Python中库的管理/OS/time/json实战
1.标准库:安装python解释器后,直接自带的
os,sys,json,csv,time,datatime,hashib
2.第三方的库:全球顶级程序员编写的(有专门的网站可以下载)
安装方式:
1)在线安装
pip3 install 库的名称
pip3 uninstall 库的名称
pip3 install -u 库的名称
2)离线安装
3)常用的第三方库
selenium:UI测试框架
pip3 install selenium √
Appium:移动UI测试框架
requests:接口测试框架
pip3 install requests √
pymsql:操作mySQL
pip3 install pymysql √
xlrd:操作Excel文件
pip3 install xlrd √
Django:全栈WEB框架
flask:轻量级WEB框架
fast:异步WEB框架
Pytest:单元测试框架
pip3 install pytest √
3.自定义的库:自己编写的python文件
针对路径的处理
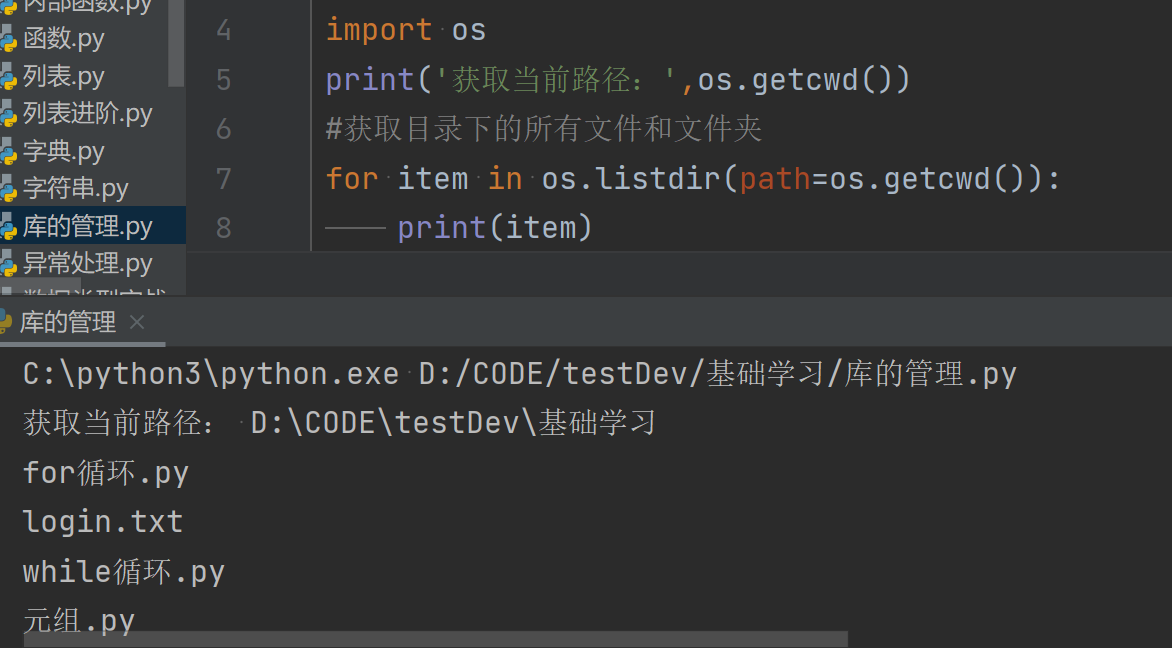
1.获取当前路径:print(os.getcwd())
2.获取目录下的所有文件和文件夹:
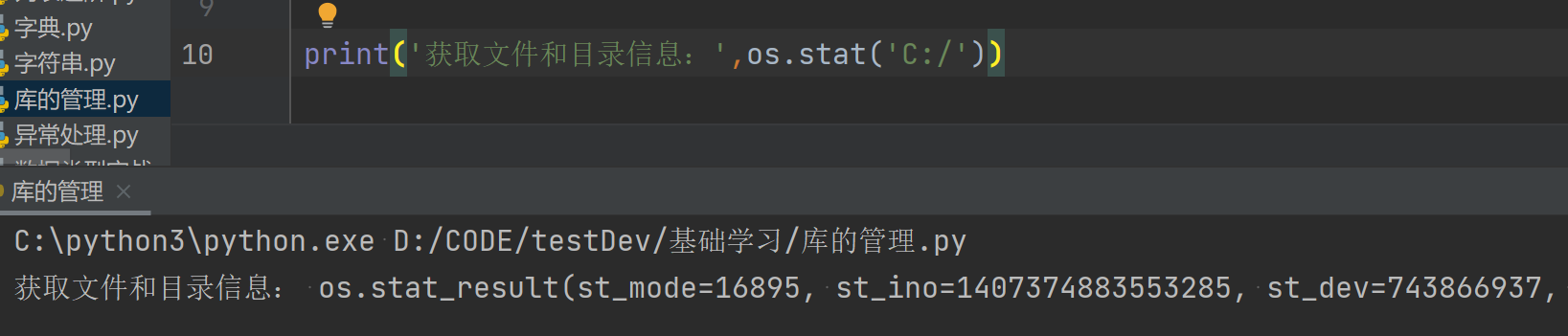
3.获取文件和目录信息:print(os.stat('C:/'))
import os #导入os print('获取当前路径:',os.getcwd())
# #获取目录下的所有文件和文件夹
for item in os.listdir(path=os.getcwd()):
print(item)
print('获取文件和目录信息:',os.stat('C:/'))
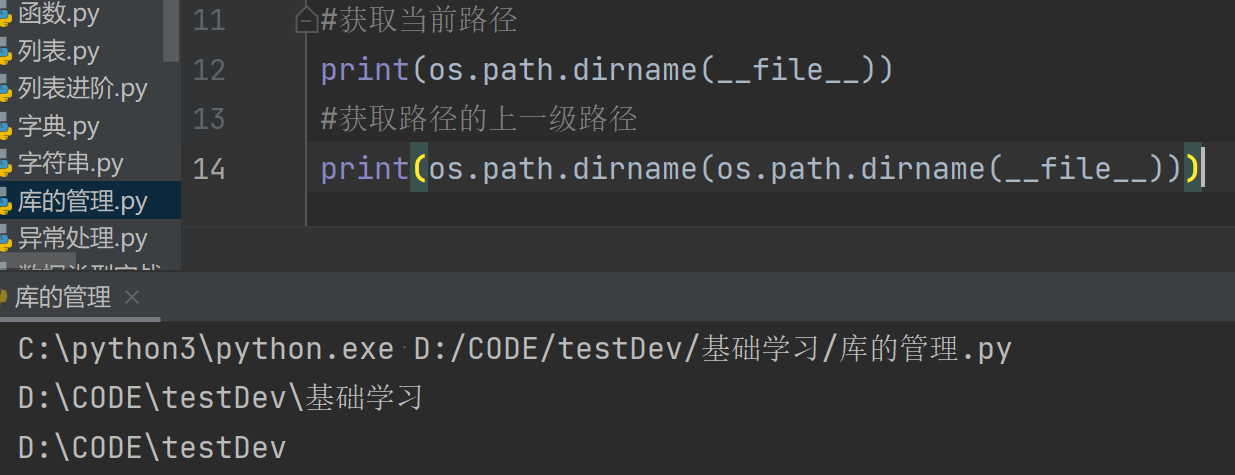
4.获取当前路径(最常使用这种方法)
#获取当前路径
print(os.path.dirname(__file__))
#获取路径的上一级路径
print(os.path.dirname(os.path.dirname(__file__)))
实战:
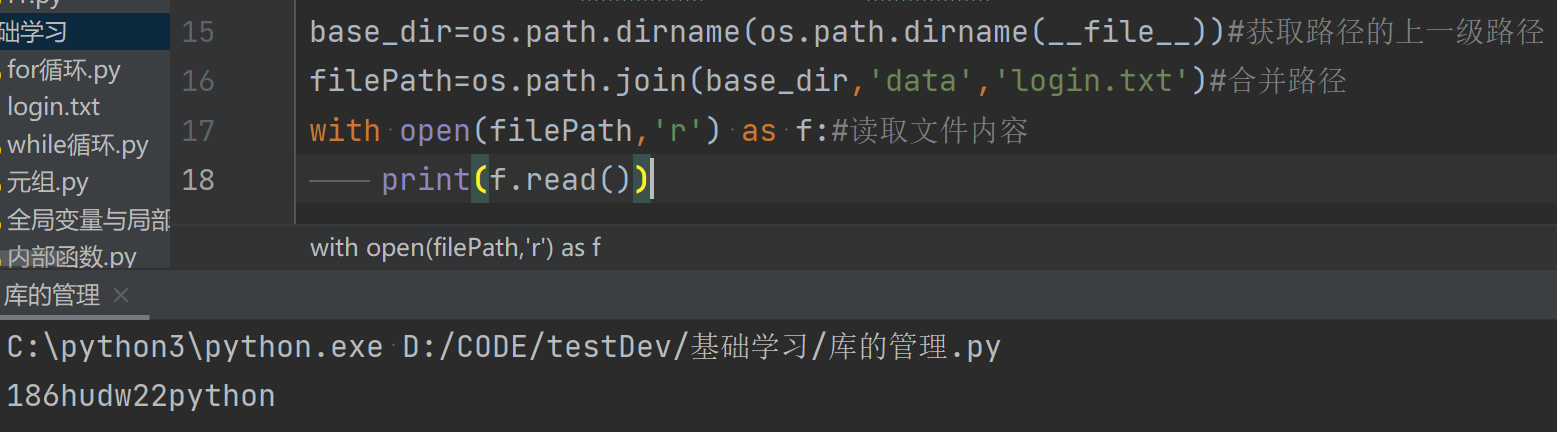
需求:新建一个data文件夹,下建一个login.txt记事本,里面输入内容。从当前路径读取login.txt里面的内容
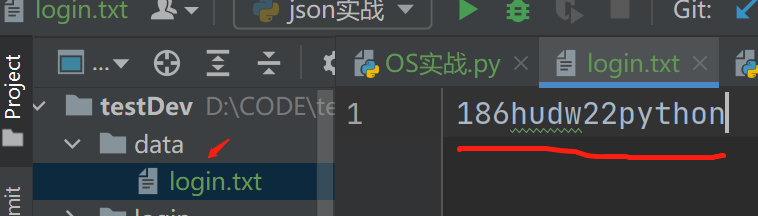
base_dir=os.path.dirname(os.path.dirname(__file__))#获取路径的上一级路径 filePath=os.path.join(base_dir,'data','login.txt')#合并路径 with open(filePath,'r') as f:#读取文件内容 print(f.read())
6.获取操作系统:
7.获取环境变量:
8.判断文件是否存在:
print('获取操作系统',os.name) print('环境变量:',os.environ) print('判断文件是否存在:',os.path.exists(filePath))

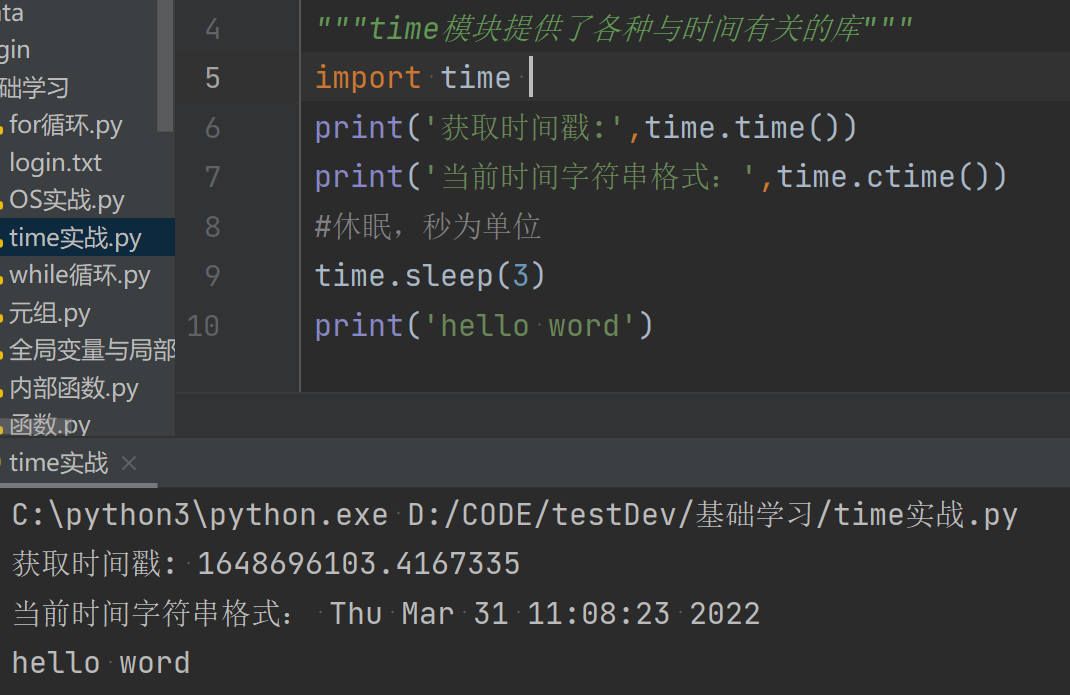
import time print('获取时间戳:',time.time()) print('当前时间字符串格式:',time.ctime()) #休眠,秒为单位 time.sleep(3) #3秒后输出 print('hello word')
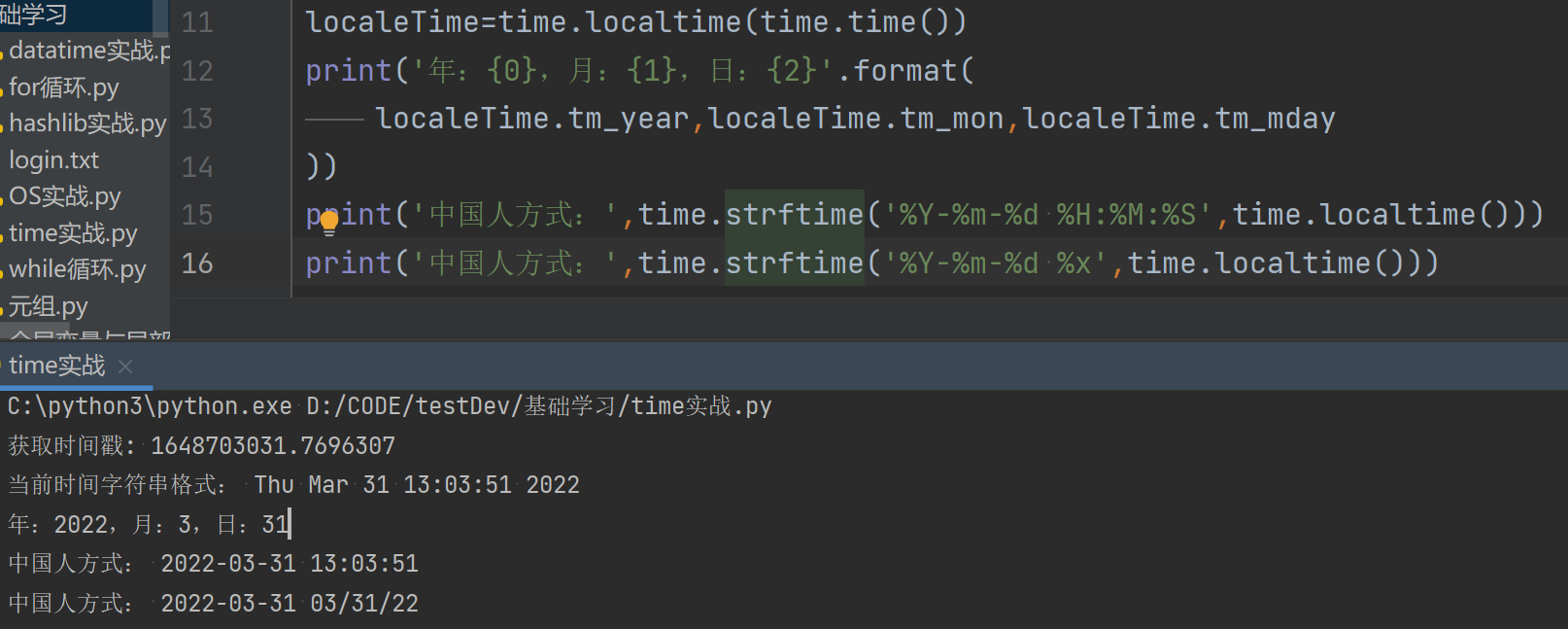
3.输出当前时间
localeTime=time.localtime(time.time()) print('年:{0},月:{1},日:{2}'.format( localeTime.tm_year,localeTime.tm_mon,localeTime.tm_mday )) print('中国人方式:',time.strftime('%Y-%m-%d %H:%M:%S',time.localtime())) #获取时间精确到时分秒 print('中国人方式:',time.strftime('%Y-%m-%d %x',time.localtime())) #只获取年月日
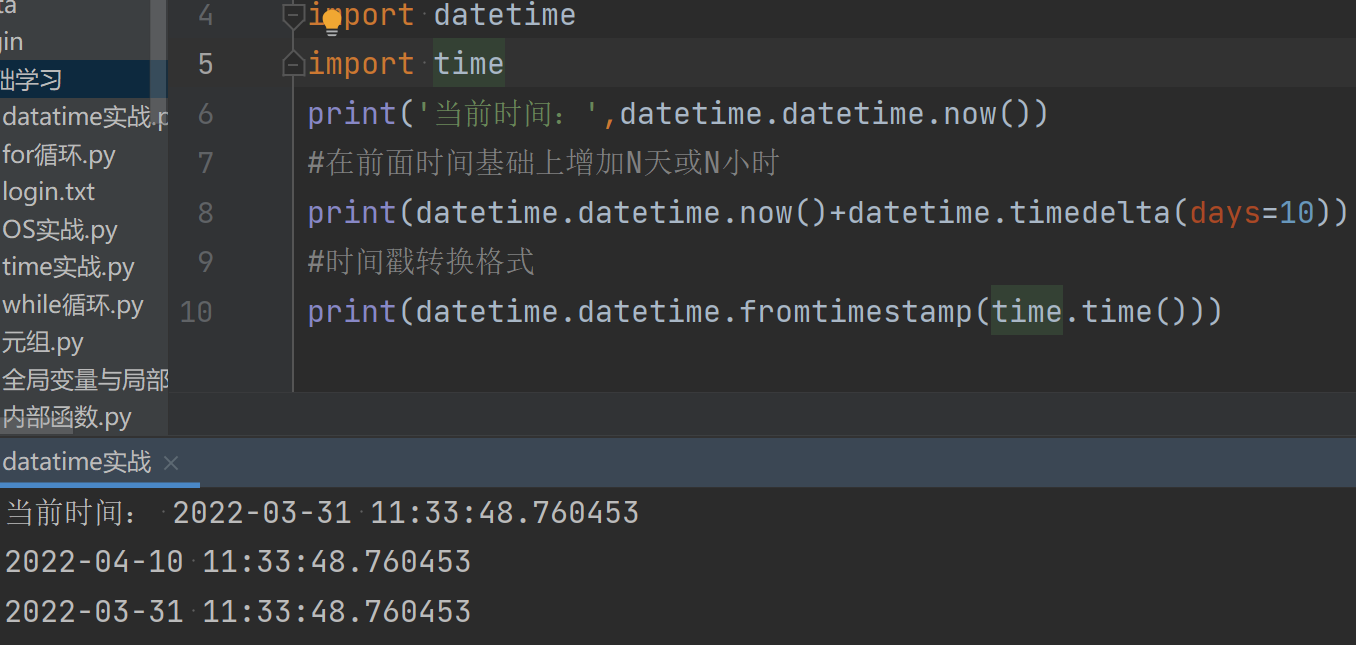
2)相比time的模块,datetime也是表示时间的,但是会更加直观
1.获取当前时间:print(datetime.datetime.now()
2.在前面时间基础上增加N天或N小时:print(datetime.datetime.now()+datetime.timedelta(days=n))
3.时间戳转换格式:print(datetime.datetime.fromtimestamp(time.time()))
print('当前时间:',datetime.datetime.now()) #在前面时间基础上增加N天或N小时 print(datetime.datetime.now()+datetime.timedelta(days=10)) #时间戳转换格式 print(datetime.datetime.fromtimestamp(time.time()))
hashlib实战
open API 开放平台
加密方式:
1.对请求参数(字典)进行排序
2.key=value&key=value
3.进行md5的加密,生成密钥
hashlib实战
import hashlib #做网络爬虫的urllib from urllib import parse import time def sign(): dict1={"name":"lm","age":20,"work":"testDev",'time':time.time()} #对请求参数进行ascill码排序 data=dict(sorted(dict1.items(),key=lambda item:item[0])) #把请求参数处理成Key=value&key1=value1&key2=value2 data=parse.urlencode(data) #进行md5的加密 m=hashlib.md5() #要把字符串的数据处理成bytes数据类型 m.update(data.encode('utf-8')) return m.hexdigest() print(sign())

序列化:把内存⾥的数据类型转为字符串的数据类型,使能够存储到硬盘或通过⽹络传输到远程,因为硬盘或者⽹络传输时只接受bytes的数据类型。简单的说就是把Python的数据类型(字典,元组,列表)转为str的数据类型过程。
反序列化:就是str的数据类型转为Python对象的过程。
| 函数 | 说明 |
|---|---|
| dumps | 对象序列化为bytes对象 |
| dump | 对象序列化到文件对象,就是存入文件 |
| loads | 从bytes对象反序列化 |
| load | 对象反序列化,从文件读取数据 |
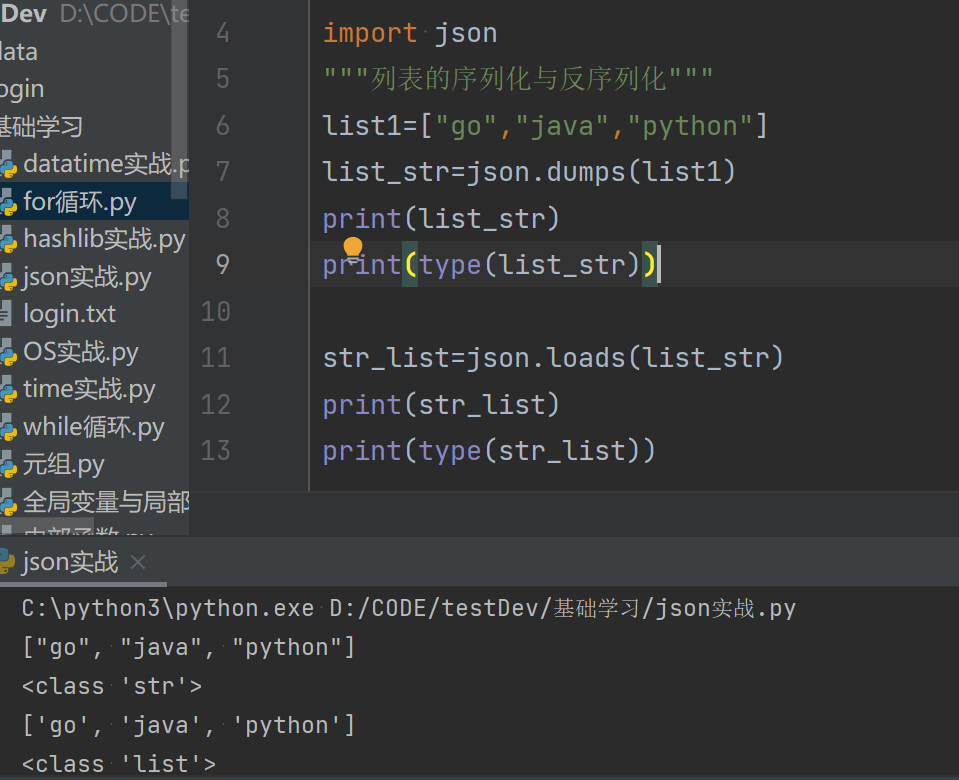
1.列表的序列化与反序列化(列表的序列化之后是str,反序列化之后还是list)
import json """列表的序列化与反序列化""" list1=["go","java","python"] list_str=json.dumps(list1) print(list_str) print(type(list_str))
str_list=json.loads(list_str) print(str_list) print(type(str_list))
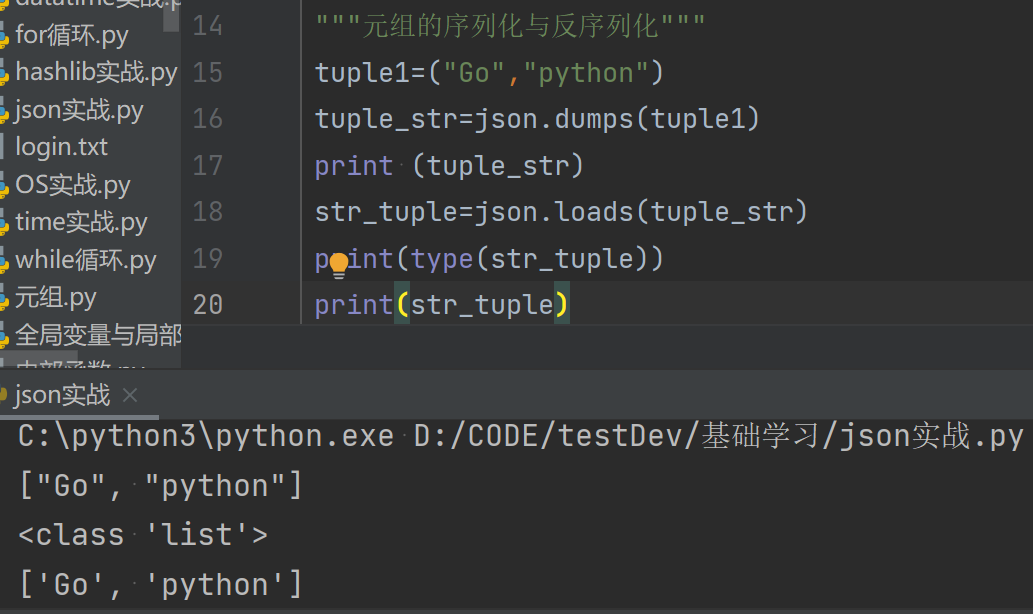
2.元组的序列化与反序列化(元组序列化之后是str,反序列化之后是list)
import json """列表的序列化与反序列化""" list1=["go","java","python"] list_str=json.dumps(list1) print(list_str) print(type(list_str)) str_list=json.loads(list_str) print(str_list) print(type(str_list))
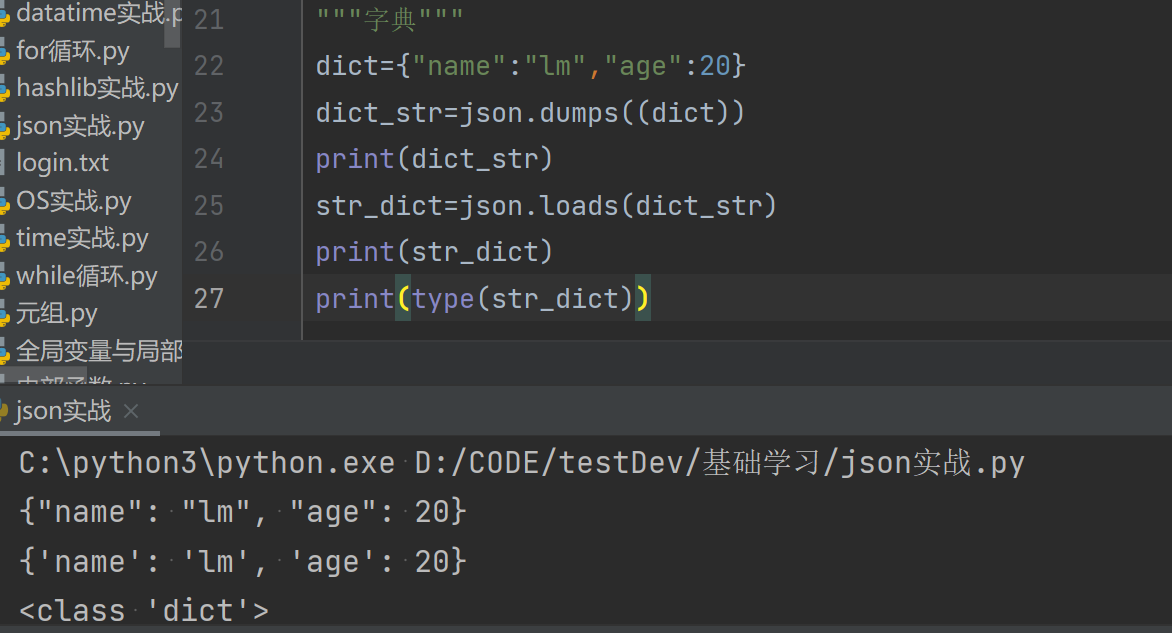
3.字典的序列化与反序列化(字典序列化之后是str,反序列化之后还是字典)
"""字典""" dict1={"name":"李敏","age":20}
dict_str=json.dumps((dict))
print(dict_str)
str_dict=json.loads(dict_str)
print(str_dict)
print(type(str_dict))
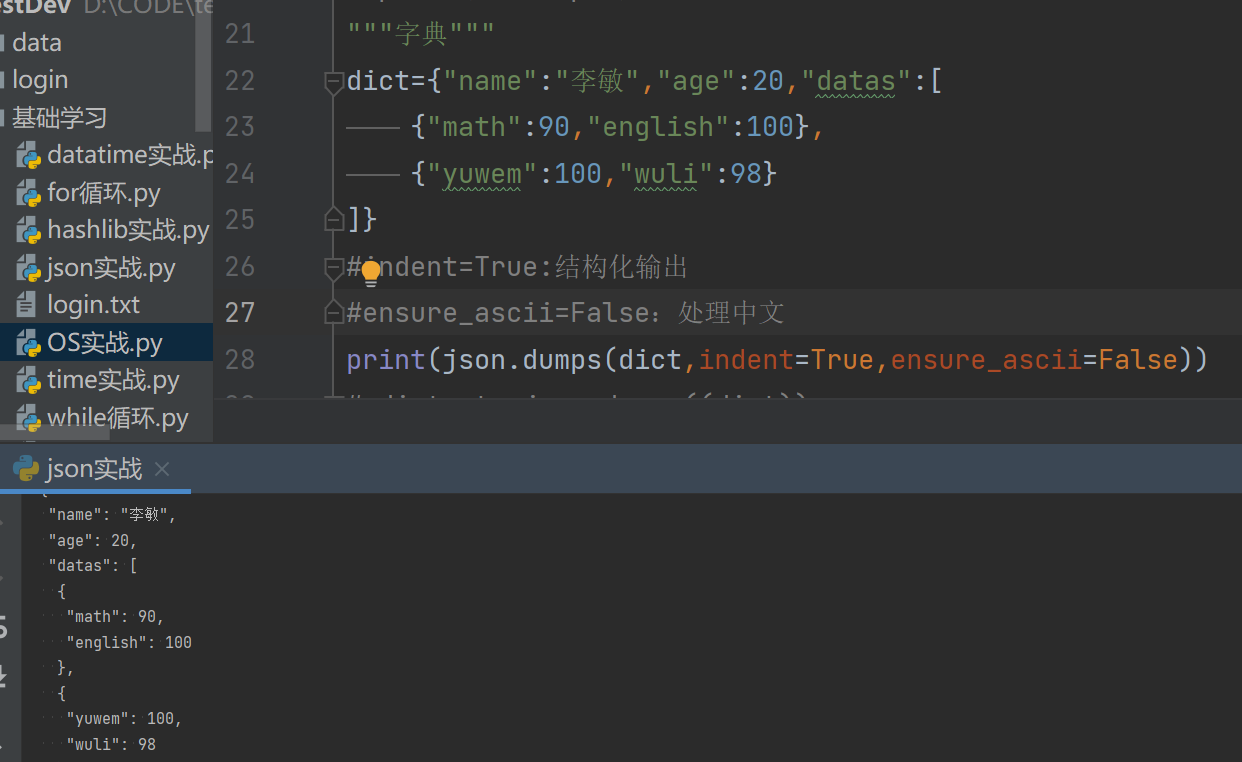
实战:结构化输出字典里的内容
#indent=True:结构化输出 #ensure_ascii=False:处理中文 print(json.dumps(dict,indent=True,ensure_ascii=False))
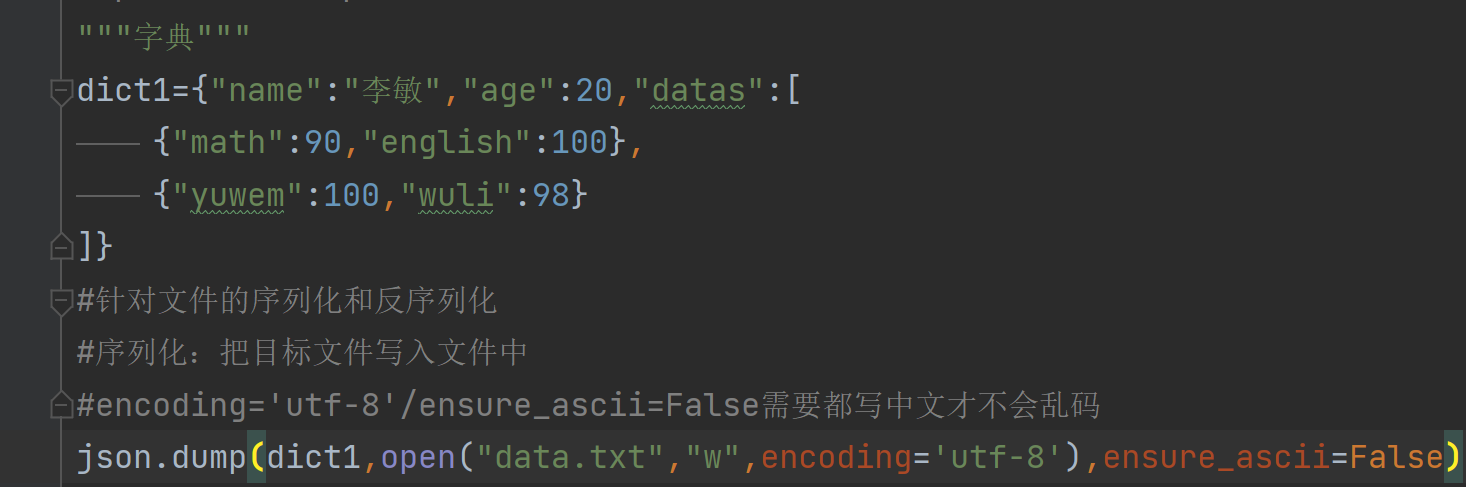
4.针对文件的序列化和反序列化
#针对文件的序列化和反序列化 #序列化:把目标文件写入文件中 #encoding='utf-8'/ensure_ascii=False需要都写中文才不会乱码 json.dump(dict1,open("data.txt","w",encoding='utf-8'),ensure_ascii=False)

反序列化
#反序列化:从文件里面读取文件的内容 print(json.load(open('data.txt','r',encoding='utf-8')))

