DB2基础学习3
1、 规范化的目的:
(1) 消除冗余数据,例如在多个表中存储相同的数据;
(2) 强制有效数据的依赖,并把关系数据拆分到多个相关表中;
(3) 将系统在数据结构和未来增长中的灵活性最大化;
2、 第一范式不能拆分;第二范式不能重复;第三范式不能冗余。
数据冗余的代价,首先是空间代价,其次是管理代价,维护数据的完整性。它的好处是:减少查询所要连接表的个数,减少了IO和CPU时间,加速了查询。所以,在规范化时,应该保证查询带来的收益应该大于两次查询之间进行维护所需要的额外时间。数据应当按访问和修改的频率和重要性进行组织,常用的反规范化技术包含增加冗余列、增加派生列、重新连接表和分割表。
3、 合理使用建表选项
(1) compression,启用它可以节省大约70%的磁盘空间,并可以提高大约20%的IO性能,但是它对减少CPU耗费没有直接的帮助。
(2) APPEND ON,若启用,对于需要大量插入操作的表,DB2就不需要再插入的过程中寻找空闲的空间了,而只需要简单的将数据记录加到表的末尾,这样,空闲空间的信息页没有必要保存了。
(3) Pctfree,用来维护磁盘上空闲的空间,为插入、导入(load)和重组(reorg)操作服务。缺失值为10,若表中还有聚集索引并有大量的插入操作,则该值可以调到20-35。注意,若使用了append on选项,则pctfree应该设置为0.
(4) Partition by range 用来支持快速的加载和分离数据。
(5) Volatitle 会建议优化器尽量使用索引扫描。这个选项表明表的基数可以很大的范围内显著变化,从一个很大的数一直到空。这样就促使优化器不管表的统计数字如何,都使用索引扫描,而不是使用表扫描。不过,只有再索引包含所有被引用的列,或者可以再索引扫描时应用谓词的情况下,上述情况才会出现。
4、 索引的性能优势表现在:
首先,为表中被请求的数据行提供直接指针;
其次,消除了排序;
最后,避免了对基表的访问,可以使用全索引扫描。
(1) 聚集索引和非聚集索引
聚集索引中,数据页中行的顺序与索引中行的顺序时对应的,在一个表中只能有一个聚集索引,可以有多个非聚集索引。可以用create index语句的cluster子句来创建聚集索引。一般情况下,建议在小数据类型(如integer)上或是查询中频繁用于范围搜索的列上建立聚集索引。
(2)唯一索引和非唯一索引
为表定义了唯一索引,则每当在索引中添加insert或更改update键时就会强制检查唯一性,若不符合唯一约束条件,则操作失败。
(3)分区索引和非分区索引
对于分区索引,每个表分区都有自己的索引分区,它是分区表创建索引时的默认类型。每个索引分区都存放在与数据表空间相同的表空间内(默认)。分区数据可以具有非分区索引(存在于一个数据库分区中的单一表空间中),可以具有一个或多个分区索引或同时又这两种索引。
(4)块索引
(5)XML索引
(6)文本搜索索引
5、索引的相关原理
(1)用索引避免表扫描
访问一个表的数据有2种方法:第一:表扫描,通过顺序扫描整个表。第二:索引扫描,通过首先访问表上的索引来定位到某一行,然后再访问该行。
在下列情况,数据库会使用索引扫描:
A、 需要在访问基表前,缩小符合条件的记录集时。索引的扫描范围取决于查询语句中值的情况,以及索引中进行比较的列的情况。
B、 需要将结果排序。
C、 用索引来直接得到所需列的数据。若所需要的数据都在索引中,那就没有必要访问索引所在的基表了。这就是通常所说的index-only access,或“完全索引访问”。
D、 物化查询表(MQT)的使用,也可以避免表扫描。
注意:并不是你建立的索引一定会在查询中用到。当索引无法为查询提供帮助时,或是优化器认为索引扫描的执行成本更高时,优化器就会选择表扫描。因为相比表扫描而言,索引扫描在下列情况会产生更高的执行成本:
1)表很小。
2)索引聚集度很低。
3)表的大部分要被访问。
(2)完全索引访问
如有的列不再索引中,那样的话,要访问这些列的数据,就必须从基表中访问相应的行。通过增加一个唯一索引,并包含include相应的列,可以很好的解决这个问题。
比如:

唯一索引XACCT增强了ACCT_GRP和ACCT_ID列的唯一性,同时也保存了ACCT_NAME和ADDRESS列的数据。如此,查询语句就满足只访问索引,而不访问基表了。即,可以使用include将其他没有被索引的列包括到索引页中来,以实现完全索引访问,并避免了从数据页取数据
(3)双向索引
默认只支持对索引正向的扫描,或者是在create index语句中明确指定的扫描方向。Allow reverse scans双向索引允许按正反2个方向进行扫描,若指定disallow reverse scans 则不能反向扫描。
6、索引设计原则
1)避免多余的索引
若表建立过多索引会影响insert,update和delete语句的性能,因为表中的数据更改时,所有索引都必须进行适当的调整。
但,对于不需要修改数据的查询select,大量索引有助于提供性能,因为数据库有更多的索引可供选择,以便确定以最快速度访问数据的方法。
2)索引对列的选择
对列做索引时有条件的,那就是,
A、 大量值;
B、 在查询中经常用到
C、 在连接中经常用到。
D、不要对存在大量相同值的列做索引,不对那些更新操作比查询次数还多的表做索引
E、避免在索引列上使用is null 和 is not null.
F、避免在索引中使用任何允许为空的列,数据库将无法使用索引
3)组合索引
一个组合索引相当于多个单列索引,如索引(colA,colB,colC)至少相当于(colA)、(colA,colB)、(colA,colB,colC)三个索引。对于组合索引,把在查询语句中对多被访问的列放到第一个位置。
组合键的候选列的顺序,主要考虑两个因素:
A、 列的基数,基数大的列一般放在基数小的列的前面。
B、 需要考虑应用中的经常使用的谓词。那些经常在谓词中出现,用于指定查询条件的列,应该放在其他列的前面。
4)键的选择
A、使用系统生成的主键
B、不要用用户的键(不让主键具有可更新性)
C、外键的使用
5)确保所创建的索引会被使用
6)尽量使用index-only
大部分情况下,创建唯一索引时可以使用include语句将查询中需要访问的列加入到索引键值中,这样有利于index-only访问的实现。这种方法只可在唯一索引中使用,并且额外的列不会影响索引的唯一性。
7)不要索引常用的小型表
8)索引优化向导
使用索引优化向导(db2advis)帮助分析查询,确定要创建的索引。
7、索引维护
Runstats命令,用于收集关于索引的统计信息,这些信息帮助优化器对通过索引访问表进行更准确的成本估算。另外,建议在创建了聚集索引之后,运行reorg命令,或者是排序操作。
8、分区表
分区表根据表分区键,将表数据分布到多个数据分区中。数据分区是表的以部分,并与其他记录分开存储。根据create table语句的partition by 子句中指定的内容,给定表的数据被划分到多个数据分区中。这些数据分区可位于不同表空间或同一表空间中。如果一个表使用了partition by子句创建,那么该表是分区表。
指定的所有表空间都必须具有相同的页大小、扩展数据块大小、存储机制(DMS或SMS)和类型,且所有表空间都必须位于同一数据库分区组中。
分区表的优势:
(1) 增加了表的功能。数据可以分区、分表空间存放,方便进行数据的转入转出。
(2) 提高SQL处理性能。如用户要访问某一月份的数据,可直接对相应的分区访问即可,避免对不感兴趣的数据的访问;同时,数据放在不同的表空间,在进行数据访问,可以进行并行I/O,以提高访问效率。另外,还有索方面的好处,即可以对相应分区加锁,避免对整个表加锁,大大提高数据库的并发性。
(3) 可以在不同的表空间放置索引,提高效率。

9、分区表全局索引
全局索引作为所有分区的单一对象来存储。默认情况下,和第一个数据分区在同一个表空间内。用户可以在不同的表空间内创建,在create table 中使用index in ,在create index中使用in子句。当创建全局索引时,要求使用not partitioned子句,一般情况下,土建将索引放置在大型表空间中。

10、分区表分区索引
即每个表分区都有自己的索引分区。使用数据分区定义中的index in子句来覆盖(create/alter table)。注意,Create 的in子句不允许作用于分区索引。
相对全局索引的优势:
(1) 对索引的安排可以更细微的控制,可以任意指定存放的表空间。
(2) 增强删除或创建在线索引的性能,当索引被删除时,空间即被释放。
(3) 因为减少了I/O操作,将提高更有效的数据并发访问。

SQL语句性能优化
1、 sql语句编写
(1) 谓词
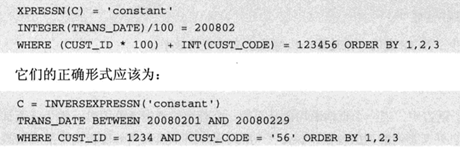
保证谓词足够简洁。如:列名=常数表达式,这样便于匹配索引。还应该避免使用类型转换,若有类型转换,应该显示的写出转换函数,并放在表示式的常数一边:
Cast(col1 as int)=100 应该写为:
Col1=cast(100 as char(10));
另外,在使用参数标记时,尽量利用cast函数表明他的类型,以免产生不必要的类型转换;
(1) 子查询
如果一个来自外部查询的列出现在where子句的子查询中,那么当外部查询中的列值改变后,子查询需要重新查询一次。查询嵌套的层次越低,效率越低。
若子查询不可比卖你,首先要将子查询中尽量去掉多余的行,其次,考虑将子查询转换为连接。特别时exists和in子句,可以方便地转换成连接。
(2) 外连接
避免不必要的外连接(outer join),outer join会限制连接的顺序,从而导致一些好的计划无法生成。因此避免使用outer join,无论时left 、right或者是full outer join。
(3) Union all的使用
注意union all的谓词是否被下推了。没有下推,可能是选择谓词过于复杂了。
(4) Having子句
检查having子句的谓词是否可以下推。尽可能的把having子句的谓词转换为where子句的谓词。为了避免没有被下推的情况,在编写sql时就应尽量将能下推的谓词写在where子句里面。
(5) OFNR和FFNR子句
OFNR:optimize for n rows子句使优化器选择那些执行时能最快得到前N行结果的访问计划,不过查询仍将返回完整的结果集。
FFNR:fetch first n rows子句显示查询只需返回n行,这样减少了返回结果集。
注意,db2不会因为指定了FFNR而选择最快的访问计划,索引应该在使用FFNR时,同时使用OFNR.
另外,若应用程序要获取整个结果集,但却指定OFNR,可能会使性能降低,因为最快的返回前N行的访问计划不一定是对于获取整个结果集最佳的访问计划。
2、 统计信息
Runstats on table myuser.tb with distribution and sampled detailed indexes all;
with distribution:用于收集列分布统计信息,这些信息可以让优化器知道列的数据分布情况。
detailed indexes all:用于收集详细的索引统计信息。然而对于数据量很大的表收集详细的索引统计信息会消耗很多的CPU和内存。Sampled选项可以减少统计信息收集过程中cpu和内存的消耗。
Runstats on table product on column((color,elasticity));
如此,优化器会考虑color和elasticity列的相关性,得到更精准的开销估计。
对于 like谓词,应该考虑收集子元素统计信息。收集子元素统计信息前,要满足两个条件:谓词中的列的值应该都是由空格分开的单词或子元素组成的字符串;like谓词的模式部分带有%通配符,且不是在模式的末尾。为了收集子元素统计信息,需要运行runstats时指定like statistics选项。
Rinstats也有缺陷,会对系统的性能产生影响。为了减少影响,可以考虑以下的方法:
1) 通过columns选项来限制要收集统计信息的列。
2) 对于值分布很一致的列,不必收集分布统计信息。
3) 通过tablesample system(页级抽样)或bernoulli(行级抽样)选项,使runstats利用页面或行级别的抽样来收集统计信息。
3、 解释工具
1) 在sql语句前加上explain plan with snapshot for,或者explain plan for。这回解释查询而不会执行查询。
2) 对于动态sql,在执行sql前,先运行set current explain explain 和set current explain snapshot explain
3) 在绑定的时候,将explain或explsnap选项设置为yes或者all。
4、 存储过程优化
存储过程的好处:封装 和 缓存:存储过程的代码时预先编译的。
1) 直接合并多条语句


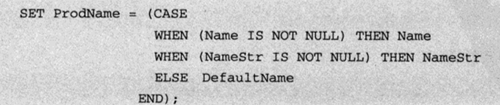
2) CASE表达式的使用代替IF语句

3) 使用sql代替逻辑块
有时候,循环、赋值和游标等过程化构造允许我们表达那些只使用sql语句不可能表达的逻辑。

4) 使用临时表
使用临时表比常规表的操作快,主要时以下原因:
A、 临时表的创建不会涉及向编目表中插入行,且临时表的使用也不会涉及对编目表的访问;因此,不会有编目表争用问题;
B、 临时表只能由创建他们的应用程序访问,因此其操作不会涉及锁的问题;
C、 若指定not logged选项,则不对临时表上的操作记录日志。
5) 保持统计信息的准确性
6) 出错处理
5、 数据在线优化
1) reorgchk
该命令返回有关数据组织的统计信息,并且建议是否需要重组表。
比如想更新表myuser.test的统计数据,根据统计数据判断是否需要重组表,可以使用带update statistics选项的reorgchk命令,具体如下:
Db2 reorgchk update statistics on table myuser.test;
2) reorg
确定需要重组的表之后,就可以对这些表运行reorg程序,并且可以选择对这些表上定义的索引进行该程序。
Db2 reorg table myuser.test;
要使用临时表空间tempspace1重组表myuser.test,可以子啊命令中使用带use tempspace1选项的reorg table命令:
Db2 reorg table myuser.test use tempspace1;
想要重组表并根据索引A1对行进行重新排序,使用带index选项的reorg table命令:
Db2 reorg table myuser.test index a1;
在使用allow write access选项进行reorg indexes命令时,如果同时允许对指定的表进行读写访问,则会重建该表的所有索引。进行重组时,对基础表所做的任何更新,以及导致索引的更改,都将记录在db2日志中。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号