
Gitee地址:https://gitee.com/Bluemingiu/project
作业①
要求:用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020) 的数据,屏幕打印爬取的大学排名信息。
(1)实验过程
核心代码:
表格数据提取
for row in rows:
cols = row.find_all('td')
rank = cols[0].text.strip()
name = cols[1].text.strip()
province = cols[2].text.strip()
school_type = cols[3].text.strip()
total_score = cols[4].text.strip()
x.add_row([rank, name, province, school_type, total_score])
运行结果如下
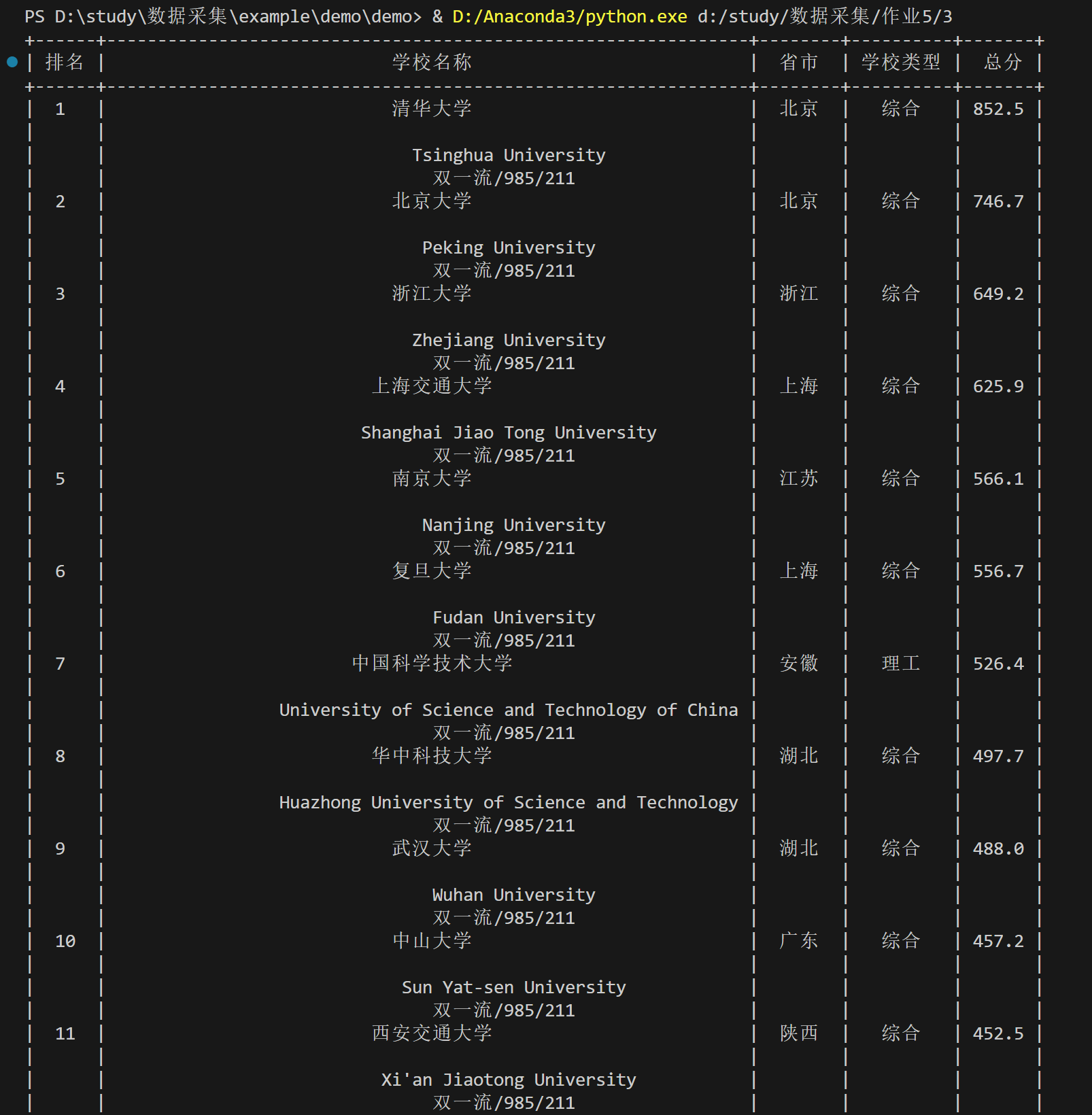
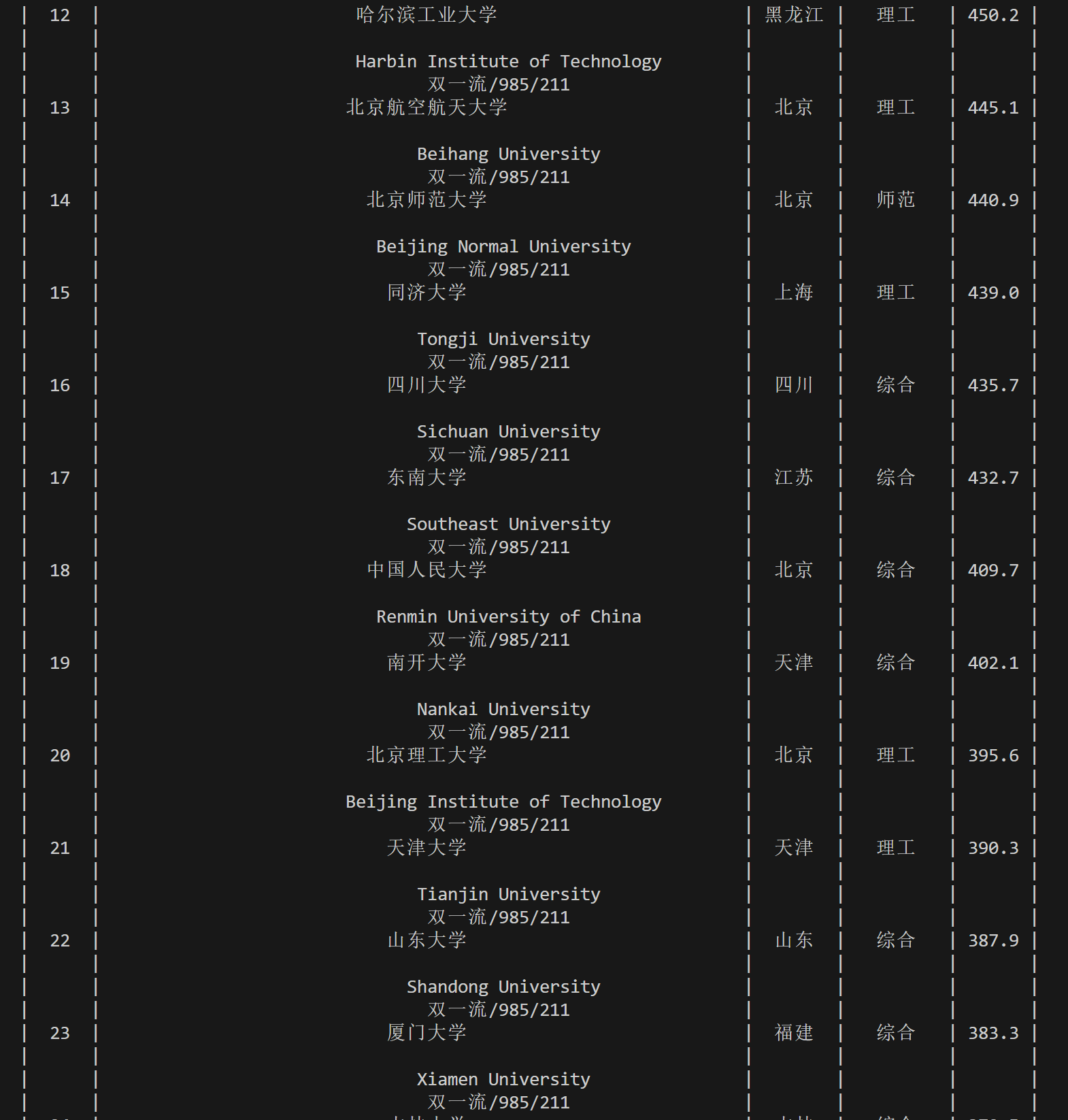

(2) 心得体会
在这个实验中,我学习了如何使用Python的requests库来发送HTTP请求,获取特定网页的内容,并利用BeautifulSoup库解析HTML,提取出网页中的大学排名数据。通过这次实践,我掌握了如何检查响应状态码以确保请求成功,如何处理网页编码问题,以及如何使用正则表达式和BeautifulSoup的选择器来定位和提取表格数据。此外,我还学习了如何使用PrettyTable库将提取的数据以表格形式美观地输出到控制台。
作业②
要求:用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。**
(1) 实验过程
核心代码
- 使用正则表达式提取商品名称和价格
names = re.findall(r'<p class="name".*?<a.*?>(.*?)</a>', html, re.S)
prices = re.findall(r'<span class="price_n">¥(\d+\.?\d*?)</span>', html)
- 输出提取的价格和名称
for index, (name, price) in enumerate(zip(names, prices), start=1):
name_cleaned = re.sub(r'<.*?>', '', name).strip()
x.add_row([index, price, name_cleaned])
运行结果如下
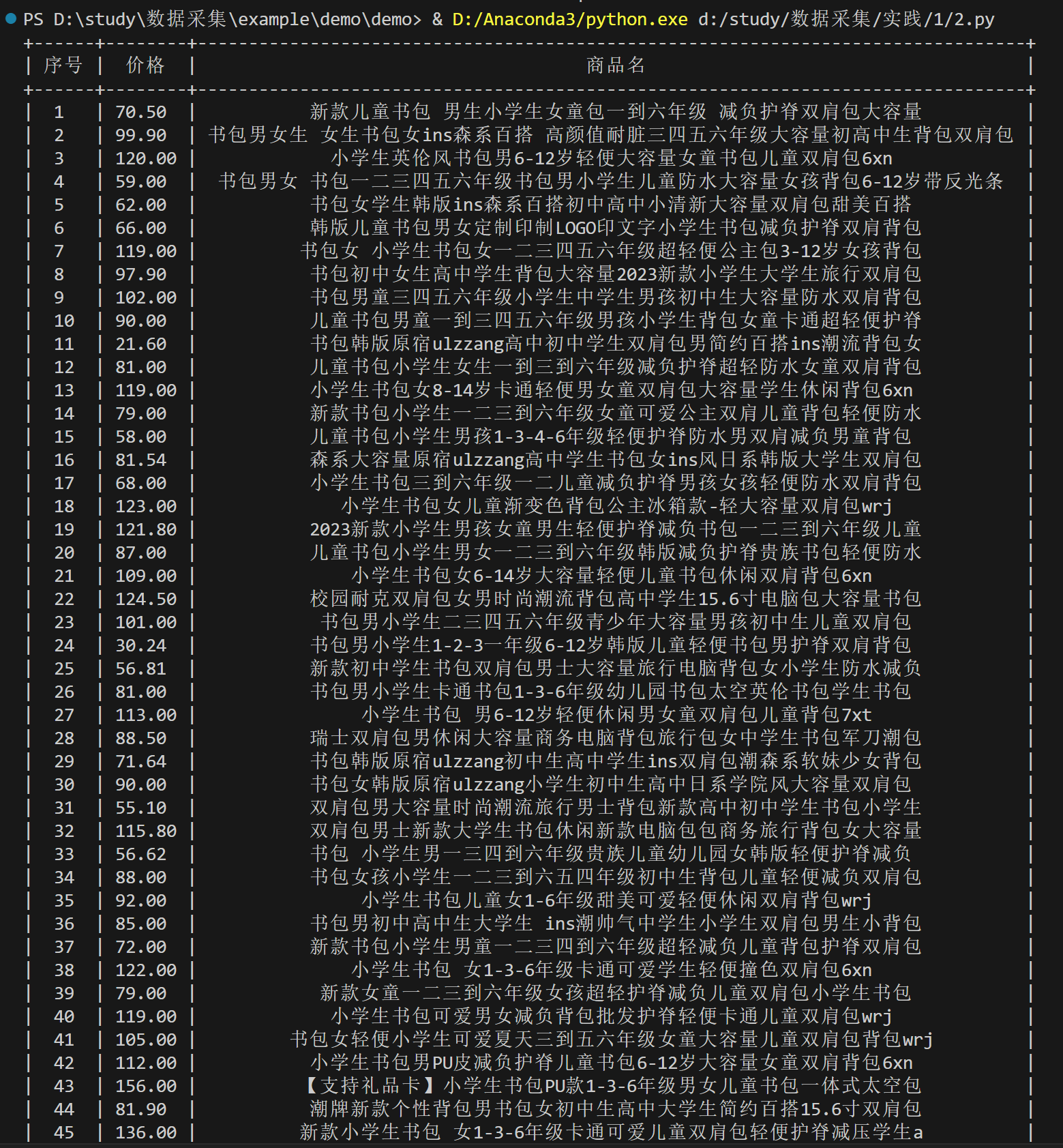
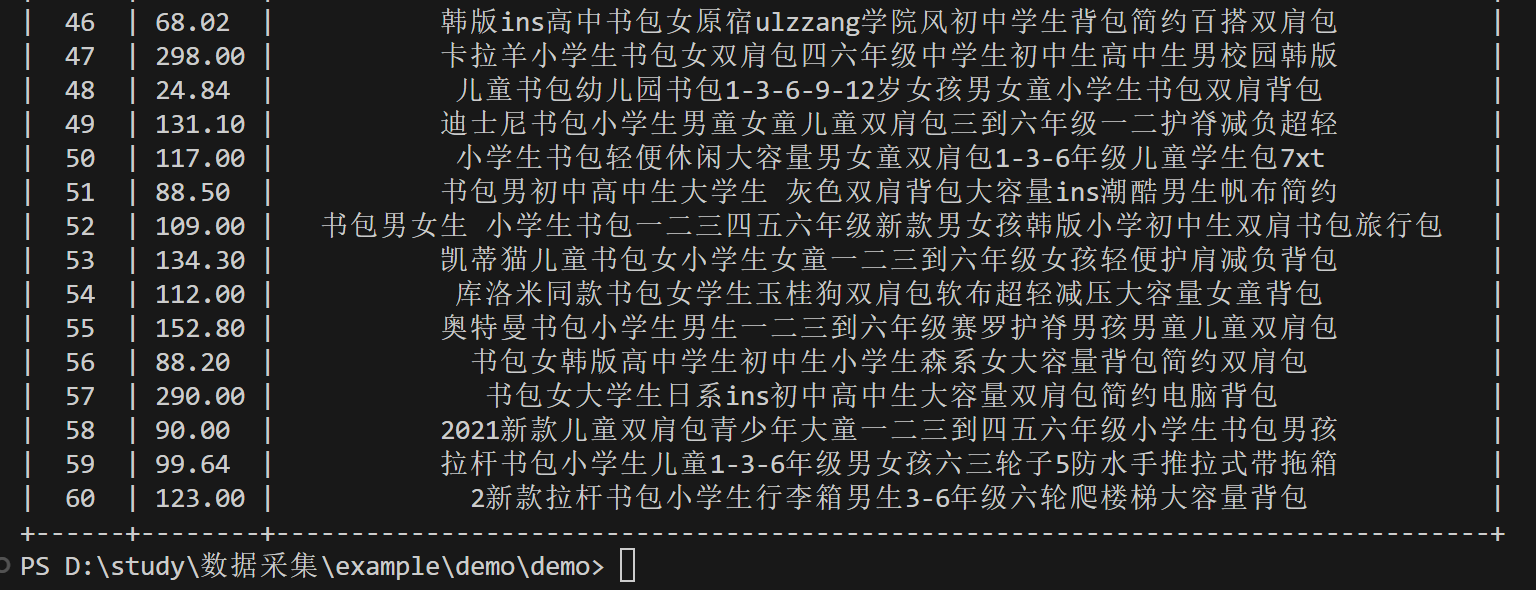
(2) 心得体会
在这个实验中,我掌握了如何使用F12获取网页结构编码,并且根据网页结构编写正则表达式来抓取商品名称和价格。一开始使用的是淘宝网,但是难度比较大,尝试了好几次都失败了,后面改用了当当网,发现能够很好完成爬虫。
作业③
要求:爬取一个给定网页( https://xcb.fzu.edu.cn/info/1071/4481.htm )或者自选网页的所有JPEG和JPG格式文件。
(1) 实验过程
核心代码
- 解析网页内容以提取图片链接
if response.status_code == 200:
# 解析页面内容
soup = BeautifulSoup(response.text, 'html.parser')
# 找到所有图片链接
img_tags = soup.find_all('img')
img_urls = [urljoin(url, img['src']) for img in img_tags if img['src'].endswith(('jpeg', 'jpg'))]
- 下载并保存图片
for img_url in img_urls:
try:
img_response = requests.get(img_url, stream=True)
if img_response.status_code == 200:
img_name = os.path.join(save_folder, os.path.basename(img_url))
with open(img_name, 'wb') as img_file:
img_file.write(img_response.content)
print(f"下载: {img_name}")
else:
print(f"无法下载图片: {img_url}, 状态码: {img_response.status_code}")
except Exception as e:
print(f"下载时发生错误: {e}")
运行结果如下

(2) 心得体会
通过这次实践,我掌握了如何检查HTTP响应状态码以确保请求成功,如何使用urllib.parse.urljoin来构造完整的图片URL,以及如何遍历所有匹配的图片链接并下载它们到本地文件夹。同时我还学习了如何使用os库来处理文件和目录,比如检查目录是否存在以及创建新目录。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号