
Gitee项目链接:https://gitee.com/wei-yuxuan6/myproject/tree/master/实践作业
| 这个项目属于哪个课程 | https://edu.cnblogs.com/campus/fzu/2024DataCollectionandFusiontechnology |
|---|---|
| 组名 | 在大大的数据里面挖呀挖呀挖 |
| 项目简介 | 项目名称:城市记忆 Logo: 项目需求:整合城市历史文化资源:需要以交互式的方式展示城市的历史发展、新旧照片、方言特色以及名人故事等内容。增强用户参与感:为用户提供交互性体验,如照片上色、语音生成、内容检索等。利用多媒体技术提升展示效果:通过地图、视频、音频、图像等多种形式,全方位展示城市记忆,构建沉浸式体验。 项目开展技术路线:python、html、JavaScript、flask、mysql |
| 团队成员学号 | 102202114农晨曦,102202118杨美荔、102202144傅钰、102202147赖越、102202150魏雨萱、102202152张静雯 |
| 这个项目的目标 | 建立多模块融合的城市记忆平台:打造一个集历史资源展示、文化传承和科技互动为一体的平台。 提升用户体验与交互性:通过地图导航、名人故事展示、黑白照片上色和方言音频生成等功能,让用户更生动地了解城市文化。 促进文化保护与传承:利用现代技术对城市历史资源进行数字化存档,帮助大众更便捷地探索与分享城市记忆。 探索跨学科技术融合:结合深度学习、多模态技术与地理信息系统等技术,提升文化展示的深度与广度。 |
| 其他参考文献 | 近20 年城市记忆研究综述 城市记忆与城市形态——从心理学、社会学视角探讨城市历史文化的延续 星火认知大模型Web API文档 |
综合设计——多源异构数据采集与融合应用综合实践
项目logo:

一、项目背景
城市记忆承载着一座城市的历史、文化与情感,其背后的故事和影像是研究城市变迁与文化保护的重要资源。然而,许多城市的历史资源缺乏系统化的整理与展示,普通大众难以方便地接触这些内容。随着人工智能与多媒体技术的快速发展,利用技术手段将历史内容与现代形式结合,可以更好地传递城市文化,增强公众的文化认同感。
本项目旨在打造一个集文化传承、历史展示和用户交互为一体的多功能平台,以现代技术手段展示和保护城市历史文化资源。通过整合地图导航、历史影像、方言语音、名人故事等内容,用户可以深入了解城市的变迁与文化特色,激发对城市历史的关注与兴趣。
项目的核心理念是将深厚的城市记忆以科技化、数字化的方式呈现出来,让人们在互动体验中感受城市文化的独特魅力,同时增强文化保护意识和传承责任感。无论是历史爱好者、城市研究者,还是普通用户,网站都将为其提供生动的探索途径和丰富的内容资源。
通过现代科技手段,为用户提供一个互动性强、内容丰富的数字化平台,致力于保护与传播城市历史文化资源。网站以城市为核心,通过整合地图导航、老照片上色、方言语音合成、历史影像和名人故事等多种功能,让用户在浏览与互动中感受城市文化的独特魅力与深厚底蕴。
二、项目需求
-
整合城市历史文化资源:需要以交互式的方式展示城市的历史发展、新旧照片、方言特色以及名人故事等内容。
-
增强用户参与感:为用户提供交互性体验,如照片上色、语音生成、内容检索等。
-
利用多媒体技术提升展示效果:通过地图、视频、音频、图像等多种形式,全方位展示城市记忆,构建沉浸式体验。
-
支持个性化需求:让用户通过输入特定内容(如城市名或文本)获取对应资源(如音频或视频)。
三、项目功能介绍
1. 时空地图
功能描述:用户通过交互式地图探索城市历史文化资源。
-
点击地图标记点:显示对应城市的方言音频、新旧照片对比、历史发展时间轴信息。
-
查看名人故事:点击标记点的“名人故事”按钮跳转到城市的名人集页面,展示与该城市相关的名人列表。
-
名人故事展示:点击名人列表中的名人姓名,可以查看详细的名人故事,包括其生平事迹、贡献和与城市的关联性。
技术实现:
-
使用高德地图 API 提供地图展示与交互功能。
-
数据库存储包含城市地理信息及相关文化资源。
-
名人资源使用Spark 4.0 Ultra搜索并整理名人集和名人故事。
2. 照片上色
功能描述:
-
用户上传黑白照片,系统自动将其转换为色彩丰富的上色照片,直观展现历史影像的色彩还原效果。
-
支持多种照片格式,快速处理。
-
生成对比图,展示黑白原图与上色图的差异。
技术实现:
-
使用 百度图片上色接口 提供高精度的图片上色服务。
-
后端实现文件上传和上色结果的高效存储与展示。
3. 方言之声
功能描述:
-
用户输入一段文本并选择城市名称,系统自动生成对应城市方言的音频文件。
-
支持多种方言生成,包括粤语、东北话等。
-
生成音频后提供播放功能,用户可以在线收听或下载保存。
技术实现:
- 使用 讯飞星火语音合成 API 实现高质量的多方言语音合成。
4. 时光影像
功能描述:
-
用户输入城市名称,系统搜索该城市的老视频并在页面中展示。
-
视频内容涵盖城市建设、名胜古迹、历史活动等主题。
-
视频可在线播放,支持用户分享和下载功能。
技术实现:
-
后端通过查询 MySQL 数据库,根据用户输入的城市关键词匹配相关视频链接。
-
视频资源通过动态渲染展示在页面,支持跨平台兼容的播放功能。
四、项目技术路线
1. 前端
-
使用 Vue.js 框架开发,支持动态渲染和响应式设计,兼容多种设备(PC 和移动端)。
-
高德地图 API 集成,用于实现地图标记与交互功能。
-
HTML5 和 CSS3 实现页面布局与动画效果,提升视觉吸引力。
2. 后端
-
基于 Flask 框架开发 RESTful API,与前端交互。
-
集成第三方服务接口(高德地图API、百度AI图片上色接口、讯飞星火语音合成API、Spark4.0 UltraAPI)。
-
提供与 MySQL 数据库的高效交互,支持查询与数据更新。
3. 数据库
-
使用 MySQL 数据库存储视频链接、名人信息和其他相关数据。
-
提供灵活的表结构设计,便于数据检索与扩展。
4. AI 技术
-
图片上色:集成百度AI图片上色接口,实现黑白图像智能上色。
-
语音合成:调用讯飞星火语音合成API生成高质量方言语音。
-
数据检索:借助 Spark4.0 UltraAPI 快速检索与展示名人集和名人故事数据。
5. 爬虫数据采集
-
使用 Python 爬虫技术 (如 Scrapy、Requests、BeautifulSoup 等)从各类公共数据源(如百科、城市历史网站、档案馆、哔哩哔哩)抓取城市历史数据、名人故事、黑白照片、老视频等内容,并存入数据库供后续处理和展示。
-
在搜索到名人之后使用Selenium同时爬取名人照片并展示。
-
动态加载和解析页面数据,清洗并规范化抓取到的信息,确保数据质量和一致性。
6. 多媒体资源管理
- 结合阿里云OSS(对象存储服务)管理照片、音频与视频资源,确保高效访问与展示。
五、项目展示
1. 首页

2. 地图页面

3. 选取城市
选取陕西延安,可以看到两张关于延安的图片,还有一段音频

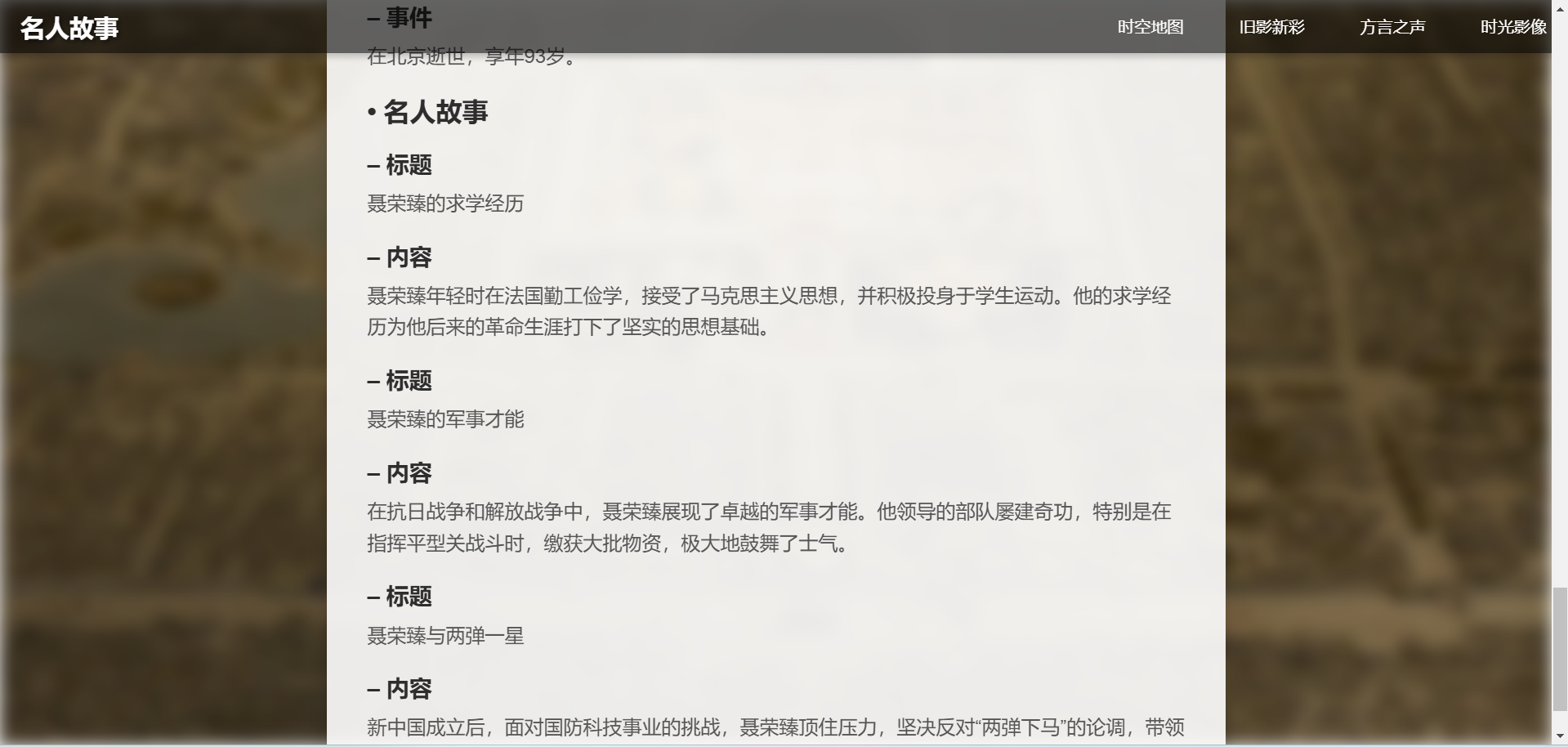
4. 名人故事
点击右上角“查看名人故事”,可以出现一些来自陕西延安的名人,点击其中一个名人,可以看到他的简介和事迹
5. 旧影新彩
上传一张黑白图片,可以使用ai功能使其上色

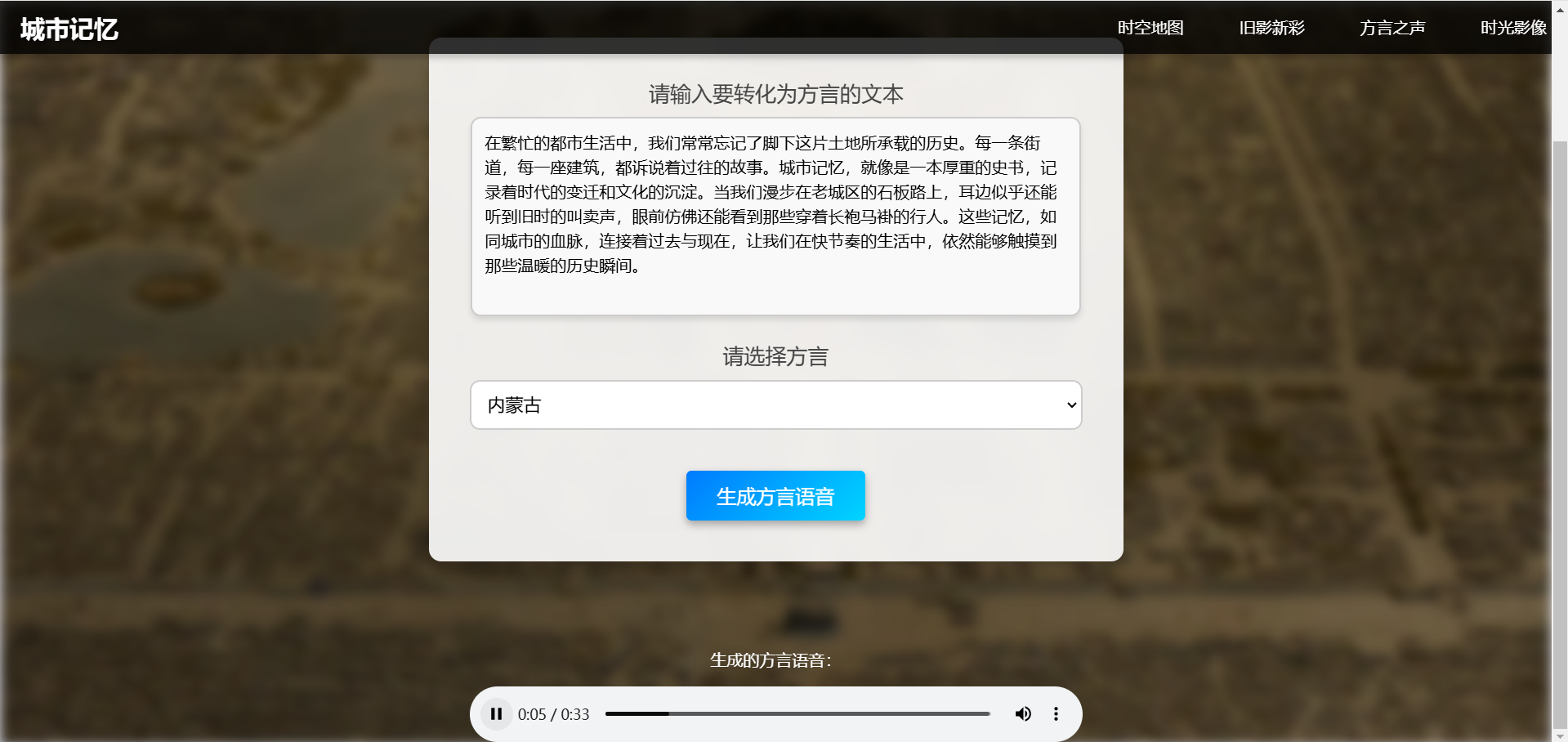
6. 方言之声
可以输入一段文本,在下方选取想要转换的方言,点击生成,就可以得到这段文本的方言音频
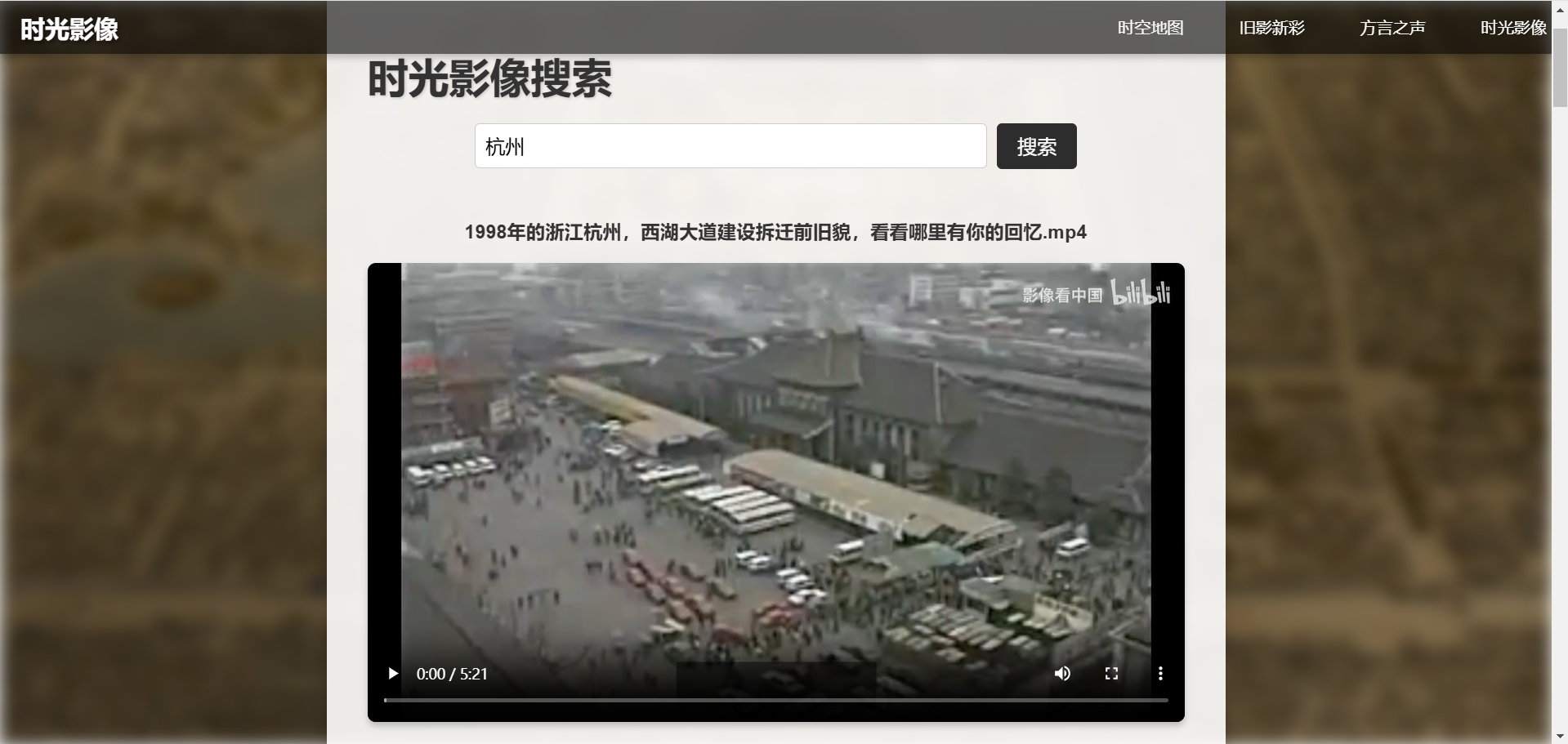
7. 时光影像
在搜索框输入想查找的城市,可以出现这座城市的一些影像资料
六、个人分工介绍
我在这次项目中主要负责的是数据采集、预处理和特征提取与融合部分。
数据采集阶段:
从网络信息中选取爬取目标,从哪个地方下载文本文件。备选有各地博物馆信息、地方志、文旅局官网等,但是结果并不理想,每个城市的网站信息并不相同,若需要具体考虑每个城市的爬取,则要耗费太多的时间,且结果不一定理想。最后选取了爬取维基百科。里面对城市事件就有简单的分块,且也包含时间信息,符合我们的要求。
部分代码展示:
def clean_text(text):
# 移除维基百科中的引用和其他无关字符
text = re.sub(r"\[.*?\]", "", text) # 去除所有的引用格式
text = re.sub(r"(.*?)", "", text) # 去除括号中的内容
text = re.sub(r"[\n\s]+", " ", text) # 去除多余的空格和换行
return text.strip()
def fetch_city_history(city_name):
search_url = f"https://zh.wikipedia.org/wiki/{city_name}"
try:
# 发送请求获取网页内容
response = requests.get(search_url, verify=False)
response.encoding = 'utf-8'
if response.status_code != 200:
print(f"无法访问城市: {city_name}")
return None
# 使用 BeautifulSoup 解析网页内容
soup = BeautifulSoup(response.text, 'html.parser')
# 查找历史部分,通常历史部分有一个对应的 id
history_section = soup.find(id="历史") # 查找历史部分的标题
if not history_section:
print(f"未找到历史部分: {city_name}")
return None
# 找到历史部分下的所有内容
history_content = []
for para in history_section.find_all_next(['p', 'ul', 'ol']):
text = para.get_text(strip=True)
if text:
history_content.append(text)
# 如果没有找到任何历史内容
if not history_content:
print(f"未找到历史内容: {city_name}")
return None
# 合并所有历史内容并进行清理
history_text = "\n".join(history_content)
cleaned_history_text = clean_text(history_text)
return {
"history": [
{"event": "历史沿革", "description": cleaned_history_text, "date": "不确定"}
]
}
except Exception as e:
print(f"发生错误:{e}")
return None
特征提取阶段:
对上一个阶段采集到的文本数据进行特征提取。我们的需求是按照年份划分时间轴,然后可以从时间轴上看到某个城市发生较大变化/事件的时间。由于提取的文本里面有时间信息,所以可以直接采用正则匹配,在年份的地方进行分割。由于我并没有在采集完数据后先进行数据清洗,所以在这个阶段提取完特征后会出现很多问题。例如古代的年份概念实际上比不上直接用朝代来进行划分,再就是有一些年份是使用民国纪年,需要换算才能得到具体年份。所以在这个阶段,我用正则表达式提取后,对数据的清洗融合花了较长时间,对于每个城市的年份与事件都要一一查看,是否有分割不完全,以及同一个年份的事件分割成了好几块的情况。
部分代码展示:
# 提取并分割每个城市的历史描述
def extract_and_split_by_time(city_data):
history_text = city_data['history'][0]['description']
# 使用正则表达式提取所有的年份(例如 "1985年"、"1954年8月" 等)
time_pattern = r'(\d{4}年|\d{4}年\d{1,2}月\d{1,2}日|\d{4}年\d{1,2}月)'
times = re.findall(time_pattern, history_text)
split_text = []
start_idx = 0
# 按时间分割历史描述
for time in times:
time_pos = history_text.find(time, start_idx)
if time_pos != -1:
# 截取时间前的部分
text_before = history_text[start_idx:time_pos].strip()
if text_before:
split_text.append((text_before, None)) # 没有时间标签前的部分
# 截取当前时间后的部分
start_idx = time_pos
end_idx = history_text.find('。', start_idx) + 1 # 假设按句号结束
if end_idx != -1:
text_after = history_text[start_idx:end_idx].strip()
split_text.append((text_after, time))
start_idx = end_idx # 更新开始索引,继续查找下一个时间段
else:
split_text.append((history_text[start_idx:], time))
break
return split_text

 浙公网安备 33010602011771号
浙公网安备 33010602011771号