


关于renderdoc中SV_position内信息处理
问题背景:
在游戏中截帧时想找到某些模型的图像坐标系上2D与世界坐标系中3D-Depth信息,用到了renderdoc这个软件截帧,通过分析得到其Mesh Viewer的VS Output中的SV_Position对我们解决问题有所帮助。
(这是一个没有接触过游戏图像开发的AI程序员的简单记录)
解决思路:
首先明确游戏渲染时坐标空间的变化关系:
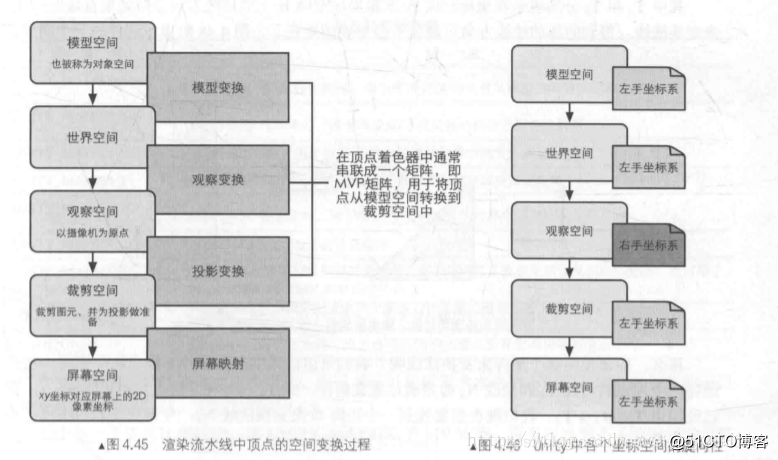
(图转自https://blog.51cto.com/u_15273495/2914633)
其次明确SV_position(以下简称为SVp)是在什么坐标下的表示。
这两篇博客可以参考:position与SV_position的对比,SV_Position的每个component都是什么
此处说明了SVp:用来存储,模型在裁剪空间(clip space),投影空间中的位置信息。
也就是说SVp中的点已经是3D模型在转换到剪裁空间中的点了。
其次是明确SVp四列各代表什么。
我们知道在转化为齐次裁剪矩阵前的空间坐标就是相机坐标中的三维坐标(x,y,z)
要转化为裁剪空间中的坐标系,即要经过投影矩阵才会变成齐次坐标系(x',y',z',w)。
关于转换到2D图像坐标系
所以我们知道现在SV_position转化到图像坐标系也就是屏幕空间上时需要经过屏幕映射(screen space,也就是电脑屏幕上)。
也就是裁剪后进行真正的投影,需要把视椎体投影到屏幕空间,最后会得到像素位置。
将顶点从裁剪空间投影到屏幕空间,来生成2D坐标。
屏幕映射具体过程:
第一步,需要进行齐次除法(homogeneous diision)
,就是使用齐次坐标系中的w分量去除以x,y,z分量,在OpenGL中这一步得到的坐标也被乘坐归一化的设备坐标(Normalized Device Coordinated, NDC).
把坐标从齐次裁剪坐标中转化到NDC中后,裁剪空间会变换到一个立方体中。分量范围在[-1, 1]。
在Unity中,屏幕左下角是(0,0),右上角是(pixelWidth,pixelHeight),由于立方体内的坐标都是[-1,1],因此映射过程就是一个缩放的过程。
通过齐次除法的屏幕映射可以总结为下面的公式:

平面中z轴一般用不到,先记录在此以备不时之需。
更新:深度即为z=z‘/w
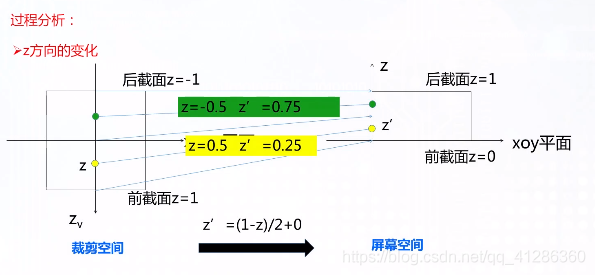
至此SV_position转化至2D图像坐标系问题已解决。
可以参考这里,有更详细的过程解释,本文只需能用不深究公式。
关于转换到3D世界坐标系
由SV_position转到世界坐标系,需要经过转换到相机坐标系(观察空间)再转换到世界坐标系(世界空间)。
这里要注意,与真实相机相关的坐标系转换中没有裁剪矩阵这一步,是游戏中(如unity编写的)为了确认渲染范围才有的齐次裁剪矩阵的步骤!
这里强调是为了防止混淆二者的概念,因为再迁移学习中的Syn2real时,可能会不清楚二者的过程导致思路不清,从而不知道在数据采集时如何将renderdoc中的数据转化为所要求的数据集。
我们要先将SV_position转换为观察空间中的坐标系,再利用RT的6D信息来转化相机坐标与世界坐标,其中R、T指旋转矩阵R与平移向量T。而姿态估计任务中最后预测的数据也是R和T(通常做法是通过网络预测出的关键点Keypoint,将点给PnP算法让其预测RT)。
SVp转换到观察空间的过程如下:

(图转自https://blog.51cto.com/u_15273495/2914633)
具体到renderdoc中可能式子需要进行一些变化,因为FOV、Far、Near这些参数都暂未发现。
假定相机视角下的3D坐标已知,下一步是找到renderdoc中的RT。
找到了renderdoc中的TransformVS即R旋转矩阵与T平移向量。
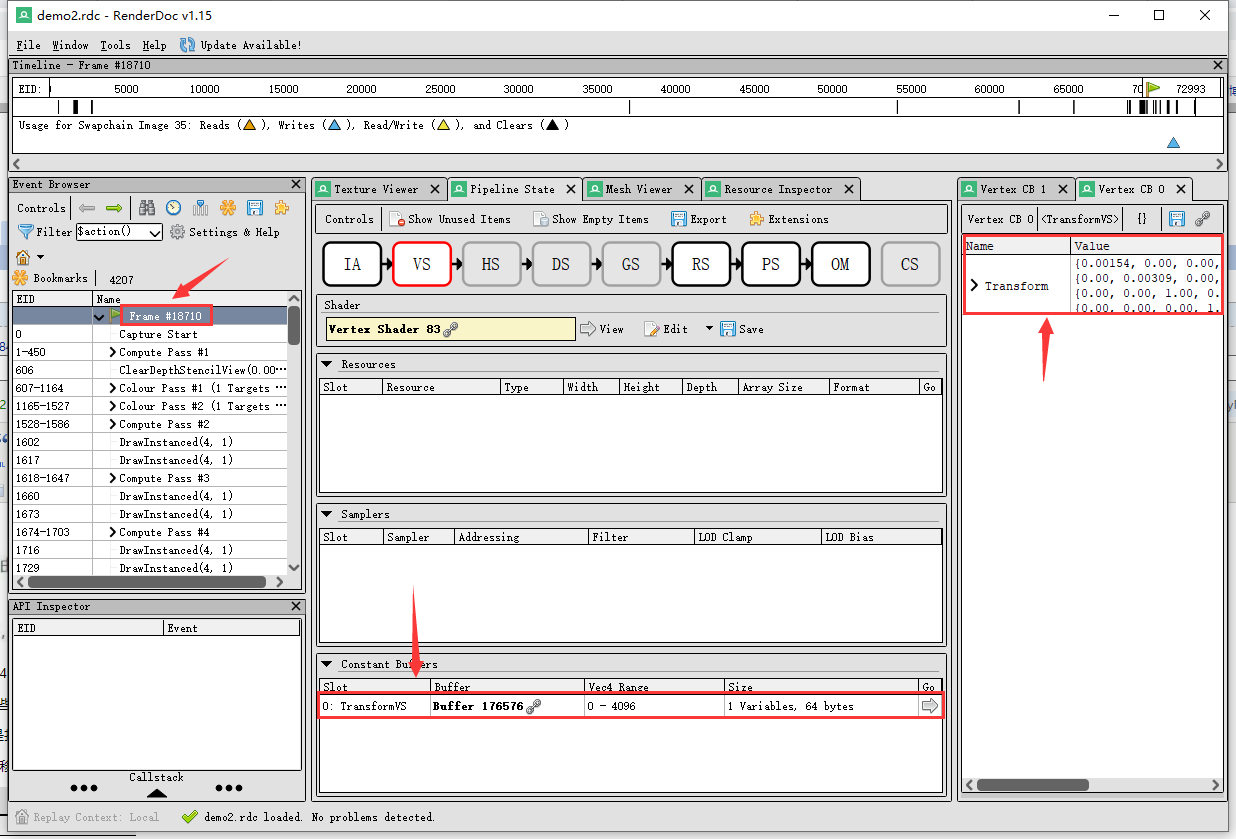
暂时未实现如何用API导出该Transform向量。
补充TransformVS中的一些发现:除了frame中,其他Clear Pass以及最后几个colour Pass通道也含有TransformVS,根据查阅资料判断,应该是清除渲染目标视图的颜色缓存等功能。

