多分类评估 - macro F1和micro F1计算方式与适用场景
1. 原理介绍
1.1 简介
macro F1和micro F1是2种多分类的效果评估指标
1.2 举例说明计算方法
假设有以下三分类的testing结果:
label:A、B、C
sample size:9
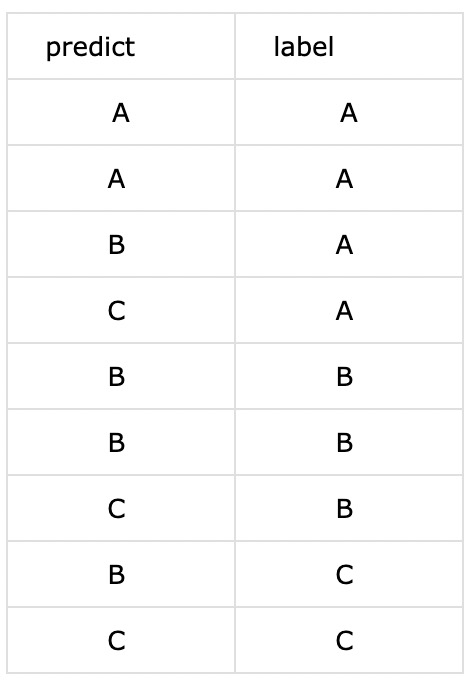
1.2.1 F1 score
下面计算各个类别的准召:
对于类别A:
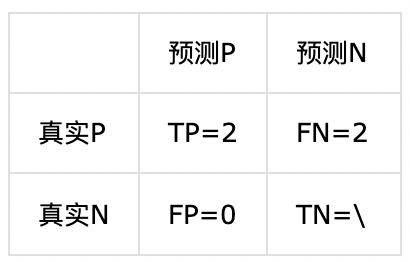
precision = 2/(2+0) = 100%
recall = 2/(2+2) = 50%
对于类别B:
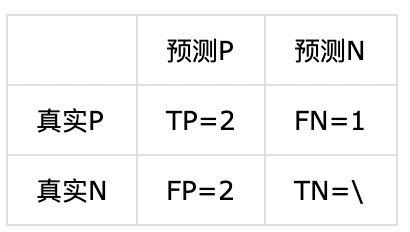
precision = 2/(2+2) = 50%
recall = 2/(2+1) = 67%
对于类别C:
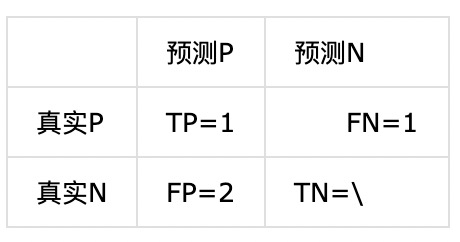
precision= 1/(1+2) = 33%
recall = 1/(1+1) = 50%
TN对于准召的计算而言是不需要的,因此上面的表格中未统计该值。
下面调用sklearn的api进行验证:
from sklearn.metrics import classification_report
print(classification_report([0,0,0,0,1,1,1,2,2], [0,0,1,2,1,1,2,1,2]))
precision recall f1-score support
0 1.00 0.50 0.67 4
1 0.50 0.67 0.57 3
2 0.33 0.50 0.40 2
avg / total 0.69 0.56 0.58 9可以看出,各个类别的准召计算完全一致。
1.2.2 Micro F1
micro f1不需要区分类别,直接使用总体样本的准召计算f1 score。
对于样本整体:
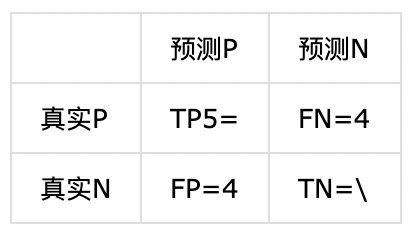
precision = 5/(5+4) = 0.5556
recall = 5/(5+4) = 0.5556
F1 = 2 * (0.5556 * 0.5556)/(0.5556 + 0.5556) = 0.5556
下面调用sklearn的api进行验证
from sklearn.metrics import f1_score
f1_score([0,0,0,0,1,1,1,2,2], [0,0,1,2,1,1,2,1,2],average="micro")
0.5555555555555556可以看出,计算结果也是一致的(保留精度问题)。
1.2.3 Macro F1
不同于micro f1,macro f1需要先计算出每一个类别的准召及其f1 score,然后通过求均值得到在整个样本上的f1 score。
类别A的:
类别B的:
类别C的:
整体的f1为上面三者的平均值:
F1 = (0.6667 + 0.57265 + 0.39759)/3 = 0.546
调用sklearn的api进行验证:
from sklearn.metrics import f1_score
f1_score([0,0,0,0,1,1,1,2,2], [0,0,1,2,1,1,2,1,2],average="macro")
0.546031746031746可见,计算结果正确。
2. 适用场景
micro-F1
计算方法:计算所有类别总的Precision和Recall,然后算F1值;
效果特点:考虑不同类样本数量,当样本不均衡时,更容易受到常见类别的影响
适用场景:注重样本真实分布,只考虑全局效果
marco-F1
计算方法:单独计算每个类别的F1值,然后取各类F1的平均值;
效果特点:不考虑不同类样本数量,1)相对更考虑稀有类别的影响;2)会相对受高precision和高recall类的影响较大
适用场景:样本不均衡,且各个类别同等重要的情况,可保障小样本的性能
3. 参考
https://zhuanlan.zhihu.com/p/64315175

 浙公网安备 33010602011771号
浙公网安备 33010602011771号