

RDD中的依赖关系
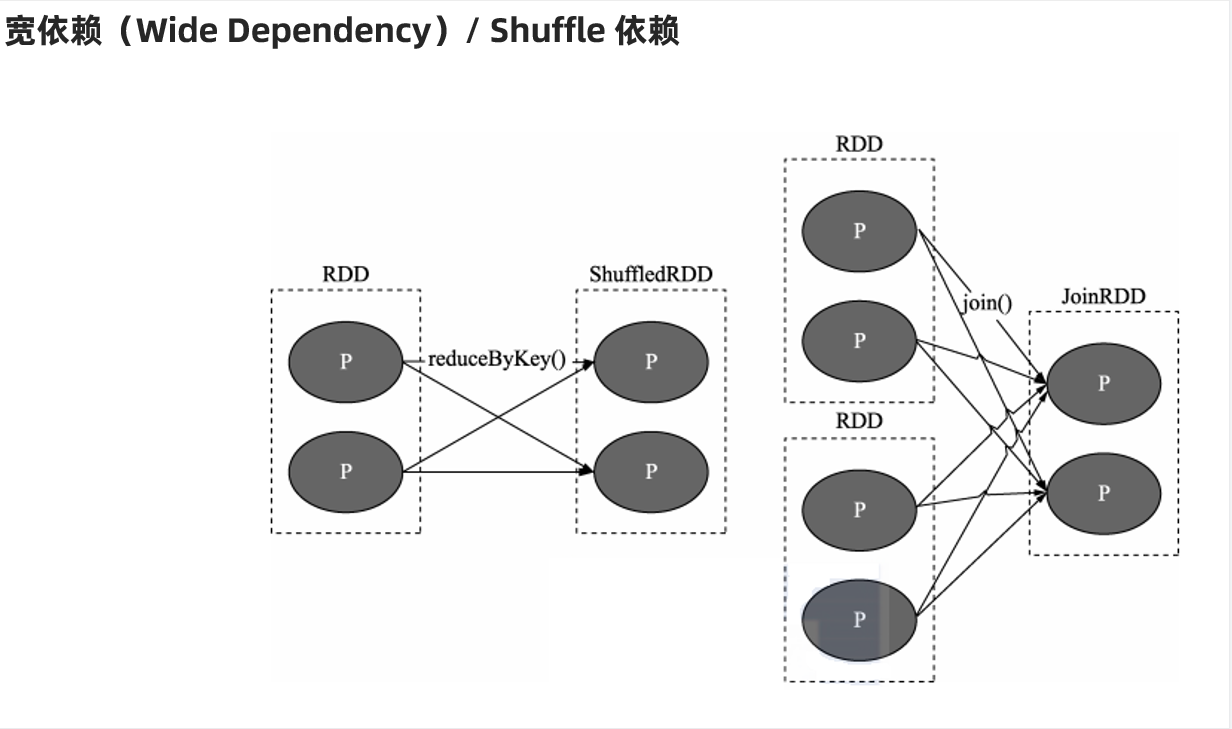
宽依赖
1.有shuffle
2.父RDD的一个分区会被子RDD的多个分区所依赖(父一对多)
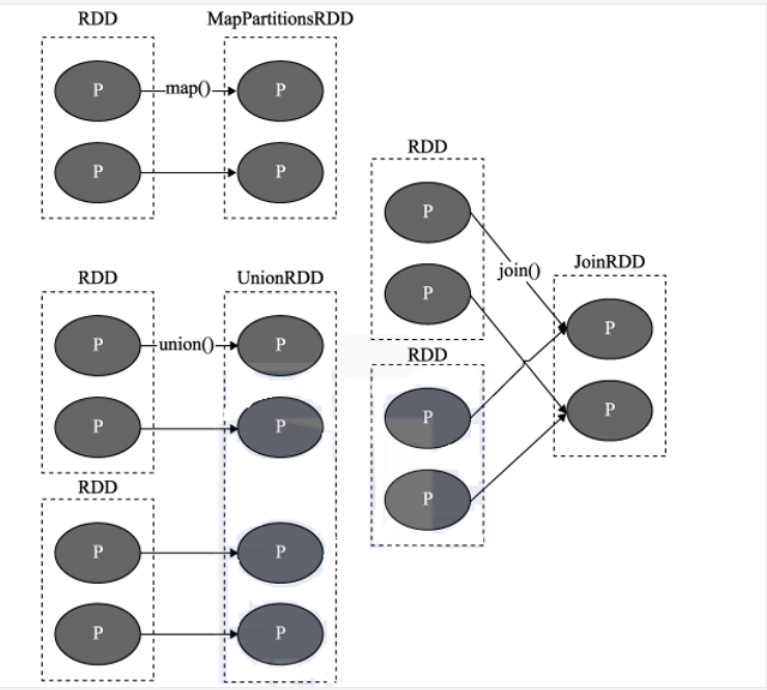
窄依赖
1.没有shuffle
2.父RDD的一个分区只会被子RDD的1个分区所依赖(一对一)
划分宽依赖和窄依赖的原因
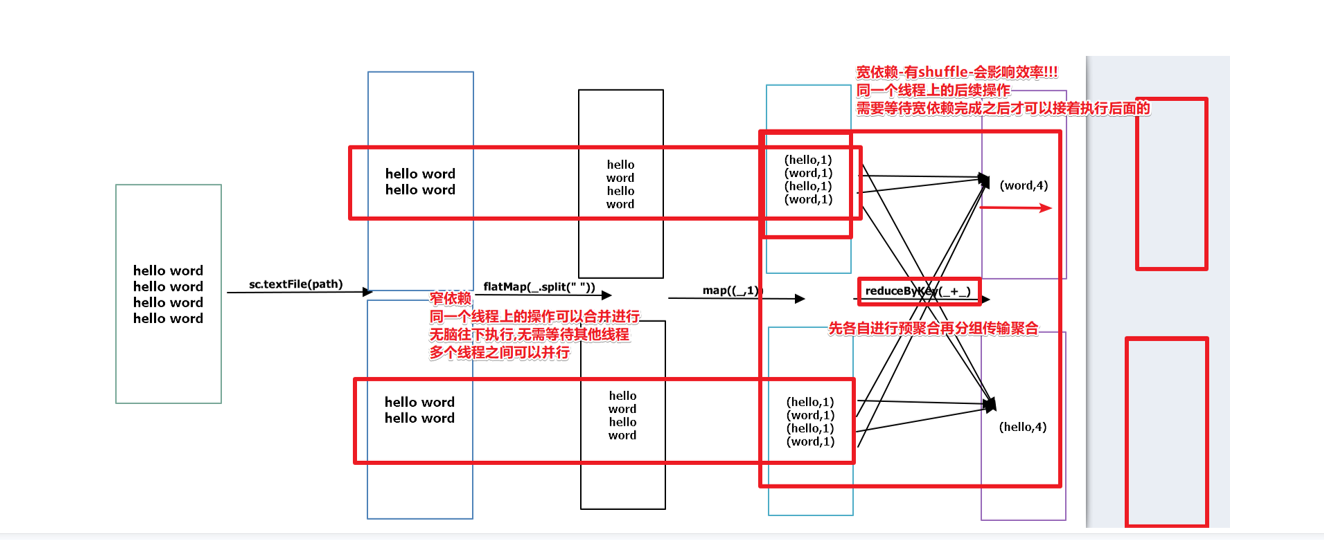
窄依赖:Spark可以对窄依赖进行优化:合并操作,形成pipeline(管道),同一个管道中的各个操作可以由同一个线程执行完,
且如果有一个分区数据丢失,只需要从父RDD的对应个分区重新计算即可,不需要重新计算整个任务,提高容错。
宽依赖:Spark可以根据宽依赖进行state阶段划分,同一个stage阶段中的都是窄依赖,可以对该阶段内的窄依赖优化
总结:
窄依赖: 并行化+容错
宽依赖: 进行阶段划分(shuffle后的阶段需要等待shuffle前的阶段计算完才能执行)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号