DB2的基础学习
1、DB2数据库的逻辑结构分别为:实例-->数据库-->表空间-->表。
表是二维结构,由行和列组成,表数据存放在表空间里,表空间是数据库的逻辑存储层,
每个数据库可以包含多个表空间,每个表空间只能归属于一个数据库,所以数据库和表空间的关系是一对多。
2、DB2的存储模型为:表空间---->容器---->extent------>page。
每个表空间由一个或多个容器组成,容器是映射到物理存储,容器可以是目录、文件、裸设备。每个容器只能属于一个表空间。
DB2将表和索引存储在PAGE页里,page是db2中最小的物理分配单元,表中的每行数据只能包含在一页中,不能跨页。
DB2支持的页大小分为:4K、8K、16K、32K四种。
当DB2在读取数据的时候,不是按页读取,而是按照extent(块)读取,一个extent是由一组连续的页组成。
如果一个表空间有多个容器,为了数据均衡的分布,所以在写数据的时候,按照循环的方式在各个容器里写数据,
当一个容器中写满一个extent的时候,将开始在第二个容器继续写extent,周而复始,可以提高读写的效率。
每个表空间由一个或多个容器组成,表空间为逻辑层次中,而真正的数据是存放在容器中的,容器是由多个extent组成。
3、主键的数据类型设置为不变长的,如char和varchar则建议选择用char.
注意字段的默认长度:
smallint——占用2个字节,表示的数值范围:-32768至+32767
integer——占用4个字节,表示的数值范围:-2147483648至+2147483647
bigint——占用8个字节,表示的数值范围:-9223372036854775808至+9223372036854775807
decimal——占用的字节数与数据类型的精度相关,最大精度为31
number,real,float这三种类型不常用。
varchar——占用N个字节,N的最大值为32672
char——N的最大值为254
long varchar不常用
date——占用4个字节,表示的日期范围:0001-01-01至9999-12-31
time——占用3个字节,表示的时间范围:00:00:00至23:59:59
timestamp(N)[with time zone]——占用7-13个字节,N的取值范围为0-12,默认为6
表示的数值范围:0001-01-01 00:00:00.000000 至9999-12-31 23:59:59.999999
4、随机抽样查询
select * from table_name fetch first 10 rows only;
5、如果有五张表关联,数据库里面同时参与关联的只能是两张表。
6、多表更新问题~嵌套 采用where exists
7、truncate和delete区别:
truncate不记日志,速度快,不可逆操作,空间立刻释放,表和表的索引重置为初始大小,不删除表结构
delete 记日志,可逆,较慢,空间没有立刻释放,一行一行的删除数据,不删除表结构
8、merge into 可以同时进行插入,删除和更新操作
MERGE INTO t_target as tt
USING t_source as ts
ON tt.col1 = ts.col1
AND tt.col2 = ts.col2
WHEN MATCHED THEN
DELETE
WHEN NOT MATCHED THEN
INSERT (col1,col2,col3)
VALUES(ts.col1,ts.col2,ts.col3) ;
9、集合操作符:
union[all]并集,intersect[all] 交集,except[all]差集
是否带all,意味是否要去重
10、存储过程,包括:对象声明,异常处理,程序主体,程序结束
对象声明~定义变量,游标
异常处理~定义异常类型,捕捉并处理
程序主体~业务逻辑sql语句
程序结束~结束事务,提交数据
create or replace procedure 这类语法不能用于建表
CREATE OR REPLACE PROCEDURE schema.sp_1
(
IN i_var1 INTEGER
)
LANGUAGE SQL
BEGIN
<SQL>
END
;

11、数据库的核心:事务和日志
事务:独立的逻辑执行单元,是恢复和并发控制的基本单元。特性:ACID
12、寄存器常量
Current_user
Current_date
Current_time
Current_timestamp
13、between a and b:b 不能小于a
14、四舍五入函数
ROUND(3.14555,4)=3.14560
CAST( ROUND(3.14555,4) as numeric(20,4) = 3.1456
15、数据迁移: insert,import和load三种
(1)load数据加载
LOAD命令主要用于将外部文件中的数据加载至DB2数据库内,也可以完成库内表之间的数据迁移。
其主要特性:
1、加载速度较快
2、不记录数据操作日志
3、不做检查约束和参照完整性约束,不触发Trigger,锁的时间比较短
因此特别适合大数据量的导入。
使用建议:
1、目标表上最好不要有约束
2、目标表中最好不要有任何数据,即空表加载。
3、如果不在本地,就要使用 load client from ...命令,否则load from..即可。无论何时,我们应该优先选用load命令来完成导入数据,因为他的效率比import要高,而且高很多。
DB2导出表的几种格式ASC,DEL,WSF,IXF
ASC = ASCII
DEL = Delimited ASCII 表示源文件为定长的ASC文件
WSF = Worksheet format
IXF = Integrated Exchange Format
ASC 和 DEL 格式的文件是文本文件,可以用任何文本编辑器打开。
WSF 格式的文件可以将数据迁移到电子表格软件中,例如 Excel,Lotus® 1-2-3。
IXF 格式文件包括了数据表的数据描述语言(DDL)和里面的数据。使用 IXF 格式是非常方便的,利用它可以重建数据表,而其他格式则没有办法这么做.
当数据导出到文件后,使用 Import 可以将数据由文件导入到数据表中。如果使用 ASC,DEL 和WSF 格式的文件作为中间文件,在它们导入之前数据表必须存在。而使用 IXF 格式的文件在导入前不需要存在相应的数据表。
具体参考以下博客:
https://www.cnblogs.com/xiaojianblogs/p/6920411.html
https://blog.csdn.net/qq342643414/article/details/77884192?locationNum=8&fps=1
(2)import数据加载
IMPORT主要完成外部文件加载至DB2数据库的目标表中。
主要特性:
1、加载速度相对较快。
2、需要记录数据操作的事务日志。
3、可分批提交
使用建议:
1、待加载的数据文件应相对较小。
2、尽量保持目标表是空表。
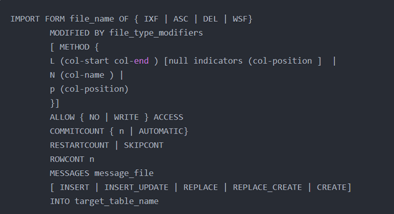
import from c:/data.ixf of ixf commitcount 1000 modifiry by compound=100 insert into table;
https://www.jianshu.com/p/7d886a33e7ec
(3)export数据导出
EXPORT工具主要用于将数据库内表的数据导出至文件。
主要特性:
1、可以从单表/多表关联的结果集中导出数据
2、导出速度较快
3、支持多种分隔符
使用建议:
1、在导出大数据量时,最好能分批导出成多个文件。
2、最好能从单表中直接导出数据。
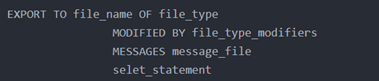
其中
- file_type 包含的格式有:DEL、IXF、WSF等
- message_file用于保存export过程中输出的信息
- file_type_modifiers是指文件类型修饰符,常见的文件类型修饰符如下:
- CHARDELx:x表示用来指定的字符串定界符。默认值是双引号(“”)。
- COLDELx :x表示的列定界符。默认值是双引号(,)。
- CODEPAGE=x:x用来表示将字符串导入文本数据时使用的编码。
- decplusblank表示对于十进制数据类型,用空格代替最前面的加号,因为默认情况下会在十进制数据前面加上正负号的。
- Timestampformat=“x”:x是源表中时间戳记的格式。(YYYY/MM/DD HH:MM:SS.UUUUUU、YYYY/MM/DD HH、YYYY-MM-DD HH:MM:SS TT、MMM DD YYYY HH:MM:SS:UUUTT、MMM DD YYYY HH:MM:SSTT)
在EXPORT中使用文件修饰符的方法如下: - 【NODOUBLEDEL、LOBSINFILE、DECPTx(x表示的小数点定义符)、DATESISO、STRIPLZEROS、NOCHARDEL、LOBSINSEPFILES、XMLINSEPFILES、XMLCHAR、XMLGRAPHIC、XMLNODECLARATION】
https://blog.csdn.net/peterxiaoq/article/details/50923096
import与load的区别
使用命令:db2 ? import //查看import语法
从参数上面来看,总体上没有太大的区别。
◆import只支持文件导入,load除了支持文件的导入,并且还支持游标、管道等输入源;
◆对于输入源为文件时,同样支持ASC、DEL、IXF三种数据文件格式;
◆对于导入动作时,均支持INSERT、REPLACE等动作,load工具相对于import来说少了CREATE、INSERT_UPDATE、REPLACE_CREATE等动作,但多了RESTART、TERMINATE等动作。
◆load不支持文件放在客户端,只支持文件在服务端的情况,而import支持文件放在客户端。
◆import是实时对一致性检查的,而load工具是在数据导入完成后再做一致性检查的,这样load的性能就远远高于import。
◕对于客户端的文件类导入建议使用import;
◕对于数据归档或者服务端文件导入,建议使用load进行;
◕对于import,我们可以通过优化COMMITCOUNT、COMPOUND选项来适当提升导入性能。
十个建议:
1、 数据类型:精准的定义表中各字段的数据类型,有利于提升SQL语句执行的效率。
2、 查询条件:关联条件与过滤条件应区别清楚,严格按条件类型写在ON与WHERE子句中。
3、 临时表:对临时表的所有操作,均不要记录事务日志。
日志主要用于事务的数据恢复,确保事务的完整性与数据的一致性。
DECLARE GLOBAL TEMPORARY TABLE tmp1
(c1 INTEGER)
WITH REPLACE NOT LOGGED
ON COMMIT PRESERVE ROWS ;
// NOT LOGGED是不记录事务日志,
// WITH REPLACE是程序结束后删除该临时表;
// ON COMMIT PRESERVE ROWS 会话级临时表:会话结束时删除数据
// ON COMMIT DELETE ROWS 事务级临时表:提交时删除数据
4、 创建索引:
5、 存储过程:
存储过程是一系列SQL语句及控制语句的集合,也是零个或多个事务的集合。
在程序结束处,应至少有一条事务控制语句。
如果整个程序中有事务操作,但没有任何事务控制语句,则待程序运行结束后,程序体内的所有事务将回滚。
6、 语句分解:尽可能将最简洁、简单的语句/事务提交给数据库执行。
7、 函数:
能用自带函数实现的,尽可能不用外部函数;
能用派生字段实现的,尽可能不用函数。
8、 提交事务
尽可能早的/小的提交事务。
事务占据着大量的数据库资源,特别是 锁 与 日志。
9、 表空间:尽可能将数据表空间与索引表空间分开。
10、统计信息:要及时更新表、索引、关键字段的统计信息,有利于优化器生成更好的执行计划。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号