Stanford机器学习笔记-9. 聚类(K-means算法)
9. Clustering
Content
9. Clustering
9.1 Supervised Learning and Unsupervised Learning
9.2 K-means algorithm(代码地址:https://github.com/llhthinker/MachineLearningLab/tree/master/K-Means)
9.3 Optimization objective
9.4 Random Initialization
9.5 Choosing the Number of Clusters
9.1 Supervised Learning and Unsupervised Learning
我们已经学习了许多机器学习算法,包括线性回归,Logistic回归,神经网络以及支持向量机。这些算法都有一个共同点,即给出的训练样本自身带有标记。比如,使用线性回归预测房价时,我们所使用的每一个训练样本是一个或多个变量(如面积,楼层等)以及自身带有的标记即房价。而使用Logistic回归,神经网络和支持向量机处理分类问题时,也是利用训练样本自身带有标记即种类,例如进行垃圾邮件分类时是利用已有的垃圾邮件(标记为1)和非垃圾邮件(标记为0),进行数字识别时,变量是每个像素点的值,而标记是数字本身的值。我们把使用带有标记的训练样本进行学习的算法称为监督学习(Supervised Learning)。监督学习的训练样本可以统一成如下形式,其中x为变量,y为标记。
![]()
显然,现实生活中不是所有数据都带有标记(或者说标记是未知的)。所以我们需要对无标记的训练样本进行学习,来揭示数据的内在性质及规律。我们把这种学习称为无监督学习(Unsupervised Learning)。所以,无监督学习的训练样本如下形式,它仅包含特征量。
![]()
图9-1形象的表示了监督学习与无监督学习的区别。图(1)表示给带标记的样本进行分类,分界线两边为不同的类(一类为圈,另一类为叉);图(2)是基于变量x1和x2对无标记的样本(表面上看起来都是圈)进行聚类(Clustering)。
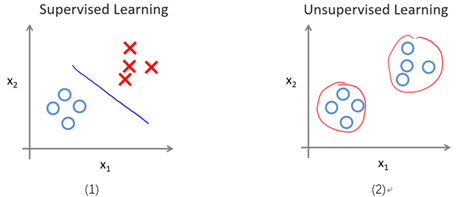
图9-1 一个监督学习与无监督学习的区别实例
无监督学习也有很多应用,一个聚类的例子是:对于收集到的论文,根据每个论文的特征量如词频,句子长,页数等进行分组。聚类还有许多其它应用,如图9-2所示。一个非聚类的例子是鸡尾酒会算法,即从带有噪音的数据中找到有效数据(信息),例如在嘈杂的鸡尾酒会你仍然可以注意到有人叫你。所以鸡尾酒会算法可以用于语音识别(详见wikipedia)。
quora上有更多关于监督学习与无监督学习之间的区别的讨论。
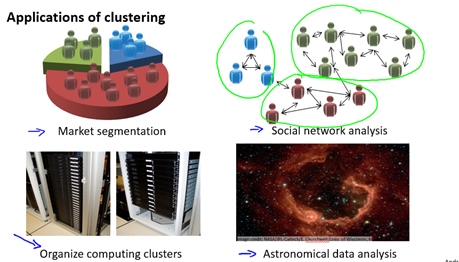
图9-2 一些聚类的应用
9.2 K-means algorithm
聚类的基本思想是将数据集中的样本划分为若干个通常是不相交的子集,每个子集称为一个"簇"(cluster)。划分后,每个簇可能有对应的概念(性质),比如根据页数,句长等特征量给论文做簇数为2的聚类,可能得到一个大部分是包含硕士毕业论文的簇,另一个大部分是包含学士毕业论文的簇。
K均值(K-means)算法是一个广泛使用的用于簇划分的算法。下面说明K均值算法的步骤:
-
随机初始化K个样本(点),称之为簇中心(cluster centroids);
-
簇分配: 对于所有的样本,将其分配给离它最近的簇中心;
-
移动簇中心:对于每一个簇,计算属于该簇的所有样本的平均值,移动簇中心到平均值处;
-
重复步骤2和3,直到找到我们想要的簇(即优化目标,详解下节9.3)
图9-3演示了以特征量个数和簇数K均为2的情况。
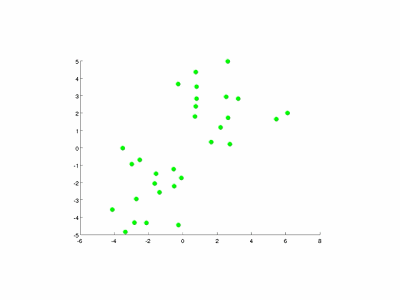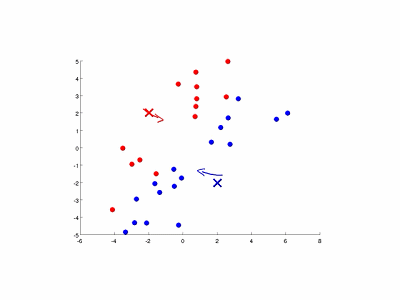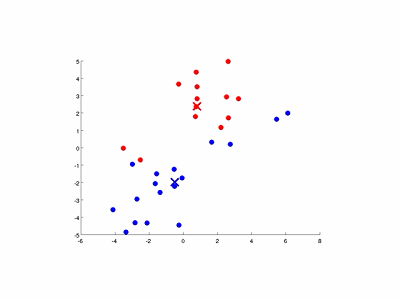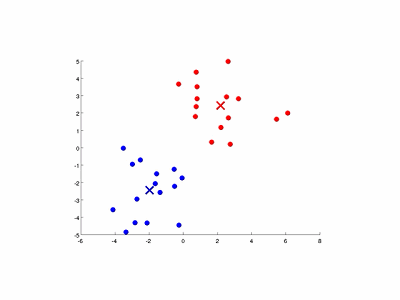
图9-3 K均值算法的演示
通过上述描述,下面我们形式化K均值算法。
输入:
-
K (number of clusters)
-
Training set
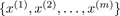 , where
, where 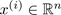 (drop
(drop 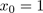 convention)
convention)
算法:
Randomly initialize K cluster centroids
Repeat {
for i = 1 to m
:= index (from 1 to K ) of cluster centroid closest to
for k = 1 to K
:= average (mean) of points assigned to cluster
}
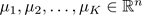
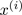
上述算法中,第一个循环对应了簇分配的步骤:我们构造向量c,使得c(i)的值等于x(i)所属簇的索引,即离x(i)最近簇中心的索引。用数学的方式表示如下:
![]()
第二个循环对应移动簇中心的步骤,即移动簇中心到该簇的平均值处。更数学的方式表示如下:
![]()
其中![]() 都是被分配给簇
都是被分配给簇 的样本。
的样本。
如果有一个簇中心没有分配到一个样本,我们既可以重新初始化这个簇中心,也可以直接将其去除。
经过若干次迭代后,该算法将会收敛,也就是继续迭代不会再影响簇的情况。
在某些应用中,样本可能比较连续,看起来没有明显的簇划分,但是我们还是可以用K均值算法将样本分为K个子集供参考。例如根据人的身高和体重划分T恤的大小码,如图9-4所示。
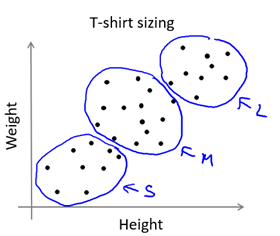
图9-4 K-means for non-separated clusters
9.3 Optimization objective
重新描述在K均值算法中使用的变量:
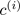 = index of cluster (1,2,…, K ) to which example
= index of cluster (1,2,…, K ) to which example 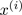 is currently assigned
is currently assigned
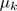 = cluster centroid k (
= cluster centroid k (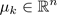 )
)
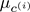 = cluster centroid of cluster to which example
= cluster centroid of cluster to which example 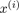 has been assigned
has been assigned
使用这些变量,定义我们的cost function如下: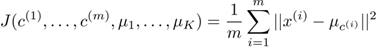
所以我们的优化目标就是
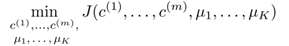
结合9.2节所描述的算法,可以发现:
- 在簇分配步骤中,我们的目标是通过改变
 最小化J函数(固定
最小化J函数(固定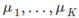 )
)
- 在移动簇中心步骤中,我们的目标通过改变
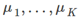 最小化J函数(固定
最小化J函数(固定 )
)
注意,在K均值算法中,cost function不可能能增加,它应该总是下降的(区别于梯度下降法)。
9.4 Random Initialization
下面介绍一种值得推荐的初始化簇中心的方法。
-
确保K < m,也就是确保簇的数量应该小于样本数;
-
随机选择K个训练样本;
-
令K个簇中心
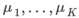 等于K个训练样本。
等于K个训练样本。
K均值算法可能陷入局部最优。为了减少这种情况的发生,我们可以基于随机初始化,多次运行K均值算法。所以,算法变成如下形式(以运行100次为例:效率与准确性的tradeoff)
For i = 1 to 100 {
Randomly initialize K-means.
Run K-means. Get
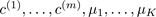
Compute cost function (distortion)
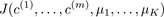
}
Pick clustering that gave lowest cost
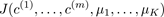
9.5 Choosing the Number of Clusters
选择K的取值通常是主观的,不明确的。也就是没有一种方式确保K的某个取值一定优于其他取值。但是,有一些方法可供参考。
The elbow method : 画出代价J关于簇数K的函数图,J值应该随着K的增加而减小,然后趋于平缓,选择当J开始趋于平衡时的K的取值。如图9-5的(1)所示。
但是,通常这条曲线是渐变的,没有很显然的"肘部"。如图9-5的(2)所示。
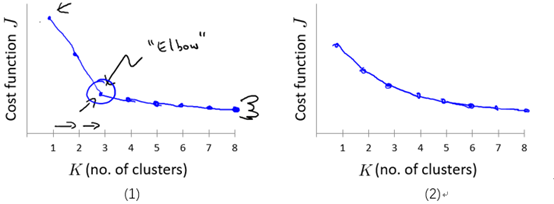
图9-5 代价J关于簇数K的曲线图
注意:随着K的增加J应该总是减少的,否则,一种出错情况可能是K均值陷入了一个糟糕的局部最优。
一些其他的方法参见wikipedia。
当然,我们有时应该根据后续目的( later/downstream purpose )来确定K的取值。还是以根据人的身高和体重划分T恤的大小码为例,若我们想将T恤大小划分为S/M/L这3种类型,那么K的取值应为3;若想要划分为XS/S/M/L/XL这5种类型,那么K的取值应为5。如图9-6所示。
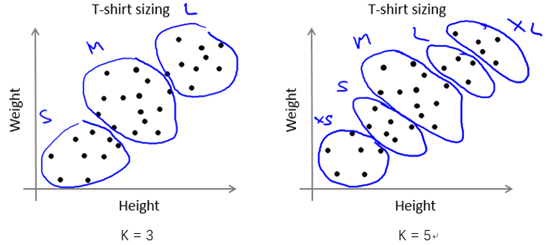
图9-6 划分T恤size的两种不同情况
【推荐阅读】讨论K均值算法的缺点

 浙公网安备 33010602011771号
浙公网安备 33010602011771号