《 Real-Time Compressive Tracking 》的个人理解
这是对《Real-Time Compressive Tracking 》论文与作者提供代码的理解要点,是个人的浅显理解。
论文要干嘛
对视频每一帧提取到的n个样本框进行分类,并提取最优值所对应的样本框作为跟踪结果,便能从前到后依次跟踪目标。其中分类器在不断地学习更新使其能对物体目标的轻微改变(比如亮度、形状上不是很大的改变)具有一定的鲁邦性。
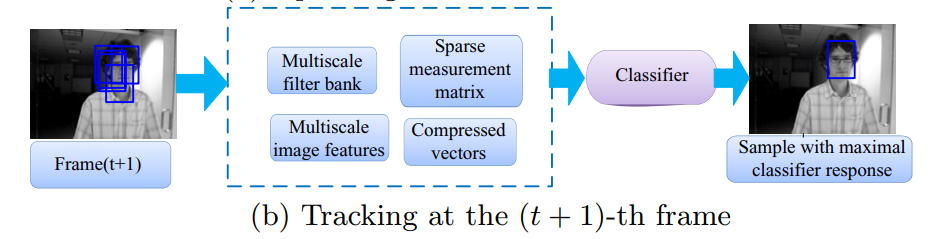
说到底就是想训练一个分类器,识别待跟踪帧中最优的目标位置。然而,特征是什么样子的呢?
作者提取什么特征?
作者提取的是类似Haar-like的特征(haar-like可以百度了解)。作者会对一帧视频的一个样本框的图片内采用不同尺寸的“rectangle
filter ”来提取,然后就组成了一维的特征矩阵。
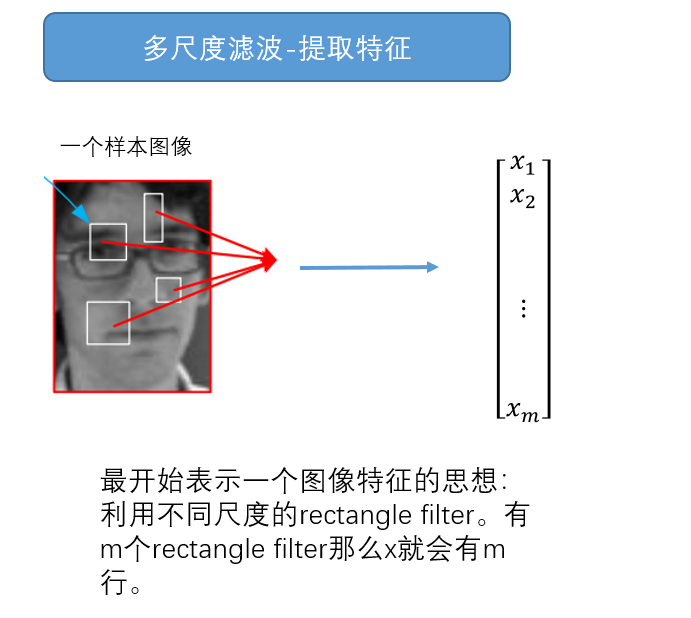
一个个计算特征的小矩形(对应一个个filter),位置随机,大小随机,代码中利用随机均匀分布计算出的,只要在样本图像内。
然而,一个重要的问题来了。小filter的数量太多了,比如作者提到的一个图像的特征数量m可能是“10^6 to 10^10 ”(作者没有给出参考图片尺寸,暂时理解图片的尺寸是正常数据集中的图片尺寸)。
因此,就需要压缩技术了。
压缩思想
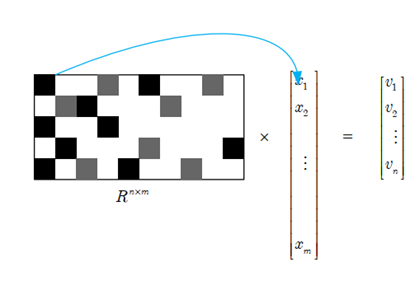
假如利用一个稀疏矩阵R,可以将x的维度m降到v的维度n(m>>n),这里的维度可以理解为数量。假如v可以极大地保留x中的特征信息,那么就可以利用v代表x来进行分类了。
那么,
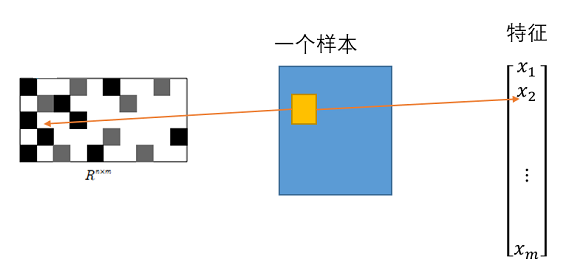
R中的一个元素会和一个样本的一个“特征框”的特征值相乘,因此可以在一开始就记下R中的这个元素和这个框的位置(作者c++代码中不容易理解的部分)。
因此,当R非常稀疏时(0很多),就可以只记录R中非0的元素和其对应的rectangle filters 的位置。这样可以存储很少量的数据。
特征提取了怎么放入分类器呢?

作者指出这些一个图片提取的特征满足gauss分布,因而能利用gauss分布将特征v计算成一个个的概率值。
有了概率,再利用朴素贝叶斯分类器计算分数,分数最高的即是跟踪的最佳结果位置了。
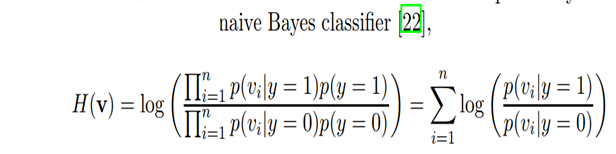
怎么更新分类器呢?

挑选接近目标框的正样本(红),和远离目标框的负样本(绿)。这两种样本,每一个样本框内可以提取特征,计算均值mu与方差sigma,代入下面公式进行更新就行了。
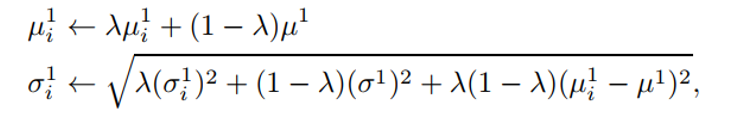
完整更新示意图如下:
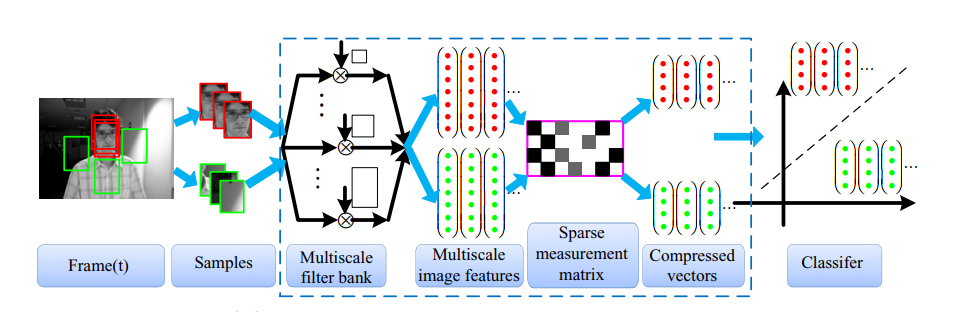
还有一点
一组正样本框或负样本框,若是正的放到一起或负的放到一起。会是什么样子呢?
这对应了C++代码中的特征提取。横着来看是一列一个样本框box,竖着看是一行一种feature。

读者感受
实时感知压缩(《Real-Time Compressive Tracking 》)构思非常巧妙,降低了很多计算量。
但是其并不能解决一些比较明显的遮挡和快速运动等问题。应对遮挡等问题有很多新的研究论文,读者在知网上就找到了很多篇。但是大多数都不能解决快速移动的问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号