特征值分解与奇异值分解(转)
写在前面:本文转载整理自https://blog.csdn.net/shenziheng1/article/details/52916278
1. 特征值与特征向量
对于矩阵 $ A $ ,若满足 $ A \zeta = \lambda \zeta $ ,则称 $ \zeta $ 是矩阵 $ A $ 的特征向量,而 $ \lambda $ 则是矩阵 $ A $ 的特征值。一个矩阵的一组特征向量是一组正交向量。
2. 特征值分解
特征值分解是将一个矩阵(维度为 $ n \times n $ )分解成下面的形式:
其中$ Q $ 是矩阵 $ A $ 的特征向量组成的矩阵,$ \Sigma $ 是一个对角阵,而对角线上的元素是矩阵 $ A $ 的特征值。
我们首先来理解一下什么是矩阵?
一个矩阵其实就是一个线性变换。也就是说当一个矩阵乘以一个向量后所得到的向量,相当于将这个向量进行了线性变换。例如对于下面这个矩阵:
其对应的线性变换如下形式:
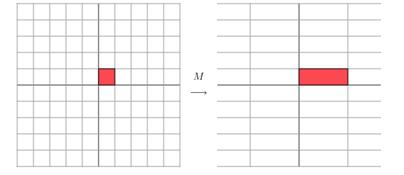
也就是说,当这个矩阵 $ M $ 乘以一个向量 $ [x,y]^T $ 时,所得到的结果是:
由于 $ M $ 是对称的,所以这个变换是一个对 $ x,y$ 轴方向上的一个拉伸(矩阵中每一个对角线上的元素将会对一个维度进行拉伸变换,当 $ 值 > 1 $ 时为拉长,当 $ 值 < 1 $ 时为缩短)。而当矩阵不是对角阵的时候,变换如下:
该矩阵所描述的变换是这样的:
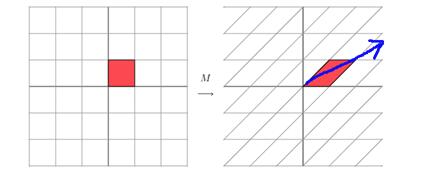
这其实是在平面上对一个轴进行的拉伸变换(如蓝色的箭头所示),在图中,蓝色的箭头是一个最主要的变化方向(变化方向可能有不止一个),如果我们想要描述好一个变换,那我们就描述好这个变换主要的变化方向就好了。反过头来看看之前特征值分解的式子,分解得到的Σ矩阵是一个对角阵,里面的特征值是由大到小排列的,这些特征值所对应的特征向量就是描述这个矩阵变化方向(从主要的变化到次要的变化排列。
当矩阵是高维的情况下,那么这个矩阵就是高维空间下的一个线性变换,这个线性变化可能没法通过图片来表示,但是可以想象,这个变换也同样有很多的变换方向,我们通过特征值分解得到的前N个特征向量,那么就对应了这个矩阵最主要的N个变化方向。我们利用这前 $ k $ 个变化方向,就可以近似这个矩阵(变换)。也就是之前说的:提取这个矩阵最重要的特征。
总结一下,特征值分解可以得到特征值与特征向量,特征值表示的是这个特征到底有多重要,而特征向量表示这个特征是什么,可以将每一个特征向量理解为一个线性的子空间,我们可以利用这些线性的子空间干很多的事情。不过,特征值分解也有很多的局限,比如说变换的矩阵必须是方阵。
3. 奇异值分解(SVD)
特征值分解是一个提取矩阵特征很不错的方法,但是它只是对方阵而言的,在现实的世界中,我们看到的大部分矩阵都不是方阵,比如说有 $ m $ 个学生,每个学生有 $ n $ 科成绩,这样形成的一个 $ m \times n $ 的矩阵就不可能是方阵,我们怎样才能描述这样普通的矩阵呢的重要特征呢?奇异值分解可以用来干这个事情,奇异值分解是一个能适用于任意的矩阵的一种分解的方法:
其中
假设 $ A $ 是一个 $ m \times n $ 的矩阵,那么得到的 $ U $ 是一个 $ m * m $ 的方阵(里面的向量是正交的,$ U $ 里面的向量称为左奇异向量, $ U $ 又叫做酉矩阵), $ \Sigma $ 是一个 $ m \times n $ 的矩阵(除了对角线的元素都是0,对角线上的元素称为奇异值),$ V^T $ 是一个 $ n \times n $ 的矩阵(里面的向量也是正交的,$ V $ 里面的向量称为右奇异向量, $ V $ 又叫做酉矩阵),如下图所示:
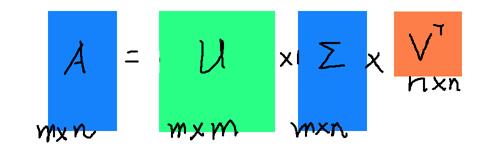
那么奇异值和特征值是怎么对应起来的呢?首先,我们将一个矩阵 $ A $ 乘以它的转置 $ A^T $ ,将会得到一个方阵,我们用这个方阵求特征值可以得到:
这里得到的 $ v_i $ ,就是我们上面的右奇异向量。此外我们还可以得到:
这里的 $ \sigma_i $ 就是上面说的奇异值,$ u_i $ 就是上面说的左奇异向量。奇异值 $ \sigma $ 跟特征值类似,在矩阵 $ \Sigma $ 中也是从大到小排列,而且 $ \sigma $ 的减少特别的快,在很多情况下,前 10% 甚至1%的奇异值的和就占了全部的奇异值之和的99%以上了。也就是说,我们也可以用前 $ r $ 大的奇异值来近似描述矩阵,这里定义一下部分奇异值分解:
$ r $ 是一个远小于 $ m、n $ 的数,这样矩阵的乘法看起来像是下面的样子:
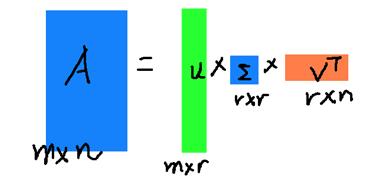
右边的三个矩阵相乘的结果将会是一个接近于 $ A $ 的矩阵,在这儿,$ r $ 越接近于 $ n $ ,则相乘的结果越接近于 $ A $ 。而这三个矩阵的面积之和(在存储观点来说,矩阵面积越小,存储量就越小)要远远小于原始的矩阵 $ A $ ,我们如果想要压缩空间来表示原矩阵 $ A $ ,我们存下这里的三个矩阵:$ U、\Sigma 、V $ 就好了。
而对于特征降维,我们只需要矩阵 $ U $ 中的前 $ r $ 个向量即可,该 $ r $ 个向量所表示的特征空间能够保留原数据中的大部分信息。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号