
import java.io.File; import java.io.FileOutputStream; import java.io.OutputStream; import java.util.Scanner; public class A { public static void main(String[] args) throws Exception { File f = new File("f:" + File.separator + "test.txt");//定位文件位置 OutputStream out = null; out = new FileOutputStream(f); Scanner in = new Scanner(System.in);//输入 System.out.println("请输入:"); String str = in.nextLine(); byte b[] = str.getBytes();//转为数组 for (int i = 0; i < b.length; i++) { if (i % 2 == 0 && b[i] >= 'a' && b[i] <= 'z') {//判定条件 b[i] = (byte) (b[i] - 32); } out.write(b[i]);//写入 } out.close();
实验结果:
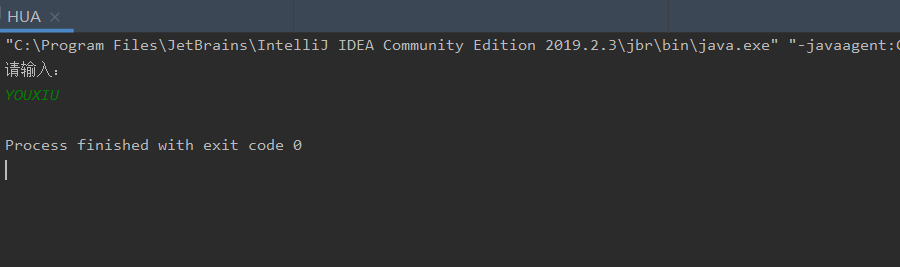
学习总结:
任何文件都可以使用字节流进行操作,因为几乎所有的文件的内容都可以转换为字节包括文本文件,使用字节流操作只是快慢问题,而字符流就不能操作所有的文件了,字符流只能操作已知编码的文件,如文本文件,控制台信息,因为这些都是使用了默认的编码。
字符是由指定编码后的字节转换而来的,所以字符流操作,实际上底层还是以字节流的形式操作的,只是在调用字节流操作时,使用了指定的编码或默认的编码,将字节转换为字符了,而如果使用的编码不对,则转换为字符就会出问题。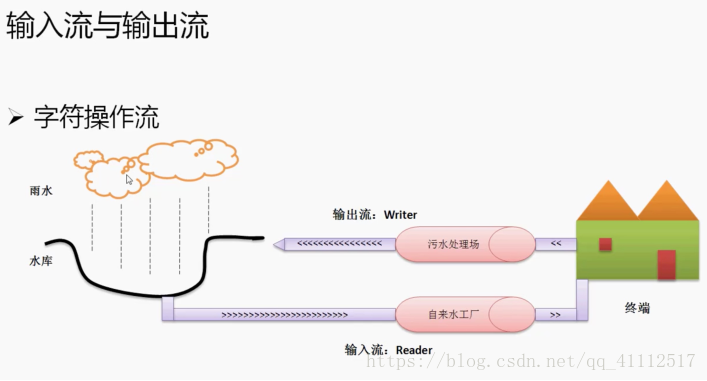
字节流与字符流操作的本质区别只有一个:字节流是原生的操作,而字符流是经过处理后的操作。在进行网络数据传输、磁盘数据保存所保存所支持的数据类型只有字节而所有磁盘中的数据必须先读取到内存后才能进行操作,而内存中会帮助我们把字节变为字符。
OutputStream是一个抽象类,按照抽象类的基本原则来讲,如果想要取得OutputStream类的实例化对象那么一定需要子类,如果要进行文件的操作,可以使用FileOutputStream类来处理,
这个类的构造方法如下:
1. 接收File类(覆盖):public FileOutputStream(File file) throws FileNotFoundException
2. 接收File类(追加):public FileOutputStream(File file, boolean append)
每次读取内容到部分字节数组,只允许读取满限制的数组的字节个数。此方法依然会返回读取的长度。
整个操作跟输出的形式几乎是相同的,参数的类型及作用也几乎是相同的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号