
Zookeeper
Zookeeper
Zookeeper是Apache Hadoop项目下的一个子项目,是一个树形目录服务,简称zk;是一个分布式应用程序的协调服务。
作用:
配置管理:从配置中心拉取对应的配置信息供自己的服务使用,运维时只需要配置配置中心
分布式锁:多个机器访问,但是锁(JDK提供的,跟JVM绑定)只在一个机器上有用,引入第三方的锁,防止数据被多台机器同时访问
集群管理:作为注册中心,配合服务提供者和消费者使用
命令操作
数据模型
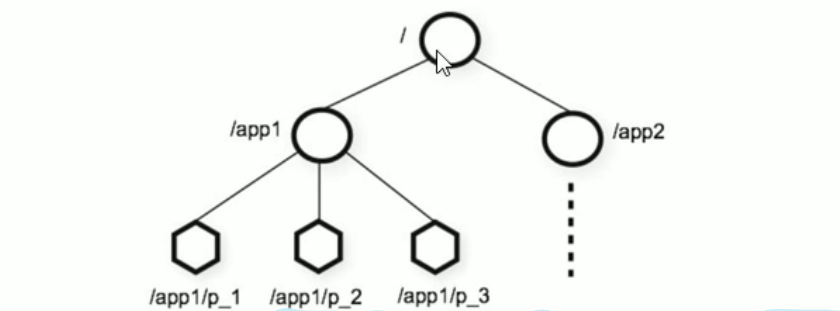
ZooKeeper 是一个树形目录服务,其数据模型和Unix的文件系统目录树很类似,拥有一个层次化结构。
这里面的每一个节点都被称为: ZNode,每个节点上都会保存自己的数据和节点信息。
节点可以拥有子节点,同时也允许少量(1MB)数据存储在该节点之下
节点可以分为四大类:
- PERSISTENT持久化节点
- EPHEMERAL临时节点
-e - PERSISTENT SEQUENTIAL持久化顺序节点
-s - EPHEMERAL SEQUENTIAL临时顺序节点
-es
服务端常用命令
启动Zookeeper服务
./zkServer.sh start
查看Zookeeper服务状态
./zkServer.sh status
停止Zookeeper服务
./zkServer.sh stop
重启Zookeeper服务
./zkServer.sh restart
客户端常用命令
连接
./zkCli.sh -server localhost:2181
./zkCli.sh -server ip:port
quit
查看节点
ls /
ls /zookeeper
#-s:更多信息,id、time、version等
czxid:节点被创建的事务ID
ctime:创建时间
mzxid:最后一次被更新的事务ID
mtime:修改时间
dataversion:数据版本号
aclversion:权限版本号
ephemeralOwner:用于临时节点,代表临时节点的事务ID,如果为持久节点则为0
pzxid:子节点列表最后一次被更新的事务IDdataLength:节点存储的数据的长度
cversion:子节点的版本号
numChildren:当前节点的子节点个数
创建节点
create /app1 lmtxt
获取数据
get /app1
设置
set /app1 lmtxttt
删除
delete /app1 #有子节点就不能删
deleteall /app1 #删除所有
帮助
help
临时节点-e,会话关了节点就没了
create -e /app1
有顺序的节点-s,所有节点共用一个编号
create -s /app1
Java API操作
Curator
Curator是ApacheZooKeeper的Java客户端库
常见的ZooKeeperJava APl:
- 原生JavaAPI
- ZkClient
- Curator
Curator项目的目标是简化ZooKeeper 客户端的使用
官网: http://curator.apache.org/
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>${curator-version}</version>
<exclusions>
<exclusion>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
</exclusion>
</exclusions>
</dependency>
版本要和Zookeeper版本对应
Curator API常用操作
<!--curator-->
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>4.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>4.0.0</version>
</dependency>
- 建立连接
第一种
RetryPolicy retryPolicy = new ExponentialBackoffRetry(3000,10);
//CuratorFramework Client = CuratorFrameworkFactory.newClient(连接字符串(端口和ip),会话超时时间,连接超时时间,重试策略);
CuratorFramework client =
CuratorFrameworkFactory.newClient("1.1.1.1,2.2.2.2",60*1000,15*1000,retryPolicy);
client.start();
第二种
CuratorFramework Client = CuratorFrameworkFactory.builder()
.connectString("1.1.1.1")
.sessionTimeoutMs(60*1000)
.connectionTimeoutMs(15*1000)
.retryPolicy(retryPolicy)
.nameSpace("lm")//加了命名空间后所有的操作默认根目录是lm
.builded();
client.start();
- 创建节点
-
查询节点
-
修改节点
-
删除节点
-
watch事件监听
分布式锁
在我们进行单机应用开发,涉及并发同步的时候,我们往往采用synchronized或者Lock的方式来解决多线程间的代码同步问题;这时多线程的运行都是在同一个JVM之下,没有任何问题。
但当我们的应用是分布式集群工作的情况下,属于多JVM下的工作环境,跨JVM之间已经无法通过多线程的锁解决同步问题。
那么就需要一种更加高级的锁机制,来处理跨机器的进程之间的数据同步问题一一这就是分布式锁。
加一个分布式锁组件
实现
- 基于缓存实现分布式锁
- Redis
- Memcache
- Zookeeper实现
- Curator
- 数据库实现分布式锁
- 悲观锁
- 乐观锁
Zookeeper集群
作为组织者,要搭建集群
Leader选举
- Serverid::服务器ID
- 比如有三台服务器,编号分别是1,2,3。编号越大在选择算法中的权重越大
- Zxid:数据ID
- 服务器中存放的最大数据ID,值越大说明数据越新,在选举算法中数据越新权重越大
- 在Leader选举的过程中,如果某台ZooKeeper获得了超过半数的选票,则此ZooKeeper就可以成为Leader了。
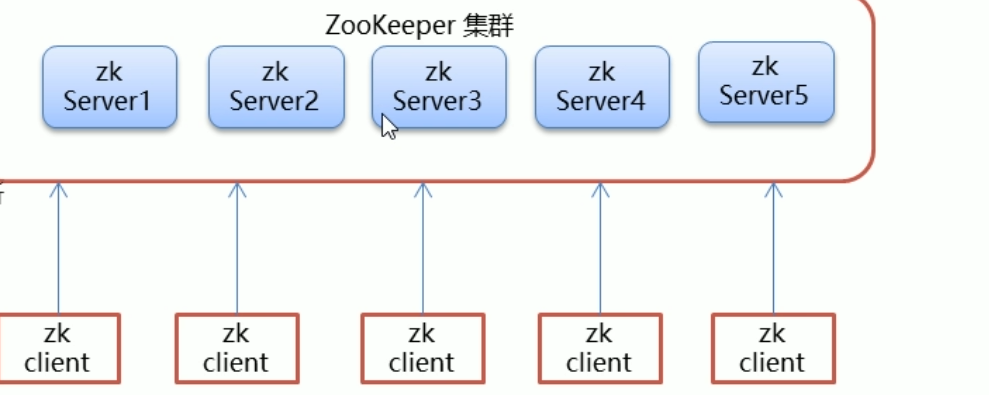
搭建集群--!!!
集群角色
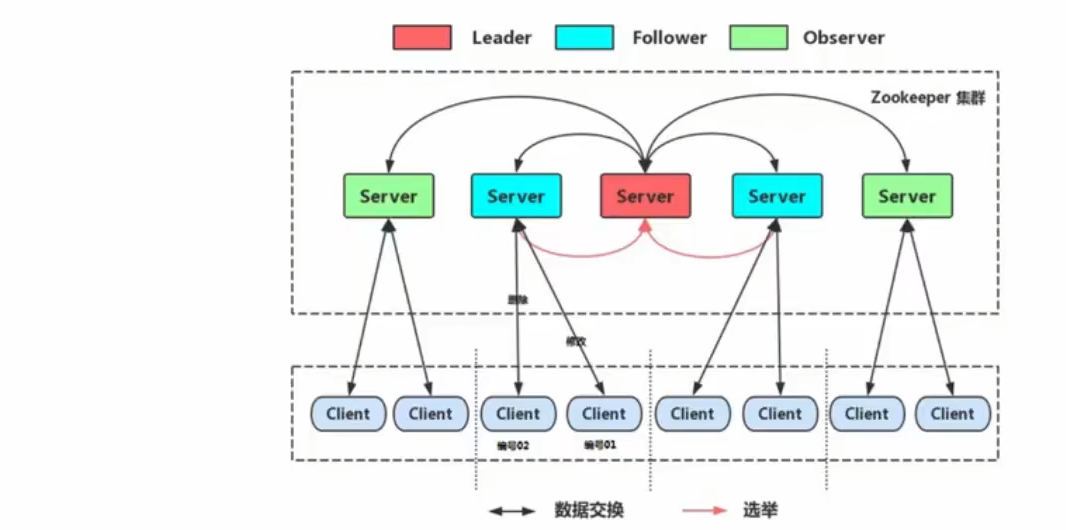
在ZooKeeper集群服中务中有三个角色
- Leader 领导者
- 处理事务请求
- 集群内部各服务器的调度者
- Follower 跟随者
- 处理客户端非事务请求,转发事务请求给Leader服务器
- 参与Leader选举投票
- Observer 观察者
- 处理客户端非事务请求,转发事务请求给Leader服务器
Follower 处理非事物请求的压力比较大,因为查询的请求很多,所以用Observer 分担压力

 浙公网安备 33010602011771号
浙公网安备 33010602011771号