Python idle中lxml 解析HTML时中文乱码解决
例:
<html><p>中文</p></html>
读取代码:
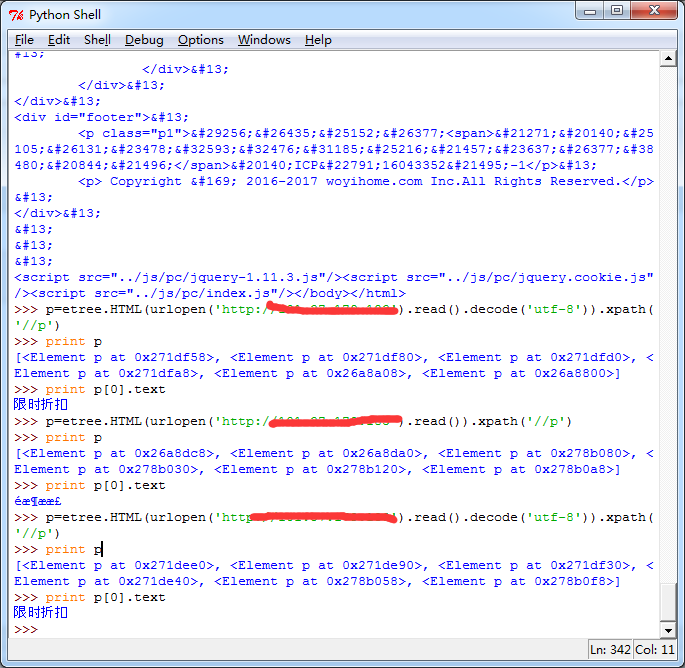
代码HTML需要进行decode('utf-8') 编译:
p=etree.HTML(urlopen('http://101.37.179.183').read().decode('utf-8')).xpath('//p')

例:
<html><p>中文</p></html>
读取代码:
代码HTML需要进行decode('utf-8') 编译:
p=etree.HTML(urlopen('http://101.37.179.183').read().decode('utf-8')).xpath('//p')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号