
Kafka
Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。 对于像Hadoop的一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群机来提供实时的消费。
Kafka是一种高吞吐量的分布式发布订阅消息系统,有如下特性: 通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能。(文件追加的方式写入数据,过期的数据定期删除) 高吞吐量:即使是非常普通的硬件Kafka也可以支持每秒数百万的消息 支持通过Kafka服务器和消费机集群来分区消息 支持Hadoop并行数据加载
二、使用场景
1、Messaging
对于一些常规的消息系统,kafka是个不错的选择;partitons/replication和容错,可以使kafka具有良好的扩展性和性能优势.不过到目前为止,我们应该很清楚认识到,kafka并没有提供JMS中的"事务性""消息传输担保(消息确认机制)""消息分组"等企业级特性;kafka只能使用作为"常规"的消息系统,在一定程度上,尚未确保消息的发送与接收绝对可靠(比如,消息重发,消息发送丢失等)
2、Websit activity tracking
kafka可以作为"网站活性跟踪"的最佳工具;可以将网页/用户操作等信息发送到kafka中.并实时监控,或者离线统计分析等
3、Log Aggregation
kafka的特性决定它非常适合作为"日志收集中心";application可以将操作日志"批量""异步"的发送到kafka集群中,而不是保存在本地或者DB中;kafka可以批量提交消息/压缩消息等,这对producer端而言,几乎感觉不到性能的开支.此时consumer端可以使hadoop等其他系统化的存储和分析系统.
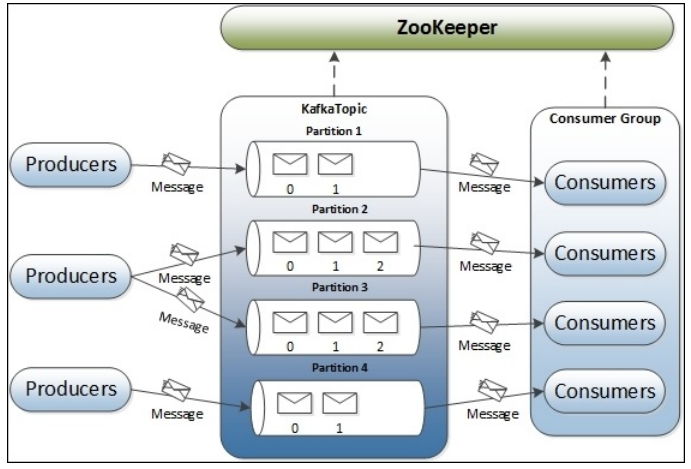
四、Kafka中的术语解释
在深入理解Kafka之前,先介绍一下Kafka中的术语。下图展示了Kafka的相关术语以及之间的关系:

上图中一个topic配置了3个partition。Partition1有两个offset:0和1。Partition2有4个offset。Partition3有1个offset。副本的id和副本所在的机器的id恰好相同。
如果一个topic的副本数为3,那么Kafka将在集群中为每个partition创建3个相同的副本。集群中的每个broker存储一个或多个partition。多个producer和consumer可同时生产和消费数据。
4.2 broker
Kafka 集群包含一个或多个服务器,服务器节点称为broker。
broker存储topic的数据。如果某topic有N个partition,集群有N个broker,那么每个broker存储该topic的一个partition。
如果某topic有N个partition,集群有(N+M)个broker,那么其中有N个broker存储该topic的一个partition,剩下的M个broker不存储该topic的partition数据。
如果某topic有N个partition,集群中broker数目少于N个,那么一个broker存储该topic的一个或多个partition。在实际生产环境中,尽量避免这种情况的发生,这种情况容易导致Kafka集群数据不均衡。
4.3 Topic
顾名思义Topics是一些主题的集合,更通俗的说Topic就像一个消息队列,生产者可以向其写入消息,消费者可以从中读取消息,一个Topic支持多个生产者或消费者同时订阅它,所以其扩展性很好。Topic又可以由一个或多个partition(分区)组成,比如下图:
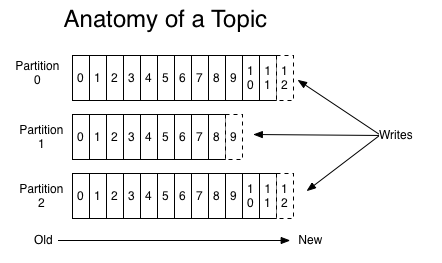
其中每个partition中的消息是有序的,但相互之间的顺序就不能保证了,若Topic有多个partition,生产者的消息可以指定或者由系统根据算法分配到指定分区,若你需要所有消息都是有序的,那么你最好只用一个分区。另外partition支持消息位移读取,消息位移有消费者自身管理,比如下图:

由上图可以看出,不同消费者对同一分区的消息读取互不干扰,消费者可以通过设置消息位移(offset)来控制自己想要获取的数据,比如可以从头读取,最新数据读取,重读读取等功能
4.3 Partition
topic中的数据分割为一个或多个partition。每个topic至少有一个partition。每个partition中的数据使用多个segment文件存储。partition中的数据是有序的,不同partition间的数据丢失了数据的顺序。如果topic有多个partition,消费数据时就不能保证数据的顺序。在需要严格保证消息的消费顺序的场景下,需要将partition数目设为1。
4.4 Producer
生产者即数据的发布者,该角色将消息发布到Kafka的topic中。broker接收到生产者发送的消息后,broker将该消息追加到当前用于追加数据的segment文件中。生产者发送的消息,存储到一个partition中,生产者也可以指定数据存储的partition。
4.5 Consumer
消费者可以从broker中读取数据。消费者可以消费多个topic中的数据。
4.6 Consumer Group/Consumers
每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)。
A、Consumers
Consumers是一群消费者的集合,可以称之为消费者组,是一种更高层次的的抽象,向Topic订阅消费消息的单位是Consumers,当然它其中也可以只有一个消费者(consumer)。下面是关于consumer的两条原则:
-
假如所有消费者都在同一个消费者组中,那么它们将协同消费订阅Topic的部分消息(根据分区与消费者的数量分配),保存负载平衡;
-
假如所有消费者都在不同的消费者组中,并且订阅了同个Topic,那么它们将可以消费Topic的所有消息;
下面是一个简单的例子,帮助大家理解:

从图中我们可以看出,首先订阅Topic的单位是消费者组,另外我们发现Topic中的消息根据一定规则将消息推送给具体消费者,主要原则如下:
-
若消费者数小于partition数,且消费者数为一个,那么它就消费所有消息;
-
若消费者数小于partition数,假设消费者数为N,partition数为M,那么每个消费者能消费的分区数为M/N或M/N+1;
-
若消费者数等于partition数,那么每个消费者都会均等分配到一个分区的消息;
-
若消费者数大于partition数,则将会出现部分消费者得不到消息分区,出现空闲的情况;
总的来说,Kafka会根据消费者组的情况均衡分配消息,比如有消息的实例宕机,亦或者有新的消费者加入等情况。
结论: 在进行高吞吐量的架构下面,最好保持Kafka集群中的分区数和消费组中消费者个数相同
4.7 Leader
每个partition有多个副本,其中有且仅有一个作为Leader,Leader是当前负责数据的读写的partition。
4.8 Follower(ISR)
Follower跟随Leader,所有写请求都通过Leader路由,数据变更会广播给所有Follower,Follower与Leader保持数据同步。如果Leader失效,则从Follower中选举出一个新的Leader。当Follower与Leader挂掉、卡住或者同步太慢,leader会把这个follower从“in sync replicas”(ISR)列表中删除,重新创建一个Follower。
★ Leader 负责读和写, follower这负责数据同步和备份。
