
Gitee链接:https://gitee.com/Bluemingiu/project/tree/master/4
作业①:
-
要求:熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
-
候选网站:东方财富网:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
-
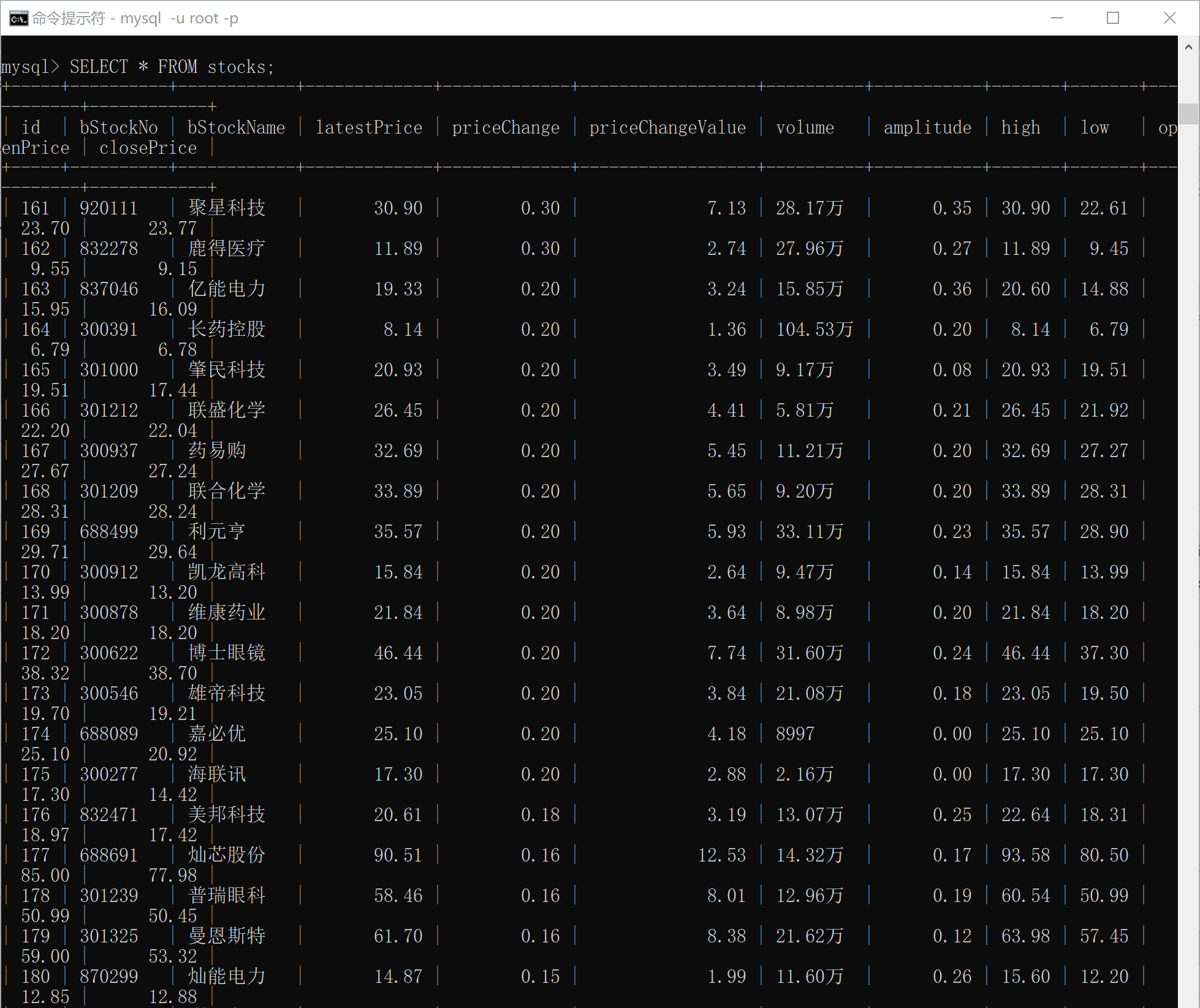
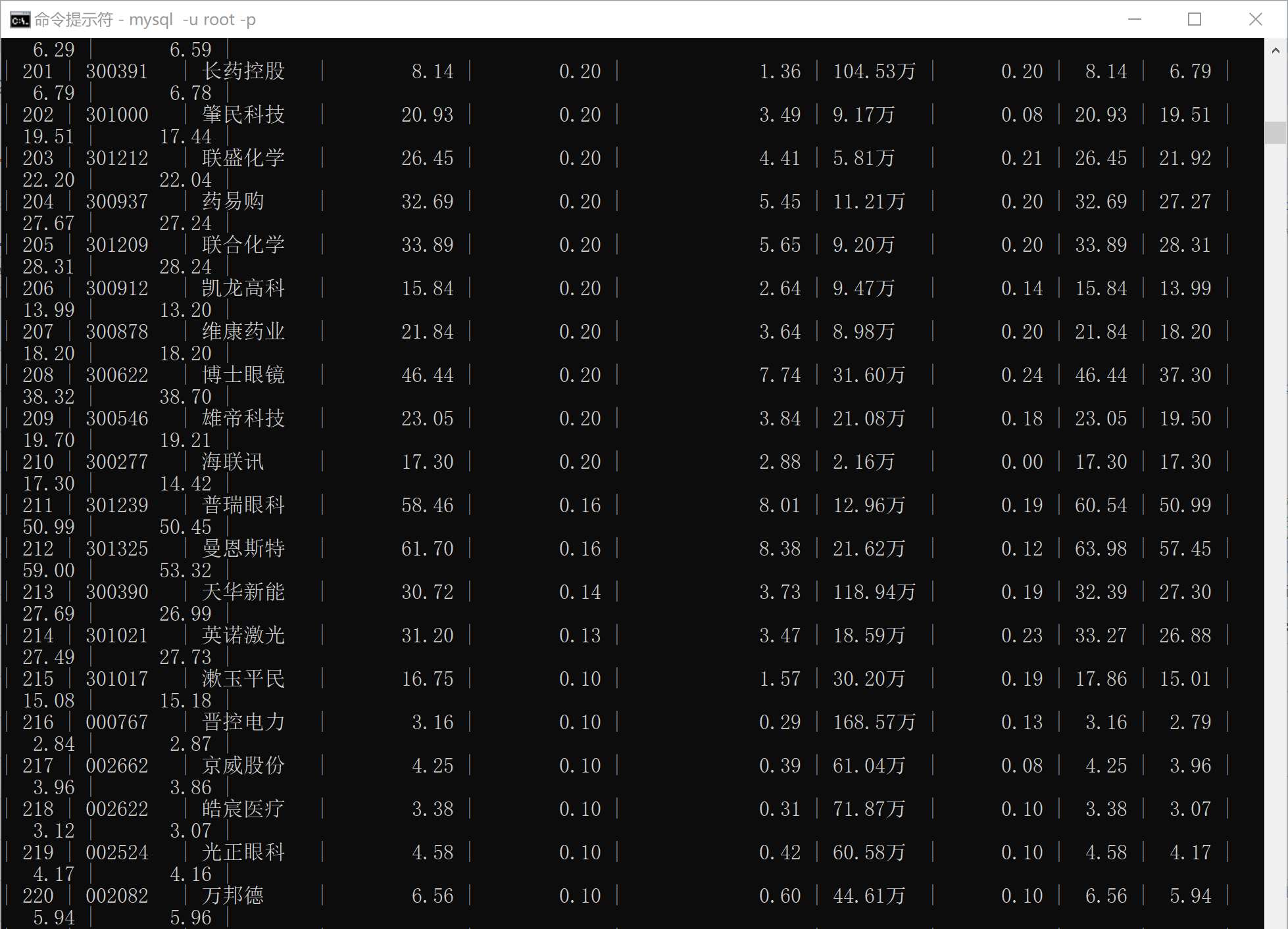
输出信息:MYSQL数据库存储和输出格式如下,表头应是英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计表头
1. 实验过程
核心代码
- 数据爬取
bStockNo = columns[1].text.strip() # 股票代码
bStockName = columns[2].text.strip() # 股票名称
latestPrice = columns[4].text.strip() # 最新价
priceChange = columns[5].text.strip() # 涨跌幅
priceChangeValue = columns[6].text.strip() # 涨跌额
volume = columns[7].text.strip() # 成交量
amplitude = columns[9].text.strip() # 振幅
high = columns[10].text.strip() # 最高价
low = columns[11].text.strip() # 最低价
openPrice = columns[12].text.strip() # 今开盘
closePrice = columns[13].text.strip() # 昨收盘
- 页面点击与切换
def switch_board_and_scrape(board_xpath):
try:
WebDriverWait(driver, 10).until(
EC.element_to_be_clickable((By.XPATH, board_xpath))
).click()
time.sleep(5) # 等待页面加载
print(f"已跳转到 {board_xpath} 板块")
scrape_page() # 爬取当前板块第一页数据
except Exception as e:
print(f"点击 '{board_xpath}' 失败:", e)
运行终端截图

数据库查询内容:
(所有输出在一张表上,为了方便查看分开截取,由于前期进行尝试后又删除表中内容,所以序号从161开始。)
- 沪京深A股:
- 上证A股:

- 深证A股:
2. 心得体会
完成这个股票数据爬取项目后,我深刻体会到网页结构解析、数据清洗、数据库操作和浏览器自动化的重要性。通过使用 selenium 模拟浏览器行为,我能够应对动态加载的页面,并提取所需的数据。在数据清洗方面,我处理了不规则的字符和格式(如“万”和“亿”),并确保了数据转换的准确性。数据库设计上,我简化了结构,确保数据正确存储,并通过事务管理保证了数据的一致性。模拟点击和页面切换时,我利用 WebDriverWait 保证页面完全加载,避免了元素未加载完成的问题。虽然性能方面仍有提升空间(例如引入多线程),但该项目让我更加熟悉了爬虫开发的全过程,特别是在异常处理、数据清洗和容错机制上,进一步提高了程序的稳定性和健壮性。
作业②:
-
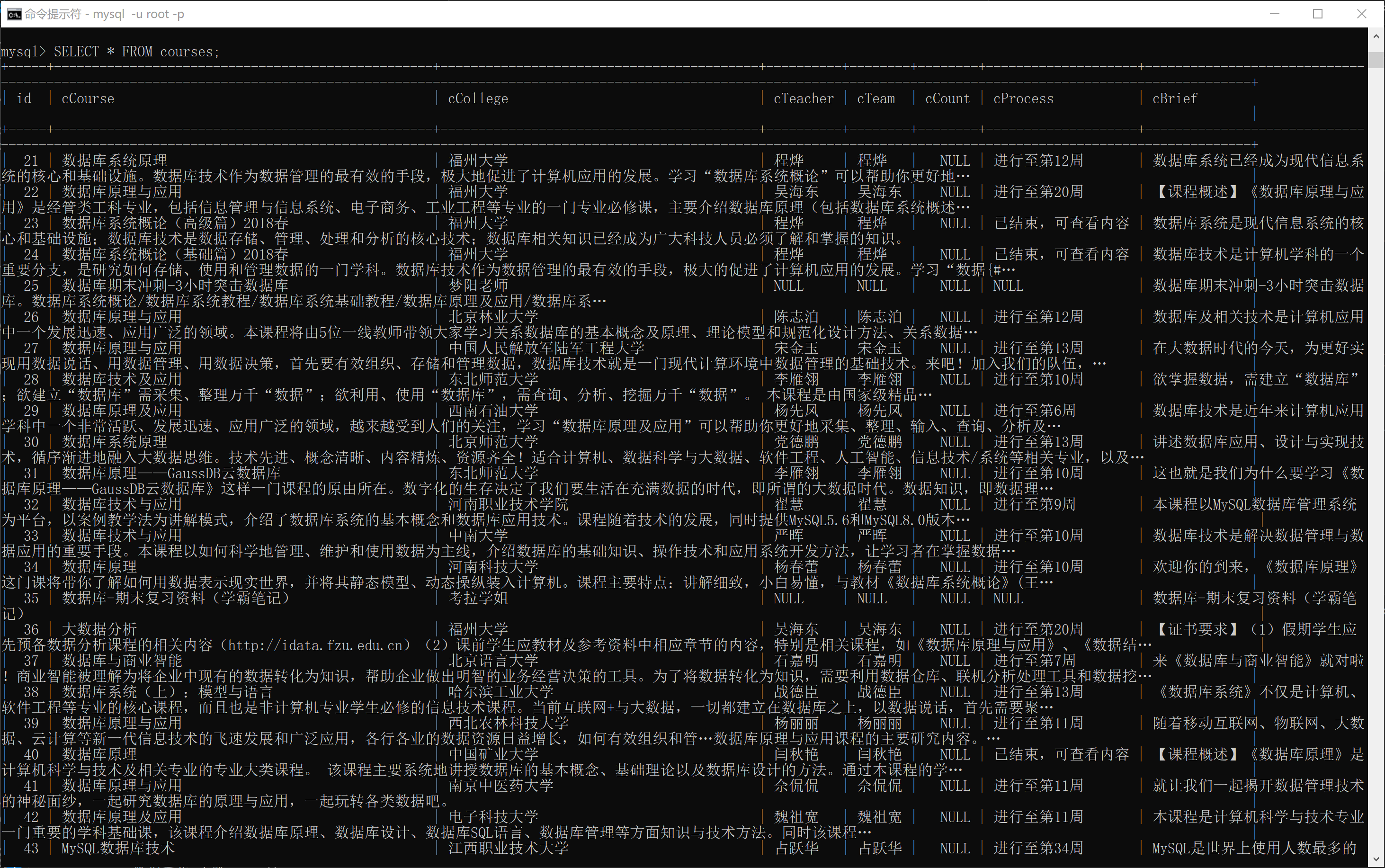
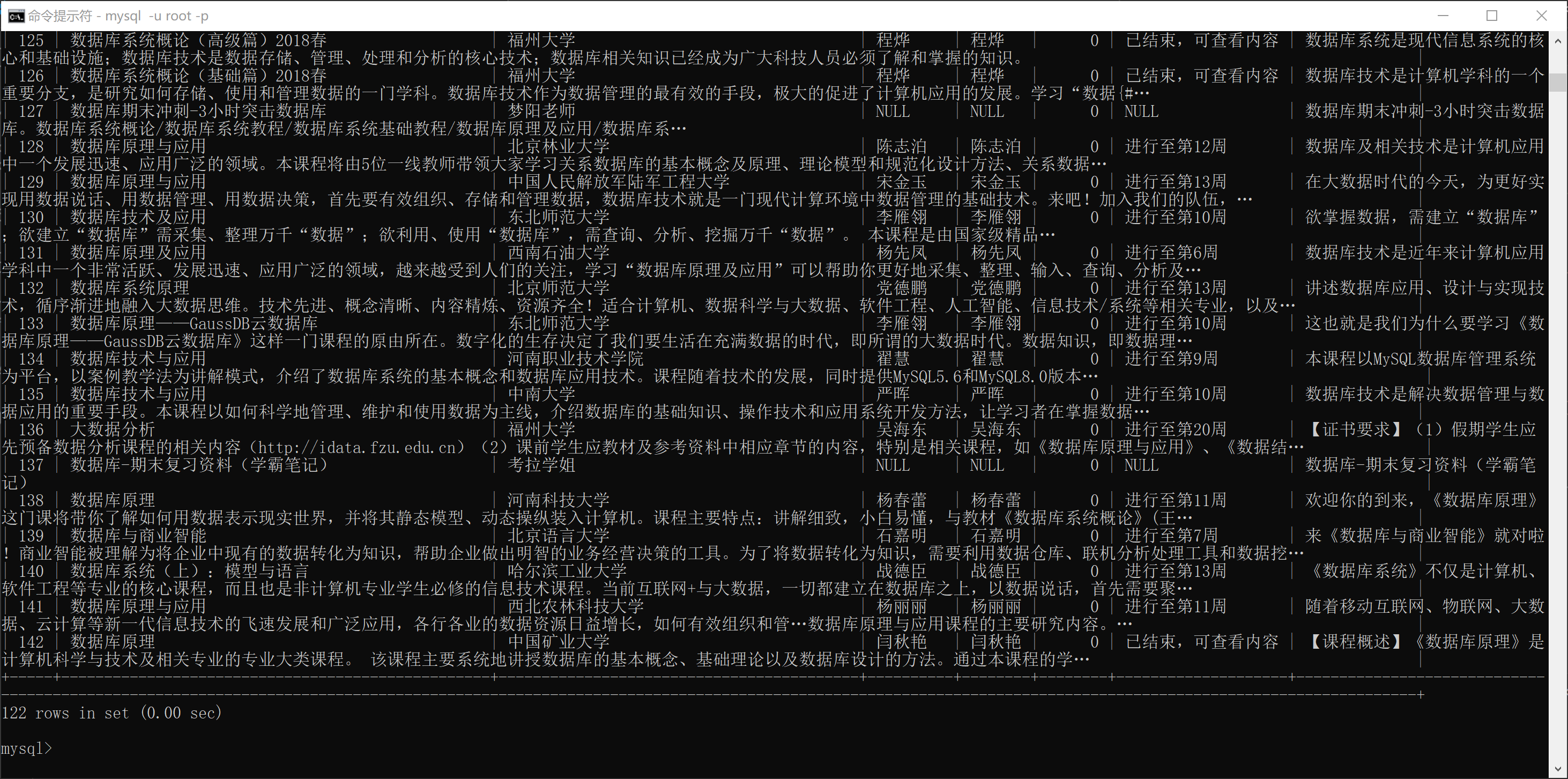
要求:熟练掌握 Selenium 查找HTML元素、实现用户模拟登录、爬取Ajax网页数据、等待HTML元素等内容。使用Selenium框架+MySQL爬取中国mooc网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
-
候选网站:中国mooc网:https://www.icourse163.org,爬取数据库相关课程
-
输出信息:MYSQL数据库存储和输出格式
1. 实验过程
核心代码
- 模拟登录
def login(driver, username, password):
driver.get("https://www.icourse163.org/")
login_button = driver.find_element(By.XPATH, '//*[@id="j-topnav"]/div')
login_button.click()
time.sleep(2)
WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.TAG_NAME, "iframe")))
iframe = driver.find_element(By.XPATH,'/html/body/div[13]/div[2]/div/div/div/div/div/div[1]/div/div[1]/div[2]/div[2]/div[1]/div/iframe')
driver.switch_to.frame(iframe)
username_field = driver.find_element(By.XPATH,'//*[@id="phoneipt"]')
password_field = driver.find_element(By.XPATH,'//*[@id="login-form"]/div/div[4]/div[2]/input[2]')
username_field.send_keys(username)
password_field.send_keys(password)
time.sleep(1)
button = driver.find_element(By.XPATH, '/html/body/div[2]/div[2]/div[2]/form/div/div[6]/a')
button.click()
WebDriverWait(driver, 60).until(EC.url_changes(driver.current_url))
driver.switch_to.default_content()
time.sleep(2)
- 模拟滚动加载更多课程
def simulate_scroll(driver):
page_height = driver.execute_script("return document.body.scrollHeight")
scroll_step = 3
scroll_delay = 4
current_position = 0
while current_position < page_height:
next_position = current_position + scroll_step
driver.execute_script(f"window.scrollTo(0, {next_position});")
driver.implicitly_wait(scroll_delay)
current_position = next_position
数据库查询内容
2. 心得体会
在这个爬虫项目中,我进行了爬虫设计的模块化,通过将代码拆分为多个独立的函数,每个函数负责一个具体任务(如数据库操作、页面滚动、元素等待等),不仅使代码更加清晰易懂,也为后期的维护和扩展提供了极大的便利。此外,使用 Selenium 处理动态页面的能力让爬取 JavaScript 渲染内容变得更加简单和高效。尤其是在处理页面加载和弹窗时,使用显式等待(WebDriverWait)可以避免元素未加载完全就进行操作的错误,提高了爬虫的稳定性。
作业③:
*要求:掌握大数据相关服务,熟悉Xshell的使用。完成文档 华为云_大数据实时分析处理实验手册-Flume日志采集实验(部分)v2.docx 中的任务,即为下面5个任务,具体操作见文档。
1.实验过程
环境搭建:开通MapReduce服务
1. 开通MRS

2. 配置
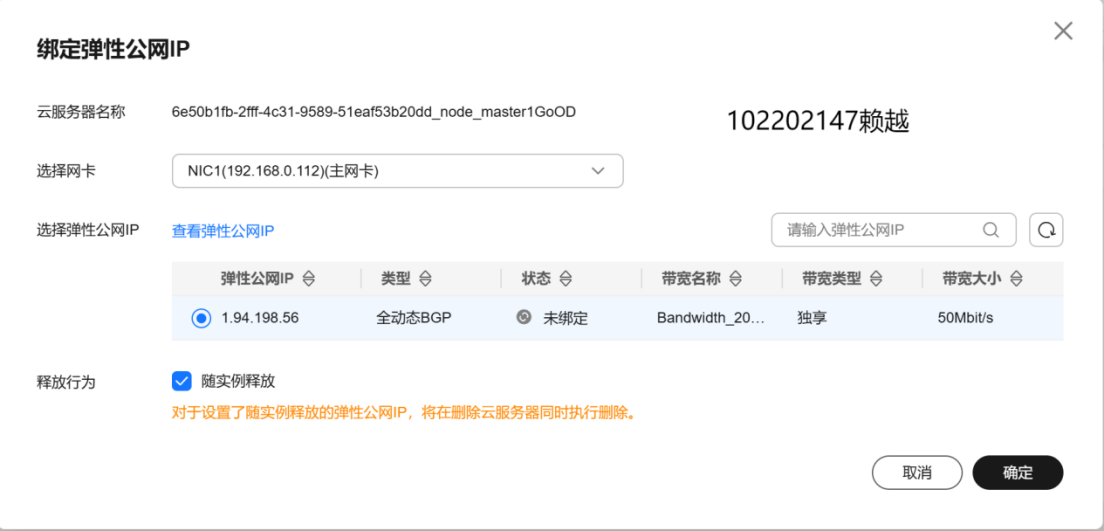

实时分析开发实战:
1. Python脚本生成测试数据
- 登录MRS的master节点服务器
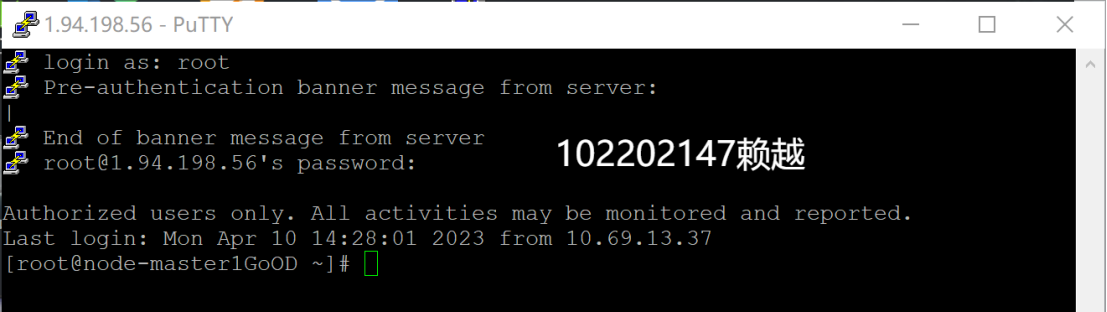
- 编写Python脚本

- 执行脚本测试

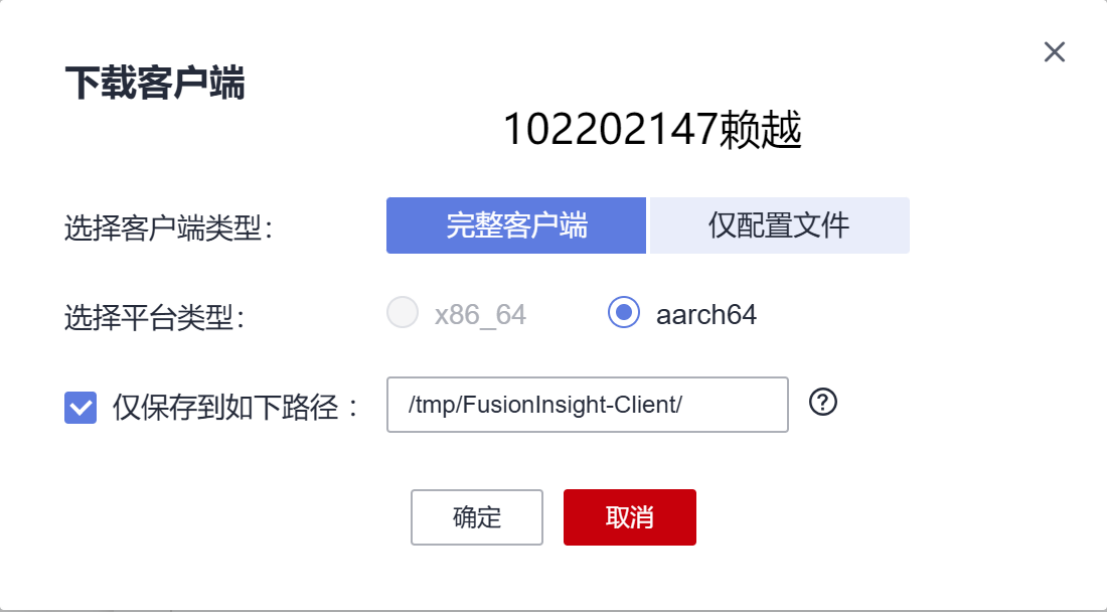
2. 配置Kafka
- 下载

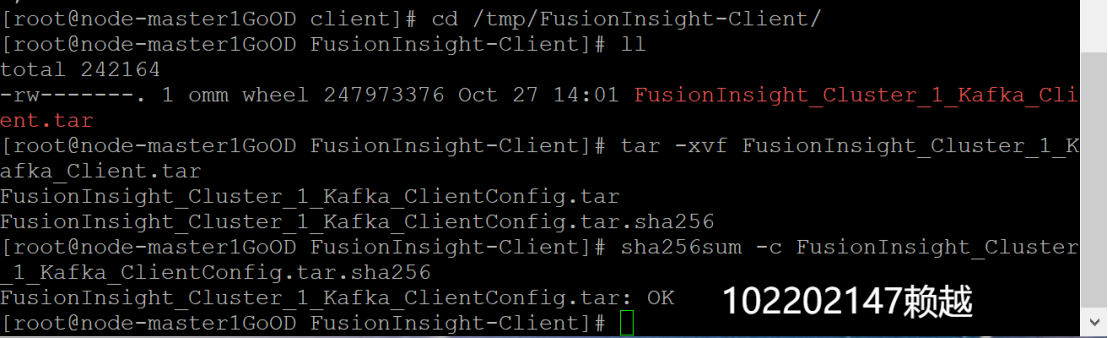
- 校验下载的客户端文件包
- 安装Kafka运行环境

- 安装Kafka客户端
- 设置环境变量

- 在kafka中创建topic并查看topic信息

3. 安装Flume客户端
- 下载

- 校验下载的客户端文件包


- 安装Flume运行环境
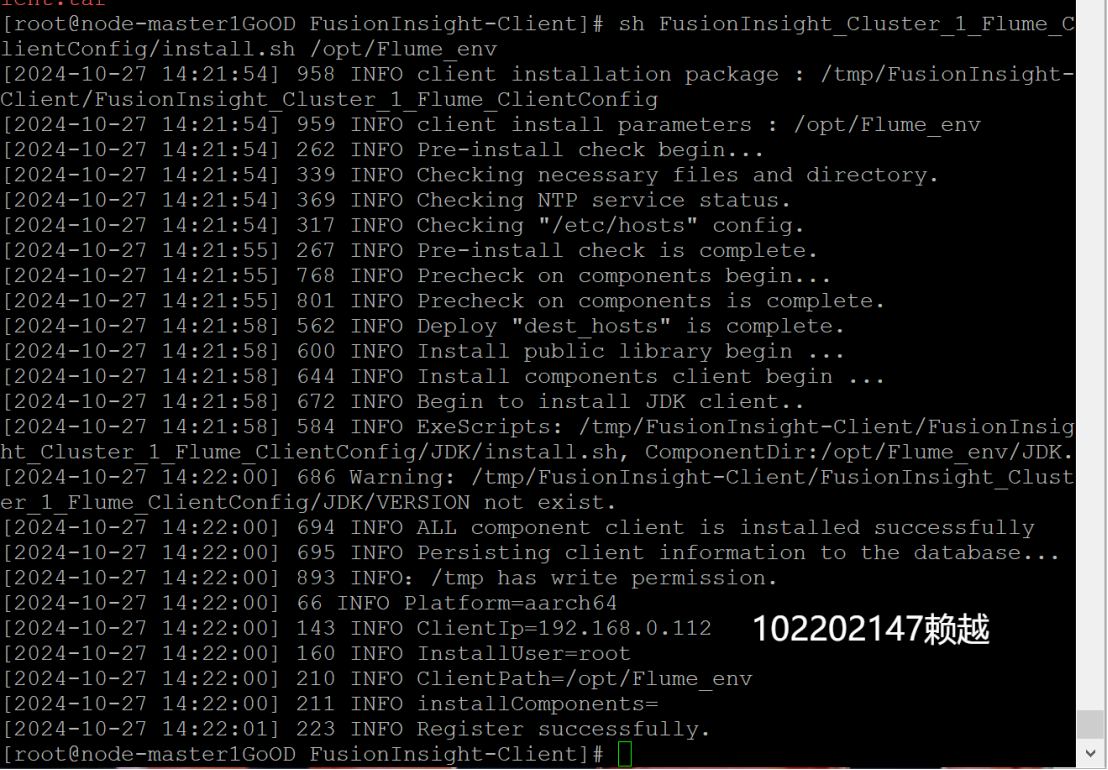
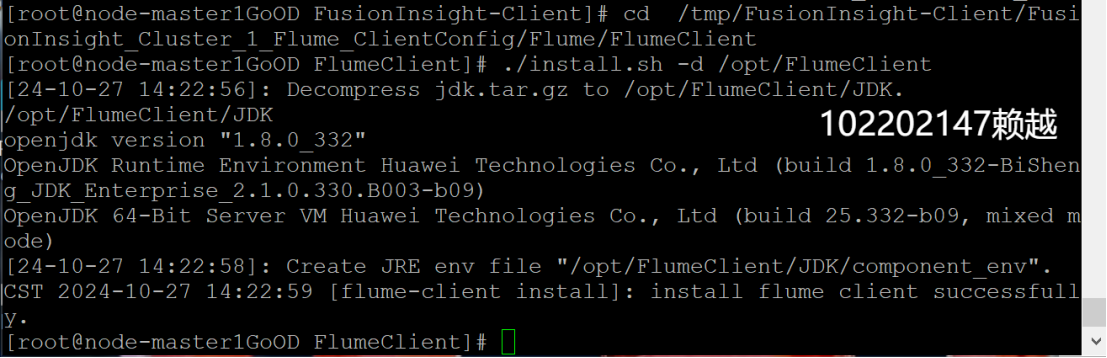
- 安装Flume客户端
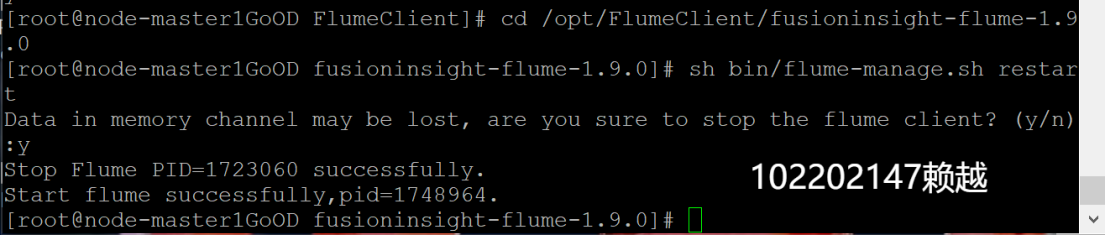
- 重启Flume服务
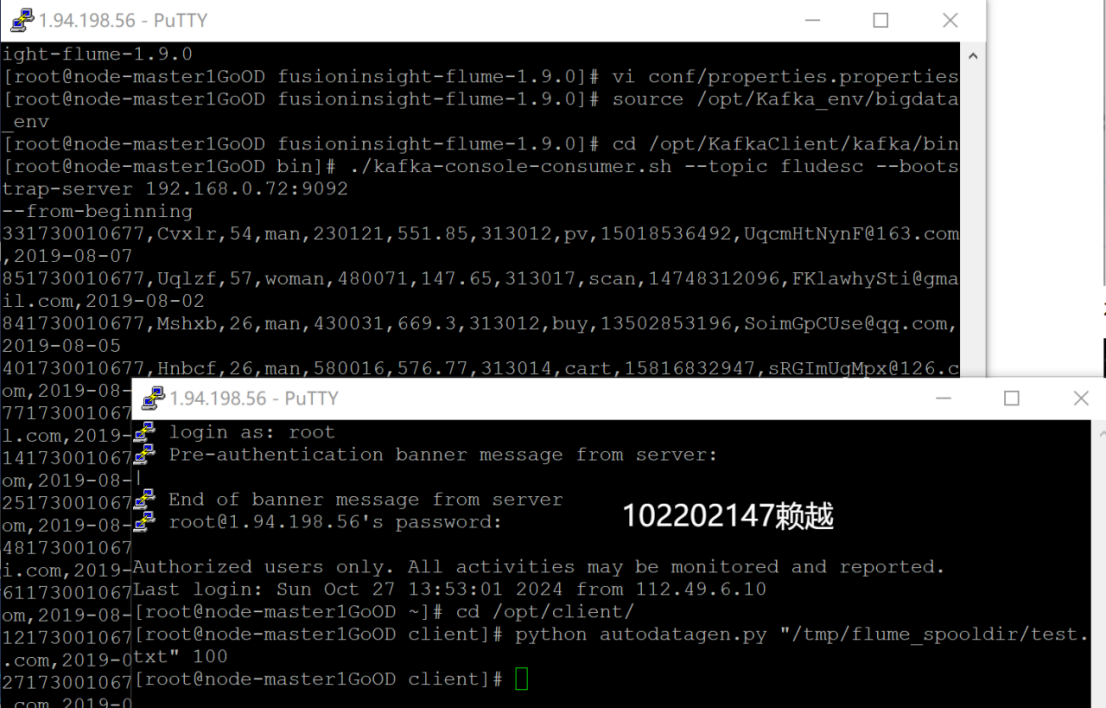
4. 配置Flume采集数据
- 修改配置文件

- 创建消费者消费kafka中的数据
2.心得体会
在完成华为云大数据实时分析处理实验任务的过程中,我深入理解了大数据处理的几个关键环节,包括数据采集、传输和存储。通过编写Python脚本生成测试数据,我掌握了如何在大数据平台上模拟真实数据流。通过进行Kafka的安装与配置,我理解了消息队列在实时数据处理中的重要性,并成功创建了Kafka的topic,确保数据能够可靠地传输。Flume的安装和配置让我进一步体会到了数据采集的灵活性和高效性,尤其是通过修改配置文件来实现数据流的定制化处理。此外,整个实验过程中,我通过不断测试和调试,增强了对大数据处理平台的理解和操作能力,尤其是在如何协同使用不同的大数据组件(如Kafka和Flume)进行数据的实时采集与分析。这次实验不仅提升了我对大数据服务的掌握,也让我更加熟悉了大数据生态中的关键技术。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号