

lightgbm 的简单实践案例
import matplotlib.pylab as plt import seaborn as sns import lightgbm as lgb import pandas as pd import numpy as np data_df = pd.read_csv('train.csv') label = data_df['TARGET'] feature = data_df.drop(['TARGET','ID'],axis=1)
data_test = pd.read_csv('test.csv') data_test_ID = data_test['ID'] data_test_feature = data_test.drop(['ID'],axis=1) feature_all = pd.concat([feature,data_test_feature]) feature_all = pd.get_dummies(feature_all, dummy_na=True, columns=None) feature_train = feature_all.iloc[:len(feature),:] feature_test = feature_all.iloc[len(feature):] # 训练模型 def train_model(data_X,data_y): from sklearn.model_selection import train_test_split X_train,x_test,Y_train,y_test = train_test_split(data_X,data_y,test_size=0.2,random_state=3) # 创建成lgb特征的数据集格式,将使加载更快 lgb_train = lgb.Dataset(X_train, label=Y_train) lgb_eval = lgb.Dataset(x_test, label=y_test, reference=lgb_train) parameters = { 'task': 'train', 'max_depth': 15, 'boosting_type': 'gbdt', 'num_leaves': 20, # 叶子节点数 'n_estimators': 50, 'objective': 'binary', 'metric': 'auc', 'learning_rate': 0.2, 'feature_fraction': 0.7, #小于 1.0, LightGBM 将会在每次迭代中随机选择部分特征. 'bagging_fraction': 1, #类似于 feature_fraction, 但是它将在不进行重采样的情况下随机选择部分数据 'bagging_freq': 3, #bagging 的频率, 0 意味着禁用 bagging. k 意味着每 k 次迭代执行bagging 'lambda_l1': 0.5, 'lambda_l2': 0, 'cat_smooth': 10, #用于分类特征,这可以降低噪声在分类特征中的影响, 尤其是对数据很少的类别 'is_unbalance': False, #适合二分类。这里如果设置为True,评估结果降低3个点 'verbose': 0 } evals_result = {} #记录训练结果所用 gbm_model = lgb.train(parameters, lgb_train, valid_sets=[lgb_train,lgb_eval], num_boost_round=50, #提升迭代的次数 early_stopping_rounds=5, evals_result=evals_result, verbose_eval=10 ) prediction = gbm_model.predict(x_test,num_iteration=gbm_model.best_iteration) from sklearn.metrics import roc_auc_score roc_auc_score = roc_auc_score(y_test, prediction) print(roc_auc_score) return gbm_model,evals_result model,evals_result = train_model(feature_train,label)
#运行结果
[5] training's auc: 0.946343 valid_1's auc: 0.94609 [10] training's auc: 0.950425 valid_1's auc: 0.948894 [15] training's auc: 0.954869 valid_1's auc: 0.950978 [20] training's auc: 0.957274 valid_1's auc: 0.951505 [25] training's auc: 0.958921 valid_1's auc: 0.95193 [30] training's auc: 0.960303 valid_1's auc: 0.951958 Early stopping, best iteration is: [24] training's auc: 0.958674 valid_1's auc: 0.952064
# 可视化训练结果以及模型下的特征重要性 def lgb_importance(): model,evals_result = train_model(feature_train,label) ax = lgb.plot_metric(evals_result, metric='auc') #metric的值与之前的params里面的值对应 plt.title('metric') plt.show() feature_names_pd = pd.DataFrame({'column': feature_train.columns, 'importance': model.feature_importance(), }) plt.figure(figsize=(10, 15)) sns.barplot(x="importance", y="column", data=feature_names_pd.sort_values(by="importance", ascending=False)) #按照importance的进行降排序 plt.title('LightGBM Features') plt.tight_layout() lgb_importance()

训练集和验证集的auc分数对比
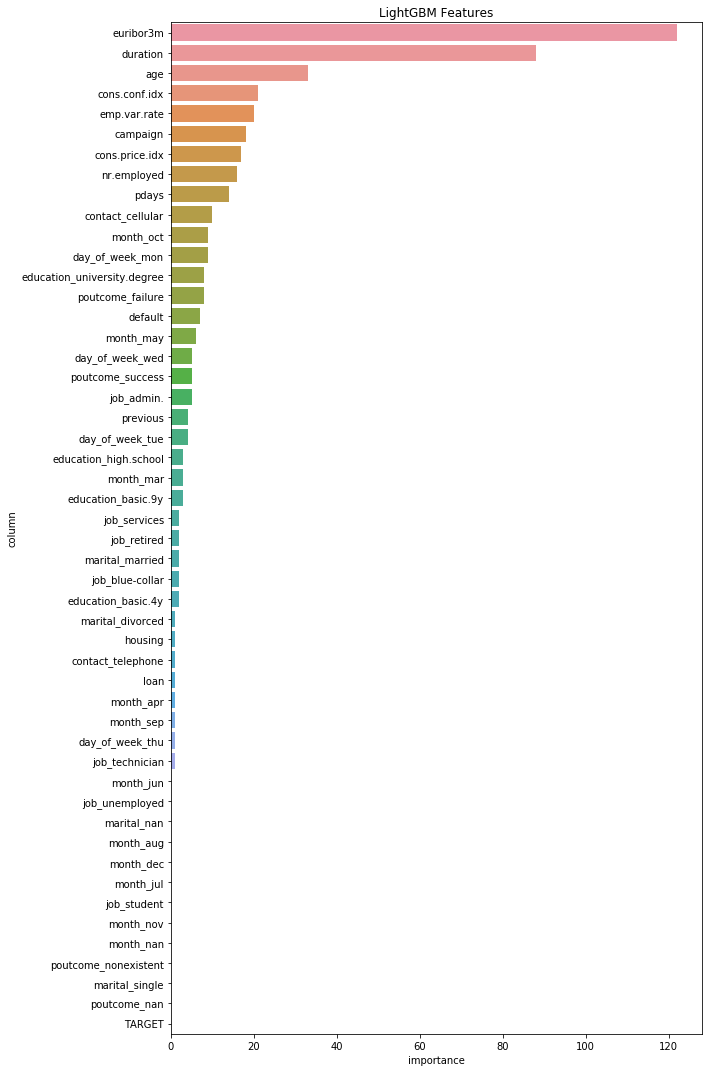
可视化出的所有特征的重要性,可以给前面数据预处理做一定参考

