECC原理
对于实际通信中,information bits表示有效信息长度,channel use表示实际传输长度。
Code rate=(information bits) / (channel use)
对于三副本则是1/3.Code rate越小 冗余越大。 Shannel揭示了,每个传输通道都有C,若 Code rate < C,则理论错误率可以趋近0.
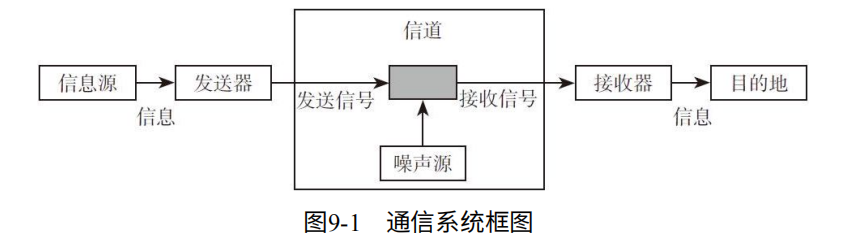
一个完整的通信系统模型:信息由信息源产生,发送器发出信号,经过包含噪音的信道,到达接收器,再发往目的地。如图9-1.
二进制编码的系统,两种常见Channel模型:
1. BSC(Binary Symmetric Channel,二进制对称信道):如果出错,收到的0可能是1.收到1也可能是0
2. BEC(Binary Erasure Channel,二进制擦除信道):可能会丢失bit,但是收到的0肯定是0,收到1肯定是1。但传输出错可能导致接受者收不到信息。
在BSC中0,1组成的二进制信号,0,1各有p概率翻转。在BEC中,信号可能变成无法识别,但是不会翻转。
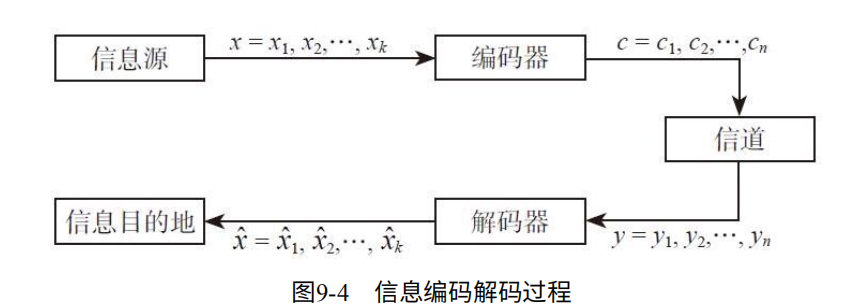
对于SSD来说,一般采用BSC模式,因为容易翻转。为了使得信息准确到达,采用编码。如图9-4.将ke位编码成n位,传入信道。
纠错编码:目的让编码后和编码前有足够大的区别。
编码距离:对于0/1串来说就是不同的位数。
对于00,01,10,11若采用重复编码
00变为00000000
01变为01010101
10变为10101010
11变为11111111
对于接收到信号00010000,发现编码距离最近的是00000000,距离是1。
CR=H(y)={0, 1}。y为信号,H为特定的处理,CR为结果,其中0是通过,1是失败。
奇偶校验:计算二进制中1的个数,作为一个位校验位,即SPC(single bit parity check code)当存在奇数个翻转,就会查出错误,但不会纠错。
校验矩阵H和生成矩阵G:由于SPC只对奇数个翻转检测,因此可以设立多个条件,建立方程组。
对于长度n位,其中r位校验码,n-r位有效位。
对于线性分组编码,原始信号u,可以通过线性变化生成纠错码c,其中G是生成矩阵,c=uG。(c为n bit信号,u为k bit信号, G为k * n矩阵,H可以推导G的生成)
LDPC:低密度奇偶校验码。其中1的分布很稀疏。
又分为正则和非正则,其中正则保证每行有固定J个1,每列有固定K个1。如图,为正则矩阵H,右侧为校验方程。

Tanner图:用于直观表示矩阵。一种节点为b节点(bit node),一种为c节点(check node)。如果bi参与了cj方程的校验则将其连线。如图9-6.

低于LDPC解码:分为硬判决和软判决。
Bit-flipping算法:作为硬判决的经典算法。
对于一个信号参与的大量校验方程失败,说明该bit大概率出现错误。
Bit-flipping 解码方式:对于n位信号y(y1, y2....yn),矩阵H。画出Tanner图,n个b节点,r个c节点。
1. 每个b节点向连接自己的c节点发送自己bit。第一次为yi。
2. 每个c节点对于受到的所有b节点信息,进行校验。
2.1 如果成功,则将b节点消息发送回去。
2.2 如果失败,则将b节点消息取反发送回去。
3. 每个b节点和多个c节点连接,可能受到0或者1,因此采用少数服从多数的投票方式保存自己的bit。
4. 如果本次所有校验方程都满足(即第2步都成功)或迭代次数超过上限,则停止。否则跳到第一步。
对于Bit-flipping有很多细节值得讨论:如b节点更新,一次更新一个还是多个,若采用多个可能无法收敛,若采取一个,速度太慢。折中办法是先更新多个,数量少后更新单个bit。
和积信息传播算法:作为软判决的经典算法。
算法的基础为概率论。
条件概率P(A|B):在B事件发生的条件下,A发生的概率。
P(B|A) = P(A, B)/P(A)。其中P(A)是A发生的概率,P(B)是B发生的概率。
P(A, B)是A和B共同发生的概率。
贝叶斯公式:P(B|A) = P(A|B) * P(B) / P(A)
边缘概率:从多元随机变量中的概率分部得出只包含部分变量的概率分布。
P(A) = ∑B ∑C ∑D f(A, B, C, D) (就是说A发生的概率 = B,C,D在任何情况下A发生的概率之和)
P(A | B=1) = ∑C ∑D f(A, B=1, C, D) (就是说B=1的条件下A发生的概率 = B为1的条件下,C,D在任何情况下A发生的概率之和)
贝叶斯网络:是一种推理性图模型。
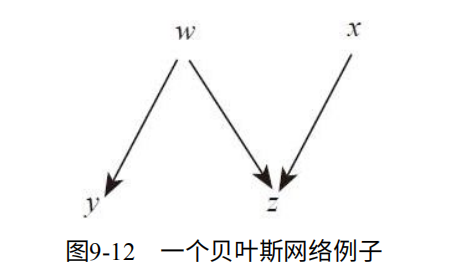
例如:x, y, z, w代表随机事件,w为是否吸烟的概率,x是职业是煤矿相关的概率,y是是否为咽炎的概率,z是是否为肺部肿瘤的概率。如图9-12
其中关系P(x, y, z, w) = P(w) * P(x) * P(y | w) * P (z | w, x )。
其中P(y|w=1)代表吸烟得咽炎的概率,P(z |w ,z)则代表 是否吸烟以及是否在煤矿工作得肺部肿瘤的概率。
因子图:无向的概率分部二部图。因子则为事务内部约束所表现的逻辑形式。
如下图所示的联合概率,其因子图如图9-13.


----------------------------------TODO 讲了一堆公式最终成功完成了计算-----------------------------------------------------
LDPC编码来说,要先确定H矩阵,才能确定G矩阵。
H矩阵的注意:
1. 保持稀疏,每行每列1的个数固定或者接近固定。
2. 考虑生成矩阵的计算复杂度。
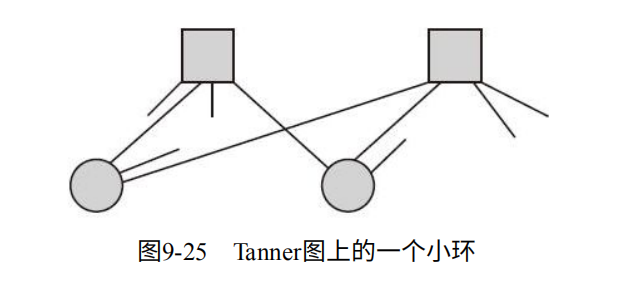
3. 减少小环的个数。如图9-25,其中一个出错,很难判断是哪个错误了。
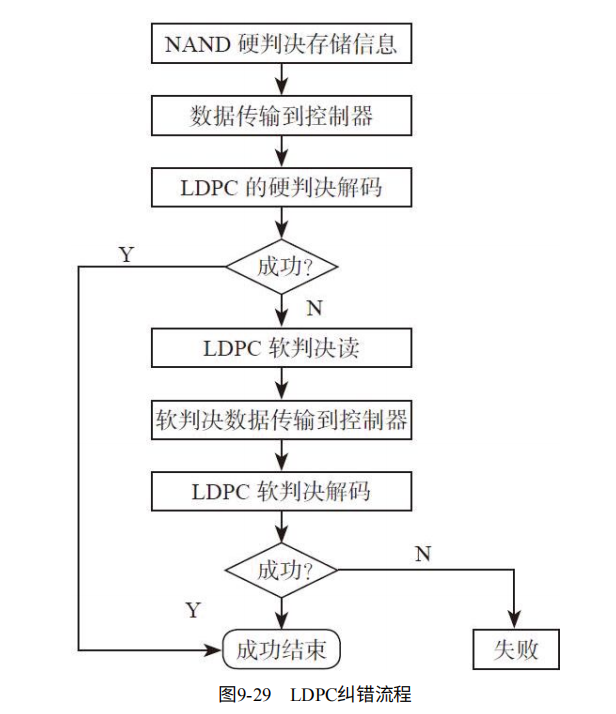
LDPC在SSD中的纠错流程,如图9-29.