

RDD的缓存
RDD的缓存/持久化
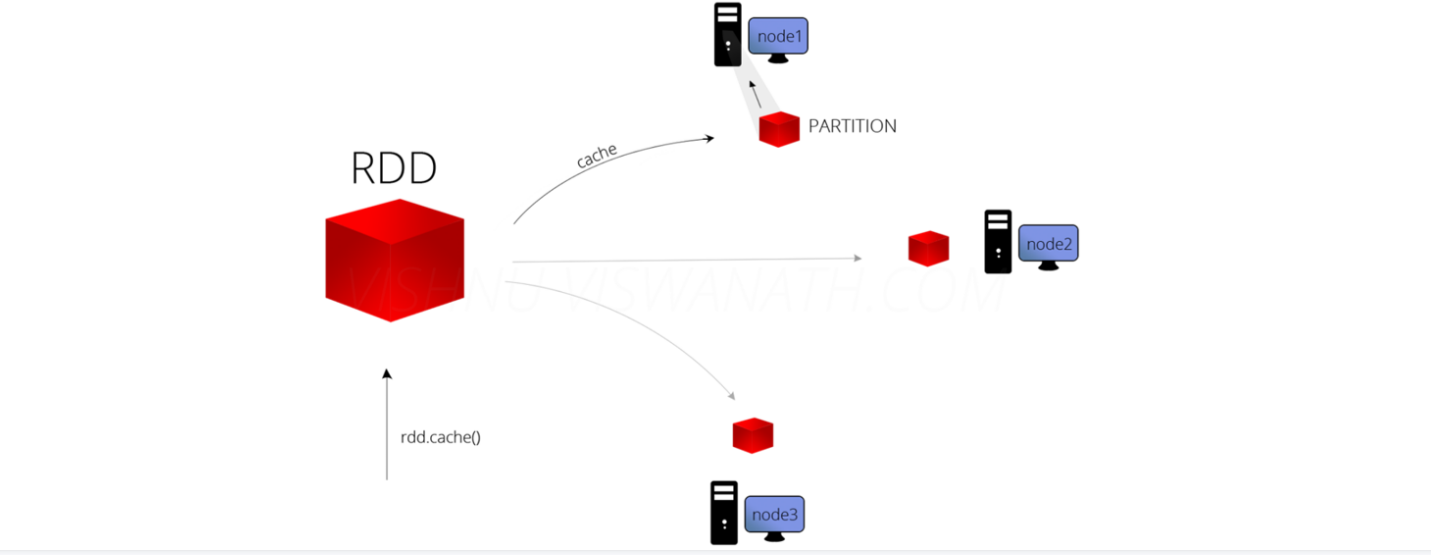
缓存解决的问题
缓存解决什么问题?-解决的是热点数据频繁访问的效率问题
在Spark开发中某些RDD的计算或转换可能会比较耗费时间,
如果这些RDD后续还会频繁的被使用到,那么可以将这些RDD进行持久化/缓存,
这样下次再使用到的时候就不用再重新计算了,提高了程序运行的效率。
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel
import org.apache.spark.{SparkConf, SparkContext}
object Demo16Cache {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("****").setMaster("local")
val sc: SparkContext = new SparkContext(conf)
val linesRDD: RDD[String] = sc.textFile("spark/data/words.txt")
//加入缓存的三种方式
//方式一
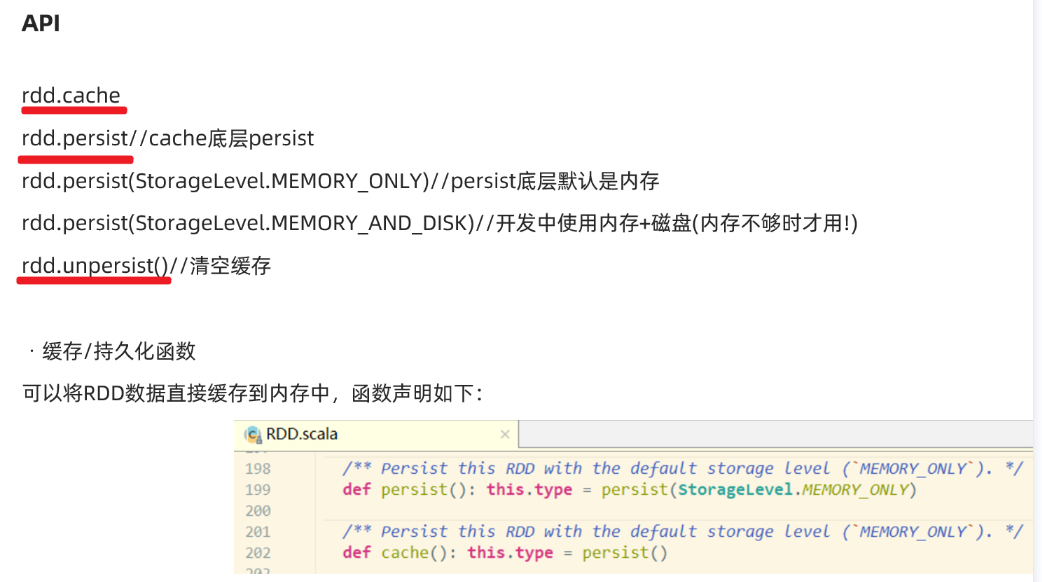
linesRDD.cache()//将常用的RDD放入缓存中,增加效率
//StorageLevel.MEMORY_ONLY 默认只放在缓存中
//方式二
//linesRDD.persist()
//def persist(): this.type = persist(StorageLevel.MEMORY_ONLY)
//指定缓存存储方式
linesRDD.persist(StorageLevel.MEMORY_AND_DISK)
/**
* 缓存的存储方式:推荐使用MEMORY_AND_DISK
* object StorageLevel {
* val NONE = new StorageLevel(false, false, false, false)
* val DISK_ONLY = new StorageLevel(true, false, false, false)
* val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)
* val MEMORY_ONLY = new StorageLevel(false, true, false, true)
* val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)
* val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
* val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)
* val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
* val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
* val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
* val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
* val OFF_HEAP = new StorageLevel(true, true, true, false, 1)
*/
linesRDD.flatMap(word => word)
.groupBy(word => word)
.map(l => {
val word = l._1
val cnt = l._2.size
word + "," + cnt
}).foreach(println)
val wordRDD: Unit = linesRDD.map(word => word)
.foreach(println)
//释放缓存
linesRDD.unpersist()
}
}
RDD中的checkpoint
RDD数据可以持久化到内存中,虽然是快速的,但是不可靠
也可以把数据放在磁盘上,也并不是完全可靠的,
我们可以把缓存数据放到我的HDFS中,借助HDFS的高可靠,高可用以及高容错来保证数据安全
sc.setCheckpointDir(HDFS路径)//设置checkpoint路径,开发中一般设置为HDFS的目录
RDD.checkpoint//对计算复杂且后续会被频繁使用的RDD进行checkpoint
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel
object Demo17CheckPoint {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("spark").setMaster("local")
val sc: SparkContext = new SparkContext(conf)
val linesRDD: RDD[String] = sc.textFile("spark/data/words.txt")
/**
* RDD数据可以持久化到内存中,虽然是快速的,但是不可靠
* 也可以把数据放在磁盘上,也并不是完全可靠的
* 我们可以把缓存数据放到我的HDFS中,借助HDFS的高可靠,高可用以及高容错来保证数据安全
*
*/
//设置HDFS的目录
sc.setCheckpointDir("spark/data/checkPoint")
//对需要缓存的RDD进行checkPoint
linesRDD.checkpoint()
linesRDD.flatMap(word => word)
.groupBy(word => word)
.map(l => {
val word = l._1
val cnt = l._2.size
word + "," + cnt
}).foreach(println)
val wordRDD: Unit = linesRDD.map(word => word)
.foreach(println)
}
}
RDD中的缓存/持久化与checkpoint的区别
1.存储位置
缓存/持久化数据存默认存在内存, 一般设置为内存+磁盘(普通磁盘)
Checkpoint检查点:一般存储在HDFS
2.功能
缓存/持久化:保证数据后续使用的效率高
Checkpoint检查点:保证数据安全/也能一定程度上提高效率
3.对于依赖关系:
缓存/持久化:保留了RDD间的依赖关系
Checkpoint检查点:不保留RDD间的依赖关系
4.开发中如何使用?
对于计算复杂且后续会被频繁使用的RDD先进行缓存/持久化,再进行Checkpoint

 浙公网安备 33010602011771号
浙公网安备 33010602011771号