

KNN算法原理以及代码实现
一、KNN简述
KNN是比较经典的算法,也是是数据挖掘分类技术中最简单的方法之一。
KNN的核心思想很简单:离谁近就是谁。具体解释为如果一个实例在特征空间中的K个最相似(即特征空间中最近邻)的实例中的大多数属于某一个类别,则该实例也属于这个类别。
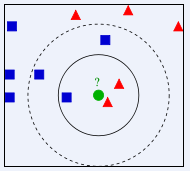
换个说法可能更好理解,比如一个一定范围的平面随机分布着两种颜色的样本点,在这个平面内有个实例点不知道它是什么颜色,因此通过它周边的不同颜色的点分布情况进行推测,假设取K=3,意思是在离这个实例点最近的样本点中去前三个最近的, 然后看这三个当中那种类别占比大,就判断该实例点属于那个类别的,当k=5的时候也一样这样判断,因此k的取值很关键,通常不会超过20。当然,因为每个样本有多个特征,因此实际工作中,这个‘平面’就是三维甚至是多维的,道理是一样的。如图:
二、KNN算法原理
在KNN中,通过计算对象间距离来作为各个对象之间的非相似性指标,避免了对象之间的匹配问题,在这里距离一般使用欧氏距离或曼哈顿距离:

对KNN算法的思想总结一下:就是在训练集中数据和标签已知的情况下,输入测试数据,将测试数据的特征与训练集中对应的特征进行相互比较,找到训练集中与之最为相似的前K个数据,则该测试数据对应的类别就是K个数据中出现次数最多的那个分类,其算法的描述为:
1)计算测试数据与各个训练数据之间的距离;
2)按照距离的递增关系进行排序;
3)选取距离最小的K个点;
4)确定前K个点所在类别的出现频率;
5)返回前K个点中出现频率最高的类别作为测试数据的预测分类。
三、KNN算法优缺点以及算法改进
优缺点:
1、简单,易于理解,是一个天然的多分类器;
2、不需要庞大的样本数据也可以完成一个简单的分类;
3、不需要训练和求解参数(既是优点也是缺点);
4、数据量大的时候,计算量也非常大(样本多,特征多);
5、不平衡样本处理能力差;
6、并没有学习和优化的过程,严格来说不算是机器学习。
改进:
进行加权平均,离得近的样本给予更大的权重,离得远的样本使其权重变小。
四、KNN代码实现
import numpy as np import pandas as pd import matplotlib.pylab as plt data_=pd.read_csv('vehicle.csv') print(data_) feature=np.array(data_.iloc[:,0:2]) # 将参数与特征进行分离,返回数据类型为数组,这里只拿去前两列 #print(feature) labels = data_['label'].tolist() # 将'label'标签提取出来转换为列表类型,方便后续使用 #print(labels) # 数据可视化 plt.scatter(data_['length'][data_['label']=='car'],data_['width'][data_['label']=='car'],c='y') #先取length的数值,里面有car和truck的长度,再单独取label那一行为car的值 plt.scatter(data_['length'][data_['label']=='truck'],data_['width'][data_['label']=='truck'],c='r') #先取width的数值,里面有car和truck的长度,再单独取label那一行为truck的值 #print(data_['length']) #print(plt.show()) test = [4.7,2.1] # 待测样本 numSamples = data_.shape[0] # 读取矩阵的长度,这里是读取第一维的长度# 运行结果:150 diff_= np.tile(test,(numSamples,1)) #这里表示test列表竖向重复150次,横向重复1一次,组成一个素组 # numpy.tile(A,B)函数:A=[4.7,2.1],B=(3,4),意思是列表A在行方向(从上到下)重复3次,在列放心(从左到右)重复4次 diff = diff_-feature # 利用这里的实验值和样本空间里的每一组数据进行相减 squreDiff = diff**2 # 将差值进行平方 squreDist = np.sum(squreDiff,axis=1) # 每一列横向求和,最后返回一维数组 distance = squreDist ** 0.5 sorteDisIndices = np.argsort(distance) # 排序 k=9 # k个最近邻 classCount = {} # 字典或者列表的数据类型需要声明 label_count=[] # 字典或者列表的数据类型需要声明 for i in range(k): voteLabel = labels[sorteDisIndices[i]] classCount[voteLabel] = classCount.get(voteLabel,0) + 1 label_count.append(voteLabel) from collections import Counter word_counts = Counter(label_count) top = word_counts.most_common(1) # 返回数量最多的值以及对应的标签 #print(word_counts) #print(top) # 利用sklearn进行实现 import numpy as np import pandas as pd import matplotlib.pylab as plt
data_=pd.read_csv('vehicle.csv') feature=np.array(data_.iloc[:,0:2]) # 将参数与特征进行分离,返回数据类型为数组,这里只拿去前两列 labels = data_['label'].tolist() # 将'label'标签提取出来转换为列表类型,方便后续使用 from sklearn.model_selection import train_test_split feautre_train,feautre_test,label_train,label_test=train_test_split(feature,labels,test_size=0.2) # 指出训练集的标签和特征以及测试集的标签和特征,0.2为参数,对测试集以及训练集按照2:8进行划分 from sklearn.neighbors import KNeighborsClassifier model=KNeighborsClassifier(n_neighbors= 9) model.fit(feautre_train,label_train) # 现在只需要传入训练集的数据 prediction=model.predict(feautre_test) #print(prediction) labels=['car','truck'] classes=['car', 'truck'] from sklearn.metrics import classification_report result_=classification_report(label_test,prediction,target_names = classes,labels=labels,digits=4) # target_names:类别;digits:int,输出浮点值的位数 print(result_)

