
前言:
对于Key-Value集合,想象两种极端的情况:如果没有内存的限制,我们可以直接将键作为一个数组的索引,那么所有的查找只需一次就可以完成;另一方面,如果没有时间的限制,那么我们就可以使用无序的数组进行顺序查找,这样只需要很少的内存。然而这两种情况几乎见不到,作为在时间和空间上做出权衡的经典方法,使用散列表可以在大部分情况下实现常数级别的查找和插入操作!
一,散列函数
我们需要有一个将Key转化为数组索引的方法,这个方法就是散列函数。如果我们有一个能保存M个键值对的数组,那么这个散列函数就能够将任意Key转化为【0,M-1】之间的索引。
散列函数和键的类型有关:严格来说:每一种类型的键都有一个对应的散列函数!
Key的常见情况:
正整数:
常用的方法是除留取余法,选择一个大小为素数M的数组,对于任意正整数K,计算K%M,选择素数的原因是使用素数,散列值的分布会更好!
浮点数:
如果键是0到1之间的小数,可以将他乘以M并四舍五入得到一个【0,M】之间的值,
但是有很大的缺陷,这种情况下键的高位起的作用更大,而最低为几乎没有影响!
比如0.554433*100=55;显然,4433这四位不起任何作用。而在Java里,对这种情况的处理是将键转化为二进制然后再使用除留取余法。
字符串:
除留取余法也可以处理字符串,只要我们将他们当做大整数处理即可。
例如:计算String的哈希值。
1 int hash=0; 2 3 for(int i=0;i<s.length();i++) 4 5 { 6 7 hash=(R*hash+s.charAt(i))%M; 8 9 }
charAt()返回一个char,即非负16位整数,如果R足够小,不造成溢出,那摩结果就能落在【0,M】之间。事实上,Java中的String的hashCode()函数就是使用类似的 方法实现的。源码如下:
1 public int hashCode() { 2 3 int h = hash; 4 5 if (h == 0 && value.length > 0) { 6 7 char val[] = value; 8 9 10 11 for (int i = 0; i < value.length; i++) { 12 13 h = 31 * h + val[i]; 14 15 } 16 17 hash = h; 18 19 } 20 21 return h; 22 23 }
组合键:
对于组合键的处理,我们可以像处理String那样将他们混合起来,如果键的类型为Date,那么可以采用下列方法:
int hash=(((day*R+month)%M)*R+year)%M;
//R同String中的R
Java中的约定:
Java要求每种类型都需要相应的散列函数,所以他们都继承了一个能返回32比特整数的hashCode()方法。但是每一种数据类型的hashCode()方法都需要和equals()方法一致,即如果a.equals(b)==true;那么一定会有a.hashCode()==b.hashCode();反之则不然,因为这里存在着哈希碰撞的问题,因此,如果你要自己实现hashCode(),请不要忘记实现equals();
但是因为hashCode默认为32位比特,在实际使用中,我们可以使用除留取余法将他转化为一个合理的整数。例如:
private int hash(K key)
{
return (key.hashCode()&0x7fffffff)%M;
}//这段代码会屏蔽符号位,将其转化为31位非负整数。
自定义hashCode
其实现在的编译器,如eclipse,IDEA,vscode(需使用插件)等都有自动生成hashCode()的功能,很多时候只需要点两下鼠标就行,如果你真想自己写哈希函数,请记住以下三个原则:
一致性——等价的键必定产生相等的哈希值
高效性——计算简便
均匀性——均匀散列所有键
基于拉链法的散列表
Java 标准库的 HashMap 基本上就是用 拉链法 实现的。 拉链法 的实现比较简单,将链表和数组相结合。也就是说创建一个链表数组,数组中每一格就是一个链表。若遇到哈希冲突,则将冲突的值加到链表中即可。
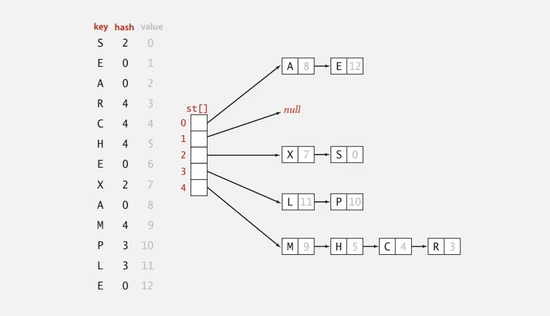
我们需要使用M条链表来保存N个键,无论键的分布如何,链表的平均长度肯定为N/M;具体实现代码如下:
定义链表,采用顺序搜索:


public class SequentialSearch<K,V>{ private Node first; private class Node { K key; V value; Node next; public Node(K k,V v,Node next) { this.key=k; this.value=v; this.next=next; } } public V get(K key) { for(Node x=first;x!=null;x=x.next) if(key.equals(x.key)) return x.value; return null; } public void put(K key,V value) { for(Node x=first;x!=null;x=x.next) if(key.equals(x.key)) { x.value=value; return ; } first=new Node(key,value,first); } }
基于拉链法的散列表:
1 public class ChainHash<K,V> { 2 3 4 5 private int N; 6 7 private int M; 8 9 private SequentialSearch<K,V>[] array; 10 11 12 13 public ChainHash() 14 15 { 16 17 18 19 } 20 21 @SuppressWarnings("unchecked") 22 23 public ChainHash(int size) 24 25 { 26 27 this.M=size; 28 29 array= (SequentialSearch<K,V>[])new SequentialSearch[M]; 30 31 //Java不允许创建泛型数组,需要强制转换 32 33 for(int i=0;i<M;i++) 34 35 { 36 37 array[i]=new SequentialSearch(); 38 39 } 40 41 } 42 43 44 45 private int hash(K key) 46 47 { 48 49 return (key.hashCode()&0x7fffffff)%M; 50 51 } 52 53 54 55 public V get(K key) 56 57 { 58 59 return (V)array[hash(key)].get(key); 60 61 } 62 63 64 65 public void put(K key,V value) 66 67 { 68 69 array[hash(key)].put(key, value); 70 71 } 72 73 } 74 75
线性探测法
用大小为M的数组保存N个键值对
通过散列函数hash(key),找到关键字key在线性序列中的位置,如果当前位置已经有了一个关键字,就长生了哈希冲突,我们直接检查散列表的下一位置, 此时会产生三种结果:
- *命中:该位置的键和被查找的键相同(更新value)
- *未命中:该位置没有键(插入相关Key-Value)
- *继续查找:该位置的键和被查找的键不同

代码实现:
这里使用了并行数组,一条保存键,一条保存值
1 public class LineHash<K,V> { 2 3 4 5 private int N; 6 7 private int M=16; 8 9 private K[] keys; 10 11 private V[] values; 12 13 14 15 public LineHash() 16 17 { 18 19 keys=(K[])new Object[M]; 20 21 values=(V[]) new Object[M]; 22 23 } 24 25 26 27 private int hash(K key) 28 29 { 30 31 return (key.hashCode()&0x7fffffff)%M; 32 33 } 34 35 private void resize() 36 37 { 38 39 //TODO 40 41 } 42 43 44 45 public void put(K key,V value) 46 47 { 48 49 int i; 50 51 for(i=hash(key);keys[i]!=null;i=(i+1)%M) 52 53 { 54 55 if(keys[i].equals(key)) 56 57 { 58 59 values[i]=value; 60 61 return; 62 63 } 64 65 } 66 67 68 69 keys[i]=key; 70 71 values[i]=value; 72 73 N++; 74 75 } 76 77 78 79 public V get(K key) 80 81 { 82 83 int i; 84 85 for(i=hash(key);keys[i]!=null;i=(i+1)%M) 86 87 { 88 89 if(keys[i].equals(key)) 90 91 return values[i]; 92 93 } 94 95 return null; 96 97 } 98 99 100 101 @Override 102 103 public String toString() 104 105 { 106 107 StringBuilder sb=new StringBuilder(); 108 109 for(int i=0;i<M;i++) 110 111 { 112 113 sb.append(i+" ").append(keys[i]).append("= ").append(values[i]).append("\n"); 114 115 } 116 117 return sb.toString(); 118 119 } 120 121 122 123 }
