


Gitee地址链接:https://gitee.com/Bluemingiu/project/tree/master/2
作业①
要求:在中国气象网(http://www.weather.com.cn)给定城市集的7日天气预报,并保存在数据库。
(1) 实验过程
核心代码:
使用 requests 库发送 HTTP 请求,并用 BeautifulSoup 解析 HTML 内容,以提取天气预报信息。
for city, url in cities.items():
response = requests.get(url)
print(f"正在爬取: {city} ({url}) - 状态码: {response.status_code}") # 打印状态码
if response.status_code == 200:
response.encoding = response.apparent_encoding # 设置正确的编码
soup = BeautifulSoup(response.text, 'html.parser')
forecasts = soup.find_all('ul', class_='t clearfix')
数据插入数据库:
INSERT INTO weather (city, date, weather, temperature) VALUES (?, ?, ?, ?)
''', (city, date, weather, temperature))
输出结果:
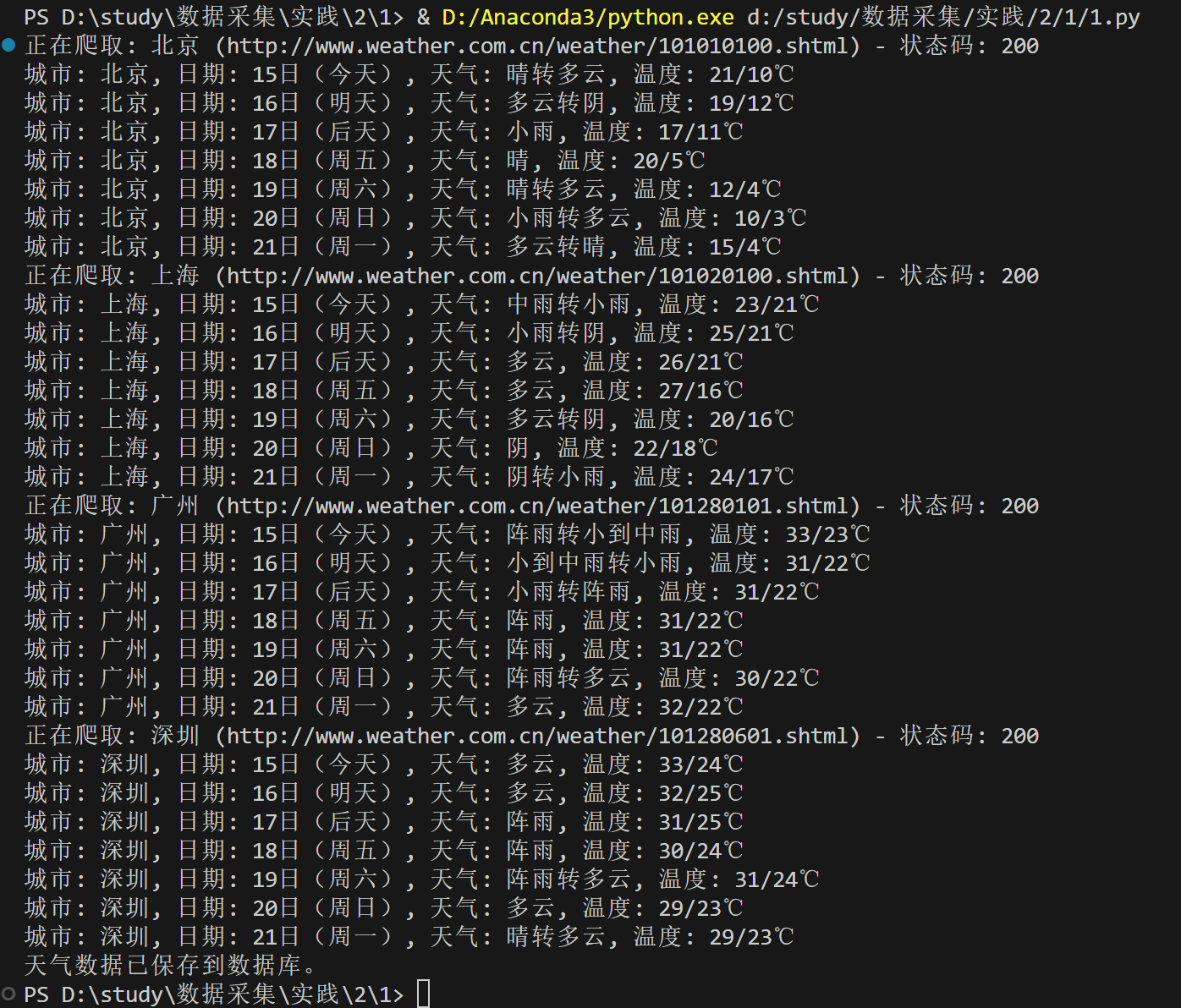
数据库查询结果:

(2) 心得体会
模块化和结构化的代码让功能分明,使用 requests 和 BeautifulSoup 能够高效处理网络请求和 HTML 解析。此外,错误处理的重要性不容忽视,网络请求可能失败且网站结构会变化,因此要灵活应对。
作业②
要求:用requests和BeautifulSoup库方法定向爬取股票相关信息,并存储在数据库中。
(1) 实验过程
选取网站:东方财富网:https://www.eastmoney.com/
核心代码:
数据抓取,从指定的 API 获取股票数据并解析 JSON
def fetch_stock_data(page):
url = f"http://64.push2.eastmoney.com/api/qt/clist/get?cb=jQuery&pn={page}&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81&s:2048&fields=f2,f3,f4,f5,f6,f7,f12,f14&_=1696660618067"
response = requests.get(url)
json_data = response.text[response.text.find('(')+1:response.text.rfind(')')]
data = json.loads(json_data)
return data.get('data', {}).get('diff', [])
数据存储,将抓取到的股票数据存储到 SQLite 数据库中
def store_data(stocks):
conn = sqlite3.connect(DATABASE)
cursor = conn.cursor()
for stock in stocks:
if isinstance(stock, dict): # 确保 stock 是字典
cursor.execute('''
INSERT INTO stocks (name, code, price, change, percent_change, volume) VALUES (?, ?, ?, ?, ?, ?)
''', (
stock.get('f12'), # 股票名称
stock.get('f14'), # 股票代码
stock.get('f2'), # 当前价格
stock.get('f3'), # 涨跌额
stock.get('f4'), # 涨跌幅
stock.get('f6') # 成交量
))
conn.commit()
conn.close()
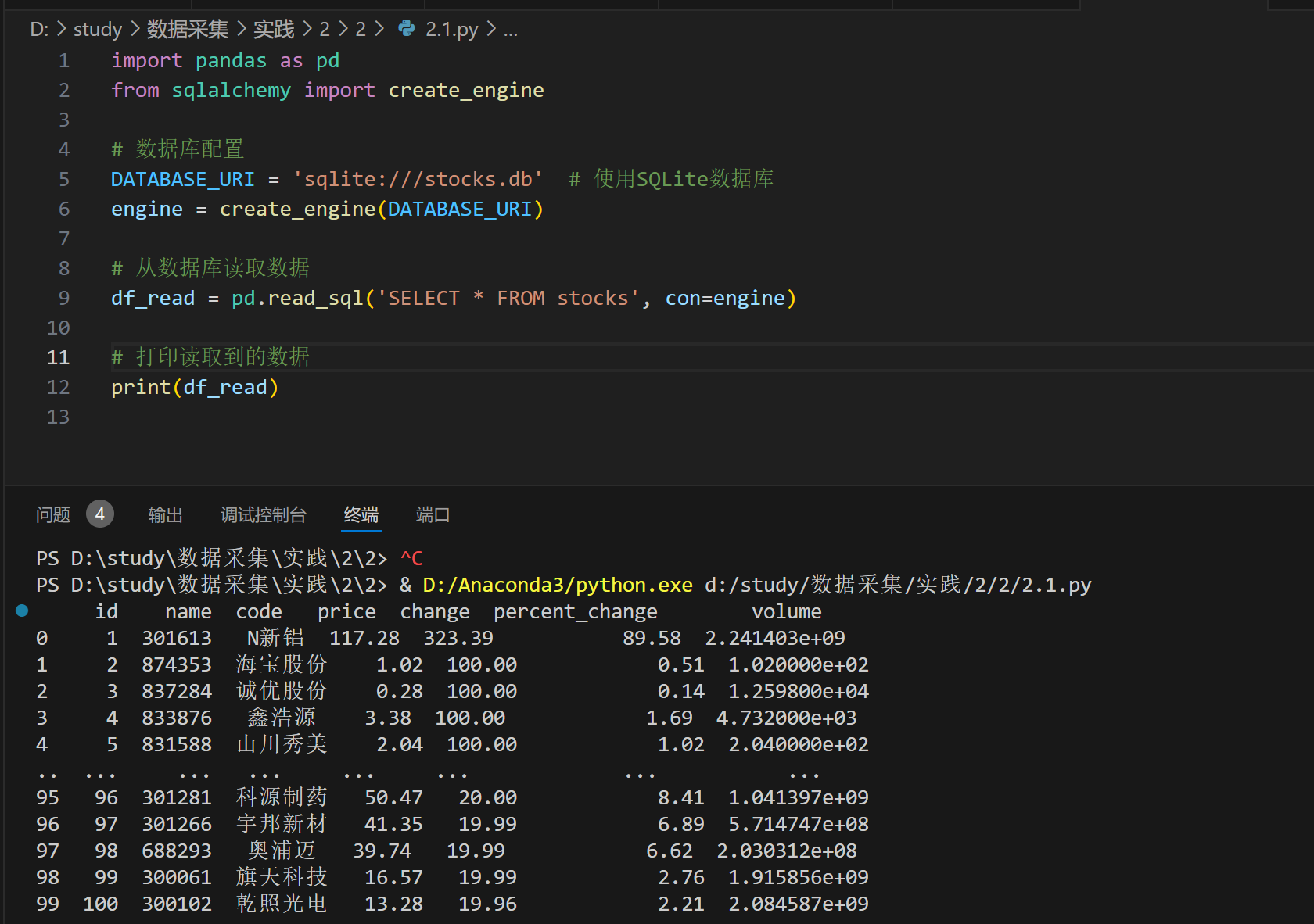
输出结果:
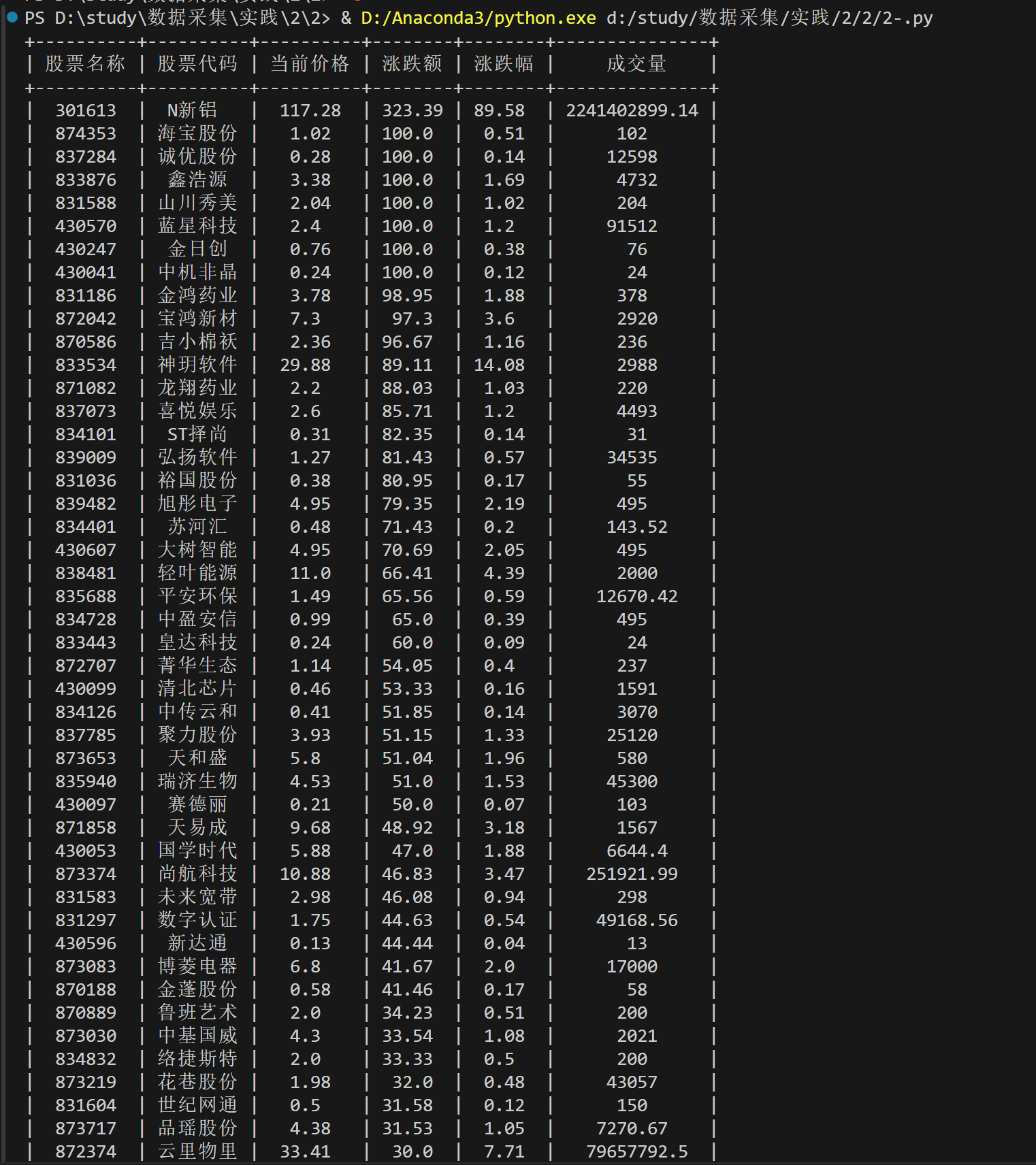
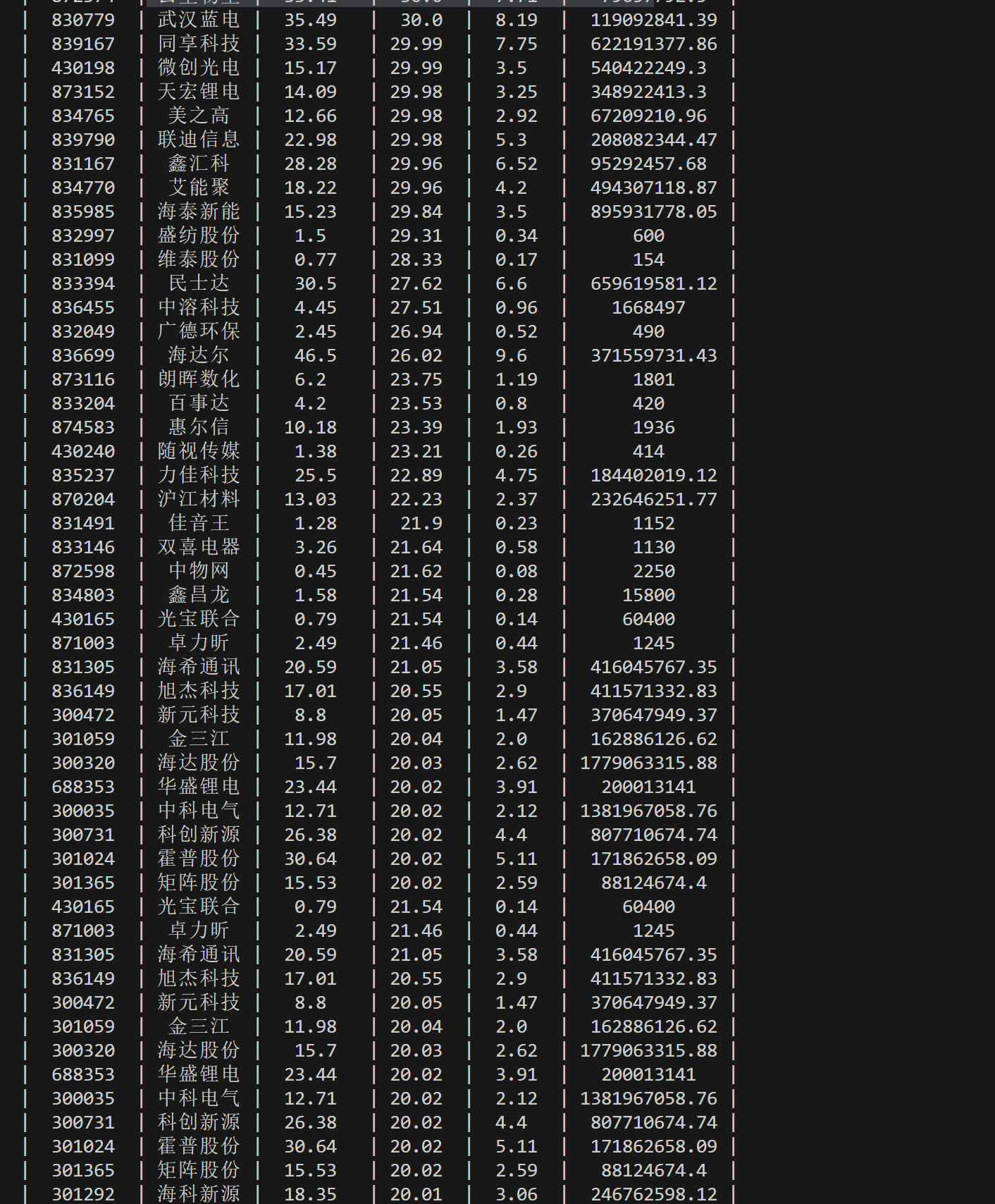
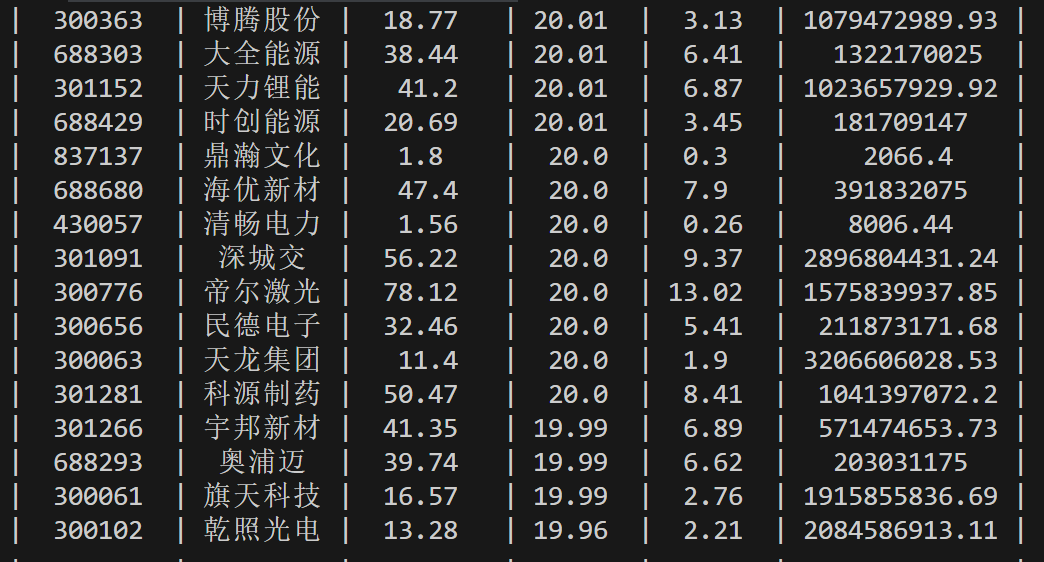
数据库查询结果:
(2)心得体会
抓取数据时需注意 API 的请求限制和数据格式,这要求在编程中保持灵活性和对错误的处理能力。其次,将数据有效地存储到数据库中不仅要考虑性能,还要确保数据的完整性和准确性。
作业③
要求:爬取中国大学2021主榜(https://www.shanghairanking.cn/rankings/bcur/2021)所有院校信息,并存储在数据库中,同时将浏览器F12调试分析的过程录制Gif加入至博客中。录制Gif加入至博客中。
(1) 实验过程
核心代码:
将数据储存到数据库中
# 存储数据到SQLite数据库
def store_data(df):
conn = sqlite3.connect('university_rankings.db')
df.to_sql('rankings', conn, if_exists='replace', index=False)
conn.close()
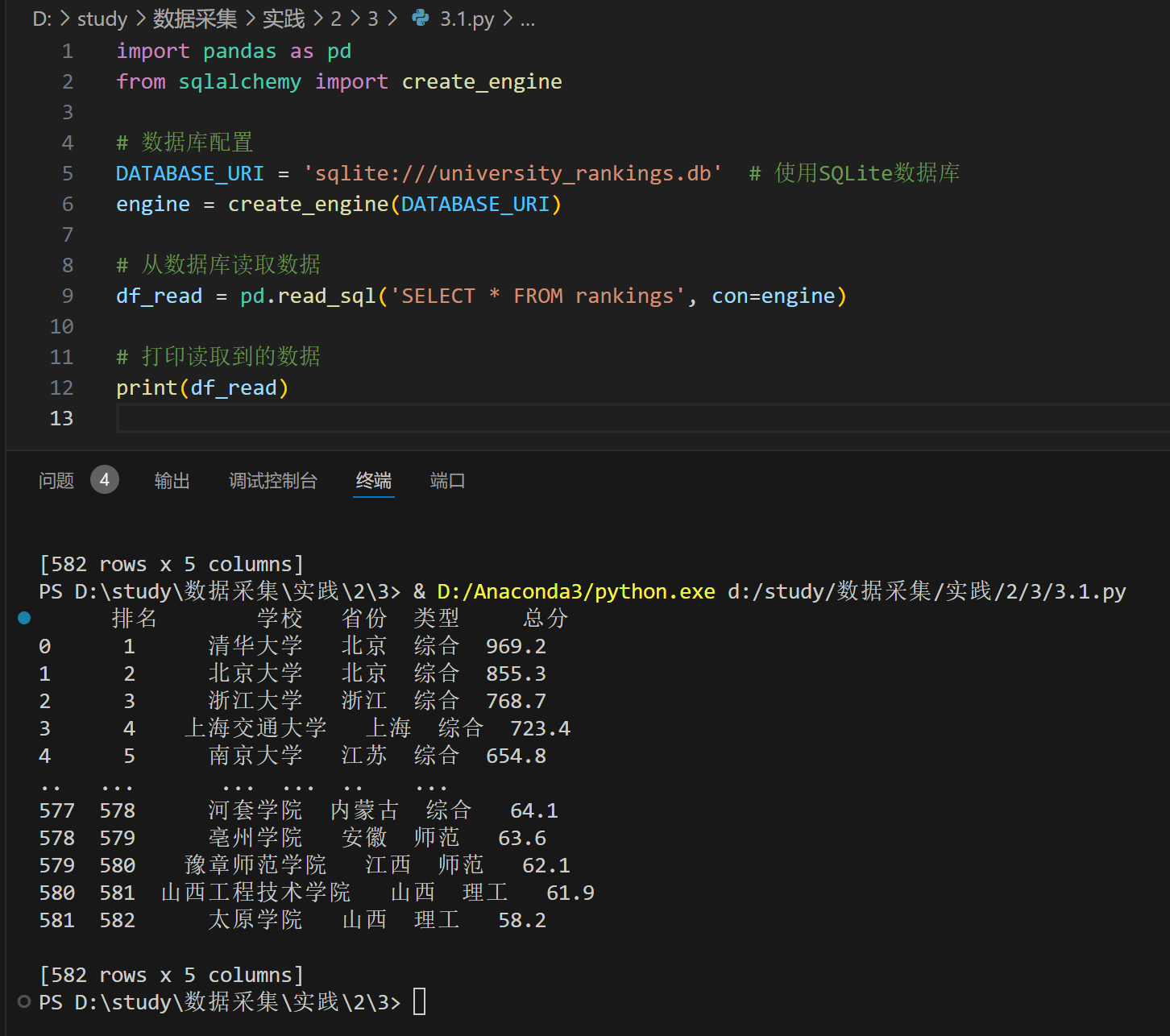
输出结果:
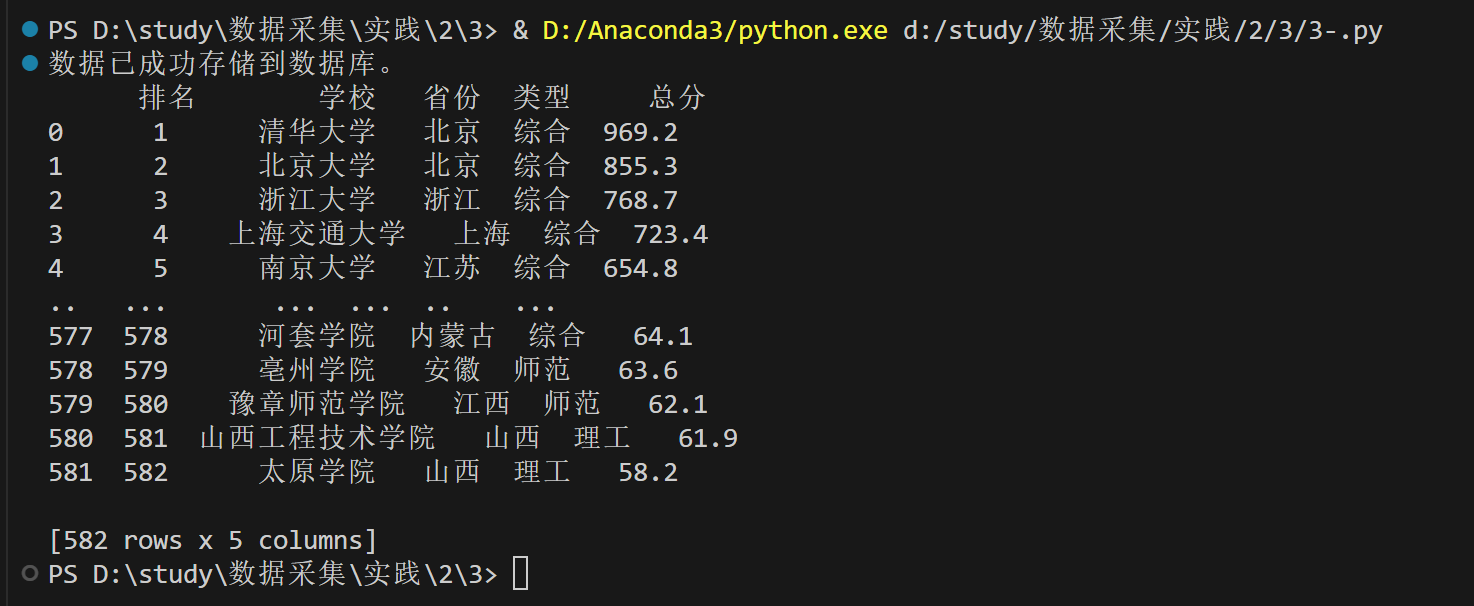
数据库查询:
F12调试分析的过程:
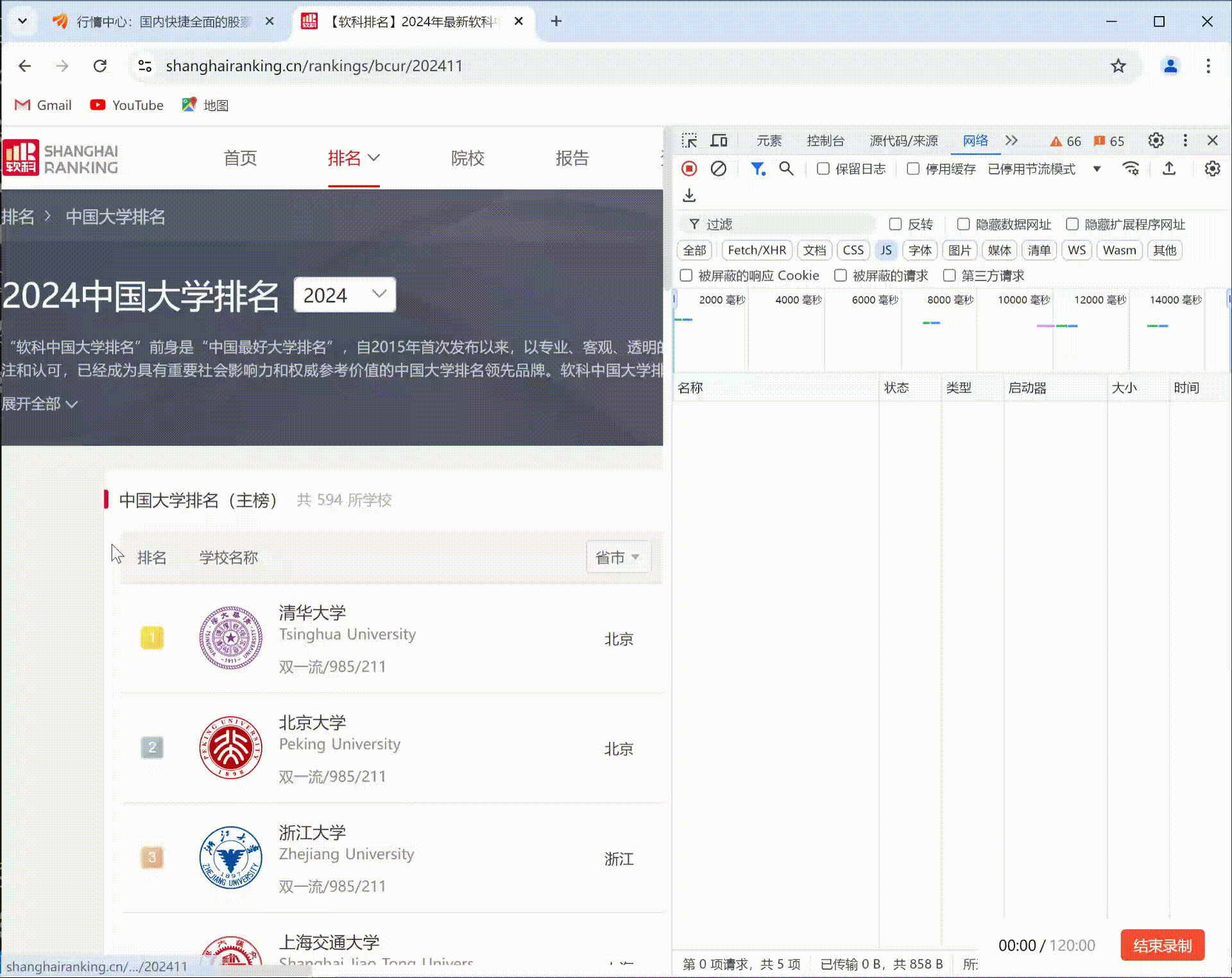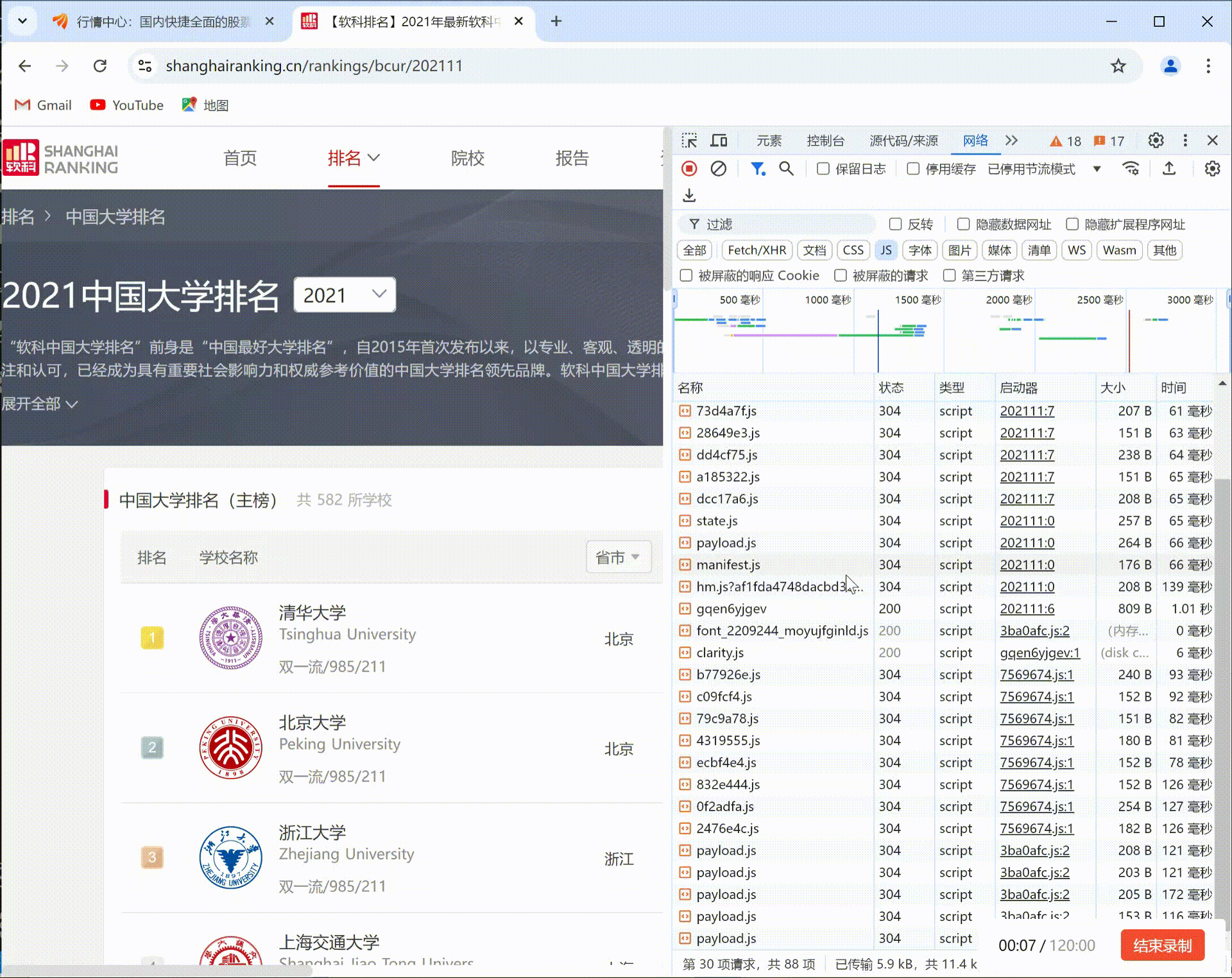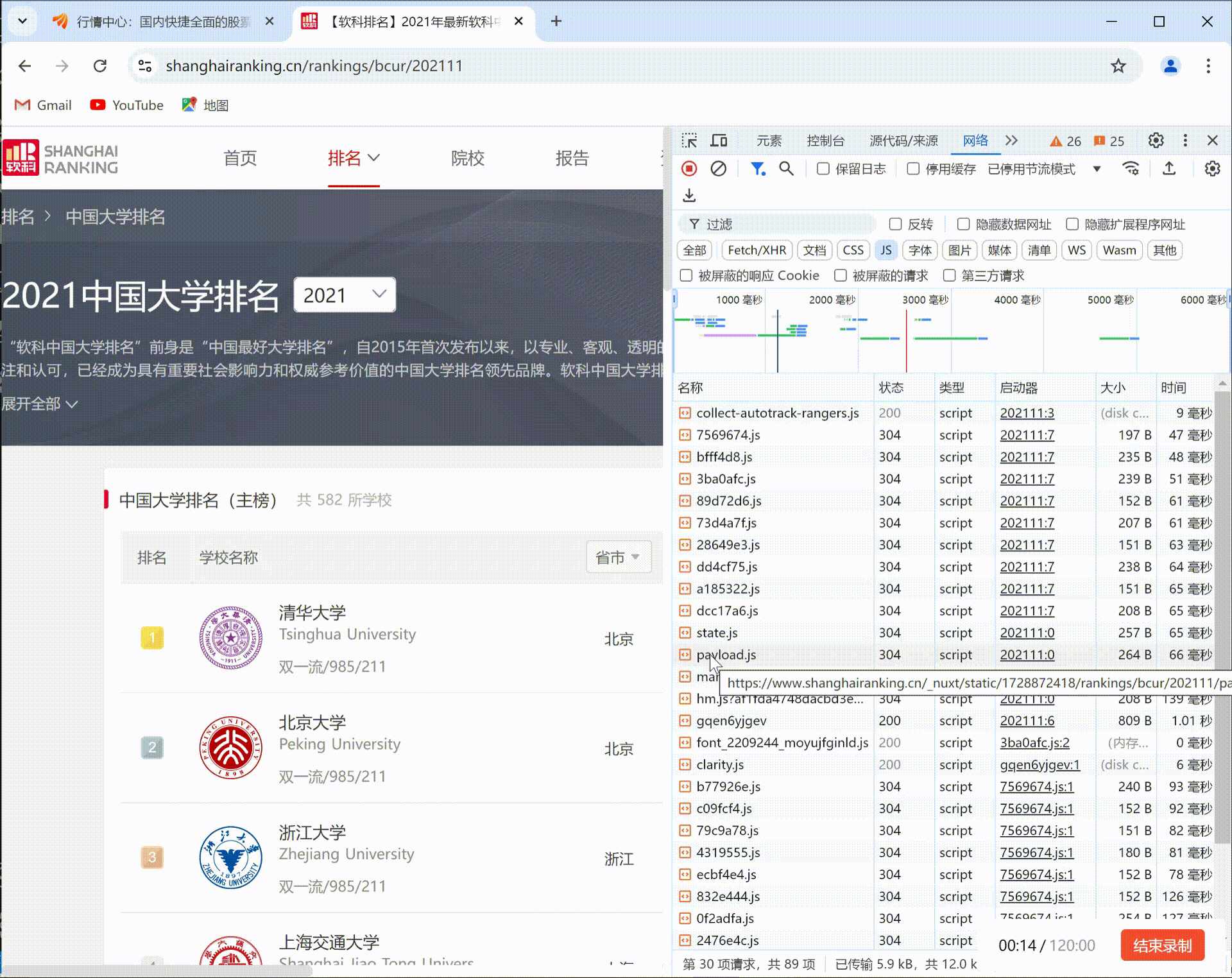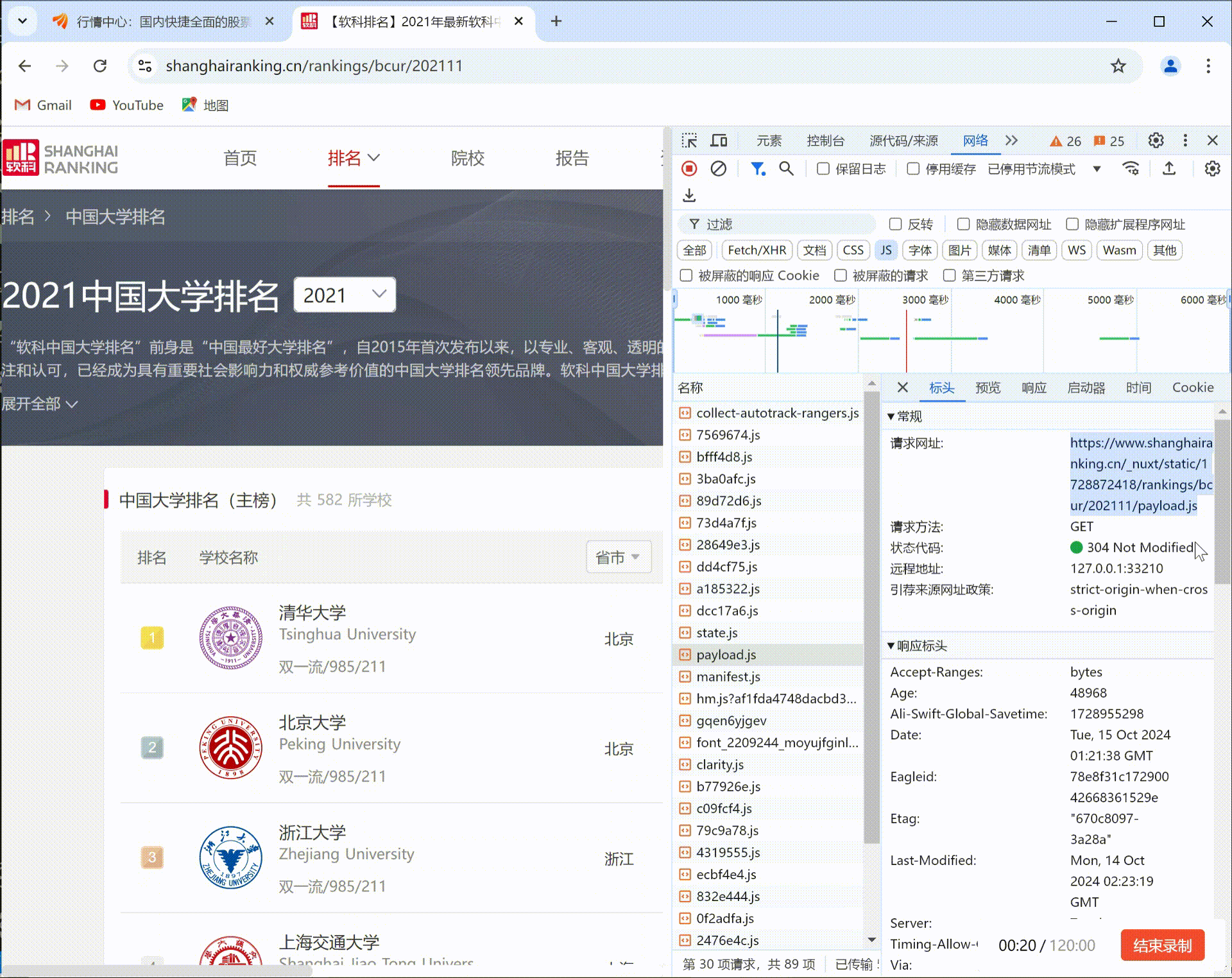
(2) 心得体会
完成这个任务让我深刻体会到数据抓取的重要性,它是高效收集信息的关键。同时,正则表达式的灵活性使得提取特定数据变得可能,尽管需要仔细设计以确保准确性。使用 SQLite 进行数据存储简单有效,适合小型项目,理解数据的持久化和结构化存储对后续分析至关重要。
