


Gitee链接地址:https://gitee.com/Bluemingiu/project/tree/master/3
作业①
-
要求:指定一个网站,爬取这个网站中的所有图片,例如:中国气象网(http://www.weather.com.cn)。使用scrapy框架分别实现单线程和多线程的方式爬取。设计爬取前47页的所有图片。
-
输出信息: 将下载的Url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。
1. 实验过程
核心代码
提取图片链接
images = response.css('img::attr(src)').getall()
处理图片链接
for img_url in images:
full_url = response.urljoin(img_url)
self.log(f'Downloading image: {full_url}')
yield {
'image_urls': [full_url]
}
单线程:
直接使用命令运行
scrapy crawl weather -o images.json
多线程:
在settings.py 文件中,设置 CONCURRENT_REQUESTS 为 16
输出结果
- 终端:
- images.json:
- images文件夹
2. 心得体会
通过完成这个任务,我对使用 Scrapy 框架进行网页数据爬取有了更深入的理解,特别是在处理网页中的图片资源和翻页机制时。一方面,掌握了如何使用 CSS 选择器提取网页中的元素,并通过 response.urljoin 处理相对路径问题,确保获得完整的图片链接。另一方面,实践了如何控制爬虫的页数和翻页,通过构造分页 URL 实现多页数据的爬取。最重要的是,我意识到爬虫设计中的一些常见挑战,比如如何正确处理分页、如何处理页面中的相对路径以及如何合理调试和优化爬虫。总的来说,这个任务让我更加熟悉了 Scrapy 的基本操作和一些高级技巧,为以后的数据爬取项目打下了坚实的基础。
作业②
- 要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。候选网站:东方财富网:https://www.eastmoney.com/
- 输出信息:MySQL数据库存储和输出格式如下:表头英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计。
1. 实验过程
核心代码
- 发送请求和获取响应
def start_requests(self):
for page in range(1, 8): # 爬取前 7 页的数据
url = self.api_url.format(page=page)
yield scrapy.Request(url=url, callback=self.parse)
- 处理 JSONP 响应并解析 JSON 数据
def parse(self, response):
jsonp_match = re.search(r'\((.*?)\)', response.text)
print(jsonp_match)
if jsonp_match:
json_data = json.loads(jsonp_match.group(1))
stocks = json_data.get('data', {}).get('diff', [])
- 提取股票数据并封装为 Item
item['bStockNo'] = stock.get('f12') # 股票代码
item['bStockName'] = stock.get('f14') # 股票名称
item['latestPrice'] = stock.get('f2') # 最新报价
item['priceChange'] = stock.get('f3') # 涨跌幅
item['priceChangeValue'] = stock.get('f4') # 涨跌额
item['volume'] = stock.get('f5') # 成交量
item['amplitude'] = stock.get('f6') # 振幅
item['high'] = stock.get('f7') # 最高价
item['low'] = stock.get('f8') # 最低价
item['open'] = stock.get('f9') # 今开盘
item['close'] = stock.get('f10') # 昨收盘
- 修改settings.py:
BOT_NAME = 'stock_spider'
SPIDER_MODULES = ['stock_spider.spiders']
NEWSPIDER_MODULE = 'stock_spider.spiders'
ITEM_PIPELINES = {
'stock_spider.pipelines.MySQLPipeline': 1,
}
# 禁用 robots.txt 规则
ROBOTSTXT_OBEY = False
# 自定义请求头
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Language': 'en-US,en;q=0.9',
'Accept-Encoding': 'gzip, deflate, br',
'Connection': 'keep-alive',
'Upgrade-Insecure-Requests': '1',
}
# 启用随机 User-Agent
DOWNLOADER_MIDDLEWARES = {
'scrapy_user_agents.middlewares.RandomUserAgentMiddleware': 400,
}
- 修改pipelines.py:
def open_spider(self, spider):
# 打开数据库连接
try:
self.conn = mysql.connector.connect(
host='localhost',
database='stock_db',
user='root',
password='iulze0516'
)
self.cursor = self.conn.cursor()
print("Connected to MySQL")
except Error as e:
print(f"Error: {e}")
def close_spider(self, spider):
# 关闭数据库连接
self.conn.commit()
self.cursor.close()
self.conn.close()
print("MySQL connection closed")
def process_item(self, item, spider):
# 插入数据到数据库
sql = """INSERT INTO stocks
(bStockNo, bStockName, latestPrice, priceChange, priceChangeValue,
volume, amplitude, high, low, open, close)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)"""
values = (
item['bStockNo'], item['bStockName'], item['latestPrice'],
item['priceChange'], item['priceChangeValue'], item['volume'],
item['amplitude'], item['high'], item['low'], item['open'],
item['close']
)
self.cursor.execute(sql, values)
return item
- 修改items.py:
class StockItem(scrapy.Item):
id = scrapy.Field() # 序号
bStockNo = scrapy.Field() # 股票代码
bStockName = scrapy.Field() # 股票名称
latestPrice = scrapy.Field() # 最新报价
priceChange = scrapy.Field() # 涨跌幅
priceChangeValue = scrapy.Field() # 涨跌额
volume = scrapy.Field() # 成交量
amplitude = scrapy.Field() # 振幅
high = scrapy.Field() # 最高
low = scrapy.Field() # 最低
open = scrapy.Field() # 今开
close = scrapy.Field() # 昨收
输出结果
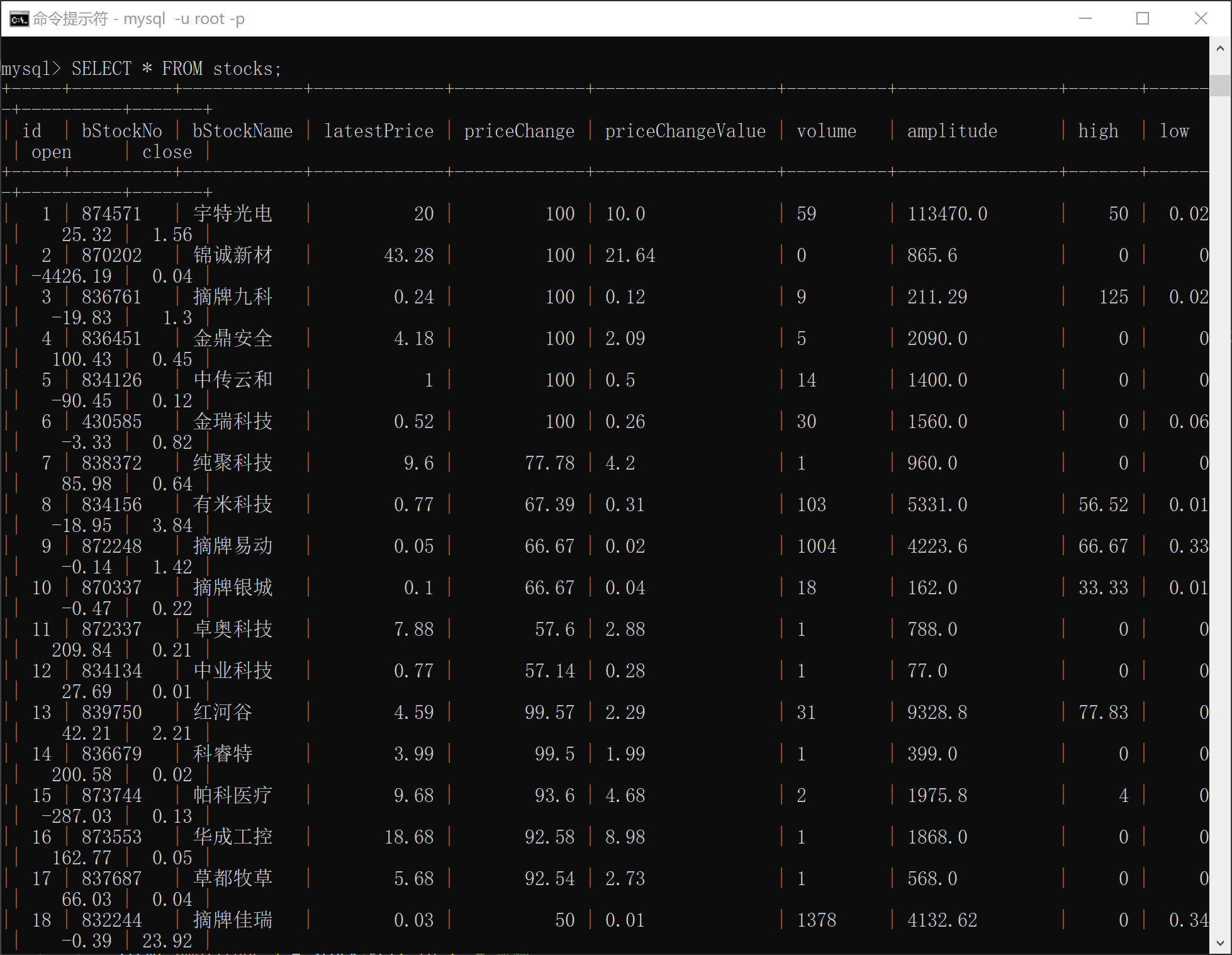
2. 心得体会
完成这个任务让我深刻体会到在数据爬取过程中,解析复杂数据格式和处理分页请求的重要性。首先,通过正则表达式提取 JSONP 响应并将其转换为标准 JSON,是处理动态加载数据时常见的挑战,这让我更清楚地认识到如何应对各种数据格式和网络请求的处理。其次,设置分页机制并通过 start_requests 动态生成请求 URL,对于高效爬取大量数据至关重要,掌握分页的控制技巧能够有效避免重复抓取和遗漏数据。总的来说,这次任务加强了我对 Scrapy 框架的应用能力,尤其是在爬取复杂 API 数据、处理数据格式和控制爬虫流程方面的理解,也让我更好地掌握了如何从网页或 API 中高效提取所需数据。
作业③
- 要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。候选网站:中国银行网:https://www.boc.cn/sourcedb/whpj/
1. 实验过程
核心代码
- 获取数据行:
rows = response.xpath('//table//tr[position()>1]')
- 提取数据并清理:
item['currency'] = row.xpath('td[1]/text()').get(default='').strip()
item['cbp'] = row.xpath('td[2]/text()').get(default='').strip()
item['tsp'] = row.xpath('td[3]/text()').get(default='').strip()
item['tbp'] = row.xpath('td[4]/text()').get(default='N/A').strip()
item['csp'] = row.xpath('td[5]/text()').get(default='').strip()
item['time'] = row.xpath('td[7]/text()').get(default='').strip()
- 修改settings.py:
BOT_NAME = 'forex_spider'
SPIDER_MODULES = ['forex_spider.spiders']
NEWSPIDER_MODULE = 'forex_spider.spiders'
ITEM_PIPELINES = {
'forex_spider.pipelines.MySQLPipeline': 1,
}
DEFAULT_REQUEST_HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Language': 'en-US,en;q=0.9',
'Accept-Encoding': 'gzip, deflate, br',
'Connection': 'keep-alive',
'Upgrade-Insecure-Requests': '1',
}
- 修改pipelines.py:
def open_spider(self, spider):
# 连接到 MySQL 数据库
self.conn = mysql.connector.connect(
host='localhost',
user='root',
password='iulze0516',
database='forex_db'
)
self.cursor = self.conn.cursor()
def process_item(self, item, spider):
# 插入数据到数据库
insert_query = """
INSERT INTO forex_data (currency, tbp, cbp, tsp, csp, time)
VALUES (%s, %s, %s, %s, %s, %s)
"""
data = (
item['currency'],
item['tbp'],
item['cbp'],
item['tsp'],
item['csp'],
item['time']
)
self.cursor.execute(insert_query, data)
self.conn.commit()
return item
def close_spider(self, spider):
# 关闭数据库连接
self.cursor.close()
self.conn.close()
- 修改items.py:
class ForexItem(scrapy.Item):
currency = scrapy.Field()
tbp = scrapy.Field()
cbp = scrapy.Field()
tsp = scrapy.Field()
csp = scrapy.Field()
time = scrapy.Field()
输出结果
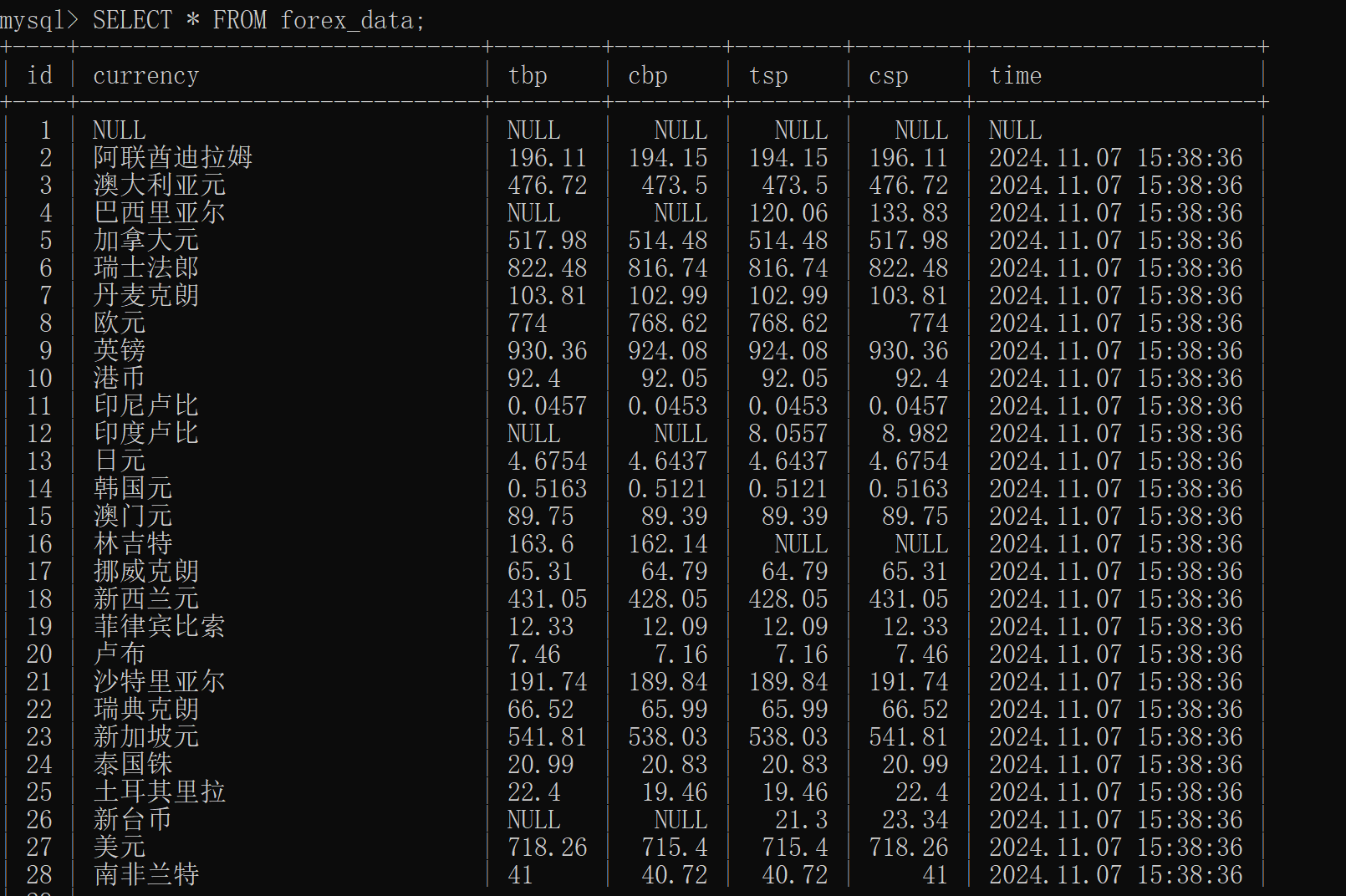
2. 心得体会
完成这个任务让我深入理解了 Scrapy 框架的使用,特别是在处理网页数据提取和清理方面。通过掌握 XPath 选择器,我能够精确提取网页中的元素,并排除表头等无关数据。此外,我学会了使用 .get(default='') 和 .strip() 等方法处理空值和格式不规范的数据,确保爬取的内容完整且符合预期。Scrapy 中的 yield 使得数据能够逐条返回,节省了内存并提高了爬取效率。在数据存储方面,利用 Scrapy Pipeline 我能够将爬取的数据有效地存入数据库或文件中,这为后续的数据处理和分析打下了基础。整个过程中,调试和错误处理的经验也让我意识到,数据抓取并非一蹴而就,往往需要反复优化代码。总的来说,这个任务不仅加深了我对 Scrapy 的理解,还提高了我在实际项目中处理数据的能力。

