
mongodb性能测试报告
1 测试目的
模拟生产环境,测试当前mongoDB的各项性能。
2 测试环境
2.1 软件配置

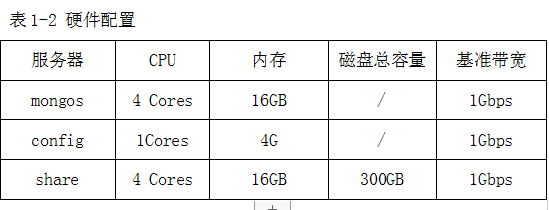
2.2 硬件配置
3 测试工具
YCSB是雅虎开源的NoSQL测试工具,通常用来对noSQL数据库进行性能,这里我们使用的是ycsb-mongodb-binding-0.15.0.tar.gz包。
需要新建配置文件,并调整参数,并利用load/run命令,加载数据进行性能测试。
3.1使用简介
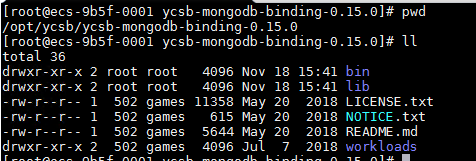
#ycsb包解压后的目录结构
#使用前,我们要先了解命令结构
命令示例:
#/opt/ycsb/ycsb-mongodb-binding-0.15.0/bin/ycsb load mongodb -threads 1 -P workloads/workloada -p fieldcount=1 -p fieldlength=1024 -p table=ycsb1 -p clientbuffering=true -p mongodb.url=mongodb://用户:密码@ip:port/test?authSource=admin
表1-4 命名参数说明
|
参数 |
含义 |
|
bin/ycsb |
命令本身。 |
|
load/run/shell |
指定这个命令的作用,分别代表加载数据/运行测试/交互界面。 |
|
mongodb/hbase10/basic.. |
指定这次测试使用的驱动,也就是这次究竟测的是什么数据库,有很多选项,可以ycsb --help看到所有。 |
|
threads |
线程数,模拟客户端数 |
|
-P |
选择加载的配置文件 |
|
workloads/workloada |
指定测试的参数文件,默认有6种测试模板,加一个大模板; workloada:读写均衡型,50%/50%,Reads/Writes workloadb:读多写少型,95%/5%,Reads/Writes workloadc:只读型,100%,Reads workloadd:读最近写入记录型,95%/5%,Reads/insert workloade:扫描小区间型,95%/5%,scan/insert workloadf:读写入记录均衡型,50%/50%,Reads/insert workload_template:参数列表模板 |
|
-p fieldcount=1 |
单条记录字段个数:1 |
|
-p fieldlength=1024 |
每个字段的大小: 1024Bytes |
|
-p table= |
自定义表名 |
|
-p clientbuffering=true |
客户端写缓存 |
|
-p mongodb.url= |
指定测试的数据库的认证信息,账号密码,地址端口和库名 |
3.2 YCSB测试参数解析
workloads目录里面下包含自带了6种压力测试场景。 如下图:
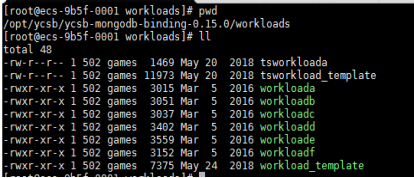
文件和相应场景的对应关系如下:
workloada:读写均衡型,50%/50%,Reads/Writes
workloadb:读多写少型,95%/5%,Reads/Writes
workloadc:只读型,100%,Reads
workloadd:读最近写入记录型,95%/5%,Reads/insert
workloade:扫描小区间型,95%/5%,scan/insert
workloadf:读写入记录均衡型,50%/50%,Reads/insert
示例文件:
#vim workloads/workloada
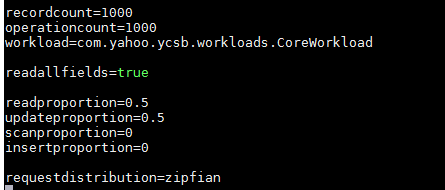
表1-5 workload参数含义
|
参数 |
含义 |
|
recordcount=1000
|
YCSB load(加载元数据)命令的参数,默认值1000表示默认加载的记录条数,可以在命令行显示修改该值。 |
|
operationcount=1000
|
YCSB run(运行压力测试)命令的参数,默认值1000表示默认选取数据库中的1000条数据进行压力测试。对于workloada这种测试场景,就意味着读数据在500左右,写数据也在500左右。 |
|
workload=com.yahoo.ycsb.workloads.CoreWorkload
|
指定了workload的实现类为 com.yahoo.ycsb.workloads.CoreWorkload |
|
readallfields=true |
表示查询时是否读取记录的所有字段 |
|
readproportion=0.5 |
表示读操作的比例,该场景为0.5 |
|
updateproportion=0.5 |
表示更新操作的比例,该场景为0.5 |
|
scanproportion=0 |
表示扫描操作的比例 |
|
insertproportion=0 |
表示插入操作的比例 |
|
requestdistribution=zipfian
|
表示请求的分布模式,YCSB提供uniform, zipfian, latest三种分布模式, Uniform(等概率随机选择记录)、Zipfian(随机选择记录,存在热纪录)和Latest(近期写入的记录是热记录) |
3.3 YCSB测试工具命令
1.先为指定的库和表指定hash分片
mongo ip:端口
>sh.enableSharding("test")
>sh.shardCollection("test.usertable", {_id:"hashed"})
2.修改业务模型
#cd /opt/ycsb-mongodb-binding-0.15.0/workloads
#只插入100万条数据
#vi workload-s1

3.数据写入
#cd /opt/ycsb/ycsb-mongodb-binding-0.15.0
#/opt/ycsb/ycsb-mongodb-binding-0.15.0/bin/ycsb load mongodb -threads 50 -P workloads/workload-s1-p fieldcount=1 -p fieldlength=1024
-p clientbuffering=true -p table=ycsb1 -p mongodb.url=mongodb://账号:密码@ip:端口,ip:端口,ip:端口/test?authSource=admin
4.查看插入的数据
#mongo ip:端口
>use test
>db.stats();

插入100万条数据后,可以看到每个share上都有33万多的objects,
5.结果参数说明
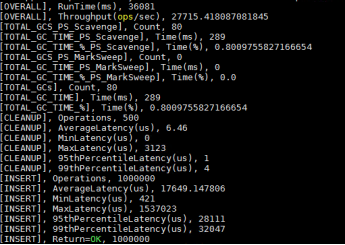
表1-6 ycsb运行结果说明
|
参数 |
说明 |
|
RunTime(ms): |
运行总时间(毫秒) |
|
Throughput(ops/sec): |
吞吐量,每秒操作数 |
|
[TOTAL_GCS_PS_Scavenge], Count: |
Parallel Scavenge 回收次数 |
|
[TOTAL_GC_TIME_PS_Scavenge], Time(ms): |
Parallel Scavenge 回收时间 |
|
[TOTAL_GC_TIME_%_PS_Scavenge], Time(%): |
Parallel Scavenge 回收时间百分比 |
|
[TOTAL_GCS_PS_MarkSweep], Count: |
PS MarkSweep 回收次数 |
|
[TOTAL_GC_TIME_PS_MarkSweep], Time(ms): |
PS MarkSweep 回收时间 |
|
[TOTAL_GC_TIME_%_PS_MarkSweep], Time(%): |
PS MarkSweep 回收时间百分比 |
|
[TOTAL_GCs], Count: |
全局 GC 次数 |
|
[TOTAL_GC_TIME], Time(ms): |
全局 GC 时间 |
|
[TOTAL_GC_TIME_%], Time(%): |
全局 GC 时间百分比 |
|
不同操作类型:READ\UPDATE\INSERT\SCAN等; |
|
|
Operations |
总操作数 |
|
AverageLatency(us) |
平均延迟(微秒) |
|
MinLatency(us) |
最小延迟(微秒) |
|
MaxLatency(us) |
最大延迟(微秒) |
|
95thPercentileLatency(us) : |
95%的样本延迟低于该值 |
|
99thPercentileLatency(us) |
99%的样本延迟低于该值 |
|
Return=OK |
结果(正确),总操作数 |
4 测试方法
- 使用YCSB-mongoDB对测试环境下test库进行各项测试。
4.1 测试环境
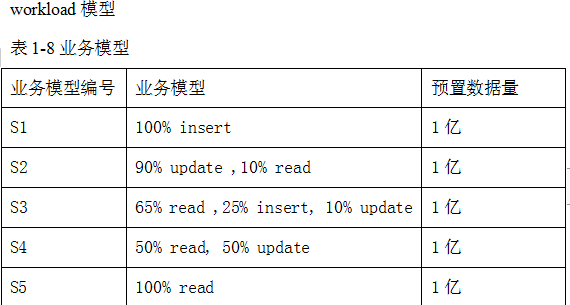
4.2测试模型
4.3测试指标
(1)OPS:Operator per Second,数据库每秒执行的操作数。
(2)AverageLatency,平均响应时间。
(3)评判指标:直到发现ops不再增加而平均响应时间继续增加;
4.4测试步骤
1.先为指定的库和表指定hash分片
#mongo ip:端口
>sh.enableSharding("test")
>sh.shardCollection("test.ycsb1", {_id:"hashed"})
2.文档模型:
修改YCSB配置,每个文档大小约为1KB,默认“_id”索引。
3.配置workload文件。
按照表1-8业务模型所示的业务模型,配置workload中的“readproportion”、“insertproportion”、“updateproportion”等值。
4.以业务模型workload_s1为例,执行以下命令,准备数据。
#cd /opt/ycsb/ycsb-mongodb-binding-0.15.0
#/opt/ycsb/ycsb-mongodb-binding-0.15.0/bin/ycsb load mongodb -threads 50 -P workloads/workload-s1 -p fieldcount=1 -p fieldlength=1024
-p clientbuffering=true -p table=ycsb1 -p mongodb.url=mongodb://账号:密码@ip:端口,ip:端口,ip:端口/test?authSource=admin
1>workload_s1_load.result 2> workload_s1_load.log
5.以业务模型workload_s1为例,执行以下命令,测试性能
#cd /opt/ycsb/ycsb-mongodb-binding-0.15.0
#/opt/ycsb/ycsb-mongodb-binding-0.15.0/bin/ycsb run mongodb -threads 50 -P workloads/workload-s1 -p fieldcount=1 -p fieldlength=1024
-p clientbuffering=true -p table=ycsb1 -p mongodb.url=mongodb://账号:密码@ip:端口,ip:端口,ip:端口/test?authSource=admin
1>workload_s1_run.result 2> workload_s1_run.log
5 测试用例
5.1 用例1 insert mongoDB测试库
|
测试用例1:插入mongoDB测试库 |
|
|
测试目的 |
在测试库100% 导入1亿条数据,观察请求状态 |
|
前置条件 |
1、mongoDB正常运行 |
|
步骤 |
1、根据需求测试项,指定mongodb分片,调整测试模型 2、准备数据 /opt/ycsb/ycsb-mongodb-binding-0.15.0/bin/ycsb load mongodb -threads 50 -P workloads/workload-s1 -p fieldcount=1 -p fieldlength=1024 -p clientbuffering=true -p table=ycsb1 -p mongodb.url=mongodb://账号:密码@ip:端口,ip:端口,ip:端口/test?authSource=admin 1>workload_s1_load.result 2> workload_s1_load.log 3、测试数据 /opt/ycsb/ycsb-mongodb-binding-0.15.0/bin/ycsb run mongodb -threads 50 -P workloads/workload-s1 -p fieldcount=1 -p fieldlength=1024 -p clientbuffering=true -p table=ycsb1 -p mongodb.url=mongodb://账号:密码@ip:端口,ip:端口,ip:端口/test?authSource=admin 1>workload_s1_run.result 2> workload_s1_run.log 4、记录测试结果 5、调整线程数,继续测试,并记录结果 6、通过调整线程数,直到发现ops不再增加而响应时间继续增加。 |
|
获取指标 |
1、读写耗时、吞吐量、平均响应时间 |
|
参数化变量 |
|
|
数据准备要求 |
|
|
备注 |
在测试前,确保网络畅通 |
5.2 用例2 update&read mongoDB测试库
|
测试用例2:update&read mongoDB测试库 |
|
|
测试目的 |
在测试库90%更新和10%读取测试1亿条数据,观察请求状态 |
|
前置条件 |
1、mongoDB正常运行 |
|
步骤 |
1、根据需求测试项,指定mongodb分片,调整测试模型 2、预备数据 参照如上命令 3.测试数据 参照如上命令 4、记录测试结果; 5、调整线程数,继续测试,并记录结果; 6、通过调整线程数,直到发现ops不再增加而响应时间继续增加。 |
|
获取指标 |
1、读写耗时、吞吐量、平均响应时间 |
|
参数化变量 |
|
|
数据准备要求 |
|
|
备注 |
在测试前,确保网络畅通 |
5.3 用例3 read&insert&update mongoDB测试库
|
测试用例3:update&read mongoDB测试库 |
|
|
测试目的 |
在测试库65%读取,10%插入和25%更新测试1亿条数据,观察请求状态 |
|
前置条件 |
1、mongoDB正常运行 |
|
步骤 |
1、根据需求测试项,指定mongodb分片,调整测试模型 2、预备数据 参照如上命令 3.测试数据 参照如上命令 4、记录测试结果; 5、调整线程数,继续测试,并记录结果; 6、通过调整线程数,直到发现ops不再增加而响应时间继续增加。 |
|
获取指标 |
1、读写耗时、吞吐量、平均响应时间 |
|
参数化变量 |
|
|
数据准备要求 |
|
|
备注 |
在测试前,确保网络畅通 |
5.4 用例4 read&update mongoDB测试库
|
测试用例4:read&update mongoDB测试库 |
|
|
测试目的 |
在测试库50%读取,50%更新测试1亿条数据,观察请求状态 |
|
前置条件 |
1、mongoDB正常运行 |
|
步骤 |
1、根据需求测试项,指定mongodb分片,调整测试模型 2、预备数据 参照如上命令 3.测试数据 参照如上命令 4、记录测试结果; 5、调整线程数,继续测试,并记录结果; 6、通过调整线程数,直到发现ops不再增加而响应时间继续增加。 |
|
获取指标 |
1、读写耗时、吞吐量、平均响应时间 |
|
参数化变量 |
|
|
数据准备要求 |
|
|
备注 |
在测试前,确保网络畅通 |
5.5 用例5 read mongoDB测试库
|
测试用例5:read mongoDB测试库 |
|
|
测试目的 |
在测试库100%读取1亿条数据,观察请求状态 |
|
前置条件 |
1、mongoDB正常运行 |
|
步骤 |
1、根据需求测试项,指定mongodb分片,调整测试模型 2、预备数据 参照如上命令 3.测试数据 参照如上命令 4、记录测试结果; 5、调整线程数,继续测试,并记录结果; 6、通过调整线程数,直到发现ops不再增加而响应时间继续增加。 |
|
获取指标 |
1、读写耗时、吞吐量、平均响应时间 |
|
参数化变量 |
|
|
数据准备要求 |
|
|
备注 |
在测试前,确保网络畅通 |
6 测试场景
|
测试类别 |
场景 |
场景的组织 |
场景的控制 |
|
用例 |
|||
|
mongoDB性能测试 |
场景1 |
6.1插入性能测试 100% insert |
云服务自带监控 |
|
mongoDB性能测试 |
场景2 |
6.2更新,读取性能测试 90% update ,10% read |
云服务自带监控 |
|
mongoDB性能测试 |
场景3 |
6.3读取,插入,更新性能测试 65% read ,25% insert, 10% update |
云服务自带监控 |
|
mongoDB性能测试 |
场景4 |
6.4 读取,更新性能测试 50% read , 50% update |
云服务自带监控 |
|
mongoDB性能测试 |
场景5 |
6.5 读取性能测试 100% read |
云服务自带监控 |
7 测试结果分析
7.1 Intert性能测试
7.1.1 测试参数记录
分片集群100% insert写入测试记录结果如下:
|
线程 |
类型 |
数据条数 |
runtime(ms) |
Ops/sec |
AverageLatency(us) |
操作执行数 |
|
50 |
分片-insert |
|
|
|
||
|
100 |
分片-insert |
|
|
|
|
|
|
200 |
分片-insert |
|
|
|
|
|
|
400 |
分片-insert |
|
|
|
7.1.2测试结果
绘制图表
7.1.3 资源情况分析
Mongos是数据库集群请求的入口,所有的请求都通过mongos进行协调,不需要在应用程序添加一个路由选择器,
mongos自己就是一个请求分发中心,它负责把对应的数据请求请求转发到对应的shard服务器上。
1.下图100线程时,使用mongostat监测到mongos的情况;

参数解释:
inserts 每秒插入次数
command 每秒的命令数
vsize 虚拟内存使用量
res 物理内存使用量
net_in/net_out 网络进出流量
2.下图为200线程时,mongos的cpu和带宽使用情况;

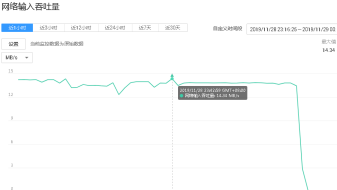
Mongos的cpu使用率稳定在50%左右,输入流量稳定在13MB/s;mongos进行协调请求,
再将数据进行转发到后端;通过监控到mongos的cpu,内存,网络带宽一直处在稳定的状态;
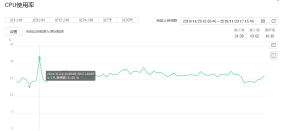
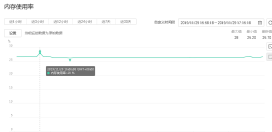
3.Config server,为配置服务器,存储所有数据库元信息(路由、分片)的配置。在生
产环境通常有多个 config server 配置服务器,因为它存储了分片路由的元数据,防止数据丢失。
下图为400线程下config的cpu和内存使用率;cpu稳定在20%以下,内存稳定在30%以下;
4.每个分片都是一个独立的数据库,所有的分片组合起来构成一个逻辑上的完整的数据库。
分片机制降低了每个分片的数据操作量及需要存储的数据量,达到多台服务器来应对不断增加的负载和数据的效果。
下图为400线程,share的cpu,内存和带宽使用情况,看到cpu大部分时间已处于100%的状态;内存使用率在60%以下,带宽为16MB/s;
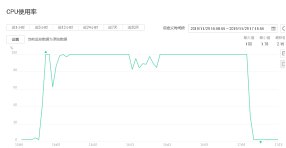
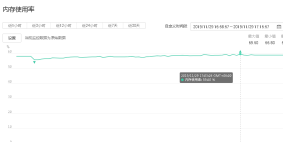
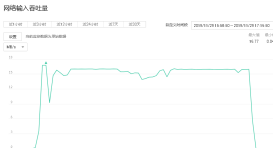
在云环境上,后端为分布式存储池,无法监控具体的磁盘写入情况;
但每当内存中的数据累计到一定量(或者一定时间),MongoDB会将内存数据flush到磁盘,
并清理脏页数据,此时该shard的cpu使用率也会飙升,达到规格上限;
后续省略
。
。
。
8 测试结果总结
1.当前测试结果绘制图表
2.当前瓶颈分析
Sharding cluster是一种可以水平扩展的模式,在数据量很大时特给力,实际大规模应用一般会采用这种架构去构建。
sharding分片很好的解决了单台服务器磁盘空间、内存、cpu等硬件资源的限制问题,把数据水平拆分出去,降低单节点的访问压力。
从以上测试记录,当share的cpu达到100%时,插入,更新和读取等操作性能有所下降,综上,目前性能受限于分片的cpu。
特别说明:测试结论只适用于本次测试;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号