10.5 George_Plover
T1 简单点
简单点
因为没看清楚题意,\(eeeaaasssyy\) 实际只算一个
分析
从贪心的角度入手,每一个字符都匹配下一个必然最多
对于每一个\(e\) 找到最近的下一个\(a\)
对于每一个\(a\) 找到最近的下一个\(s\)
对于每一个\(s\) 找到最近的下一个\(y\)
对于每一个\(y\) 找到最近的下一个\(e\)
进行建边后得到一个 \(DAG\)
查询时,先找到最近的一个 \(e\), 然后开始跳
但跳的过程可以使用倍增
点击查看代码
#include<cstdio>
#include<iostream>
#include<cstring>
#define int long long
#define maxn 200010
using namespace std;
char s[maxn];
int ans,strt;
int len,m,l,r,fail[maxn],nex[maxn][21];
int qe[maxn],qa[maxn],qs[maxn],qy[maxn],tmpi,tmpj;
int tote,tota,tots,toty;
template<typename T>void read(T &x)
{
x=0;char c=getchar();T neg=0;
while(!isdigit(c))neg|=!(c^'-'),c=getchar();
while(isdigit(c))x=(x<<3)+(x<<1)+(c^48),c=getchar();
if(neg)x=(~x)+1;
}
template<typename T>void wr(T x)
{
if(x<0)putchar('-'),x=-x;
if(x>9)wr(x/10);
putchar((x-x/10*10)^48);
return ;
}
signed main()
{
freopen("easier.in","r",stdin);
freopen("easier.out","w",stdout);
scanf("%s",s+1);
len=strlen(s+1);
for(int i=1;i<=len;i++)
{
if(s[i]=='e') qe[++tote]=i;
if(s[i]=='a') qa[++tota]=i;
if(s[i]=='s') qs[++tots]=i;
if(s[i]=='y') qy[++toty]=i;
}
int i,j;
i=j=1; while(i<=tote&&j<=tota){if(qe[i]<qa[j]) {nex[qe[i]][0]=qa[j],i++;continue;}else j++;}
i=j=1; while(i<=tota&&j<=tots){if(qa[i]<qs[j]) {nex[qa[i]][0]=qs[j],i++;continue;}else j++;}
i=j=1; while(i<=tots&&j<=toty){if(qs[i]<qy[j]) {nex[qs[i]][0]=qy[j],i++;continue;}else j++;}
i=j=1; while(i<=toty&&j<=tote){if(qy[i]<qe[j]) {nex[qy[i]][0]=qe[j],i++;continue;}else j++;}
// eesaseyaesasyy eeeaaasssyyy
nex[len+1][0]=len+1;
for(int j=1;j<=17;j++)
{
for(int i=1;i<=len+1;i++)
{
if(!nex[i][0]) nex[i][0]=len+1;
nex[i][j]=nex[nex[i][j-1]][j-1]?nex[nex[i][j-1]][j-1]:len+1;
}
}
scanf("%lld",&m);
for(int i=1;i<=m;i++)
{
read(l); read(r);
while(s[l]!='e') l++;
int num=0;
int st=l;
for(int j=17;j>=0;j--)
{
if(nex[st][j]<=r)
{
st=nex[st][j];
num+=(1<<j);
}
if(st==r) break;
}
wr((num+1)/4); putchar('\n');
}
return 0;
}
/*
eaeasyesasyea
eeeeyeeeeassssy
eeaseyaesasyy
4
1 13
2 12
2 10
3 11
eeeaaasssyyy
3
1 12
2 12
1 11
*/
T2 不可做题

\(to\quad be\quad continue....\)
T3
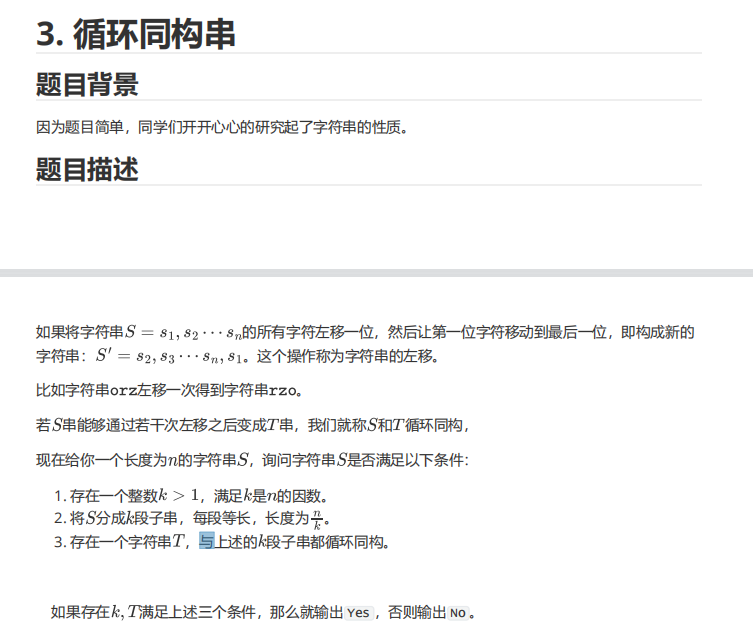
分析
\(KMP\)
纯纯的暴力,先枚举所有因数 \(k\) ,对每一段前 \(k\) 个循环一遍如 \(abc\) 变为 \(abcabc\)
对于剩下的部分,每一个都 \(KMP\) 一次;
\(H ash\)
枚举 \(k\) ,计算每一串的哈希值,每次断开匹配,
如 \(aaaab\) 与 \(aaaba\) 可以拆开\(a\quad aaab\) 与 \(aaab \quad a\)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号