# day5(适合周五讲) #### ORM单表操作(预习博客<https://www.cnblogs.com/Dominic-Ji/p/9203990.html>) #### 单表操作演示表 ```python class Book(models.Model): name = models.CharField(max_length=32) price = models.DecimalField(max_digits=8,decimal_place=2) publish = models.CharField(max_length=32) author = models.CharField(max_length=32) create_time = models.DateField(null=True) # 配置auto_now_add=True,创建数据记录的时候会把当前时间添加到数据库。 # 配置上auto_now=True,每次更新数据记录的时候会更新该字段。 ``` 新增数据 ```python # 第一种:有返回值,并且就是当前被创建的数据对象 modles.Book.objects.create(name='',price='',publish='',author='',create_time='2019-5-1') # 第二种:先实例化产生对象,然后调用save方法保存 book_obj = models.Book(name='',price='',publish='',author='',create_time='2019-5-1') book_obj.save() # 2.验证时间格式字段即可以传字符串也可以传时间对象 import datetime ctime = datetime.datetime.now() book = models.Book.objects.create(name='',price='',author='',create_time=ctime) ``` 删除数据 ```python """删除数据""" # 1.删除书名为xxx的这本书 queryset方法 res = models.Book.objects.filter(name='').delete() print(res) # 2.删除书名为xxx的这本书 queryset方法 res = models.Book.objects.filter(name='').first() res.delete() ``` 修改数据 ```python # 1.queryset修改 models.Book.objects.filter(name='').update(price='') # 2.对象修改 book = models.Book.objects.filter(name='').first() book.price = 66.66 book.save() # 对象只有保存方法 这样也能实现修改需求 ``` 查询数据 ```python <1> all(): 查询所有结果 <2> filter(**kwargs): 它包含了与所给筛选条件相匹配的对象 <3> get(**kwargs): 返回与所给筛选条件相匹配的对象,返回结果有且只有一个,如果符合筛选条件的对象超过一个或者没有都会抛出错误。(源码就去搂一眼~诠释为何只能是一个对象) <4> exclude(**kwargs): 它包含了与所给筛选条件不匹配的对象 <5> order_by(*field): 对查询结果排序('-id')/('price') <6> reverse(): 对查询结果反向排序 >>>前面要先有排序才能反向 <7> count(): 返回数据库中匹配查询(QuerySet)的对象数量。 <8> first(): 返回第一条记录 <9> last(): 返回最后一条记录 <10> exists(): 如果QuerySet包含数据,就返回True,否则返回False <11> values(*field): 返回一个ValueQuerySet——一个特殊的QuerySet,运行后得到的并不是一系列 model的实例化对象,而是一个可迭代的字典序列 <12> values_list(*field): 它与values()非常相似,它返回的是一个元组序列,values返回的是一个字典序列 <13> distinct(): 从返回结果中剔除重复纪录 # ******************* # 必须完全一样才可以去重(意味着带了id就没有意义了) # res = models.Book.objects.all().values('name').distinct() 先查一个重复的值再去重 ``` 基于双下划线的查询 ```python # 价格 大于 小于 大于等于 小于等于 filter(price__gt='90') filter(price__lt='90') filter(price_gte='90') filter(price_lte='90') # 存在与某几个条件中 filter(price__in=['11','22','33']) # 在某个范围内 filter(price__range=[50,90]) # 模糊查询 filter(title__contains='西') filter(title__icontains='P') # 以什么开头 以什么结尾 # 按年查询 filter(create_time__year='2017') ``` ps:上述所有的查询方法中返回结构都有哪几类类型? 作业 ```python """ 1 单表查询: 1 查询老男孩出版社出版过的价格大于200的书籍 2 查询2017年8月出版的所有以py开头的书籍名称 3 查询价格为50,100或者150的所有书籍名称及其出版社名称 4 查询价格在100到200之间的所有书籍名称及其价格 5 查询所有人民出版社出版的书籍的价格(从高到低排序,去重) """ ``` ### 多表操作 创建图书管理系统表(给作者表加一张作者详情表为了一对一的查询),诠释一对一关联其实就是外健关联再加一个唯一性约束而已 ```python ForeignKey(unique=Ture) >>> OneToOneField() # 即一对一可以用ForeignKey来做,但是需要设唯一性约束并且会报警告信息,不建议使用,建议用OneToOneField # 用了OneToOneField和用ForeignKey会自动在字段后面加_id # 用了ManyToMany会自动创建第三张表 ``` #### 1.一对多的书籍记录增删改查 ```python # 针对外键关联的字段 两种添加方式 # 第一种通过publish_id # 第二种通过publish传出版社对象 # 删除书籍直接查询删除即可,删除出版社会级联删除 # 编辑数据也是两种对应的方式(对象点的方式(这里能点publish和publish_id)最后点save(),queryset方式update()) ``` #### 2.多对多的书籍与作者的增删改查 ```python """前提:先获取书籍对象,再通过书籍对象点authors来进行书籍作者的增删改查""" # 1.给书籍新增作者add # 1.add可以传作者id,也可以直接传作者对象,并且支持传多个位置参数(不要混着用) # 2.给书籍删除作者remove # 1.remove同样可以传id,对象,并且支持传多个位置参数(不要混着用) # 3.直接清空书籍对象所有的作者数据clear()不用传任何参数 # 4.修改书籍对象所关联的作者信息set,注意点set括号内必须传可迭代对象,里面可以传id,对象 """总结:一对多增删改,多对多add,remove,clear,set""" ``` ### 正向反向概念 ```python # 正向与方向的概念解释 # 一对一 # 正向:author---关联字段在author表里--->authordetail 按字段 # 反向:authordetail---关联字段在author表里--->author 按表名小写 # 查询jason作者的手机号 正向查询 # 查询地址是 :山东 的作者名字 反向查询 # 一对多 # 正向:book---关联字段在book表里--->publish 按字段 # 反向:publish---关联字段在book表里--->book 按表名小写_set.all() 因为一个出版社对应着多个图书 # 多对多 # 正向:book---关联字段在book表里--->author 按字段 # 反向:author---关联字段在book表里--->book 按表名小写_set.all() 因为一个作者对应着多个图书 # 连续跨表 # 查询图书是三国演义的作者的手机号,先查书,再正向查到作者,在正向查手机号 # 总结:基于对象的查询都是子查询,这里可以用django配置文件自动打印sql语句的配置做演示 ``` 基于双下划线的查询 ```python # 一对一 -连表查询 -一对一双下划线查询 -正向:按字段,跨表可以在filter,也可以在values中 -反向:按表名小写,跨表可以在filter,也可以在values中 # 查询jason作者的手机号 正向查询 跨表的话,按字段 # ret=Author.objects.filter(name='jason').values('authordetail__phone') # 以authordetail作为基表 反向查询,按表名小写 跨表的话,用表名小写 # ret=AuthorDetail.objects.filter(author__name='jason').values('phone') # 查询jason这个作者的性别和手机号 # 正向 # ret=Author.objects.filter(name='jason').values('sex','authordetail__phone') # 查询手机号是13888888的作者性别 # ret=Author.objects.filter(authordetail__phone='13888888').values('sex') # ret=AuthorDetail.objects.filter(phone='13888888').values('author__sex') """ 总结 其实你在查询的时候先把orm查询语句写出来,再看用到的条件是否在当前表内,在就直接获取,不在就按照正向按字段反向按表名来查即可 比如: 1.查询出版社为北方出版社的所有图书的名字和价格 res1 = Publish.objects.filter(name='').values('book__name','book__price') res2 = Book.objects.filter(publish__name='').values('name','price') 2.查询北方出版社出版的价格大于19的书 res1 = Publish.objects.filter(name='',book__price__gt=19).values('book__name','book__price) """ ``` 作业: 图书管理系统表创建好 基于对象练习 基于双下滑线练习 聚合查询 ```python from django.db.models import Avg,Count,Max,Min,Sum # 参照博客介绍即可 ``` 分组查询 ```python https://www.cnblogs.com/Dominic-Ji/p/9209341.html 分组与聚合参考博客示例演示即可 # 详细演示示例1,2,5 ``` F与Q查询 ```python # F(查询条件两端都是数据库数据) # 给书籍表增加卖出和库存字段 # 1.查询出卖出数大于库存数的商品 # 2.将每个商品的价格提高50块 # Q(filter里面条件都是与,Q支持与或非) # 1.查询 卖出数大于100 或者 价格小于100块的 # 2.查询 库存数是100 并且 卖出数不是0 的产品 # 3.查询 产品名包含新款, 并且库存数大于60的 ``` 事务 ```python from django.db.models import F from django.db import transaction # 开启事务处理 try: with transaction.atomic(): # 创建一条订单数据 models.Order.objects.create(num="110110111", product_id=1, count=1) # 能执行成功 models.Product.objects.filter(id=1).update(kucun=F("kucun")-1, maichu=F("maichu")+1) except Exception as e: print(e) ``` 常用字段 ```python # 参考博客(<https://www.cnblogs.com/Dominic-Ji/p/9203990.html>) auto_now与auto_now_add defer与only res = models.Author.objects.all().values('name') # 这样虽然能拿到对象的name属性值,但是已经是queryset里面套字典的格式,我现在想拿到queryset里面放的还是一个个的对象,并且这这些对象“只有”name属性,其他属性也能拿,但是会重新查询数据库,类似于for循环N次走N次数据库查询 res = models.Author.objects.all().only('name') # 一旦指导了only就不要取对象没有的属性值了 defer与only刚好相反,取不包括括号内的其他属性值 ``` 图书管理系统整体敲一遍
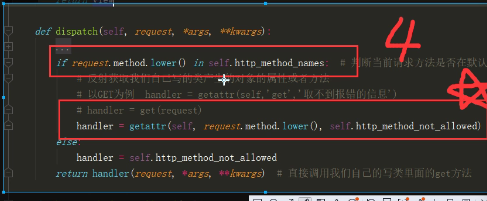
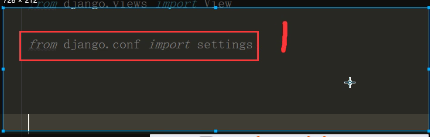
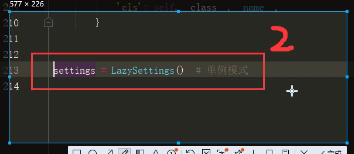
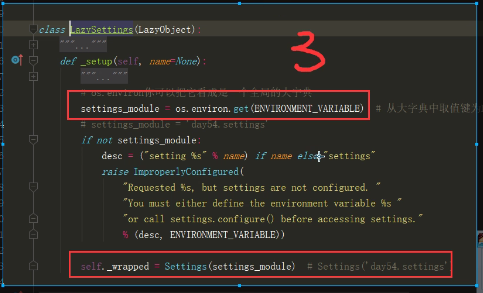
昨日内容 视图层 视图函数可以是函数也可以是类 只要是处理业务逻辑的视图函数都需要接受一个request参数 FBV与CBV FBV基于函数的视图 CBV基于类的视图 views.py from django.views import View class MyView(View): def get(self,request): return HttpRespose('get请求') def post(self,request): return HttpRespose('post请求') urls.py url(r'^login/',MyView.as_view()) 源码部分 @classonlymethod def as_view(cls,**initkwargs): def view(cls,**initkwargs): pass return view 通过源码分析得到 FBV与CBV在路由匹配上 规则都是意义的 都是url后面跟函数的内存地址 看截图即可 django settings源码 项目通常都会有两个配置文件 一个是暴露给用户可以配置的 一个是项目默认的配置 特点:当用户配置了就使用用户的,当用户没有配就使用项目默认的 django中暴露给用户的配置默认就与项目同名的文件夹中 django项目内部默认的配置文件 from django.conf import global_settings 通常我们在django中使用配置文件一般都是按照一下方式导入的 from django.conf import settings 但是也可以直接带入与项目同名的文件夹中的配置文件 from 项目名 import settings class LazySettings(object): def _setup(self): settings = LazySettings() 详细的看截图即可 参考settings源码书写实例(要求掌握) 模板层 {{}} 变量相关 {%%} 逻辑相关 给模板传值 python所有的数据类型都可以被传递到前端页面 注意在传递函数的时候 会自动加括号调用 前端展示的是函数调用的之后的返回值 (ps:前端在调用函数的时候 是不支持给函数传递额外参数的) 如果你想在前端获取后端传递的某个容器类型中的具体元素 那么你可以通过句点符来获取具体的元素 .索引 .键 过滤器 | 过滤器会将|左边的对象当做过滤器第一个参数传入 或将右侧的对象当做第二个参数传入 |length |add:2 |default:'' |slice:'0:8:2' |filesizeformat |truncatewords:3 按照空格切分 不包含三个点 |truncatechars:6 按照字符切分 三个点也算 也就意味着后面的数字起码得大于3 |safe 前后端取消转义 也及意味着前端的html代码 并不单单只能在html文件中书写 你也可以在后端先生成html代码 然后直接传递给前端(******) 前端 |safe 后端 from django.utils.safestring import mark_safe mark_safe("<a href='url'>xxx</a>") 标签 {%%} if判断 {% if 'sasdasd' %} if条件成立 {% elif 'sadsad' %} elif条件成立 {% else %} 上面两者都不成立 {% endif %} for循环 {% for %} {{ forloop }} {{ forloop.first }} {{ forloop.last }} {{ forloop.counter0 }} {{ forloop.counter }} 数据库中的数据它的主键值 不可能是依次递增的 有可能被你删除了几条数据 主键值就不再连续的了 {% empty %} 当for循环对象不能被for循环的时候会走empty逻辑 {% endfor %} for循环里面是可以嵌套if判断的 {% with l.0.2.name as ttt %} {% endwith %} 自定义过滤器 标签 inclusion_tag 1.先在应用名下的文件夹中新建一个名字必须叫做templatetags文件夹 2.在该文件夹内新建一个任意名称的py文件 3.在该py文件中 必须先写一下两句代码 from django import template register = template.Library() # 自定义过滤器 @register.filter(name='mysum') def mysum(a,b) retunr a + b # 自定义标签 @register.simple_tag(name='myplus') def myplus(a,b,c,d,e): return None # 自定义inclusion_tag @register.inclusion_tag('mytag.html') def mytag(n): ... # return {'l':l} return locals() 在html上使用需要先导入后使用 {% load py文件名 %} {{ 2|mysum:1}} {% myplus 1 2 3 5 5 %} {% mytag 10 %} 模板的继承与导入 当多个html页面需要使用相同的html代码块的时候 你可以考虑使用继承 首先需要你在模板html代码中 通过block块儿划定后续想要修改的区域 {%block content%} {%endblock%} 一般情况下 模板html文件内应该有三块区域 css,content,js 模板的导入 {% extends '模板的名字'%} {%block content%} 修改模板中content区域的内容 {{ block.super }}重新复用模板的html样式 {%endblock%} 模板的导入 {% include '你想要导入的html文件名'%} 模型层单表的增删改查
今日内容 神奇的双下划线 day54 test.py 多表操作 图书管理系统 表与表的关系 一对一OneToOneField 可以用ForeignKey(unique=True) 一对多ForeignKey 以上二种 字段 + id 多对多ManyToManyFiled 1.告诉orm自动创建第三种表 2.跨表查询 orm常见字段 事务操作 查询优化 模型层 13个方法 all() filter() get() reverse() order_by() exclude() values() values_list() count() distinct() exists() first() last() 神奇的双下滑查询 """ 查看orm内部sql语句的方法有哪些 1.如果是queryset对象 那么可以点query直接查看该queryset的内部sql语句 2.在django项目的配置文件中 配置一下参数即可实现所有的orm在查询的时候自动打印对应的sql语句 LOGGING = { 'version': 1, 'disable_existing_loggers': False, 'handlers': { 'console':{ 'level':'DEBUG', 'class':'logging.StreamHandler', }, }, 'loggers': { 'django.db.backends': { 'handlers': ['console'], 'propagate': True, 'level':'DEBUG', }, } } """ """神奇的双下滑查询""" # 查询价格大于200的书籍 # res = models.Book.objects.filter(price__gt=200) # print(res) # 查询价格小于200的书籍 # res = models.Book.objects.filter(price__lt=200) # print(res) # 查询价格大于等于200.22的书籍 # res = models.Book.objects.filter(price__gte=200.22) # print(res) # 查询价格小于等于200.22的书籍 # res = models.Book.objects.filter(price__lte=200.22) # print(res) # 查询价格要么是200,要么是300,要么是666.66 # res = models.Book.objects.filter(price__in=[200,300,666.66]) # print(res) # 查询价格在200到800之间的 # res = models.Book.objects.filter(price__range=(200,800)) # 两边都包含 # print(res) # 查询书籍名字中包含p的 """原生sql语句 模糊匹配 like % _ """ # res = models.Book.objects.filter(title__contains='p') # 仅仅只能拿小写p # res = models.Book.objects.filter(title__icontains='p') # 忽略大小写 # print(res) # 查询书籍是以三开头的 # res = models.Book.objects.filter(title__startswith='三') # res1 = models.Book.objects.filter(title__endswith='p') # print(res) # print(res1) # 查询出版日期是2017的年(******) res = models.Book.objects.filter(create_time__year='2017') print(res) 多表操作 图书管理系统表创建 一对多:ForeignKey 一对一:OnoToOneField 可以用ForeignKey代替ForeignKey(unique=True) 上面两个关键字所创建出来的字段会自动加上_id后缀 多对多:ManyToManyFiled 该字段并不会真正的在表中展示出来 它仅仅是一个虚拟字段 1.告诉orm自动创建第三种表 2.帮助orm跨表查询 一对多字段的增删改查 多对多字段的增删改查 ORM跨表查询(******) 基于对象的跨表查询 基于双下划线的查询 聚合查询 aggregate from django.db.models import Sum,Max,Min,Avg,Count 分组 annotate F与Q查询 F查询 Q查询 q = Q() q.connector = 'or' # 修改查询条件的关系 默认是and q.children.append(('title__contains','三国演义')) # 往列表中添加筛选条件 q.children.append(('price__gt',444)) # 往列表中添加筛选条件 res = models.Book.objects.filter(q) # filter支持你直接传q对象 但是默认还是and关系 print(res) ORM常见字段 ORM事务操作 ORM查询优化 ...
""" Django settings for day55 project. Generated by 'django-admin startproject' using Django 1.11.11. For more information on this file, see https://docs.djangoproject.com/en/1.11/topics/settings/ For the full list of settings and their values, see https://docs.djangoproject.com/en/1.11/ref/settings/ """ import os # Build paths inside the project like this: os.path.join(BASE_DIR, ...) BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) # Quick-start development settings - unsuitable for production # See https://docs.djangoproject.com/en/1.11/howto/deployment/checklist/ # SECURITY WARNING: keep the secret key used in production secret! SECRET_KEY = '3dh*maq((3)fe6_+k9-85%(sj%-6si*oee4n2t7p@=@ui&kj6)' # SECURITY WARNING: don't run with debug turned on in production! DEBUG = True ALLOWED_HOSTS = [] # Application definition INSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'app01.apps.App01Config', ] MIDDLEWARE = [ 'django.middleware.security.SecurityMiddleware', 'django.contrib.sessions.middleware.SessionMiddleware', 'django.middleware.common.CommonMiddleware', 'django.middleware.csrf.CsrfViewMiddleware', 'django.contrib.auth.middleware.AuthenticationMiddleware', 'django.contrib.messages.middleware.MessageMiddleware', 'django.middleware.clickjacking.XFrameOptionsMiddleware', ] ROOT_URLCONF = 'day55.urls' TEMPLATES = [ { 'BACKEND': 'django.template.backends.django.DjangoTemplates', 'DIRS': [os.path.join(BASE_DIR, 'templates')] , 'APP_DIRS': True, 'OPTIONS': { 'context_processors': [ 'django.template.context_processors.debug', 'django.template.context_processors.request', 'django.contrib.auth.context_processors.auth', 'django.contrib.messages.context_processors.messages', ], }, }, ] WSGI_APPLICATION = 'day55.wsgi.application' # Database # https://docs.djangoproject.com/en/1.11/ref/settings/#databases DATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', 'NAME': 'day55_1', 'USER': 'root', 'PASSWORD': 'llx20190411', 'HOST': '127.0.0.1', 'PORT': 3306, 'CHARSET':'utf8' } } # Password validation # https://docs.djangoproject.com/en/1.11/ref/settings/#auth-password-validators AUTH_PASSWORD_VALIDATORS = [ { 'NAME': 'django.contrib.auth.password_validation.UserAttributeSimilarityValidator', }, { 'NAME': 'django.contrib.auth.password_validation.MinimumLengthValidator', }, { 'NAME': 'django.contrib.auth.password_validation.CommonPasswordValidator', }, { 'NAME': 'django.contrib.auth.password_validation.NumericPasswordValidator', }, ] # Internationalization # https://docs.djangoproject.com/en/1.11/topics/i18n/ LANGUAGE_CODE = 'en-us' TIME_ZONE = 'UTC' USE_I18N = True USE_L10N = True USE_TZ = True # Static files (CSS, JavaScript, Images) # https://docs.djangoproject.com/en/1.11/howto/static-files/ STATIC_URL = '/static/' LOGGING = { 'version': 1, 'disable_existing_loggers': False, 'handlers': { 'console': { 'level': 'DEBUG', 'class': 'logging.StreamHandler', }, }, 'loggers': { 'django.db.backends': { 'handlers': ['console'], 'propagate': True, 'level': 'DEBUG', }, } }
from django.db import models # Create your models here. class Book(models.Model): title = models.CharField(max_length=255) price = models.DecimalField(max_digits=8,decimal_places=2) publish_date = models.DateField(auto_now_add=True) # 库存数 kucun = models.IntegerField(null=True) # 卖出数 maichu = models.IntegerField(null=True) # 虚拟字段 1.自动创建第三张表 2.帮助orm跨表查询 authors = models.ManyToManyField(to='Author') # 默认是跟publish的主键字段做的一对多外键关联 publish = models.ForeignKey(to='Publish') def __str__(self): return self.title class Publish(models.Model): name = models.CharField(max_length=32) addr = models.CharField(max_length=32) # email = models.EmailField() # 就是varchar(254) def __str__(self): return self.name class Author(models.Model): name = models.CharField(max_length=32) age = models.IntegerField() author_detail = models.OneToOneField(to='AuthorDetail') def __str__(self): return self.name class AuthorDetail(models.Model): phone = models.BigIntegerField() addr = models.CharField(max_length=64) """ models.py中的模型类__str__方法 必须返回一个字符串形式数据!!! """ def __str__(self): return self.addr
python manage.py createsuperuser 创建超级管理员账号
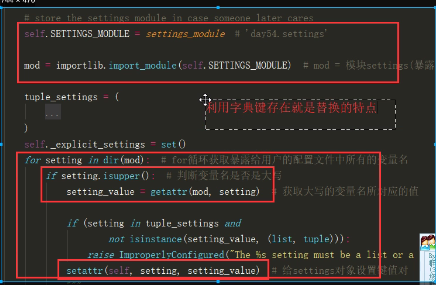
setings源码
settings1.png
settings2.png
settings3.png
settings4.png
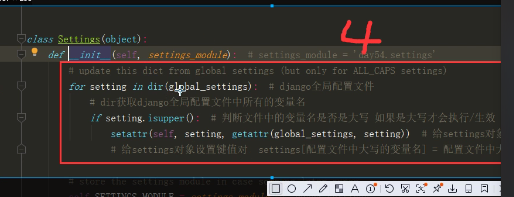
settings5.png
CBV源码
CBV操作步骤1.png

CBV操作步骤2.png
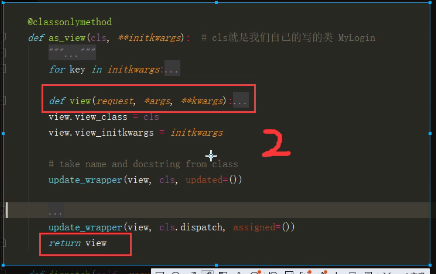
CBV操作步骤3.png
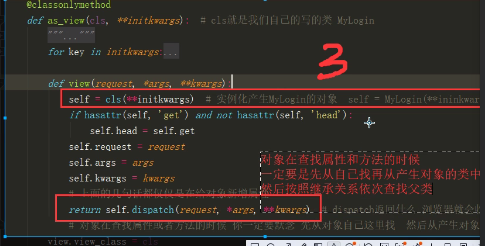
CBV操作步骤4.png