Estimating 6D Aircraft Pose from Keypoints and Structures学习笔记(PnP+PnL、中继监督)
Estimating 6D Aircraft Pose from Keypoints and Structures
前言
这篇论文在现有的姿态估计上提供了三个贡献:
1、 提出了新的方法PEKS检测6D飞机姿态估计,提高了网络在复杂天气情况下的姿态估计的精度;
2、 PEKS中包含了一个新的PnP+PnL的算法:PnPS算法,其通过关键点和结构估计RT矩阵;
3、 提供了一个21600张合成图像组成的飞机姿态估计数据集(APE),未公开暂无找到资源。
接下来细致介绍以上三点:
1、PEKS介绍
1.1 基本框架
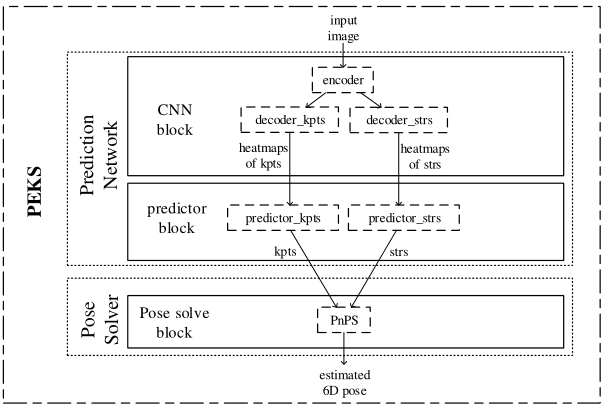
这是PEKS的基本框架,它是一个two-stage模型,分别为Prediction Network与Pose Solver。
我在阅读时误认为两部分都是神经网络模型,其实只有上半部分是神经网络(Network嘛,其实已经很明白了只是我以为two-stage必指R-CNN这种两段网络模型),而下半部分是一个基于数学最优化问题的算法。
预测时网络的输入为RGB图片,中间网络输出为图片中的关键点和结构,最终经过PnPs算法输出为6D姿态,也就是姿态估计中常见的R旋转矩阵、T平移向量。
训练数据的注释放在第三点讲。
1.2 Prediction Network结构
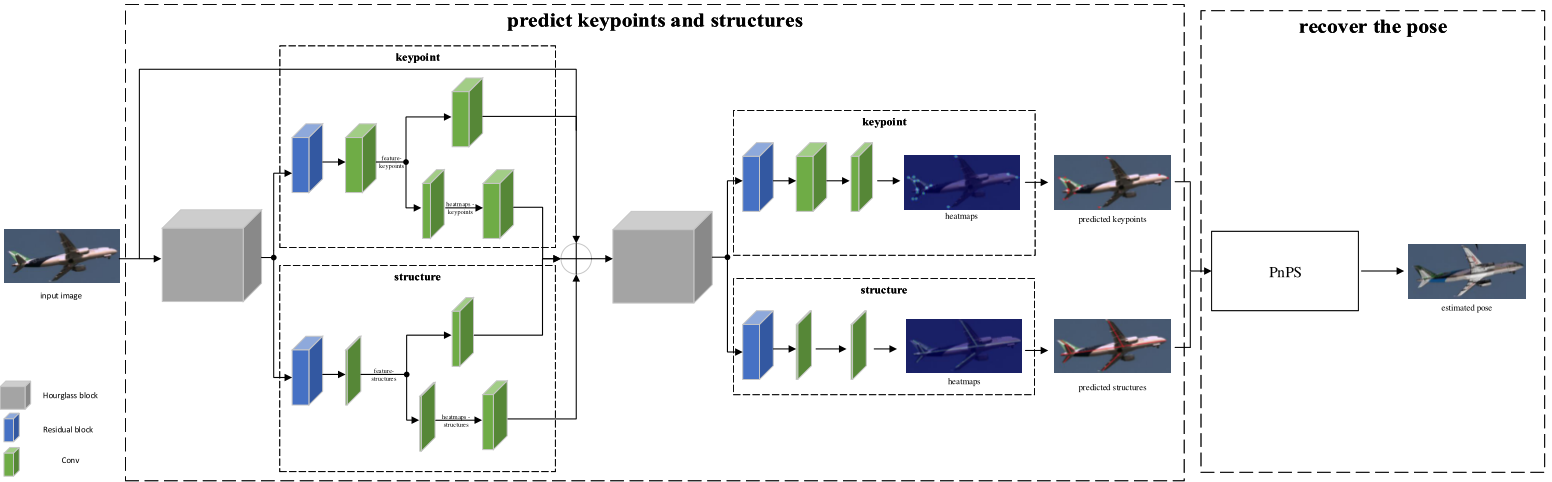
上图是预测网络的详细架构,所提出的网络是一个多级体系结构,灰色方块为堆叠沙漏网络。裁剪后的图像被输入网络,两个沙漏组件被用来生成每个关键点的热图。热图的强度表示各个关键点在每个像素上被定位的概率。
CNN通过两个阶段的架构共同预测关键点和结构,在网络的第一阶段,预测关键点和结构的热图,进行中间监督。
第二阶段以合并后的第一阶段特征和热图作为输入;网络的最终输出是第二阶段预测的热图。在每个阶段,均方误差损失被用来比较预测的热图和地面真值热图。然后,利用PnPS算法根据预测的关键点和结构恢复6D位姿。(该段原文摘录)
1.3 Hourglass block
其中Hourglass block可能平时不常见(可能是我论文读的少),但在姿态估计任务中是常用的一个网络模块。
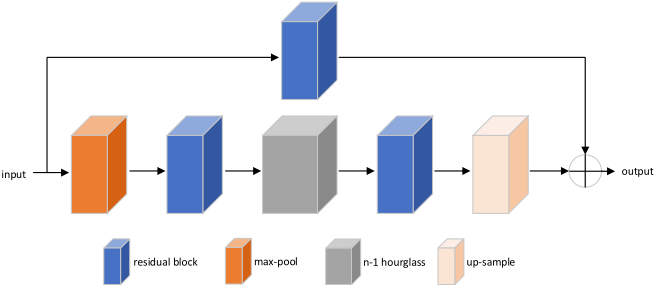
上图是n层hourglass网络结构图,其中n-1层与n层结构相同,n-2同理,hourglass网络边上如此递归形成。
Motivation:使用沙漏网络的目的是为了反复获取不同尺度下图片所包含的信息。例如一些局部信息,包括脸部和手部信息。最后的人体姿态估计需要对整个人体做一个理解,因此需要结合不同尺度下的信息,人体的方位,肢体的动作以及相邻关节点的关系。
Design:单个的hourglass模块对应的是一个residual模块,它的拓扑结构是对称的。最开始的卷积层和池化层是为了将特征映射到很小的分辨率。每经过一次池化,进行一次下采样,网络从这里开始分叉——下采样之前的特征图经过卷积保留下来,和之后bottom-up上采样到相同分辨率的特征图融合;下采样之后的特征图继续卷积池化操作。当达到最小分辨率后,网络开始上采样,使用双线性差值,并开始融合不同尺度的信息。Hourglass网络的输出再经过两个连续的1*1的卷积处理,得到最终的输出。输出是一个heatmap的集合,表示的是各个关节点在该像素出现的概率(即置信度)。
中继监督
Hourglass网络输出heatmap的集合(蓝色),将这与ground truth进行误差计算,其中使用1*1的卷积层进行处理是为了保证通道数相同,这是一种保证通道数相同很常见的方法,对每一个hourglass网络都添加loss,这就相当于是8个loss一起监督。测试
采用MPII数据集,以人为目标裁剪图片。Resize到256*256,+/-30度旋转,0.75-1.25尺度变换。测试的时候,原始图片和翻转图片,输入到网络中,取输出的heatmap的平均值,最终输出的各heatmap的最大值作为关节点的位置。总结
本文的设计基于模块到子网络再到完整网络的思想。一阶hourglass网络就是一个最简单的旁路相加,上半路在原尺度进行,下半路先经历下采样再进行上采样。对于二阶hourglass网络,就是在一阶的基础上将一阶网络嵌套进来。至于之后的高阶hourglass就是一层一层嵌套,从本质上说子模块都是一样的。模块特点:
每次下采样前,分出一路保留原尺度信息
每次上采样之后,和上一尺度的特征融合
两次下采样之间,用三个residual模块提取特征
两次相加之间,使用一个residual模块提取特征
因此整个hourglass不改变特征的尺度,只改变特征的深度。
————————————————
版权声明:本文为CSDN博主「青青韶华」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_36165459/article/details/78321529
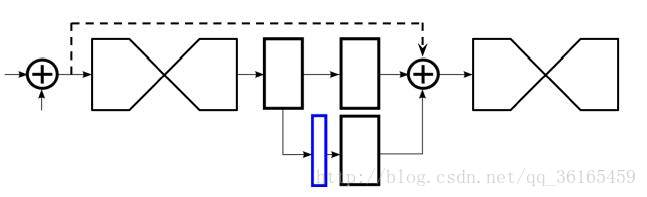
1.4 loss与中间监督
我看网上对于hourglass结构的中间监督的解释一笔带过,但我在这里纠结了很久,不是特别明白他说的添加loss含义以及具体实现手段,然后通过阅读原文,我明白了其具体做法,首先晒上原文中的图:
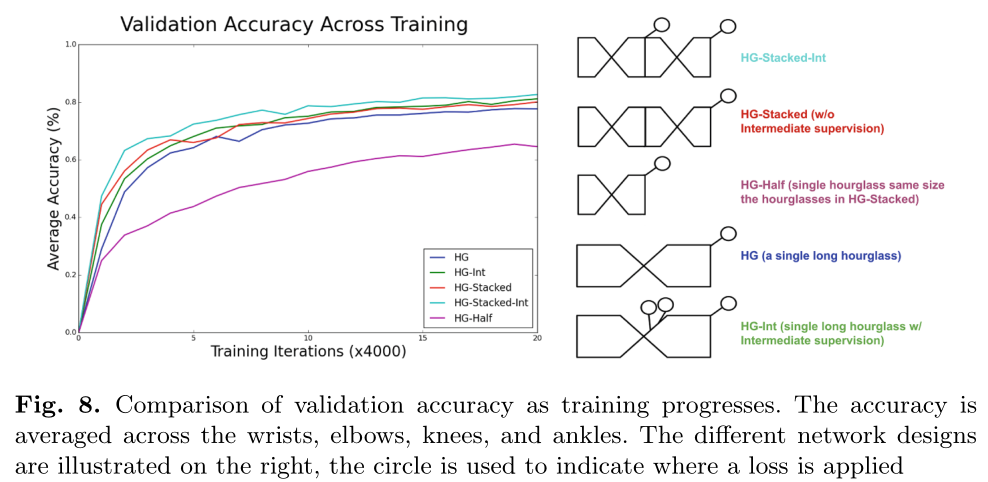
右侧是其将结果考虑入loss的一些地方,可以看到除了最后一种,其他的情况都是只考虑最后一层的loss(即H*W与原题大小一致时),而最后一种中间监督的方式是将一个hourglass的中间输出作为loss。
而我疑惑的地方正是这个中间输出的loss,它究竟是如何求误差的,首先hourglass原文是以常见的MSE作为loss函数,loss = Σ(yi-y)²;而在中间的输出层没有直接对应的GT来求loss,原文的方法是:max pooling前每四个像素点若含有关键点,则缩小得到的像素点为关键点;通过这种方式可以不用额外标注图片也能得到中间图片的关键点。每一个Houglass网络便单独计算一次loss,原Stacked Houglass论文整个网络中用了八个沙漏网络,这些网络的参数基于相同的GT使用各自的损失函数独立更新。
因为hourglass的输出为heatmap,每个像素的值为关键点/结构的置信度。
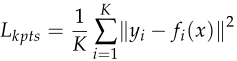
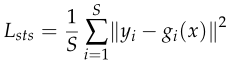
Lkpts,Lsts分别代表关键点与结构的loss函数。 fi(x),gi(x)中i代表第i个关键点/结构,而yi为ground truth heatmap。
所以总的损失函数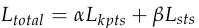
其中α,β为超参数,论文中提到一般分别预设为α = 1,β = 0.5
2、 PnPs介绍
2.1 问题背景

以上引用 https://zhuanlan.zhihu.com/p/399140251?utm_source=qq&utm_medium=social&utm_oi=546351940519534592
而PnL在网上能查找的资料有限,本质上要解决的问题相同,都是要求世界坐标系转换到相机坐标系的R、T两个未知数,只是输入为线段(向量)。
2.2 PnP与PnL的区别
有人可能会问:PnL本质不就是让两个关键点代表一条线段吗?那么这和PnP直接已知关键点求RT有什么区别呢?
我个人的理解是,PnL相对与PnP的鲁棒性更强,PnL中线并非固定某两个端点表示,只要两点所连的线与真实情况下两点所在的线相同即可。这反映了一个事实,即在实际中,3D参考线可能无法在图像中完全检测到,或者它们可能被部分遮挡,从而排除了基于点的PnP算法的使用。
PnP的常用方法:非迭代求解策略OPnP、EPnP;优缺点:抗干扰能力差、位姿求解精度差、求解速度快。
PnL的方法比起PnP少很多,主要分为线性与非线性方法;优缺点:无法在高精度的同时保证高效率,鲁棒性较强。
2.3 PnPs算法
PnPs结合以上两者的优势,在保证了算法准确度和鲁棒性的同时保证了速度,是一个PnP+PnL的算法。
下面介绍算法流程:
PnPs的输入由关键点K,与结构L组成。
对于关键点,它的优化方式与正常PnP的相仿,即最小化估计点与实际点的误差距离,如下图所示
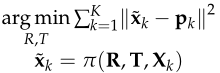
其中pk为关键点的估计坐标,Xk为关键点的三维坐标,x~k为Xk的二维投影,π为透视投影函数。
对于结构,我们用点P和方向向量d表示: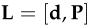 ,一个点加方向向量可以表示空间中的一条直线,而这条直线也就代表了所谓的结构L。
,一个点加方向向量可以表示空间中的一条直线,而这条直线也就代表了所谓的结构L。
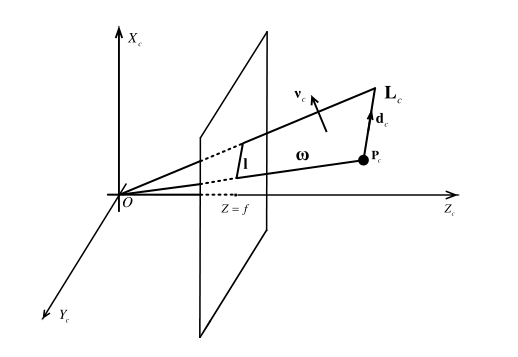
如图中Lc为点Pc和方向向量dc表示;c下标表示在相机坐标系下。
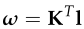 ,其中K为内参矩阵,主要由相机的焦距影响;l为结构在图像坐标系上的投影,w为由l决定的平面。
,其中K为内参矩阵,主要由相机的焦距影响;l为结构在图像坐标系上的投影,w为由l决定的平面。
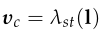 ,vc是刚刚得到的w平面的法向量,所以λst代表由l计算出的平面的法向量。
,vc是刚刚得到的w平面的法向量,所以λst代表由l计算出的平面的法向量。
根据数学知识可以得到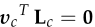 ,这个式子最后会用来验证误差。
,这个式子最后会用来验证误差。
用数学式表示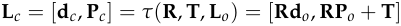 ,与上式结合可得:
,与上式结合可得:
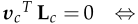
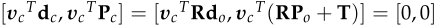
所以最终结构L优化的目标为: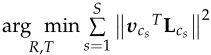
其中两个参数分别由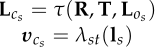 决定。
决定。
综合以上两个优化函数,PnPs的总优化函数为:

ck、cs分别代表关键点与结构的热图计算出的置信度。
3、数据集
这一节主要是想总结归纳一下飞机姿态估计能找到的数据集:
3.1 Aircraft-Pose-Estimation(APE) Dataset
本文介绍了一个新的飞机姿态估计数据集,它包含了3681张真实图像和216,000张渲染图像,称为APE数据集。本数据集中所有图像的大小为1920 × 1080。该数据集包含了飞机在飞行过程中可能遇到的大多数场景,能够有效地评估飞机姿态估计方法的鲁棒性。对于真实的图像,我们从不同机场的摄像机拍摄的79个视频中取样。这些图像是在不同的姿势下,如起飞,降落,盘旋,滑行,和不同的天气场景。这些注释包括摄像机的焦点和像素大小、2D包围框、6D姿态、3D包围框的投影、关键点的投影、结构的投影和天气场景。我们根据天气情况将图片分为四类:好天气、雾霾天气、大气抖动和过度曝光。图11展示了真实图像的示例。更重要的是,我们还为训练生成了216000张渲染图像。渲染后的图像是在OpenGL的帮助下,将3D飞机模型放置在背景图像的前面创建的。背景图像选取不同天气场景下人工拍摄的天空图像和KITTI数据集中模拟飞机在空中盘旋和地面滑行场景的道路图像。(以上译自原文)

目前还没能在网上找到APE数据集,应该是还未开源,所以要介绍的下一个数据集是已开源的可以用来训练的数据集
3.2 ObjectNet3D dataset
其是含有多个样本的姿态估计数据集,用于 3D 对象识别的大型数据库,名为 ObjectNet3D,它由 100 个类别、90,127 张图像、这些图像中的 201,888 个对象和 44,147 个 3D 形状组成。其注释为:Euler Angles + BoundingBox。
飞机所处ID:start_index:n04012084_17 ,end_index:n04012084_11662。包含飞机图片的总数约为400张。




因为这是一个大型数据库,无法直接看到图像上的标注,所以还需要通过在数据库中读取其标注才可。
标记文件的格式为:image_id,x1,y1,x2,y2,score,azimuth,elevation,in-plane rotation,其中x1,y1,x2,y2分别为左上、右下坐标边界框,分数是检测分数,方位角,仰角和平面内旋转在[-pi,pi]中
官方网站:https://cvgl.stanford.edu/projects/objectnet3d/
3.3 数据集标注总结
姿态估计注释一般有:6D姿态(RT矩阵)、Depth/Mask/BoundingBox(表三者其一)。
本片论文中数据集的标注有:摄像机的焦点和像素大小、2D包围框、6D姿态、3D包围框的投影、关键点的投影、结构的投影和天气场景
关于姿态估计(不仅飞机)的数据集github上有一个综述:https://github.com/YoungXIAO13/ObjectPoseEstimationSummary
4、 问题
论文中提到了一些PEKS存在的问题,有以下几个:
1、数据增强时不能通过水平翻转图片扩大数据集,否则会导致模型被混淆,导致预测的关键点和结构左右对称错位。(未解决)
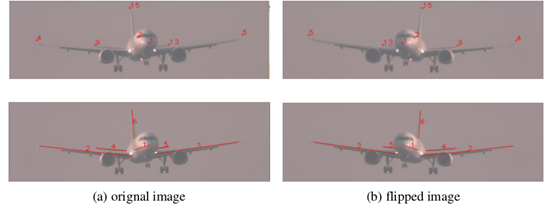
这个错误暂时没有想到原因,不知如何解决。
2、评估网络时,由于APE数据集与其他数据集中的G、T以及焦距差别较大;ADD指标评估下,正确性阈值需要有不同的设置,否则会导致不合理的评估结果。(可解决)
然而,这并不意味着我们的方法不能准确估计位姿参数。我们分析了这些算法在该数据集上失败的原因,发现APE数据集上图像的ground-truth T和焦距都比基准数据集大很多。对于APE数据集,在飞行器飞行过程中,相机与飞行器之间的距离变化较大,地真T范围在100 m到5 km左右。而在其他基准数据集中,以LineMOD数据集为例,ground-truth T约为1 m。用模型大小的10%作为阈值来评估算法的准确性是不合理的。此外,使用变焦镜头相机在飞行过程中清晰地捕捉飞机,焦距范围从30毫米到1000毫米。而在其他基准中,也以LineMOD数据集为例,焦距不超过100毫米。长焦距使得位姿参数的精确估计,尤其是T。
译自原论文

 浙公网安备 33010602011771号
浙公网安备 33010602011771号